特点:分布式、基于JSON和HTTP接口
4.1.1、Elastic Stack家族
基于 Elasticsearch 衍生出一系列开源软件,统称 Elastic Stack
分布式搜索引擎:Elasticsearch
可视化分析平台:Kibana
日志采集、解析工具:Logstash
数据采集工具:Beats 家族
- Filebeat:收集文件数据,轻量级日志采集工具;
- Metricbeat:搜集 系统、进程、文件系统 级别的 CPU和内存使用情况;
- Packetbeat:收集网络流数据;实时监控 系统应用和服务,将延迟时间、错误、响应、SLA性能等发送到 Logstash或Elasticsearch
- Winlogbeat:收集 windows 事件日志数据;
- Heartbeat:监控服务器运行状态;
Elastic家族配合使用时,版本必须一致;
4.1.3、架构解读
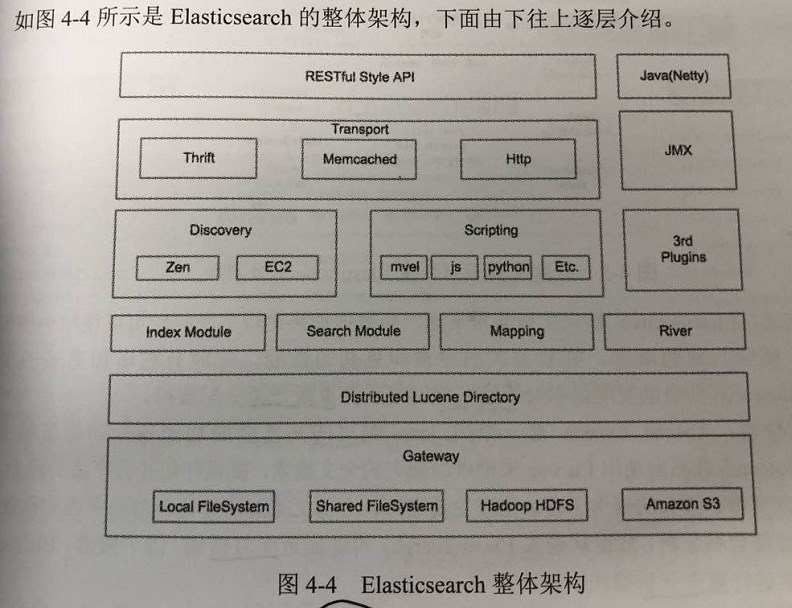
Gateway 存储索引的文件系统:
- Local FileSystem —— 存储在本地文件系统;
- Shared FileSystem —— 共享存储;
- Hadoop HDFS —— 使用 hdfs 分布式存储;
- Amazon S3 —— 存储Amazon S3云服务上;
分布式 Lucene 层,Elasticsearch 的底层 API由 Lucene 提供,每一个ES节点 都有 一个Lucene引擎支持:
- 索引模块
- 搜索模块
- 映射解析模块
- River模块 —— 用来导入第三方数据源,2.X之后已经废弃
Discovery模块 —— Elasticsearch 节点发现,集群内master选举,节点间通信
Scripting模块 —— 支持 JavaScript、Python 等多种语言
第三方插件模块 —— 支持 多种第三方插件;
Transport —— ES传输模块,支持 Thrift,Memcached、HTTP,默认使用 HTTP;
JMX——Java管理框架,用来管理 Elasticsearch 应用;
RESTFull API —— ES提供给用户的接口
4.1.4、优点
- 分布式 —— 灵活的横向扩展,自动识别新节点 并 重新平衡分配数据;
- 全文检索 —— 多语言支持、强大的查询语言、地理位置支持、上下文感知的建议、自动完成和搜索片段;
- 近实时搜索和分析 —— 近实时搜索,也可以 聚合分析;
- 高可用 —— 容错机制,自动发现新节点 和失败节点,重新分配数据,确保集群可用;
- 模式自由 —— 动态 mapping 机制,自动检测 数据结构和类型,创建索引,使数据可搜索;
- RESTFul API —— 任何语言都能访问;
4.1.5、应用场景
1、站内搜索 —— 全文检索功能;
2、NoSQL数据库 —— 读写性能优于 MongoDB;
3、日志分析 —— 经典的ELK日志分析平台;
4.1.6、核心概念
集群 —— 多个节点组成的集群;
节点 —— 一个服务器
索引 —— 拥有 几分相似特征 的 文档的集合;
类型 —— 索引在一个逻辑上的分类 或 分区;
文档 —— JSON格式,被索引的基础信息单元;
分片 —— 一个索引大小 可以超出 单节点硬件限制,一个索引 可以分成多个分片;
分片 水平分割和扩容 你的内存容量;
可以在 主副分片 上 并行查询,提高性能和吞吐量;
副本 —— 分片的 一份或多份拷贝,分为主分片 和 副分片;
