Lucene写文档
主类:IndexWriter
org.apache.lucene.index.IndexWriter
API 调用过程:
1 | IndexWriter.addDocument(): |
1 | SimpleTextStoredFieldsWriter.writeField(); |
1 | public long addDocument(Iterable<? extends IndexableField> doc) { |
1 | private long updateDocument(final DocumentsWriterDeleteQueue.Node<?> delNode, |
org.apache.lucene.index.DocumentsWriter
1 | long updateDocument(final Iterable<? extends IndexableField> doc, |
1 | startStoredFields(docState.docID); // 开始存储Fields数据 |
Lucene删除文档
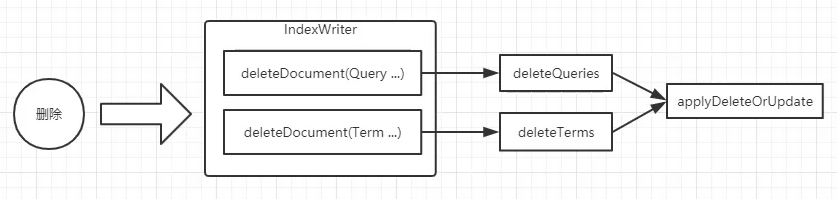
1 | IndexWriter.deleteDocuments(Term... terms); |
1 | package org.apache.lucene.index; |
1 | class DocumentsWriterDeleteQueue { |
1 | // 便于内存控制 |
1 | final class DocumentsWriterFlushQueue { |
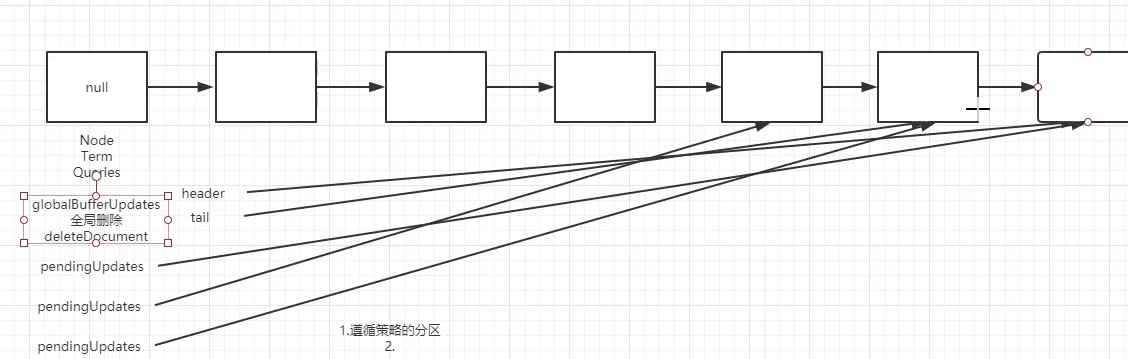
globalBufferUpdates 是全局删除,删除Document
pendingUpdates 是局部删除, 添加或更新Document
局部指向最自己最后的节点, 全局永远指向 整个链表 的 最后一个节点;
Lucene检索过程
查询代码:
1 | public class QueryParseTest { |
查询关键代码:
1 | package org.apache.lucene.search; |
Analysyer 包含两个组件
Tokenizer 分词器(分词 token)
TokenFilter 分词过滤器(大小写转换,词根cats)
Lucene70Codec => 实际去写Term
1 | public class Lucene70Codec extends Codec { |