bind实现
按照socket网络编程的顺序,我们这一篇来分析bind函数。我们通过socket函数拿到了一个socket结构体。bind函数的逻辑其实比较简单,他就是给socket结构体绑定一个地址,简单来说,就是给他的某些字段赋值。talk is cheap。show me the code。
1 | static int sock_bind(int fd, struct sockaddr *umyaddr, int addrlen) |
主要是两个函数,我们一个个来。
1、sockfd_lookup
通过之前一些文章的分析,我们应该数socket和文件的内存布局比较熟悉了。下面的代码不难理解。就是根据文件描述符从pcb中找到inode节点。因为inode节点里保存了socket结构体,所以最后返回fd对应的socke结构体就行。
1 | // 通过fd找到file结构体,从而找到inode节点,最后找到socket结构体 |
2、sock->ops->bind
我们回顾socket那篇文章可以知道socket结构体里保存了一些列的操作函数,假设是协议簇是ipv4,那么bind函数就是inet_bind函数(省略了部分代码)。
1 | // 给socket绑定一个地址 |
bind函数主要是对待绑定的ip和端口做一个校验,合法的时就记录在sock结构体中。并且把sock结构体挂载到一个全局的哈希表里。
listen 实现
listen函数的逻辑比bind还简单。bind主要是校验和绑定ip、端口。listen则是修改socket的状态,并记录一些设置。
1 | static int sock_listen(int fd, int backlog) |
accept 实现
我们继续分析tcp/ip协议的实现,这一篇讲一下accept,accept就是从已完成三次握手的连接队列里,摘下一个节点。我们可以了解到三次握手的实现和过程。很多同学都了解三次握手是什么,但是可能很少同学会深入思考或者看他的实现,众所周知,一个服务器启动的时候,会监听一个端口。其实就是新建了一个socket。那么如果有一个连接到来的时候,我们通过accept就能拿到这个新连接对应的socket。那么这个socket和监听的socket是不是同一个呢?其实socket分为监听型和通信型的。表面上,服务器用一个端口实现了多个连接,但是这个端口是用于监听的,底层用于和客户端通信的其实是另一个socket。所以每一个连接过来,负责监听的socket发现是一个建立连接的包(syn包),他就会生成一个新的socket与之通信(accept的时候返回的那个)。我们将会从代码中看到这个实现。
我们从accept函数开始,详细分析这个过程。
1 | static int sock_accept(int fd, struct sockaddr *upeer_sockaddr, int *upeer_addrlen) |
我们一步步来分析这个函数。
1 通过fd找到对应的socket结构体,然后申请一个新的socket结构体和sock结构体,并且把他们两互相关联。这个在前面的文章分析过。
2 然后把监听的socket和准备用于通信的结构体作为参数,调用accept函数。
3 最后返回通信socket对应的文件描述符。
下面我们开始分析accept函数的真正实现。
1 | static int inet_accept(struct socket *sock, struct socket *newsock, int flags) |
这个函数主要是调底层的accept函数,底层accept函数会返回一个新的sock结构体,socket和sock结构体的区别和背景在之前的文章里已经分析过。总的来说,accept函数就是申请一个新的通信socket,这个socket关联了一个新的sock结构体。下面我们看看tcp层的accept函数。
1 | static struct sock *tcp_accept(struct sock *sk, int flags) |
这个函数主要的逻辑是从监听型socket的已完成三次握手的队列里摘下一个节点。这个节点是一个sk_buff结构体,sk_buff是一个表示网络数据包的数据结构。
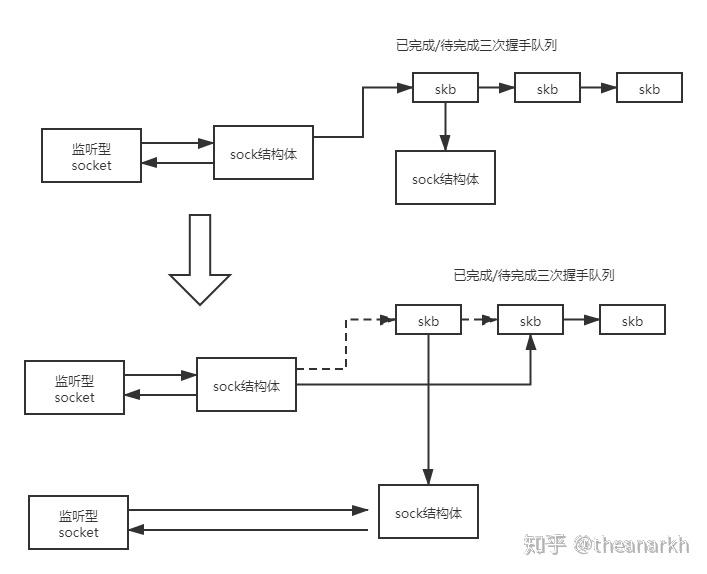
accept函数就分析完了。下一篇我们分析三次握手。看看accept函数摘下的这个节点是如果生成的。
connect 实现
分析完了服务器端,我们继续分析客户端,在socket编程中,客户端的流程是比较简单的,申请一个socket,然后调connect去发起连接就行。我们先看一下connect函数的定义。
1 | /* |
我们通过层层调用揭开connect的迷雾。
1 | static int sock_connect(int fd, struct sockaddr *uservaddr, int addrlen) |
没有太多逻辑,通过fd找到关联的socket结构体。然后调底层函数。底层的函数是inet_connect,这个函数逻辑比较多,我们分开分析。
1 | if (sock->state == SS_CONNECTING && sk->protocol == IPPROTO_TCP && (flags & O_NONBLOCK)) { |
正在连接,并且是非阻塞的,直接返回。
1 | if (sock->state != SS_CONNECTING) |
继续调用底层的函数,这里是tcp,所以是发送一个sync包(一会分析)。然后把socket状态修改为连接中。
1 | if (sk->state != TCP_ESTABLISHED &&(flags & O_NONBLOCK)) |
还没建立连接成功并且是非阻塞的方式,直接返回。
1 | // 连接建立中,阻塞当前进程 |
connect的时候如果没有设置阻塞标记,则进程会被挂起。tcp层建立连接后会唤醒进程。
1 | // 连接建立 |
最后被连接建立唤醒后,设置socket的状态。connect就完成了。
下面我们看一下tcp层的connect的实现,其实就是从客户端视角看三次握手的过程。代码比较多,只看一下核心的。
1 | static int tcp_connect(struct sock *sk, struct sockaddr_in *usin, int addr_len) |
代码很长,主要是构建一个sync包发出去。在这个代码里我们大概能看到tcp协议的相关实现。上面的代码完成了第一次握手。下面再看一下第二次握手的代码。
1 | // 发送了syn包 |
上面代码完成了第二次握手。tcp_send_ack完成第三次握手。这里不打算深入分析tcp层的代码,后续再深入分析。