目录
2.4.1、Lucene 字段类型
2.4.2、索引文档示例
2.4.3、在Luke中查看索引
2.4.4、索引的删除
2.4.5 索引的更新
-———————————————–
上一节 介绍完了 Lucene 分词器,这节介绍 Lucene 是如何索引文档的。
2.4.1、Lucene 字段类型
文档:文档是 Lucene索引的基本单位;
字段:比文档更小的单位,字段是文档的一部分;
每个字段 由 3部分组成:名称(name),类型(type),取值(value);
字段的取值(value)一般为:文本、二进制、数值
Lucene的主要字段类型:
- TextField:字段内容 -> 索引并词条化 -> 不保存 词向量 -> 整篇文档的body字段,常用TextField进行索引;
- StringField:只 索引 -> 不词条化 -> 不保存 词向量;
- IntPoint:适合 int类型 的索引;
- LongPoint:适合 long类型的 索引;
- FloatPoint:
- DoublePoint:
- SortedDocValuesField:存储值为 文本内容的 DocValue字段,且需要 按值排序;
- SortedSetDocValuesField:多值域为 DocValue字段,值为文本内容,且 需要 按值分组、聚合;
- NumbericDocValuesField: DocValue为(int,long,float,double)
- SortedNumbericDocValuesField:需要排序的 (int,long,float,double)
- SortedField:索引 保存字段值,不进行其他操作
Lucene 使用 倒排索引 快速搜索 <===> 建立 词项和文档id的关系映射;
搜索过程:
通过 类似hash算法 -> 定位到 搜索关键词 -> 读取文档id集合
上述过程的缺陷:
当我们需要对数据做 聚合操作,排序、分组时,Lucene会提取所有出现在文档集合中的排序字段,再次构建一个排好序的文件集合;这个过程全部在内存中进行,如果数据量巨大,会造成 内存溢出 和 性能缓慢;
Lucene 4.X 之后出现了 DocValues,DocValues是 Lucene 构建索引时,额外建立的一个有序的基于 document => field/value 的映射列表。
2.4.2、索引文档示例
代表新闻的实例类 News.java
1 | package com.learn.lucene.chapter2.index; |
创建索引文件的CreateIndex.java
1 | package com.learn.lucene.chapter2.index; |
运行结果:
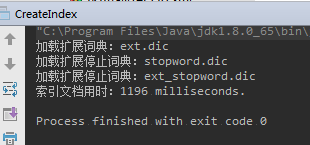
生成对应的索引文件
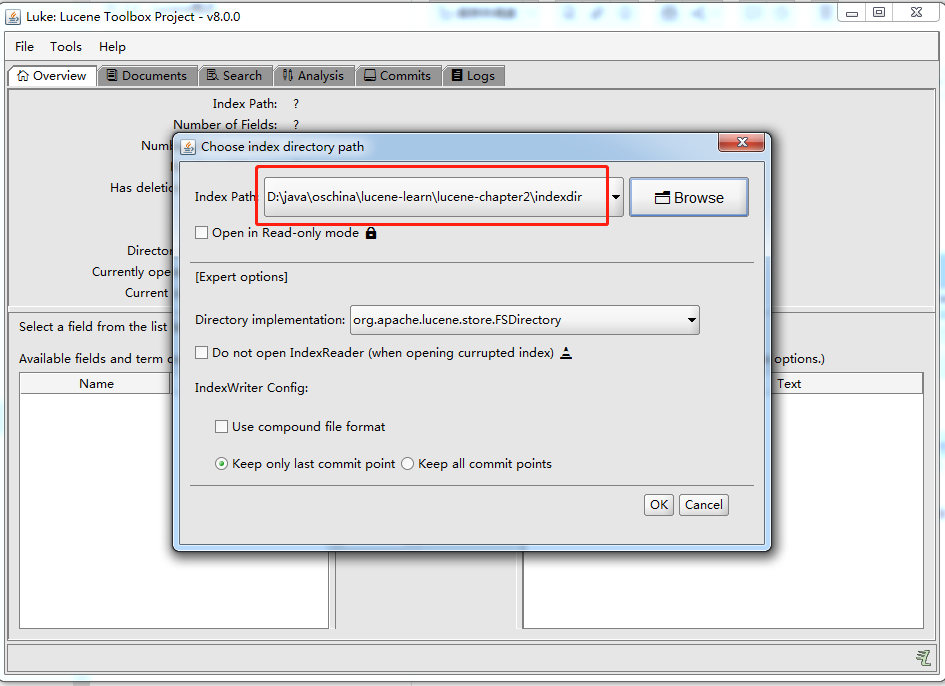
2.4.3、在Luke中查看索引
打开索引文件目录:D:\java\oschina\lucene-learn\lucene-chapter2\indexdir
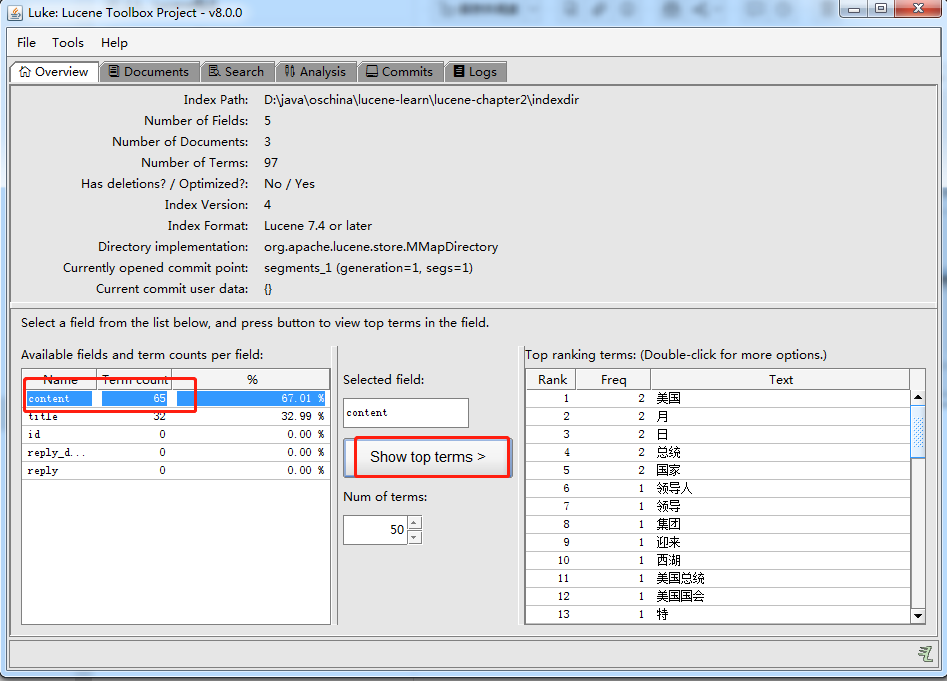
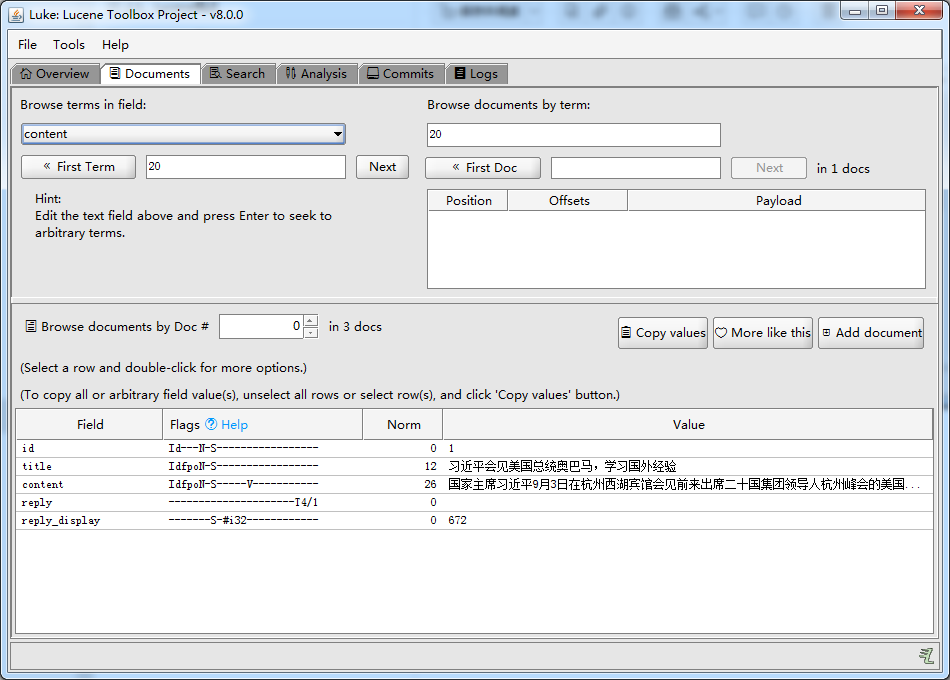
2.4.4、索引的删除
索引同样存在 CRUD 操作
本节演示 根据 Term 来删除点单个或多个Document,删除 title 中 包含关键词“美国”的文档。
1 | package com.learn.lucene.chapter2.index; |
运行结果:
除此之外,IndexWriter还提供了以下方法:
- DeleteDocuments(Query query):根据Query条件来删除单个或多个Document。
- DeleteDocuments(Query[] queries):根据Query条件来删除单个或多个Document。
- DeleteDocuments(Term term):根据Term条件来删除单个或多个Document。
- DeleteDocuments(Term[] terms):根据Term条件来删除单个或多个Document。
- DeleteAll():删除所有的Document。
使用IndexWriter进行Document删除操作时,文档并不会立即被删除,而是把这个删除动作缓存起来,当IndexWriter.Commit() 或 IndexWriter.Close()时,删除操作才会真正执行。
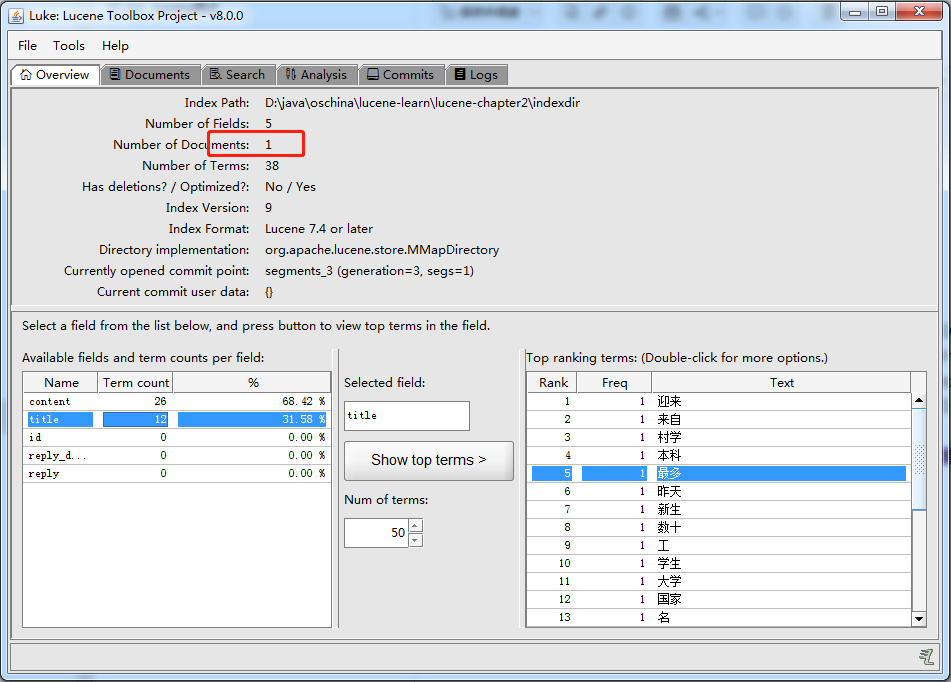
使用Luke 重新打开 索引之后,只剩下了一个索引文档:
2.4.5 索引的更新
本质:先删除索引,再建立新的文档。
1 | package com.learn.lucene.chapter2.index; |
运行结果:
修改前: 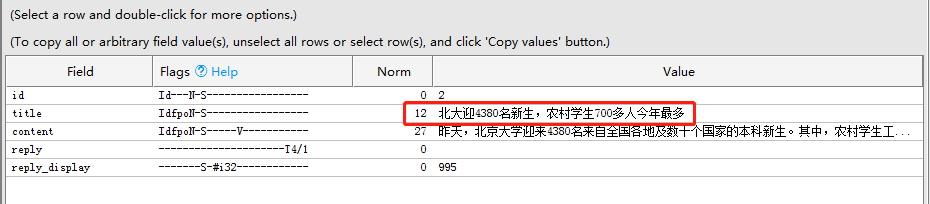
修改后: 