- 先建立model对象
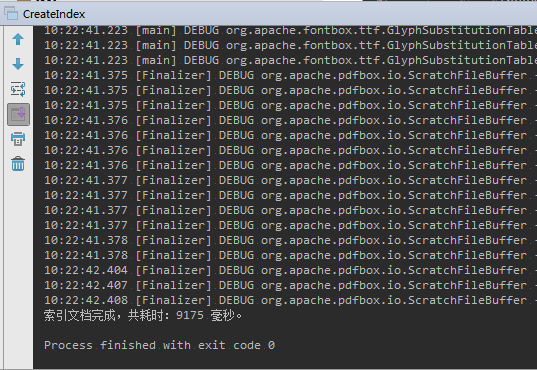
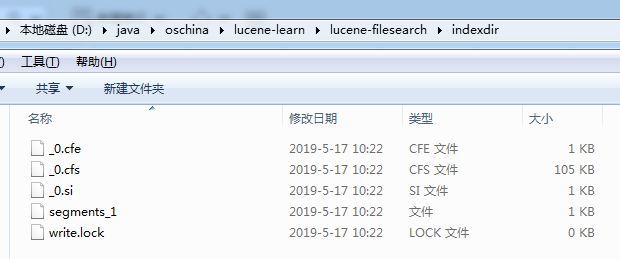
- 创建索引
-———————————-
代码仓库:https://gitee.com/carloz/lucene-learn.git
https://gitee.com/carloz/lucene-learn/tree/master/lucene-filesearch
-———————————-
工程搭建完成以后,首先构建索引;
检索的对象:文件;
为了简单:只索引 文档名 和 文档内容;
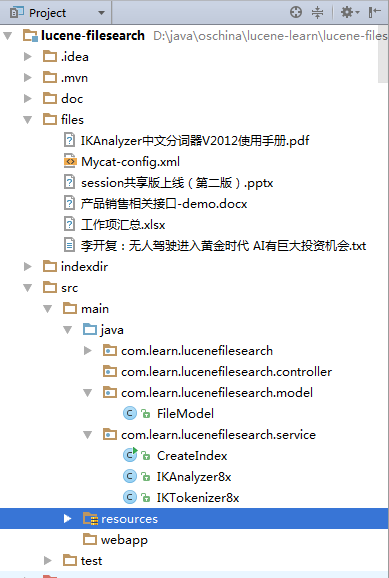
1、先建立model对象
1 | package com.learn.lucenefilesearch.model; |
2、创建索引
将 IKTokenizer8x 和 IKAnalyzer8x 从第2章的工程里复制过来;
1 | package com.learn.lucenefilesearch.service; |