1、缓存 IO
缓存 I/O 又称 标准 I/O,大都数文件系统的默认 I/O 操作 都是操作缓存 I/O。在Linux的缓存 I/O 机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到 应用程序的地址空间。
读操作:操作系统检查内核的缓存区 有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓冲中。
写操作:将数据从用户空间复制到内核空间的缓冲区中。这时对用户程序来说写操作已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显式调用了sync同步命令(详情操作《【珍藏】linux 同步IO: sync、fsync与fdatasync》)
缓存I/O的优点:① 在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;② 可以减少读盘的次数,从而提高性能;
缓冲I/O的缺点:在缓存 I/O 机制中,DMA方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输,这样,数据在传输过程中需要在应用程序的地址空间(用户空间)和缓存(内核空间)之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的。
2、直接IO
直接 I/O 就是应用程序直接访问磁盘数据,而不经过内核缓冲区,这样做的目的是减少一次内核缓冲区到用户程序缓存的数据复制。比如说 数据库管理系统这类应用,他们更倾向于选择他们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存在的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
直接IO的缺点:如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,这种加载会非常缓慢。通常 直接IO与异步IO结合使用,会得到比较好的性能。
异步IO:当访问数据的线程发出请求后,线程接着去处理其他事,而不是阻塞等待;
下图分析了写场景下的 DirectIO 和 BufferIO:

首先,磁盘IO主要的延时是由(以15000rpm硬盘为例): 机械转动延时(机械磁盘的主要性能瓶颈,平均为2ms) + 寻址延时(2~3ms) + 块传输延时(一般4k每块,40m/s的传输速度,延时一般为0.1ms) 决定。(平均为5ms)
而网络IO主要延时由: 服务器响应延时 + 带宽限制 + 网络延时 + 跳转路由延时 + 本地接收延时 决定。(一般为几十到几千毫秒,受环境干扰极大)
所以两者一般来说网络IO延时要大于磁盘IO的延时。
PIO与DMA
有必要简单的说说慢速I/O设备和内存之间的数据传输方式。
PIO
我们拿磁盘来说,很早以前,磁盘和内存之间的数据传输是需要CPU控制的,也就是说如果我们读取磁盘文件到内存中,数据要经过CPU存储转发,这种方式称为PIO。显然这种方式非常不合理,需要占用大量的CPU时间来读取文件,造成文件访问时系统几乎停止响应。
DMA
后来,DMA(直接内存访问,Direct Memory Access)取代了PIO,它可以不经过CPU而直接进行磁盘和内存的数据交换。在DMA模式下,CPU只需要向DMA控制器下达指令,让DMA控制器来处理数据的传送即可,DMA控制器通过系统总线来传输数据,传送完毕再通知CPU,这样就在很大程度上降低了CPU占有率,大大节省了系统资源,而它的传输速度与PIO的差异其实并不十分明显,因为这主要取决于慢速设备的速度。
可以肯定的是,PIO模式的计算机我们现在已经很少见到了。
标准文件访问方式
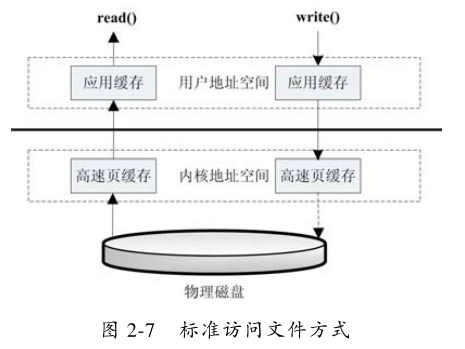
具体步骤:
当应用程序调用read接口时,操作系统检查在内核的高速缓存有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回,如果没有,则从磁盘中读取,然后缓存在操作系统的缓存中。
应用程序调用write接口时,将数据从用户地址空间复制到内核地址空间的缓存中,这时对用户程序来说,写操作已经完成,至于什么时候再写到磁盘中,由操作系统决定,除非显示调用了sync同步命令。

内存映射
减少数据在用户空间和内核空间之间的拷贝操作,适合大量数据传输
Linux内核提供一种访问磁盘文件的特殊方式,它可以将内存中某块地址空间和我们要指定的磁盘文件相关联,从而把我们对这块内存的访问转换为对磁盘文件的访问,这种技术称为内存映射(Memory Mapping)。
操作系统将内存中的某一块区域与磁盘中的文件关联起来,当要访问内存中的一段数据时,转换为访问文件的某一段数据。这种方式的目的同样是减少数据从内核空间缓存到用户空间缓存的数据复制操作,因为这两个空间的数据是共享的。
内存映射是指将硬盘上文件的位置与进程逻辑地址空间中一块大小相同的区域一一对应,当要访问内存中一段数据时,转换为访问文件的某一段数据。这种方式的目的同样是减少数据在用户空间和内核空间之间的拷贝操作。当大量数据需要传输的时候,采用内存映射方式去访问文件会获得比较好的效率。
使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行I/O操作,这意味着在对文件进行处理时将不必再为文件申请并分配缓存,所有的文件缓存操作均由系统直接管理,由于取消了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等步骤,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。


在大多数情况下,使用内存映射可以提高磁盘I/O的性能,它无须使用read()或write()等系统调用来访问文件,而是通过mmap()系统调用来建立内存和磁盘文件的关联,然后像访问内存一样自由地访问文件。
有两种类型的内存映射,共享型和私有型,前者可以将任何对内存的写操作都同步到磁盘文件,而且所有映射同一个文件的进程都共享任意一个进程对映射内存的修改;后者映射的文件只能是只读文件,所以不可以将对内存的写同步到文件,而且多个进程不共享修改。显然,共享型内存映射的效率偏低,因为如果一个文件被很多进程映射,那么每次的修改同步将花费一定的开销。
直接I/O
绕过内核缓冲区,自己管理I/O缓存区
在Linux 2.6中,内存映射和直接访问文件没有本质上差异,因为数据从进程用户态内存空间到磁盘都要经过两次复制,即在磁盘与内核缓冲区之间以及在内核缓冲区与用户态内存空间。
引入内核缓冲区的目的在于提高磁盘文件的访问性能,因为当进程需要读取磁盘文件时,如果文件内容已经在内核缓冲区中,那么就不需要再次访问磁盘;而当进程需要向文件中写入数据时,实际上只是写到了内核缓冲区便告诉进程已经写成功,而真正写入磁盘是通过一定的策略进行延迟的。
然而,对于一些较复杂的应用,比如数据库服务器,它们为了充分提高性能,希望绕过内核缓冲区,由自己在用户态空间实现并管理I/O缓冲区,包括缓存机制和写延迟机制等,以支持独特的查询机制,比如数据库可以根据更加合理的策略来提高查询缓存命中率。另一方面,绕过内核缓冲区也可以减少系统内存的开销,因为内核缓冲区本身就在使用系统内存。
应用程序直接访问磁盘数据,不经过操作系统内核数据缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序缓存的数据复制。这种方式通常是在对数据的缓存管理由应用程序实现的数据库管理系统中。
直接I/O的缺点就是如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘进行加载,这种直接加载会非常缓慢。通常直接I/O跟异步I/O结合使用会得到较好的性能。


Linux提供了对这种需求的支持,即在open()系统调用中增加参数选项O_DIRECT,用它打开的文件便可以绕过内核缓冲区的直接访问,这样便有效避免了CPU和内存的多余时间开销。
顺便提一下,与O_DIRECT类似的一个选项是O_SYNC,后者只对写数据有效,它将写入内核缓冲区的数据立即写入磁盘,将机器故障时数据的丢失减少到最小,但是它仍然要经过内核缓冲区。
sendfile/零拷贝
网络I/O,kafka用到此特性
普通的网络传输步骤如下
1、操作系统将数据从磁盘复制到操作系统内核的页缓存中;
2、应用将数据从内核缓存复制到应用的缓存中;
3、应用将数据写回内核的Socket缓存中;
4、操作系统将数据从Socket缓存区复制到网卡缓存,然后将其通过网络发出;

解析:
1、当调用read系统调用时,通过DMA(Direct Memory Access)将数据copy到内核模式;
2、然后由CPU控制将内核模式数据copy到用户模式下的 buffer中;
3、read调用完成后,write调用首先将用户模式下 buffer中的数据copy到内核模式下的socket buffer中;
4、最后通过DMA copy将内核模式下的socket buffer中的数据copy到网卡设备中传送;
从上面的过程可以看出,数据白白从内核模式到用户模式走了一圈,浪费了两次copy,而这两次copy都是CPU copy,即占用CPU资源;
sendfile

通过sendfile传送文件只需要一次系统调用,当调用sendfile时:
1、首先通过 DMA copy 将数据从磁盘读取到 kernel buffer 中;
2、然后通过 CPU copy 将数据从 kernel buffer 复制到 socket buffer 中;
3、最终通过 DMA copy 将 socket buffer 中的数据复制到 网卡buffer 中;
sendfile与read/write方式相比,少了 一次模式切换一次CPU copy。但是从上述过程中也可以发现从kernel buffer中将数据copy到socket buffer是没必要的。
为此,Linux2.4内核对sendfile做了改进,下图所示:
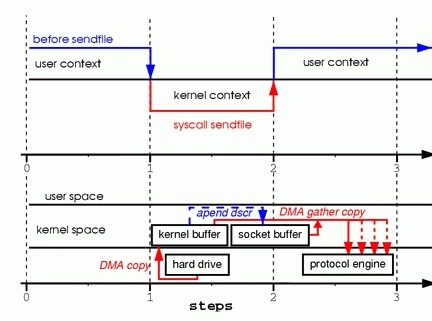
改进后的处理过程如下:
1、DMA copy 将 磁盘数据 复制到 kernel buffer 中;
2、向 socket buffer 中追加当前要发送的数据在 kernel buffer 中的位置和偏移量;
3、DMA gather copy 根据 socket buffer 中的位置和偏移量直接将 kernel buffer 中的数据copy到网卡上;
经过上述过程,数据只经过了2次copy就从磁盘传送出去了。(事实上这个Zero copy是针对内核来讲的,数据在内核模式下是Zero-copy的)。
当前许多高性能http server都引入了sendfile机制,如nginx,lighttpd等。
1 | // Java中的零拷贝 |
Java NIO中FileChannel.transferTo(long position, long count, WriteableByteChannel target)方法将当前通道中的数据传送到目标通道target中,在支持Zero-Copy的linux系统中,transferTo()的实现依赖于 sendfile()调用;


整个数据通路涉及4次数据复制和2个系统调用,如果使用sendfile则可以避免多次数据复制,操作系统可以直接将数据从内核页缓存中复制到网卡缓存,这样可以大大加快整个过程的速度;
大多数时候,我们都在向Web服务器请求静态文件,比如图片、样式表等,根据前面的介绍,我们知道在处理这些请求的过程中,磁盘文件的数据先要经过内核缓冲区,然后到达用户内存空间,因为是不需要任何处理的静态数据,所以它们又被送到网卡对应的内核缓冲区,接着再被送入网卡进行发送。
数据从内核出去,绕了一圈,又回到内核,没有任何变化,看起来真是浪费时间。在Linux 2.4的内核中,尝试性地引入了一个称为khttpd的内核级Web服务器程序,它只处理静态文件的请求。引入它的目的便在于内核希望请求的处理尽量在内核完成,减少内核态的切换以及用户态数据复制的开销。
同时,Linux通过系统调用将这种机制提供给了开发者,那就是sendfile()系统调用。它可以将磁盘文件的特定部分直接传送到代表客户端的socket描述符,加快了静态文件的请求速度,同时也减少了CPU和内存的开销。
在OpenBSD和NetBSD中没有提供对sendfile的支持。通过strace的跟踪看到了Apache在处理151字节的小文件时,使用了mmap()系统调用来实现内存映射,但是在Apache处理较大文件的时候,内存映射会导致较大的内存开销,得不偿失,所以Apache使用了sendfile64()来传送文件,sendfile64()是sendfile()的扩展实现,它在Linux 2.4之后的版本中提供。
这并不意味着sendfile在任何场景下都能发挥显著的作用。对于请求较小的静态文件,sendfile发挥的作用便显得不那么重要,通过压力测试,我们模拟100个并发用户请求151字节的静态文件,是否使用sendfile的吞吐率几乎是相同的,可见在处理小文件请求时,发送数据的环节在整个过程中所占时间的比例相比于大文件请求时要小很多,所以对于这部分的优化效果自然不十分明显。