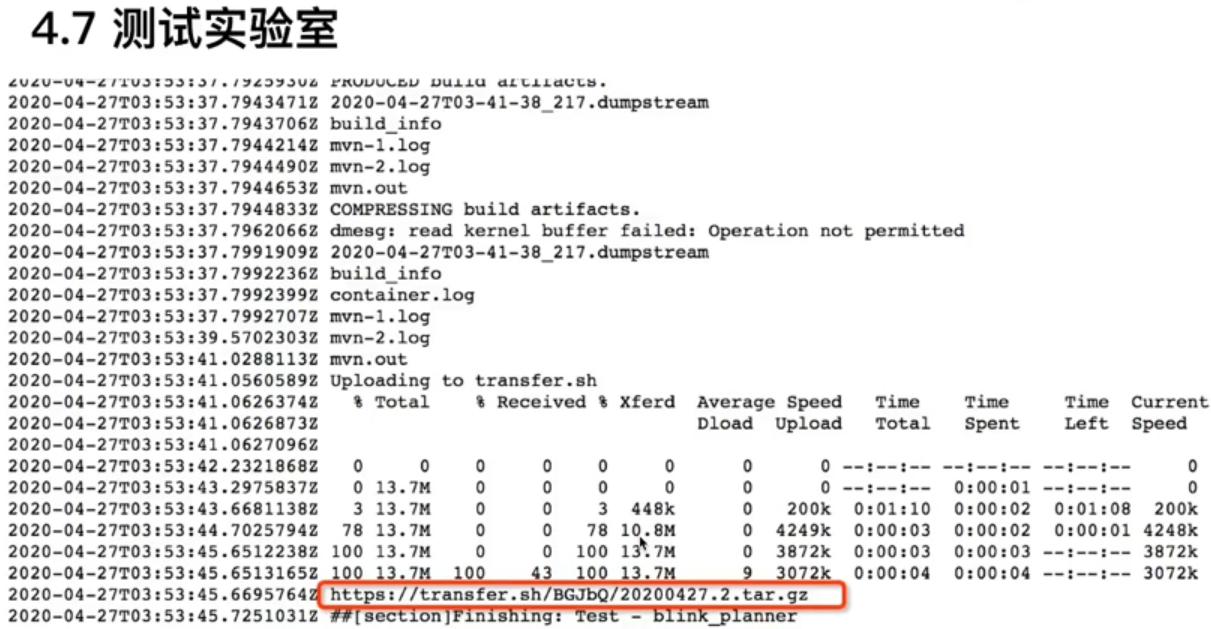
strace 解决 springboot 服务 时通时不通故障
现象
通过http访问springboot服务时,时而正常,时而超时
背景
springboot webflux 开发
centos7
原因分析
1、排除网络问题
1 | tcpdump -n -i eth0 '((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0' and host 172.16.160.12 and host 172.16.247.230 and port 18092 -XX |
使用tcpdump抓包,发现 12:18:14.286806 收到请求,直到 12:40:33.668631 才将结果返回。证明网络链路是通的,但在近20分钟的时间里,服务究竟在干嘛?
1 | 12:18:14.286806 IP 172.16.160.12.50966 > 172.16.247.230.18092: Flags [P.], seq 200172037:200172579, ack 1033672370, win 16652, options [nop,nop,TS val 15683831 ecr 93358138], length 542 |
2、排除ipv4和ipv6双栈问题
只抓ipv4包
1 | tcpdump -nv -i eth0 '((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0' and host 172.16.160.12 and host 172.16.247.230 and port 18092 -XX |
只抓ipv6包
2、 strace查看系统调用
1 | jps -ml |
正常访问如下:
1 | 275 [pid 23135] 13:02:24 futex(0x7f87240f0854, FUTEX_WAIT_BITSET_PRIVATE, 1, {tv_sec=96308, tv_nsec=293387689}, 0xffffffff <unfinished ...> |
访问超时调用如下:
1 | 817 [pid 23147] 13:02:32 <... epoll_wait resumed>[{EPOLLIN, {u32=34, u64=34}}], 4096, -1) = 1 |
涉及线程
23135、23147、23167
1 | printf '%x %x %x \n' 23135 23147 23167 |
EAGAIN (Resource temporarily unavailable)
1 | accept4(34, 0x7f8714bfa220, [128], SOCK_CLOEXEC|SOCK_NONBLOCK) = -1 EAGAIN (Resource temporarily unavailable) |
在linux进行非阻塞的socket接收数据时经常出现Resource temporarily unavailable,errno代码为11(EAGAIN),这是什么意思?
这表明你在非阻塞模式下调用了阻塞操作,在该操作没有完成就返回这个错误,这个错误不会破坏socket的同步,不用管它,下次循环接着recv就可以。对非阻塞socket而言,EAGAIN不是一种错误。在VxWorks和Windows上,EAGAIN的名字叫做EWOULDBLOCK。
另外,如果出现EINTR即errno为4,错误描述Interrupted system call,操作也应该继续。
最后,如果recv的返回值为0,那表明连接已经断开,我们的接收操作也应该结束。
1 | strace -t -fp 23126 2>&1 | egrep 'accept|poll|read|write|connect|send|recv|ctl|sock' |
正常
1 | [root@appweb-docker-002 ~]# strace -t -fp 23126 2>&1 | grep -v 'futex' |
基础知识扫盲
strace命令
strace命令是一个集诊断、调试、统计与一体的工具,我们可以使用strace对应用的系统调用和信号传递的跟踪结果来对应用进行分析,以达到解决问题或者是了解应用工作过程的目的。当然strace与专业的调试工具比如说gdb之类的是没法相比的,因为它不是一个专业的调试器。
strace的最简单的用法就是执行一个指定的命令,在指定的命令结束之后它也就退出了。在命令执行的过程中,strace会记录和解析命令进程的所有系统调用以及这个进程所接收到的所有的信号值。
语法
1 | strace [ -dffhiqrtttTvxx ] [ -acolumn ] [ -eexpr ] ... |
选项
1 | -c 统计每一系统调用的所执行的时间,次数和出错的次数等. |
epoll使用详解
EPOLL 的API用来执行类似poll()的任务。能够用于检测在多个文件描述符中任何IO可用的情况。Epoll API可以用于边缘触发(edge-triggered)和水平触发(level-triggered), 同时epoll可以检测更多的文件描述符。以下的系统调用函数提供了创建和管理epoll实例:
- epoll_create() 可以创建一个epoll实例并返回相应的文件描述符(epoll_create1() 扩展了epoll_create() 的功能)。
- 注册相关的文件描述符使用epoll_ctl()
- epoll_wait() 可以用于等待IO事件。如果当前没有可用的事件,这个函数会阻塞调用线程。
epoll_create 创建epoll
1 | int epoll_create(int size); |
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大。这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
epoll_ctl 设置epoll事件
1 |
|
这个系统调用能够控制给定的文件描述符epfd\指向的epoll实例,op\是添加事件的类型,fd\是目标文件描述符。
有效的op值有以下几种:
- EPOLL_CTL_ADD 在epfd\中注册指定的fd文件描述符并能把event\和fd\关联起来。
- EPOLL_CTL_MOD 改变* fd*和*evetn*之间的联系。
- EPOLL_CTL_DEL 从指定的epfd\中删除fd\文件描述符。在这种模式中event\是被忽略的,并且为可以等于NULL。
event\这个参数是用于关联制定的fd\文件描述符的。它的定义如下:
1 | typedef union epoll_data { |
events\这个参数是一个字节的掩码构成的。下面是可以用的事件:
- EPOLLIN - 当关联的文件可以执行 read ()操作时。
- EPOLLOUT - 当关联的文件可以执行 write ()操作时。
- EPOLLRDHUP - (从 linux 2.6.17 开始)当socket关闭的时候,或者半关闭写段的(当使用边缘触发的时候,这个标识在写一些测试代码去检测关闭的时候特别好用)
- EPOLLPRI - 当 read ()能够读取紧急数据的时候。
- EPOLLERR - 当关联的文件发生错误的时候,epoll_wait() 总是会等待这个事件,并不是需要必须设置的标识。
- EPOLLHUP - 当指定的文件描述符被挂起的时候。epoll_wait() 总是会等待这个事件,并不是需要必须设置的标识。当socket从某一个地方读取数据的时候(管道或者socket),这个事件只是标识出这个已经读取到最后了(EOF)。所有的有效数据已经被读取完毕了,之后任何的读取都会返回0(EOF)。
- EPOLLET - 设置指定的文件描述符模式为边缘触发,默认的模式是水平触发。
- EPOLLONESHOT - (从 linux 2.6.17 开始)设置指定文件描述符为单次模式。这意味着,在设置后只会有一次从epoll_wait() 中捕获到事件,之后你必须要重新调用 epoll_ctl() 重新设置。
返回值:\如果成功,返回0。如果失败,会返回-1, errno\将会被设置
有以下几种错误:
- EBADF - epfd\ 或者 fd\ 是无效的文件描述符。
- EEXIST - op\是EPOLL_CTL_ADD,同时 fd\ 在之前,已经被注册到epoll中了。
- EINVAL - epfd\不是一个epoll描述符。或者fd\和epfd\相同,或者op\参数非法。
- ENOENT - op\是EPOLL_CTL_MOD或者EPOLL_CTL_DEL,但是fd\还没有被注册到epoll上。
- ENOMEM - 内存不足。
- EPERM - 目标的fd\不支持epoll。
epoll_wait 等待epoll事件
1 |
|
epoll_wait 这个系统调用是用来等待epfd\中的事件。events\指向调用者可以使用的事件的内存区域。maxevents\告知内核有多少个events,必须要大于0.
timeout\这个参数是用来制定epoll_wait 会阻塞多少毫秒,会一直阻塞到下面几种情况:
- 一个文件描述符触发了事件。
- 被一个信号处理函数打断,或者timeout超时。
当timeout\等于-1的时候这个函数会无限期的阻塞下去,当timeout\等于0的时候,就算没有任何事件,也会立刻返回。
struct epoll_event 如下定义:
1 | typedef union epoll_data { |
每次epoll_wait() 返回的时候,会包含用户在epoll_ctl中设置的events。
还有一个系统调用epoll_pwait ()。epoll_pwait()和epoll_wait ()的关系就像select()和 pselect()的关系。和pselect()一样,epoll_pwait()可以让应用程序安全的等待知道某一个文件描述符就绪或者捕捉到信号。
下面的 epoll_pwait () 调用:
1 | ready = epoll_pwait(epfd, &events, maxevents, timeout, &sigmask); |
在内部等同于:
1 | pthread_sigmask(SIG_SETMASK, &sigmask, &origmask); |
如果 sigmask\为NULL, epoll_pwait()等同于epoll_wait()。
返回值:\有多少个IO事件已经准备就绪。如果返回0说明没有IO事件就绪,而是timeout超时。遇到错误的时候,会返回-1,并设置 errno。
有以下几种错误:
- EBADF - epfd\是无效的文件描述符
- EFAULT - 指针events\指向的内存没有访问权限
- EINTR - 这个调用被信号打断。
- EINVAL - epfd\不是一个epoll的文件描述符,或者maxevents\小于等于0
关于ET、LT两种工作模式
边缘触发(edge-triggered 简称ET)和水平触发(level-triggered 简称LT):
epoll的事件派发接口可以运行在两种模式下:边缘触发(edge-triggered)和水平触发(level-triggered),两种模式的区别请看下面,我们先假设下面的情况:
- 一个代表管道读取的文件描述符已经注册到epoll实例上了。
- 在管道的写入端写入了2kb的数据。
- epoll_wait 返回一个可用的rfd文件描述符。
- 从管道读取了1kb的数据。
- 调用epoll_wait 完成。
如果rfd被设置了ET,在调用完第五步的epool_wait 后会被挂起,尽管在缓冲区还有可以读取的数据,同时另外一段的管道还在等待发送完毕的反馈。这是因为ET模式下只有文件描述符发生改变的时候,才会派发事件。所以第五步操作,可能会去等待已经存在缓冲区的数据。在上面的例子中,一个事件在第二步被创建,再第三步中被消耗,由于第四步中没有读取完缓冲区,第五步中的epoll_wait可能会一直被阻塞下去。
下面情况下推荐使用ET模式:
- 使用非阻塞的IO。
- epoll_wait() 只需要在read或者write返回的时候。
相比之下,当我们使用LT的时候(默认),epoll会比poll更简单更快速,而且我们可以使用在任何一个地方。
从单体迈向Serverless的避坑指南
简介: 用户需求和云的发展两条线推动了云原生技术的兴起、发展和大规模应用。本文将主要讨论什么是云原生应用,构成云原生应用的要素是什么,什么是Serverless 计算,以及Serverless如何简化技术复杂度,帮助用户应对快速变化的需求,实现弹性、高可用的服务,并通过具体的案例和场景进行说明。
作者 | 不瞋
来源 | 凌云时刻(微信号:linuxpk)
前言
如今,各行各业都在谈数字化转型,尤其是新零售、传媒、交通等行业。数字化的商业形态已经成为主流,逐渐替代了传统的商业形态。在另外一些行业里(如工业制造),虽然企业的商业形态并非以数字化的形式表现,但是在数字孪生理念下,充分利用数据科技进行生产运营优化也正在成为研究热点和行业共识。
企业进行数字化转型,从生产资料、生产关系、战略规划、增长曲线四个层面来看:
- 生产资料:数据成为最重要的生产资料,需求/风险随时变化,企业面临巨大的不确定性。
- 生产关系:数据为中心,非基于流程和规则的固定生产关系。网络效应令生产关系跨越时空限制,多连接方式催生新的业务和物种。
- 战略规划:基于数据决策,快速应对不确定的商业环境。
- 增长曲线:数字化技术带来触达海量用户的能力,可带来突破性的增长。
从云服务商的角度来看云的演进趋势,在Cloud 1.0时代,基础设施的云化是其主题,采用云托管模式,云上云下的应用保持兼容,传统的应用可以直接迁移到云上,这种方式的核心价值在于资源的弹性和成本的低廉;在基础设施提供了海量算力之后,怎么帮助用户更好地利用算力,加速企业创新的速度,就成为云的核心能力。
如果仍在服务器上构建基础应用,那么研发成本就会很高,管理难度也很大,因此有了Cloud 2.0,也就是云原生时代。在云原生时代,云服务商提供了丰富的托管服务,助力企业数字化转型和创新,用户可以像搭积木一样基于各种云服务来构建应用,大大降低了研发成本。
云原生应用要素
云原生应用有三个非常关键的要素:微服务架构,应用容器化和Serverless化,敏捷的软件交付流程。
- 微服务架构
单体架构和微服务架构各有各的特点,其主要特点对比如下图所示。总的来说,单体架构上手快,但是维护难,微服务架构部署较难,但是独立性和敏捷性更好,更适合云原生应用。

- 应用容器化和Serverless化
容器是当前最流行的代码封装方式,借助K8s及其生态的能力,大大降低了整个基础设施的管理难度,而且容器在程序的支撑性方面提供非常出色的灵活性和可移植性,越来越多的用户开始使用容器来封装整个应用。
Serverless计算是另外一种形态,做了大量的端到端整合和云服务的集成,大大提高了研发效率,但是对传统应用的兼容性没有容器那么灵活,但是也带来了很大的整洁性,用户只需要专注于业务逻辑的编码,聚焦于业务逻辑的创新即可。
- 敏捷的应用交付流程
敏捷的应用交付流程是非常重要的一个要素,主要包括流程自动化,专注于功能开发,快速发现问题,快速发布上线。
Serverless 计算
- 阿里云函数计算
Serverless是一个新的概念,但是其内涵早就已经存在。阿里云或者AWS的第一个云服务都是对象存储,对象储存实际上就是一个存储领域的Serverless服务;另外,Serverless指的是一个产品体系,而不是单个产品。当前业界云服务商推出的新功能或者新产品绝大多数都是Serverless形态的。阿里云Serverless产品体系包括计算、存储、API、分析和中间件等,目前云的产品体系正在Serverless化。
阿里云Serverless计算平台函数计算,有4个特点:
- 和云端无缝集成:通过事件驱动的方式将云端的各种服务与函数计算无缝集成,用户只需要关注函数的开发,事件的触发等均由服务商来完成。
- 实时弹性伸缩:由系统自动完成函数计算的弹性伸缩,且速度非常快,用户可以将这种能力用在在线应用上。
- 次秒级计量:次秒级的计量方式提供了一种完全的按需计量方式,资源利用率能达到百分之百。
- 高可用:函数计算平台做了大量工作帮助用户构建高可用的应用。
那么,阿里云函数计算是如何做到以上4点呢?阿里云函数计算的产品能力大图如下图所示,首先函数计算产品是建立在阿里巴巴的基础设施服务之上的产品,对在其之上的计算层进行了大量优化。接着在应用层开发了大量能力和工具,基于以上产品能力,为用户提供多种场景下完整的解决方案,才有了整个优秀的函数计算产品。函数计算是阿里云的一个非常基础的云产品,阿里云的许多产品和功能均是建立在函数计算的基础上。目前阿里云函数计算已经在全球19个区域提供服务。
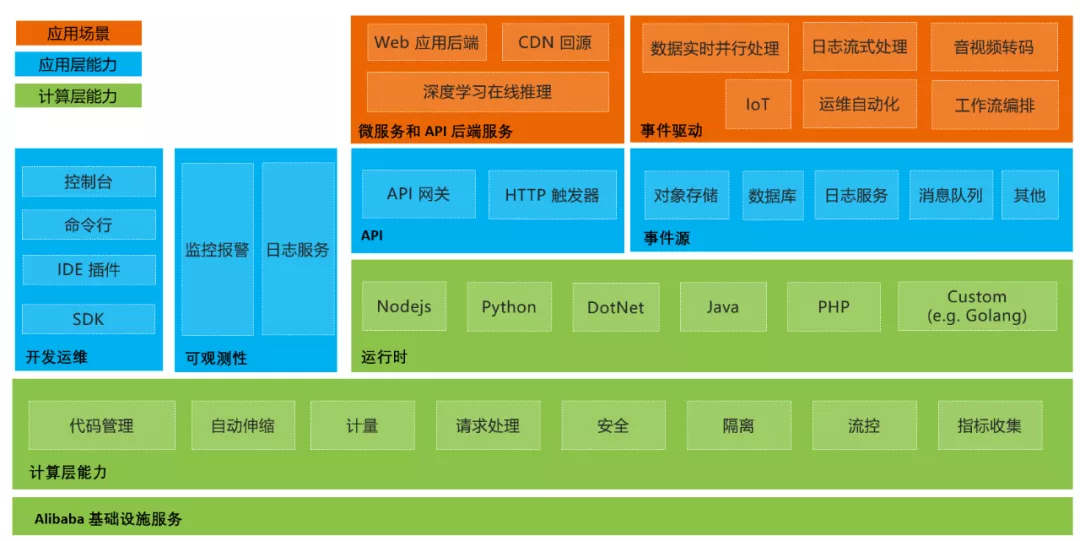
- Serverless帮助用户简化云原生应用高可用设计、实施的复杂度
云原生应用的高可用是一个系统的工程,包括众多方面,完整的高可用体系构建需要很多时间和精力。那么Serverless计算是如何帮助用户简化云原生应用高可用设计、实施的复杂度呢?
如下图所示,高可用体系建设要考虑的点包括基础设施层、运行时层、数据层以及应用层,且每一层都有大量的工作要做才可以实现高可用。函数计算主要是从容错、弹性、流控、监控四方面做了大量工作来实现高可用,下图中蓝色虚线框所对应的功能均由平台来实现,用户是不需要考虑的。蓝色实线框虽然平台做了一些工作来简化用户的工作难度,但是仍需要用户来进行关注,而橘红色的实线框代表需要用户去负责的部分功能。结合平台提供的功能和用户的部分精力投入,可以极大地减轻用户进行高可用体系建设的难度。
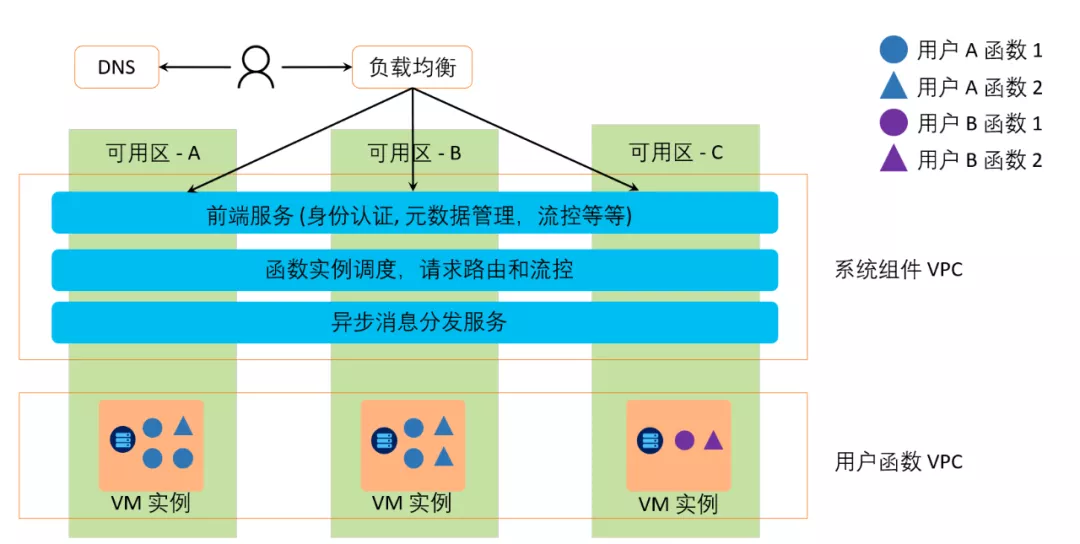
函数计算在很多方面做了优化来帮助用户建设高可用体系。下图展示了函数计算在可用区容灾方面的能力。从图中可知,函数计算做了相应的负载均衡,使得容灾能力大大提升。
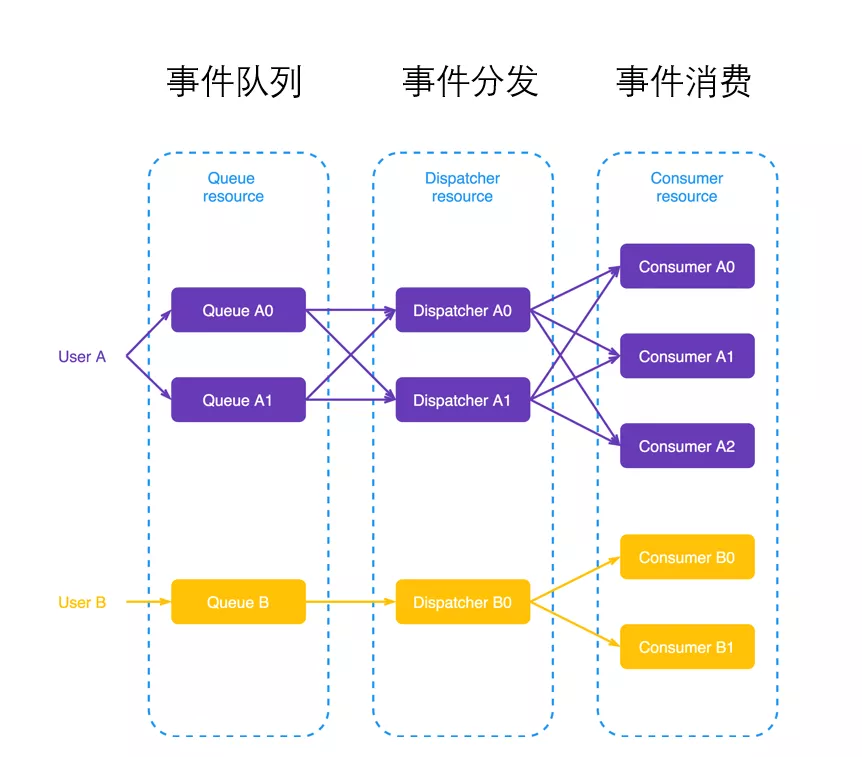
下图展示的是函数计算对事件的异步处理,其处理流水线主要包括事件队列、事件分发、事件消费三个环节,在每一个环节上都可以进行水平伸缩,其中一个比较关键的点是事件的分发需要匹配下游的消费能力。另外,通过为不同函数指定不同数量的计算资源,用户能方便地动态调整不同类型事件的消费速度。此外,还可以自定义错误重试逻辑,并且有背压反馈和流控,不会在短时间内产生大量请求时压垮下一个服务。
在函数计算的可观测性上面,提供了日志收集和查询功能,除了默认的简单日志查询功能外,还提供了高级日志查询,用户可以更方便地进行日志分析。在指标收集和可视化方面,函数计算提供了丰富的指标收集能力,并且提供了标准指标、概览信息等视图,可以更方便用户进行运维工作。
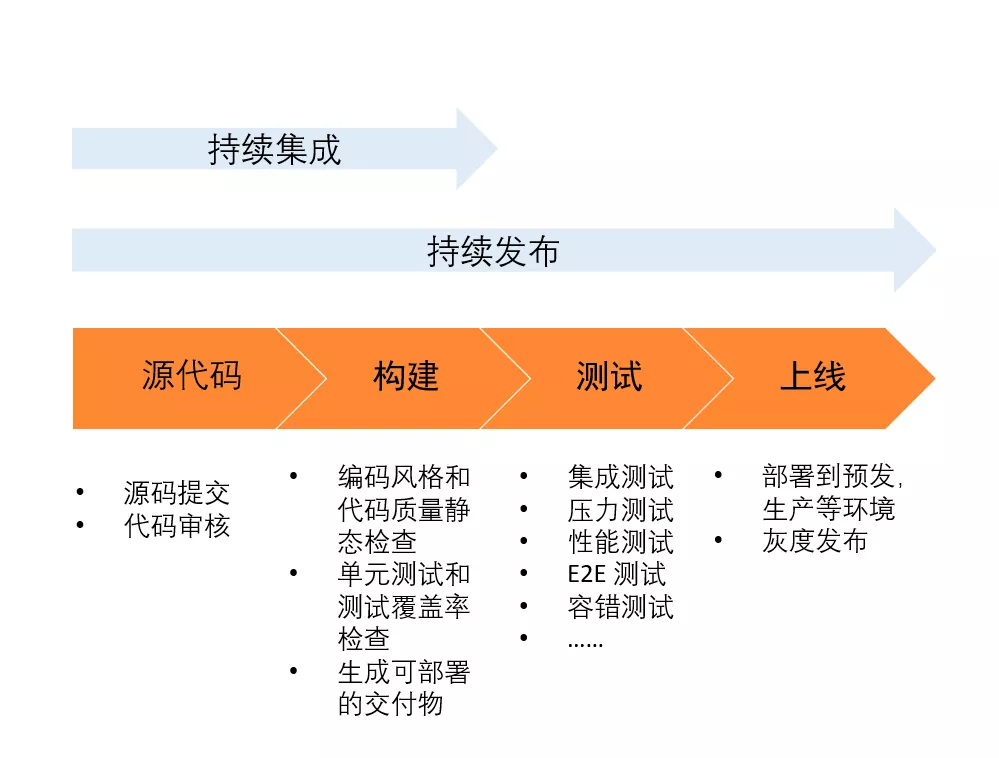
下图是应用交付的一个示意图,在整个应用的交付过程中,只有每个环节都做好,才能够建设一个敏捷的应用交付流程,其核心是自动化,只有做到了自动化,才能提升整个流水线的效率和敏捷度。
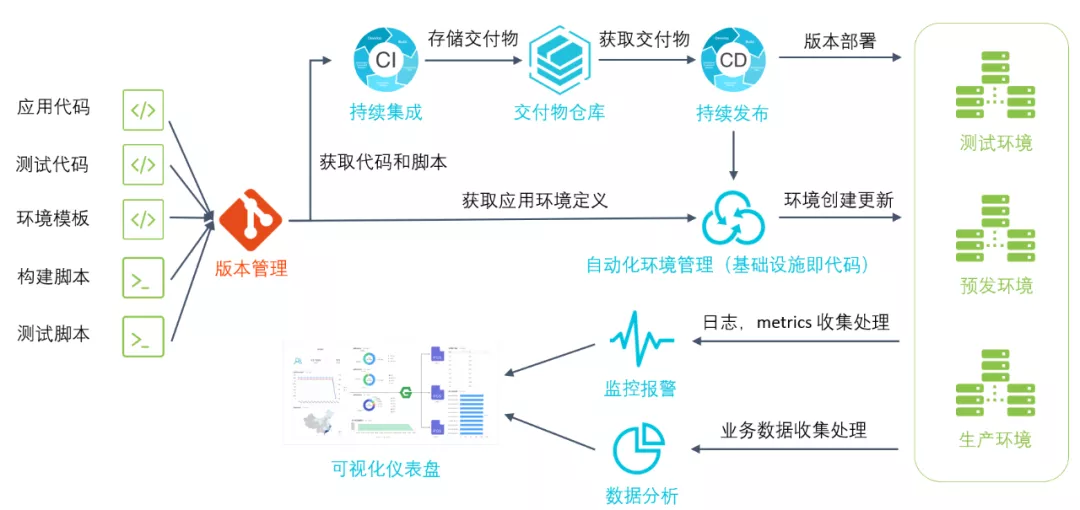
下图展示了自动化应用交付流水线在每个环节的具体任务。其中需要注意的是做到基础设施即代码,才能进行模板定义和自动化设置应用运行环境,进而实现自动化的持续集成等。
做到了应用的自动化交付之后,对整个研发效率的帮助是非常大的。在Serverless应用上,阿里云提供了多种工具来帮助用户实现基础设施即代码。Serverless的模型有一个很好的能力,就是同一份模板可以传入不同的参数,进而生成不同环境的定义,然后通过自动化地管理这些环境。
对于应用本身不同服务版本的交付和灰度发布,函数计算提供了服务版本和服务别名来提供相应的服务,整个应用的灰度发布流程可以简化成一些API的操作,大大提升业务的效率。通过Serverless计算平台提供的这些能力,整个软件应用的交付流水线自动化程度得到了大幅度的提高。
函数计算还有一个很有用的功能——对存量应用的兼容性。通过Custom runtime,能够适配很多的流行框架,兼容传统应用,使其能够很容易地适配到Serverless平台上面,由控制台提供应用的创建、部署、关联资源管理、监控等一系列服务。
除了函数计算,还可以用Serverless工作流对不同的应用环节、不同的函数进行编排,通过描述性的语言去定义工作流,由其可靠地执行每一个步骤,这就大幅度降低用户对于复杂任务的编排难度。
应用场景案例
函数计算有几个典型的应用场景,一个就是Web/API后端服务,阿里云已经有包括石墨文档、微博、世纪华联在内的多个成功应用案例。
函数计算的另外一个应用场景就是大规模的数据并行处理,比如往OSS上面上传大量的图片、音频、文本等数据,可以触发函数做自定义的处理,比如转码、截帧等。这方面的成功案例包括虎扑、分众传媒、百家互联等。
函数计算还有一个应用场景就是数据实时流式处理,比如不同的设备产生的消息、日志发送到消息队列等管道类似的服务中,就可以触发函数来进行流式处理。
最后一个应用场景就是运维的自动化,通过定时触发、云监控事件触发、流程编排等方式调用函数完成运维任务,大大降低运维成本和难度,典型的成功案例有图森未来等。
图森未来是一家专注于L4级别无人驾驶卡车技术研发与应用的人工智能企业,面向全球提供可大规模商业化运营的无人驾驶卡车技术,为全球物流运输行业赋能。在路测过程中会有大量数据产生,而对这些数据的处理流程复杂多变,即使对于同一批数据,不同的业务小组也会有不同的使用及处理方式。如何有效管理不同的数据处理流程、降低人为介入频率能够大幅的提高生产效率。
路测不定时运行的特点使得流程编排任务运行时间点、运行时长具有极大的不确定性,本地机房独自建立流程管理系统难以最大优化机器利用率,造成资源浪费。而图森未来本地已有许多单元化业务处理脚本及应用程序,但因为各种限制而无法全量的迁移上云,这也对如何合理化使用云上服务带来了挑战。
针对上述情况,图森未来开始探索数据处理平台的自动化。阿里云 Serverless 工作流按执行调度的次数计费,具有易用易集成、运维简单等诸多优点,能够很好的解决上述场景中所遇到的问题,非常适合这类不定时运行的离线任务场景。
Serverless 工作流还支持编排本地或自建机房的任务,图森未来通过使用Serverless 工作流原生支持的消息服务MNS解决了云上云下的数据打通问题,使得本地的原有任务得到很好的编排及管理。
除了调度外,Serverless 工作流也支持对任务的状态及执行过程中所产生的数据进行维护。图森未来通过使用任务的输入输出映射及状态汇报机制,高效的管理了流程中各任务的生命周期及相互间的数据传递。
在未来,随着业务规模的扩大,图森未来将持续优化离线大数据处理流程的运行效率及自动化水平。通过各种探索,图森未来将进一步提升工程团队的效率,将更多的精力和资金投入到业务创新中去。
总结
Serverless 工作流是阿里云 Serverless 产品体系中的关键一环。通过 Serverless 工作流,用户能够将函数计算、视觉智能平台等多个阿里云服务,或者自建的服务,以简单直观的方式编排为工作流,迅速构建弹性高可用的云原生应用。
自2017年推出函数计算起,该服务根据应用负载变化实时智能地弹性扩缩容,1分钟完成上万实例的伸缩并保证稳定的延时。目前已经支撑微博、芒果TV、华大基因、图森未来、石墨科技等用户的关键应用,轻松应对业务洪峰。
Flink 1.11 究竟有哪些易用性上的改善?
7月7日,Flink 1.11.0 正式发布了,作为这个版本的 release manager 之一,我想跟大家分享一下其中的经历感受以及一些代表性 feature 的解读。在进入深度解读前,我们先简单了解下社区发布的一般流程,帮助大家更好的理解和参与 Flink 社区的工作。
首先在每个版本的规划初期,会从志愿者中选出 1-2 名作为 Release Manager。1.11.0 版本我作为中国这边的 Release Manager,同时还有一名来自 Ververica 的 Piotr Nowojski 作为德国方的 Release Manager,这在某种程度上也说明中国的开发者和贡献度在整个社区的占比很重要。
接下来会进行这个版本的 Feature Kickoff。在一些大的方向上,社区的规划周期可能比较久,会分阶段、分步骤跨越多个版本完成,确保质量。每个版本的侧重点也会有所不同,比如前两个版本侧重于批处理的加强,而这个版本更侧重于流处理易用性的提升。社区规划的 Feature 列表会在邮件列表中发起讨论,以收集更多的用户/开发者意见和反馈。
一般的开发周期为 2-3 个月时间,提前会明确规划出大概的 Feature Freeze 时间,之后进行 Release Candidate 的发布和测试、以及 Bug Fix。一般经过几轮的迭代周期后会正式投票通过一个相对稳定的 Candidate 版本,然后基于这个版本正式发布。
Flink 1.11.0 从 3 月初的功能规划到 7 月初的正式发布,历经了差不多 4 个月的时间,对 Flink 的生态、易用性、生产可用性、稳定性等方面都进行了增强和改善,下面将一一跟大家分享。
一、综述
Flink 1.11.0 从 Feature 冻结后发布了 4 次 Candidate 才最终通过。经统计,一共有 236 个贡献者参与了这次版本开发,解决了 1474 个 Jira 问题,涉及 30 多个 FLIP,提交了 2325 个 Commit。
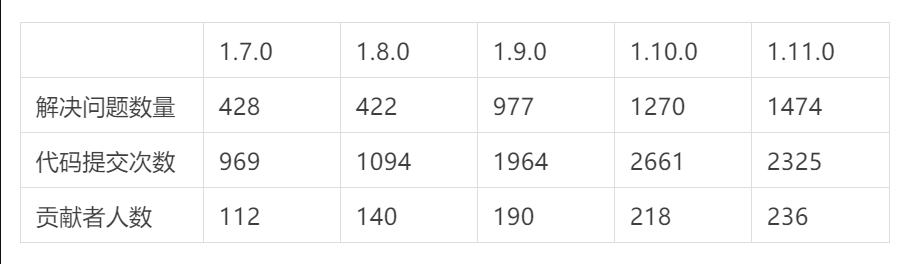
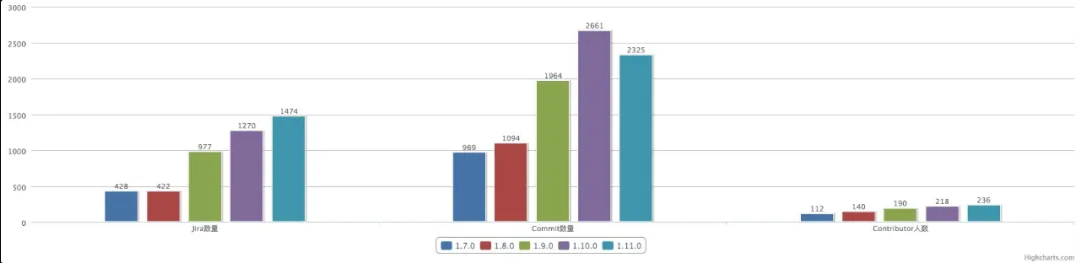
纵观近五次版本发布,可以看出从 1.9.0 开始 Flink 进入了一个快速发展阶段,各个维度指标相比之前都有了几乎翻倍的提高。也是从 1.9.0 开始阿里巴巴内部的 Blink 项目开始被开源 Flink 整合,到 1.10.0 经过两个大版本已经全部整合完毕,对 Flink 从生态建设、功能性、性能和生产稳定性上都有了大幅的增强。
Flink 1.11.0 版本的最初定位是重点解决易用性问题,提升用户业务的生产使用体验,整体上不做大的架构调整和功能开发,倾向于快速迭代的小版本开发。但是从上面统计的各个指标来看,所谓的“小版本”在各个维度的数据也丝毫不逊色于前两个大版本,解决问题的数量和参与的贡献者人数也在持续增加,其中来自中国的贡献者比例达到 62%。
下面我们会深度剖析 Flink 1.11.0 带来了哪些让大家期待已久的特性,从用户直接使用的 API 层一直到执行引擎层,我们都会选择一些有代表性的 Feature 从不同维度解读,更完整的 Feature 列表请大家关注发布的 Release Blog。
二、生态完善和易用性提升
这两个维度在某种程度上是相辅相成的,很难严格区分开,生态兼容上的缺失常常造成使用上的不便,提升易用性的过程往往也是不断完善相关生态的过程。在这方面用户感知最明显的应该就是 Table & SQL API 层面的使用。
1、Table & SQL 支持 Change Data Capture(CDC)
CDC 被广泛使用在复制数据、更新缓存、微服务间同步数据、审计日志等场景,很多公司都在使用开源的 CDC 工具,如 MySQL CDC。通过 Flink 支持在 Table & SQL 中接入和解析 CDC 是一个强需求,在过往的很多讨论中都被提及过,可以帮助用户以实时的方式处理 Changelog 流,进一步扩展 Flink 的应用场景,例如把 MySQL 中的数据同步到 PG 或 ElasticSearch 中,低延时的 Temporal Join 一个 Changelog 等。
除了考虑到上面的真实需求,Flink 中定义的“Dynamic Table”概念在流上有两种模型:Append 模式和 Update 模式。通过 Append 模式把流转化为“Dynamic Table”在之前的版本中已经支持,因此在 1.11.0 中进一步支持 Update 模式也从概念层面完整的实现了“Dynamic Table”。
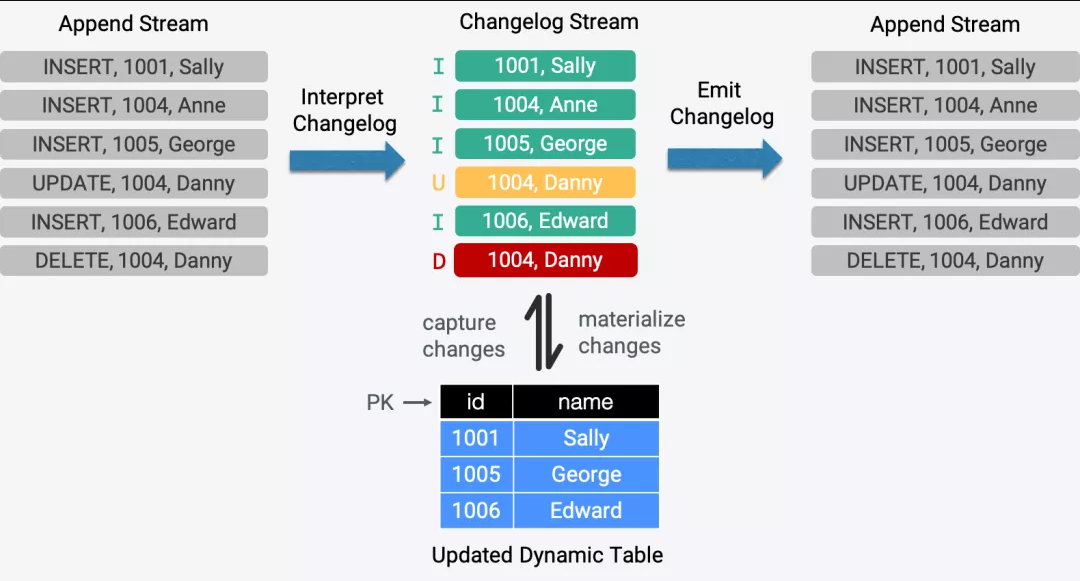
为了支持解析和输出 Changelog,如何在外部系统和 Flink 系统之间编解码这些更新操作是首要解决的问题。考虑到 Source 和 Sink 是衔接外部系统的一个桥梁,因此 FLIP-95 在定义全新的 Table Source 和 Table Sink 接口时解决了这个问题。
在公开的 CDC 调研报告中,Debezium 和 Canal 是用户中最流行使用的 CDC 工具,这两种工具用来同步 Changelog 到其它的系统中,如消息队列。据此,FLIP-105 首先支持了 Debezium 和 Canal 这两种格式,而且 Kafka Source 也已经可以支持解析上述格式并输出更新事件,在后续的版本中会进一步支持 Avro(Debezium) 和 Protobuf(Canal)。
1 | CREATE TABLE my_table ( |
2 、Table & SQL 支持 JDBC Catalog
1.11.0 之前,用户如果依赖 Flink 的 Source/Sink 读写关系型数据库或读取 Changelog 时,必须要手动创建对应的 Schema。而且当数据库中的 Schema 发生变化时,也需要手动更新对应的 Flink 作业以保持一致和类型匹配,任何不匹配都会造成运行时报错使作业失败。用户经常抱怨这个看似冗余且繁琐的流程,体验极差。
实际上对于任何和 Flink 连接的外部系统都可能有类似的上述问题,在 1.11.0 中重点解决了和关系型数据库对接的这个问题。FLIP-93 提供了 JDBC catalog 的基础接口以及 Postgres catalog 的实现,这样方便后续实现与其它类型的关系型数据库的对接。
1.11.0 版本后,用户使用 Flink SQL 时可以自动获取表的 Schema 而不再需要输入 DDL。除此之外,任何 Schema 不匹配的错误都会在编译阶段提前进行检查报错,避免了之前运行时报错造成的作业失败。这是提升易用性和用户体验的一个典型例子。
3、Hive 实时数仓
从 1.9.0 版本开始 Flink 从生态角度致力于集成 Hive,目标打造批流一体的 Hive 数仓。经过前两个版本的迭代,已经达到了 Batch 兼容且生产可用,在 TPC-DS 10T Benchmark 下性能达到 Hive 3.0 的 7 倍以上。
1.11.0 在 Hive 生态中重点实现了实时数仓方案,改善了端到端流式 ETL 的用户体验,达到了批流一体 Hive 数仓的目标。同时在兼容性、性能、易用性方面也进一步进行了加强。
在实时数仓的解决方案中,凭借 Flink 的流式处理优势做到实时读写 Hive:
Hive 写入:FLIP-115 完善扩展了 FileSystem Connector 的基础能力和实现,Table/SQL 层的 sink 可以支持各种格式(CSV、Json、Avro、Parquet、ORC),而且支持 Hive Table 的所有格式。
Partition 支持:数据导入 Hive 引入 Partition 提交机制来控制可见性,通过sink.partition-commit.trigger 控制 Partition 提交的时机,通过 sink.partition-commit.policy.kind 选择提交策略,支持 SUCCESS 文件和 Metastore 提交。
Hive 读取:实时化的流式读取 Hive,通过监控 Partition 生成增量读取新 Partition,或者监控文件夹内新文件生成来增量读取新文件。
在 Hive 可用性方面的提升:
FLIP-123 通过 Hive Dialect 为用户提供语法兼容,这样用户无需在 Flink 和 Hive 的 CLI 之间切换,可以直接迁移 Hive 脚本到 Flink 中执行。
提供 Hive 相关依赖的内置支持,避免用户自己下载所需的相关依赖。现在只需要单独下载一个包,配置 HADOOP_CLASSPATH 就可以运行。
在 Hive 性能方面,1.10.0 中已经支持了 ORC(Hive 2+)的向量化读取,1.11.0 中我们补全了所有版本的 Parquet 和 ORC 向量化支持来提升性能。
4、全新 Source API
前面也提到过,Source 和 Sink 是 Flink 对接外部系统的一个桥梁,对于完善生态、可用性及端到端的用户体验是很重要的环节。社区早在一年前就已经规划了 Source 端的彻底重构,从 FLIP-27 的 ID 就可以看出是很早的一个 Feature。但是由于涉及到很多复杂的内部机制和考虑到各种 Source Connector 的实现,设计上需要考虑的很全面。从 1.10.0 就开始做 POC 的实现,最终赶上了 1.11.0 版本的发布。
先简要回顾下 Source 之前的主要问题:
对用户而言,在 Flink 中改造已有的 Source 或者重新实现一个生产级的 Source Connector 不是一件容易的事情,具体体现在没有公共的代码可以复用,而且需要理解很多 Flink 内部细节以及实现具体的 Event Time 分配、Watermark 产出、Idleness 监测、线程模型等。
批和流的场景需要实现不同的 Source。
Partitions/Splits/Shards 概念在接口中没有显式表达,比如 Split 的发现逻辑和数据消费都耦合在 Source Sunction 的实现中,这样在实现 Kafka 或 Kinesis 类型的 Source 时增加了复杂性。
在 Runtime 执行层,Checkpoint 锁被 Source Function 抢占会带来一系列问题,框架很难进行优化。
FLIP-27 在设计时充分考虑了上述的痛点:
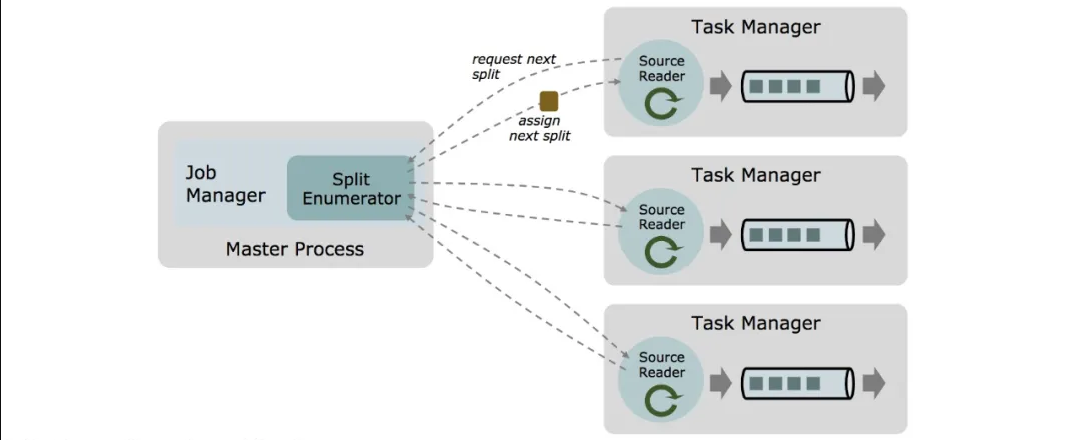
首先在 Job Manager 和 Task Manager 中分别引入两种不同的组件 Split Enumerator 和 Source Reader,解耦 Split 发现和对应的消费处理,同时方便随意组合不同的策略。比如现有的 Kafka Connector 中有多种不同的 Partition 发现策略和实现耦合在一起,在新的架构下,我们只需要实现一种 Source Reader,就可以适配多种 Split Enumerator 的实现来对应不同的 Partition 发现策略。
在新架构下实现的 Source Connector 可以做到批流统一,唯一的小区别是对批场景的有限输入,Split Enumerator 会产出固定数量的 Split 集合并且每个 Split 都是有限数据集;对于流场景的无限输入,Split Enumerator 要么产出无限多的 Split 或者 Split 自身是无限数据集。
复杂的 Timestamp Assigner 以及 Watermark Generator 透明的内置在 Source Reader 模块内运行,对用户来说是无感知的。这样用户如果想实现新的 Source Connector,一般不再需要重复实现这部分功能。
目前 Flink 已有的 Source Connector 会在后续的版本中基于新架构来重新实现,Legacy Source 也会继续维护几个版本保持兼容性,用户也可以按照 Release 文档中的说明来尝试体验新 Source 的开发。
5、PyFlink 生态
众所周知,Python 语言在机器学习和数据分析领域有着广泛的使用。Flink 从 1.9.0 版本开始发力兼容 Python 生态,Python 和 Flink 合力为 PyFlink,把 Flink 的实时分布式处理能力输出给 Python 用户。前两个版本 PyFlink 已经支持了 Python Table API 和 UDF,在 1.11.0 中扩大对 Python 生态库 Pandas 的支持以及和 SQL DDL/Client 的集成,同时 Python UDF 性能有了极大的提升。
具体来说,之前普通的 Python UDF 每次调用只能处理一条数据,而且在 Java 端和 Python 端都需要序列化/反序列化,开销很大。1.11.0 中 Flink 支持在 Table & SQL 作业中自定义和使用向量化 Python UDF,用户只需要在 UDF 修饰中额外增加一个参数 udf_type=“pandas” 即可。这样带来的好处是:
每次调用可以处理 N 条数据。
数据格式基于 Apache Arrow,大大降低了 Java、Python 进程之间的序列化/反序列化开销。
方便 Python 用户基于 Numpy 和 Pandas 等数据分析领域常用的 Python 库,开发高性能的 Python UDF。
除此之外,1.11.0 中 PyFlink 还支持:
PyFlink table 和 Pandas DataFrame 之间无缝切换(FLIP-120),增强 Pandas 生态的易用性和兼容性。
Table & SQL 中可以定义和使用 Python UDTF(FLINK-14500),不再必需 Java/Scala UDTF。
Cython 优化 Python UDF 的性能(FLIP-121),对比 1.10.0 可以提升 30 倍。
Python UDF 中用户自定义 Metric(FLIP-112),方便监控和调试 UDF 的执行。
上述解读的都是侧重 API 层面,用户开发作业可以直接感知到的易用性的提升。下面我们看看执行引擎层在 1.11.0 中都有哪些值得关注的变化。
三、生产可用性和稳定性提升
1、支持 Application 模式和 Kubernetes 增强
1.11.0 版本前,Flink 主要支持如下两种模式运行:
Session 模式:提前启动一个集群,所有作业都共享这个集群的资源运行。优势是避免每个作业单独启动集群带来的额外开销,缺点是隔离性稍差。如果一个作业把某个 Task Manager(TM)容器搞挂,会导致这个容器内的所有作业都跟着重启。虽然每个作业有自己独立的 Job Manager(JM)来管理,但是这些 JM 都运行在一个进程中,容易带来负载上的瓶颈。
Per-job 模式:为了解决 Session 模式隔离性差的问题,每个作业根据资源需求启动独立的集群,每个作业的 JM 也是运行在独立的进程中,负载相对小很多。
以上两种模式的共同问题是需要在客户端执行用户代码,编译生成对应的 Job Graph 提交到集群运行。在这个过程需要下载相关 Jar 包并上传到集群,客户端和网络负载压力容易成为瓶颈,尤其当一个客户端被多个用户共享使用。
1.11.0 中引入了 Application 模式(FLIP-85)来解决上述问题,按照 Application 粒度来启动一个集群,属于这个 Application 的所有 Job 在这个集群中运行。核心是 Job Graph 的生成以及作业的提交不在客户端执行,而是转移到 JM 端执行,这样网络下载上传的负载也会分散到集群中,不再有上述 Client 单点上的瓶颈。
用户可以通过 bin/flink run-application 来使用 Application 模式,目前 Yarn 和 Kubernetes(K8s)都已经支持这种模式。Yarn application 会在客户端将运行作业需要的依赖都通过 Yarn Local Resource 传递到 JM。K8s Application 允许用户构建包含用户 Jar 与依赖的镜像,同时会根据作业自动创建 TM,并在结束后销毁整个集群,相比 Session 模式具有更好的隔离性。K8s 不再有严格意义上的 Per-Job 模式,Application 模式相当于 Per-Job 在集群进行提交作业的实现。
除了支持 Application 模式,Flink 原生 K8s 在 1.11.0 中还完善了很多基础的功能特性(FLINK-14460),以达到生产可用性的标准。例如 Node Selector、Label、Annotation、Toleration 等。为了更方便的与 Hadoop 集成,也支持根据环境变量自动挂载 Hadoop 配置的功能。
2、Checkpoint & Savepoint 优化
Checkpoint 和 Savepoint 机制一直是 Flink 保持先进性的核心竞争力之一,社区在这个领域的改动很谨慎,最近的几个大版本中几乎没有大的功能和架构上的调整。在用户邮件列表中,我们经常能看到用户反馈和抱怨的相关问题:比如 Checkpoint 长时间做不出来失败,Savepoint 在作业重启后不可用等等。1.11.0 有选择的解决了一些这方面的常见问题,提高生产可用性和稳定性。
1.11.0 之前, Savepoint 中 Meta 数据和 State 数据分别保存在两个不同的目录中,这样如果想迁移 State 目录很难识别这种映射关系,也可能导致目录被误删除,对于目录清理也同样有麻烦。1.11.0 把两部分数据整合到一个目录下,这样方便整体转移和复用。另外,之前 Meta 引用 State 采用的是绝对路径,这样 State 目录迁移后路径发生变化也不可用,1.11.0 把 State 引用改成了相对路径解决了这个问题(FLINK-5763),这样 Savepoint 的管理维护、复用更加灵活方便。
实际生产环境中,用户经常遭遇 Checkpoint 超时失败、长时间不能完成带来的困扰。一旦作业 failover 会造成回放大量的历史数据,作业长时间没有进度,端到端的延迟增加。1.11.0 从不同维度对 Checkpoint 的优化和提速做了改进,目标实现分钟甚至秒级的轻量型 Checkpoint。
首先,增加了 Checkpoint Coordinator 通知 Task 取消 Checkpoint 的机制(FLINK-8871),这样避免 Task 端还在执行已经取消的 Checkpoint 而对系统带来不必要的压力。同时 Task 端放弃已经取消的 Checkpoint,可以更快的参与执行 Coordinator 新触发的 Checkpoint,某种程度上也可以避免新 Checkpoint 再次执行超时而失败。这个优化也对后面默认开启 Local Recovery 提供了便利,Task 端可以及时清理失效 Checkpoint 的资源。
其次,在反压场景下,整个数据链路堆积了大量 Buffer,导致 Checkpoint Barrier 排在数据 Buffer 后面,不能被 Task 及时处理对齐,也就导致了 Checkpoint 长时间不能执行。1.11.0 中从两个维度对这个问题进行解决:
1)尝试减少数据链路中的 Buffer 总量(FLINK-16428),这样 Checkpoint Barrier 可以尽快被处理对齐。
上游输出端控制单个 Sub Partition 堆积 Buffer 的最大阈值(Backlog),避免负载不均场景下单个链路上堆积大量 Buffer。
在不影响网络吞吐性能的情况下合理修改上下游默认的 Buffer 配置。
上下游数据传输的基础协议进行了调整,允许单个数据链路可以配置 0 个独占 Buffer 而不死锁,这样总的 Buffer 数量和作业并发规模解耦。根据实际需求在吞吐性能和 Checkpoint 速度两者之间权衡,自定义 Buffer 配比。
这个优化有一部分工作已经在 1.11.0 中完成,剩余部分会在下个版本继续推进完成。
2)实现了全新的 Unaligned Checkpoint 机制(FLIP-76)从根本上解决了反压场景下 Checkpoint Barrier 对齐的问题。实际上这个想法早在 1.10.0 版本之前就开始酝酿设计,由于涉及到很多模块的大改动,实现机制和线程模型也很复杂。我们实现了两种不同方案的原型 POC 进行了测试、性能对比,确定了最终的方案,因此直到 1.11.0 才完成了 MVP 版本,这也是 1.11.0 中执行引擎层唯一的一个重量级 Feature。其基本思想可以概括为:
Checkpoint Barrier 跨数据 Buffer 传输,不在输入输出队列排队等待处理,这样就和算子的计算能力解耦,Barrier 在节点之间的传输只有网络延时,可以忽略不计。
每个算子多个输入链路之间不需要等待 Barrier 对齐来执行 Checkpoint,第一个到的 Barrier 就可以提前触发 Checkpoint,这样可以进一步提速 Checkpoint,不会因为个别链路的延迟而影响整体。
为了和之前 Aligned Checkpoint 的语义保持一致,所有未被处理的输入输出数据 Buffer 都将作为 Channel State 在 Checkpoint 执行时进行快照持久化,在 Failover 时连同 Operator State 一同进行恢复。换句话说,Aligned 机制保证的是 Barrier 前面所有数据必须被处理完,状态实时体现到 Operator State 中;而 Unaligned 机制把 Barrier 前面的未处理数据所反映的 Operator State 延后到 Failover Restart 时通过 Channel State 回放进行体现,从状态恢复的角度来说最终都是一致的。注意这里虽然引入了额外的 In-Flight Buffer 的持久化,但是这个过程实际是在 Checkpoint 的异步阶段完成的,同步阶段只是进行了轻量级的 Buffer 引用,所以不会过多占用算子的计算时间而影响吞吐性能。

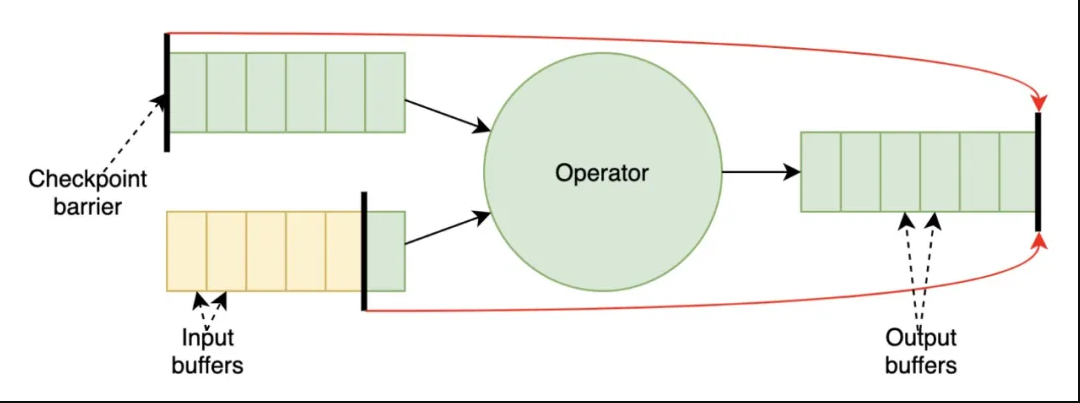
Unaligned Checkpoint 在反压严重的场景下可以明显加速 Checkpoint 的完成时间,因为它不再依赖于整体的计算吞吐能力,而和系统的存储性能更加相关,相当于计算和存储的解耦。但是它的使用也有一定的局限性,它会增加整体 State 的大小,对存储 IO 带来额外的开销,因此在 IO 已经是瓶颈的场景下就不太适合使用 Unaligned Checkpoint 机制。
1.11.0 中 Unaligned Checkpoint 还没有作为默认模式,需要用户手动配置来开启,并且只在 Exactly-Once 模式下生效。但目前还不支持 Savepoint 模式,因为 Savepoint 涉及到作业的 Rescale 场景,Channel State 目前还不支持 State 拆分,在后面的版本会进一步支持,所以 Savepoint 目前还是会使用之前的 Aligned 模式,在反压场景下有可能需要很长时间才能完成。
四、总结
Flink 1.11.0 版本的开发过程中,我们看到越来越多来自中国的贡献者参与到核心功能的开发中,见证了 Flink 在中国的生态发展越来越繁荣,比如来自腾讯公司的贡献者参与了 K8s、Checkpoint 等功能开发,来自字节跳动公司的贡献者参与了 Table & SQL 层以及引擎网络层的一些开发。希望更多的公司能够参与到 Flink 开源社区中,分享在不同领域的经验,使 Flink 开源技术一直保持先进性,能够普惠到更多的受众。
经过 1.11.0 “小版本”的短暂调整,Flink 正在酝酿下一个大版本的 Feature,相信一定会有很多重量级的特性登场,让我们拭目以待!
Flink 年度学习资料大礼包
Flink 年度学习资料大礼包!
大数据实时计算及 Apache Flink 年度Flink 年度学习资料大礼包,300+页实战应用精华总结!
- 零基础入门,30 天成长为 Flink 大神的经典教程。
- Apache Flink 核心贡献者及阿里巴巴技术专家的一线实战经验总结。
- 收录来自 bilibili、美团点评、小米、OPPO、快手、Lyft、Netflix 等国内外一线大厂实时计算平台及实时数仓最佳实践案例。
点击免费下载:
《零基础入门:从 0 到 1 学会 Apache Flink》
为什么要学习 Flink?
面对全量数据和增量数据,能否用一套统一的大数据引擎技术来处理?
Apache Flink 被业界公认为最好的流计算引擎,其计算能力不仅仅局限于做流处理,而是一套兼具流、批、机器学习等多种计算功能的大数据引擎,用户只需根据业务逻辑开发一套代码,无论是全量数据还是增量数据,亦或者实时处理,一套方案即可全部支持。为了让大家更全面地了解 Apache Flink 背后的技术以及应用实践,Flink 社区推出年度学习资料大礼包!马上下载,越早学习,越能抓住时代先机!
《零基础入门:从 0 到 1 学会 Apache Flink》
Apache Flink 零基础入门系列教程重磅发布!由多位 Flink PMC 及核心贡献者出品,帮你建立系统框架体系,最详细的免费教程,Flink 入门必读经典!
点击免费下载
《零基础入门:从 0 到 1 学会 Apache Flink》>>>
课程亮点
- 实现从0到1了解 Flink 建立 Flink 的系统框架体系,为大数据引擎学习打下基础。
- 通过实际案例,带你快速上手 Flink 这个分布式、高性能、高可用、高精确的为数据流应用而生的开源流式处理框架,带你领略计算之美。
- 课程内容侧重于原理解析与基础应用,通过对Flink流计算的概念、技术原理、实践操作等详细解析,从最实际的应用场景出发引导你深入了解Flink,帮助你从 Flink 小白成长为 Flink 技术专家。
课程目录
- Apache Flink 进阶(一):Runtime 核心机制剖析
- Apache Flink 进阶(二):时间属性深度解析
- Apache Flink 进阶(三):Checkpoint 原理剖析与应用实践
- Apache Flink 进阶(四):Flink on Yarn/K8s 原理剖析及实践
- Apache Flink 进阶(五):数据类型和序列化
- Apache Flink 进阶(六):Flink 作业执行深度解析
- Apache Flink 进阶(七):网络流控及反压剖析
- Apache Flink 进阶(八):详解 Metrics 原理与实战
- Apache Flink 进阶(九):Flink Connector 开发
- Apache Flink 进阶(十):Flink State 最佳实践
- Apache Flink 进阶(十一):TensorFlow On Flink
- Apache Flink 进阶(十二):深度探索 Flink SQL
- Apache Flink 进阶(十三):Python API 应用实践

《Apache Flink 十大技术难点实战》
Apache Flink 核心贡献者及阿里巴巴技术专家总结 Flink 生产环境应用的十大常见难点,10 篇技术实战文章帮你完成故障识别、问题定位、性能优化等全链路过程,实现从基础概念的准确理解到上手实操的精准熟练,从容应对生产环境中的技术难题!
点击免费下载
《Apache Flink 十大技术难点实战》>>>
目录
- 深度解读 |102万行代码,1270个问题,Flink 1.10 发布了什么?
- 从开发到生产上线,如何确定集群规划大小?
- Demo:基于 Flink SQL 构建流式应用
- Flink Checkpoint 问题排查实用指南
- 如何分析及处理 Flink 反压?
- Flink on YARN(上):一张图轻松掌握基础架构与启动流程
- Flink on YARN(下):常见问题与排查思路
- Apache Flink与Apache Hive的集成
- Flink Batch SQL 1.10 实践
- 如何在 PyFlink 1.10 中自定义 Python UDF?
- Flink 1.10 Native Kubernetes 原理与实践

在大数据的日常场景中,从数据生产者,到数据收集、数据处理、数据应用(BI+AI),整个大数据 + AI 全栈的每个环节,Flink 均可应用于其中。作为新一代开源大数据计算引擎,Flink 不仅满足了工业界对实时性的需求,还能够打通端到端的数据价值挖掘全链路。
《Apache Flink 年度最佳实践》
首次一次性公布来自 bilibili、美团点评、小米、快手、菜鸟、Lyft、Netflix 等精彩内容,9 篇深度文章揭秘一线大厂实时计算平台从无到有到有、持续优化的详细细节!不容错过的精品电子书,大数据工程师必读实战“真经”!
点击免费下载
《Apache Flink 年度最佳实践》>>>
目录
- 仅1年GitHub Star数翻倍,Apache Flink 做了什么?
- Lyft基于Apache Flink的大规模准实时数据分析平台
- Apache Flink在快手实时多维分析场景的应用
- Bilibili基于Apache Flink的平台化探索与实践
- 美团点评基于 Apache Flink 的实时数仓平台实践
- 小米流式平台架构演进与实践
- Netflix:Evolving Keystone to an Open Collaborative Real-time ETL Platform
- OPPO 基于 Apache Flink 的实时数仓实践
- 菜鸟供应链实时数仓的架构演进及应用场景

从媒体的最新资讯推送,到购物狂欢的实时数据大屏,甚至城市级计算的工业大脑,实时计算已经应用到了多个生活、工作场景,随着业务的快速增长,企业对大数据处理的需求越来越高,Flink的应用也越来越广泛,相信在不久的将来,Flink将会成为各行业不同规模企业主流的大数据处理框架,并最终成为下一代大数据处理框架的标准。越早学习,越能抓住时代先机。
阿里云开发者社区——藏经阁系列电子书,汇聚了一线大厂的技术沉淀精华,爆款不断。点击链接获取海量免费电子书:https://developer.aliyun.com/topic/ebook























Flink-1.11 知识图谱
速度收藏!看完这份知识图谱,才算搞懂 Flink!
简介: 社区整理了这样一份知识图谱,由 Apache Flink Committer 执笔,四位 PMC 成员审核,将 Flink 9 大技术版块详细拆分,突出重点内容并搭配全面的学习素材。看完这份图谱,才算真的搞懂 Flink!
先跟大家分享一个好消息!即日起,Apache Flink 社区微信公众号 Ververica 正式更名为「Flink 中文社区」并由 Apache Flink PMC 成员进行维护,是国内唯一的 Flink 社区官方微信公众号。
在去年的一年中,Flink 中文社区共发布文章 144 篇,通过提供 Flink 技术原理剖析、上手实操、多场景下的最佳实践以及社区的最新资讯等帮助大家更好的理解、使用 Flink。
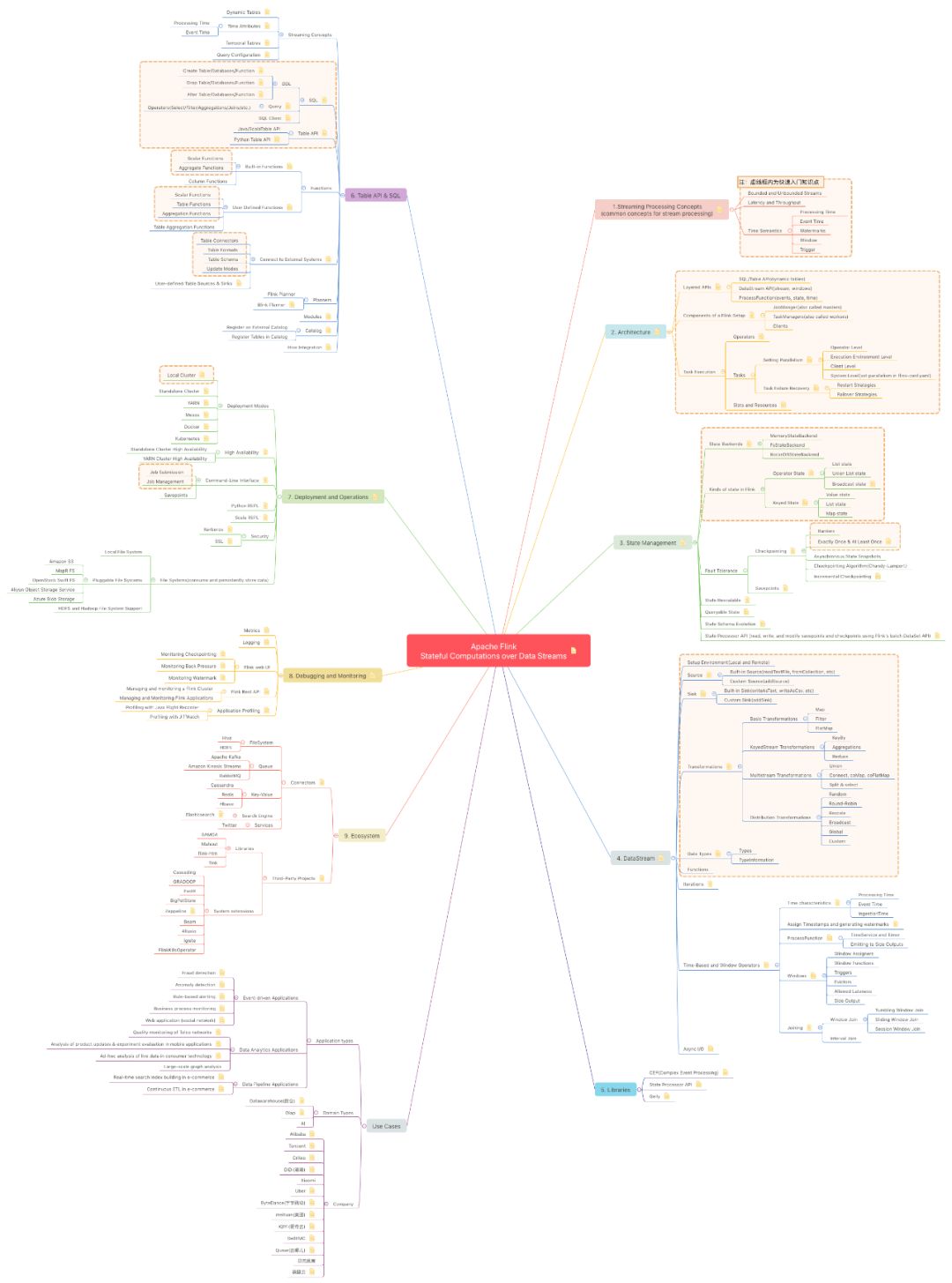
同时,我们也发现当前社区除文章、直播教程、Meetup 外还缺少一个清晰的图谱让大家了解 Flink 完整的技术体系与学习路径。因此,社区整理了这样一份知识图谱,由 Apache Flink Committer 执笔,四位 PMC 成员审核,将 Flink 9 大技术版块详细拆分,突出重点内容并搭配全面的学习素材。看完这份图谱,才算真的搞懂 Flink!
▽ Flink 知识图谱概览 ▽
如何获取?
点击下方链接即可马上下载,知识图谱 PDF 版本内含大量补充链接,一键点击即可查看相关扩展素材!
《Apache Flink 知识图谱》
https://ververica.cn/developers/special-issue/
最实用的知识图谱
1.内容全面,将 Flink 所涉及的技术内容划分为 9 大版块,每部分内容进行详细分解,并提供学习路径及深入了解的学习素材。
- Streaming Processing Concepts(common concepts for stream processing)
- Architecture
- State Management
- DataStream
- Libraries
- Table API & SQL
- Deployment and Operations
- Debugging and Monitoring
- Ecosystem
- Use Cases
2.层次分明,将各部分技术内容中的基础入门知识进行标示,重点突出,帮你找到清晰的学习路径。
3.方便实用,每个知识点附带补充说明的链接与最佳学习素材,可及时进行深度探索,有助于理解消化。
4.强大的拓展阅读资料配置,整合了社区全年输出的技术文章、系列直播教程、线下 Meetup 及 Flink Forward Asia 的精华内容,一图在手,学好 Flink 不用愁!
各版块知识点详解
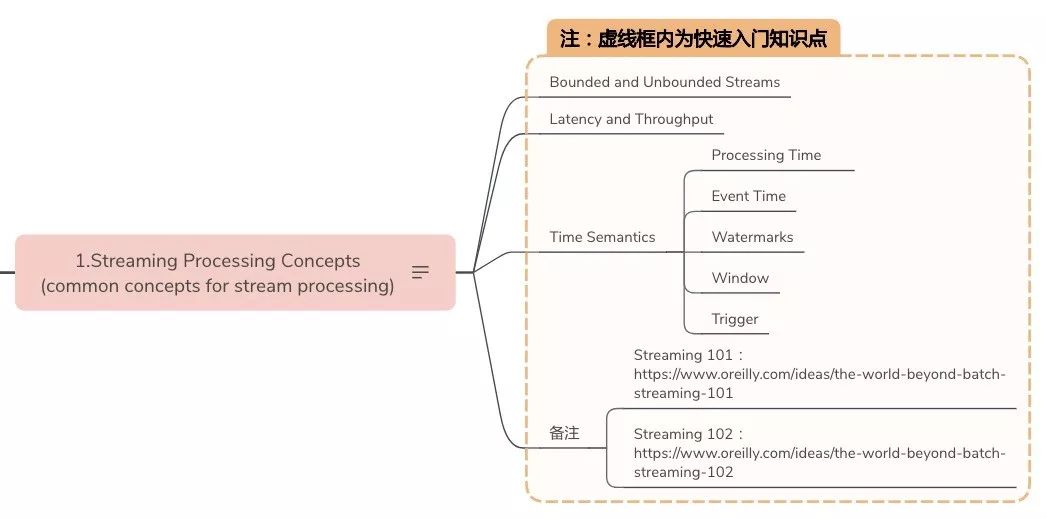
- Streaming Processing Concepts(common concepts for stream processing)
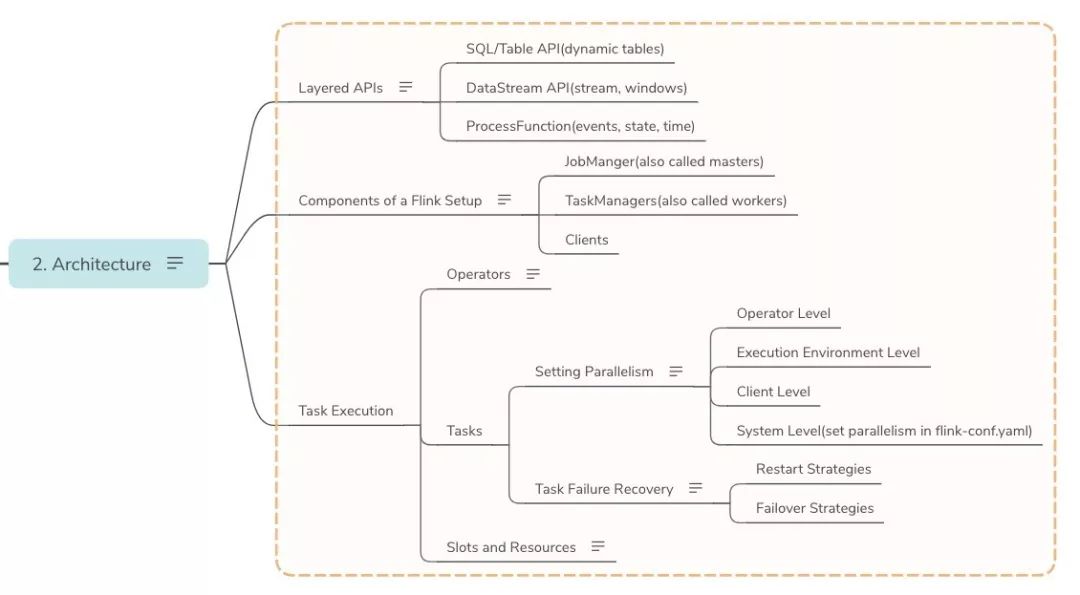
- Architecture
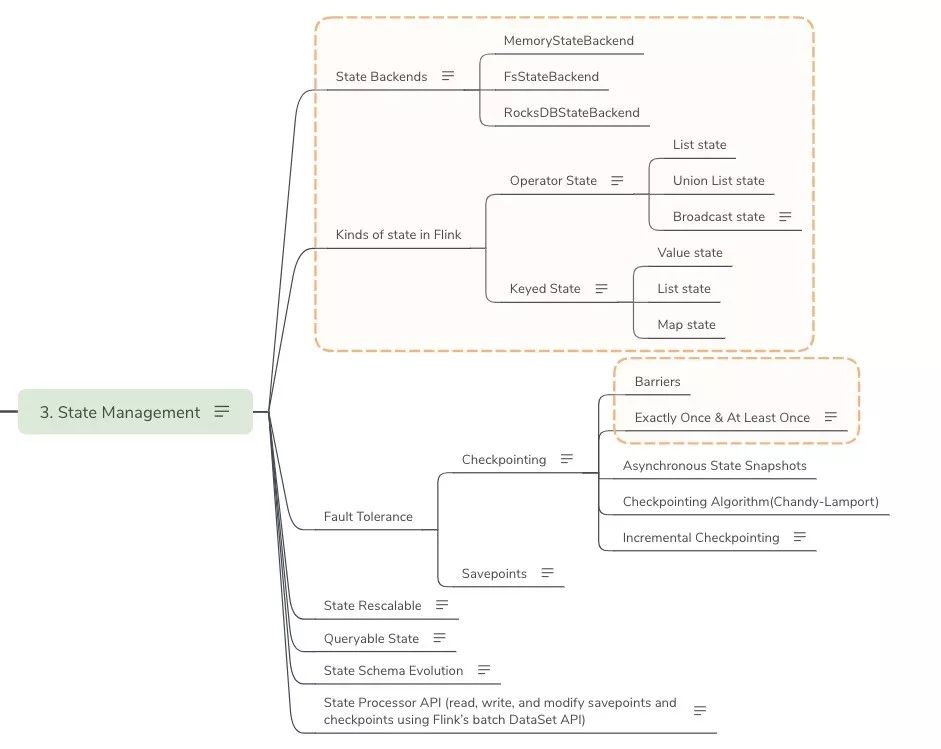
- State Management
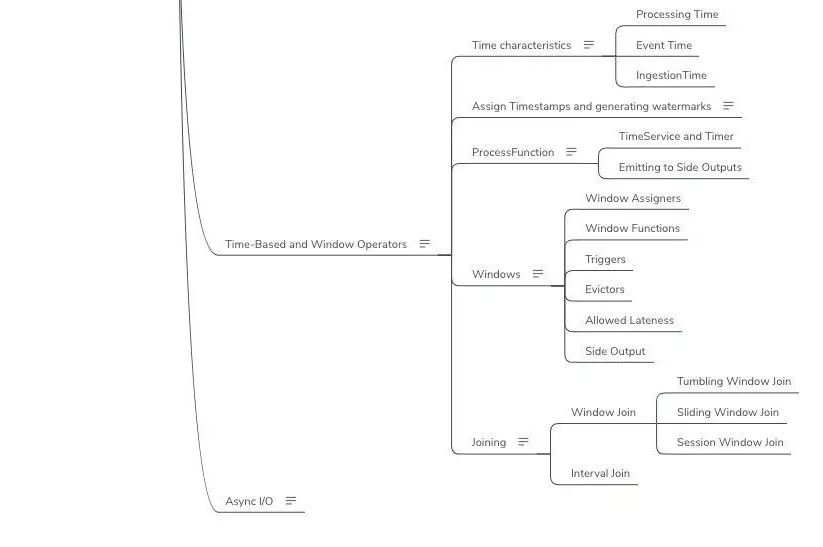
- DataStream

- Libraries

- Table API & SQL

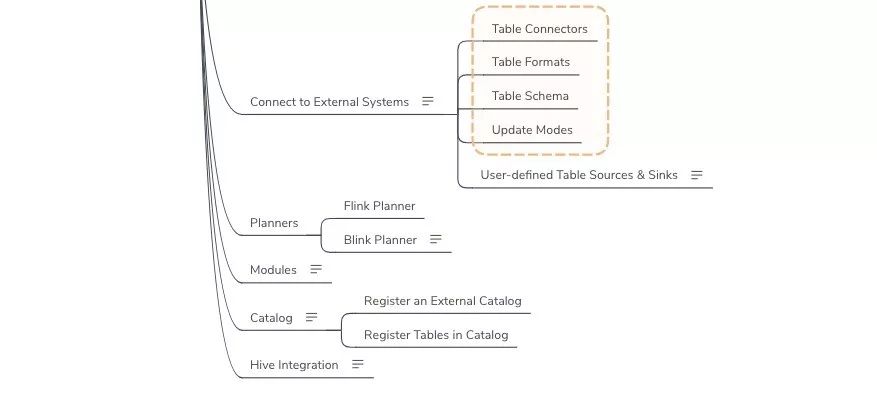
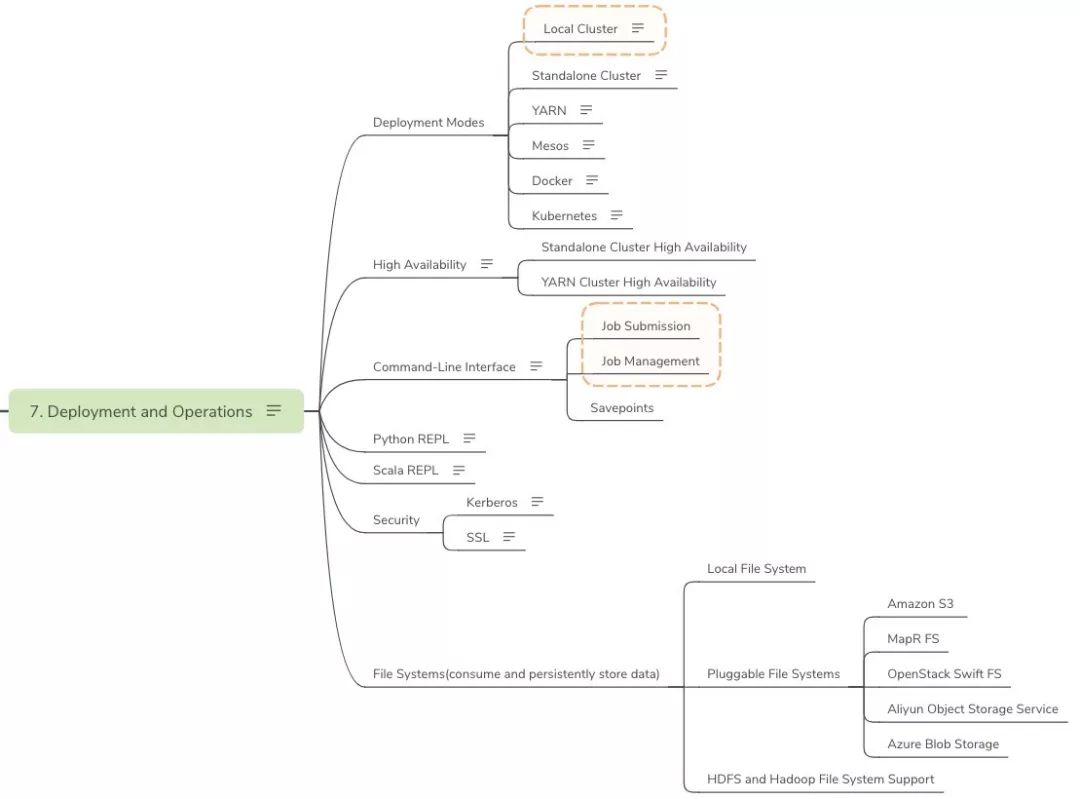
- Deployment and Operations
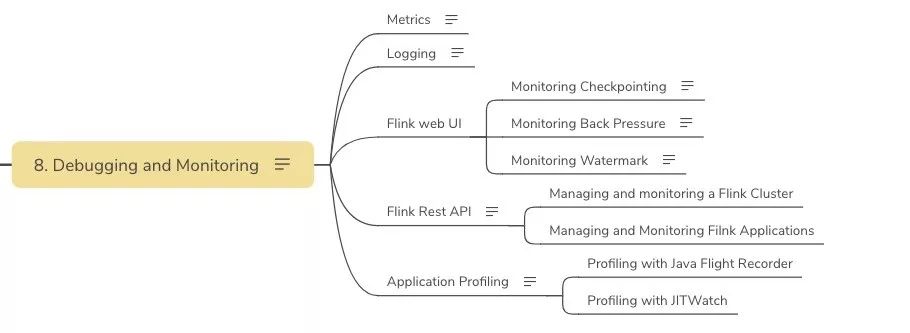
- Debugging and Monitoring
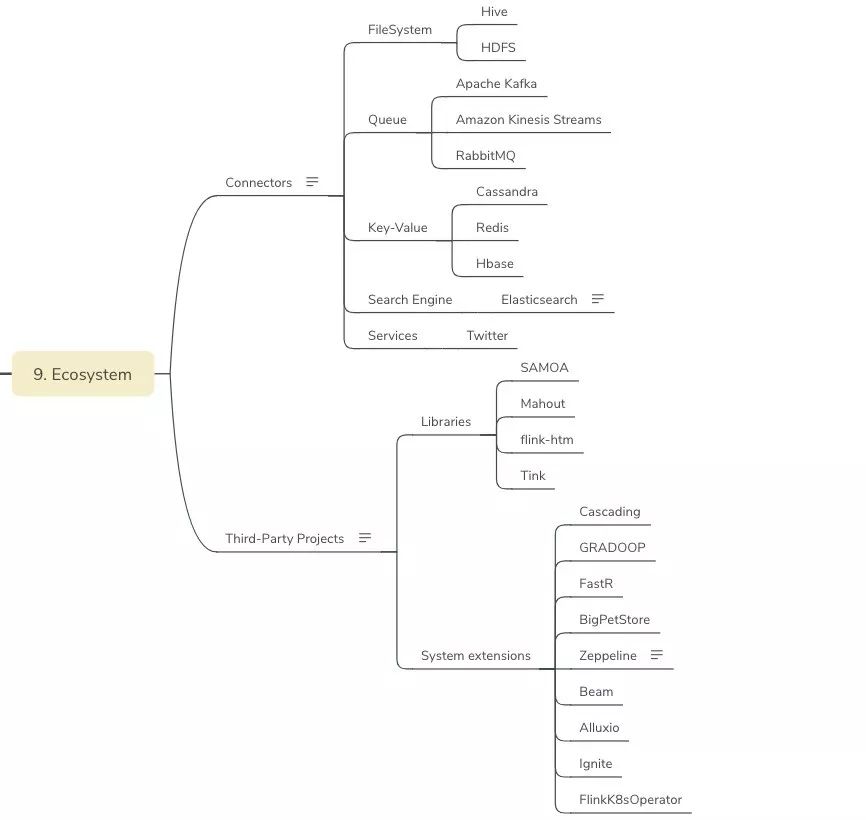
- Ecosystem
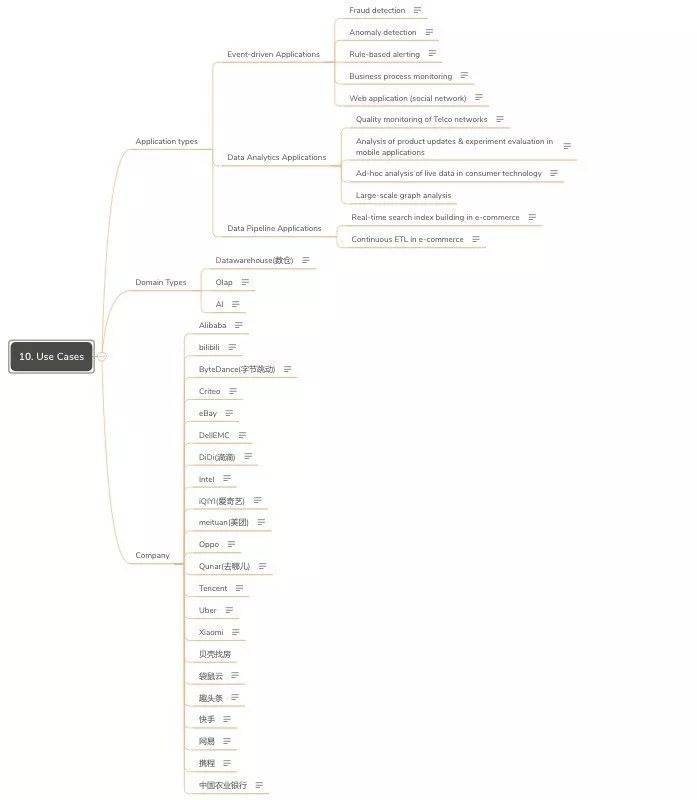
- Use Cases
部分知识图谱扩展素材
直播教程
| Flink 基础概念解析
| Flink 开发环境搭建和应用的配置、部署及运行
| Flink Datastream API 编程
| Flink 客户端操作
| Flink Time & Window
| Flink 状态管理及容错机制
| Flink Table API 编程
| Flink SQL 编程实践
| 5分钟从零构建第一个 Flink 应用
| 零基础实战教程:如何计算实时热门商品
| Runtime 核心机制剖析
| 时间属性深度解析
| Checkpoint 原理剖析与应用实践
| Flink on Yarn / K8s 原理剖析及实践
| 数据类型和序列化
| Flink 作业执行深度解析
| 网络流控和反压剖析
| 详解 Metrics 原理与实战
User Case 及补充
| 小米流式平台架构演进与实践
| 美团点评基于 Flink 的实时数仓平台实践
| 监控指标10K+!携程实时智能检测平台实践
| Lyft 基于 Flink 的大规模准实时数据分析平台
| 基于 Flink 构建 CEP 引擎的挑战和实践
| 趣头条基于 Flink 的实时平台建设实践
| G7 在实时计算的探索与实践
| Flink 靠什么征服饿了么工程师?
| Apache Flink 的迁移之路,2 年处理效果提升 5 倍
| 日均百亿级日志处理:微博基于 Flink 的实时计算平台建设
| Flink 在同程艺龙实时计算平台的研发与应用实践
| 从 Storm 到 Flink,汽车之家基于 Flink 的实时 SQL 平台设计思路与实践
| 日均处理万亿数据!Apache Flink在快手的应用实践与技术演进之路
| 从 Spark Streaming 到 Apache Flink : 实时数据流在爱奇艺的演进
| Apache Flink 在 eBay 监控系统上的实践和应用
| 每天30亿条笔记展示,小红书如何实现实时高效推荐?
| 360深度实践:Flink 与 Storm 协议级对比
| Blink 有何特别之处?菜鸟供应链场景最佳实践
| 58 集团大规模Storm 任务平滑迁移至 Flink 的秘密
| 从Storm到Flink,有赞五年实时计算效率提升实践
拓展链接
| https://ververica.cn/developers/table-api-programming/
| https://sf-2017.flink-forward.org/kb_sessions/streaming-models-how-ing-adds-models-at-runtime-to-catch-fraudsters/
| https://sf-2017.flink-forward.org/kb_sessions/building-a-real-time-anomaly-detection-system-with-flink-mux/
| https://sf-2017.flink-forward.org/kb_sessions/dynamically-configured-stream-processing-using-flink-kafka/
| https://jobs.zalando.com/en/tech/blog/complex-event-generation-for-business-process-monitoring-using-apache-flink/
| https://berlin-2017.flink-forward.org/kb_sessions/drivetribes-kappa-architecture-with-apache-flink/
| https://2016.flink-forward.org/kb_sessions/a-brief-history-of-time-with-apache-flink-real-time-monitoring-and-analysis-with-flink-kafka-hb/
| https://ci.apache.org/projects/flink/flink-docs-master/monitoring/checkpoint_monitoring.html
| https://ci.apache.org/projects/flink/flink-docs-master/dev/table/functions/udfs.html
| https://ci.apache.org/projects/flink/flink-docs-master/dev/table/functions/systemFunctions.html
| https://ci.apache.org/projects/flink/flink-docs-master/dev/table/streaming/dynamic_tables.html
| https://ci.apache.org/projects/flink/flink-docs-master/monitoring/metrics.html
重磅福利
Flink 社区知识图谱免费下载链接来啦~关注点击下方链接即可下载,并有直播课程详解知识图谱的正确打开方式,让你一图在手,学好 Flink 不用愁!
《Apache Flink 知识图谱》链接地址:https://ververica.cn/developers/special-issue/
知识图谱作者介绍:
程鹤群(军长),Apache Flink Committer,阿里巴巴技术专家,2015 年 4 月加入阿里巴巴,从事主搜离线相关开发。2016 年开始参与 Flink SQL 相关的研发。2018 年开始核心参与 Flink Table API 相关的研发。
什么是Flink?
Apache Flink 是什么?
简介: Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
接下来,我们来介绍一下 Flink 架构中的重要方面。
处理无界和有界数据
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。
1.无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
2.有界流 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。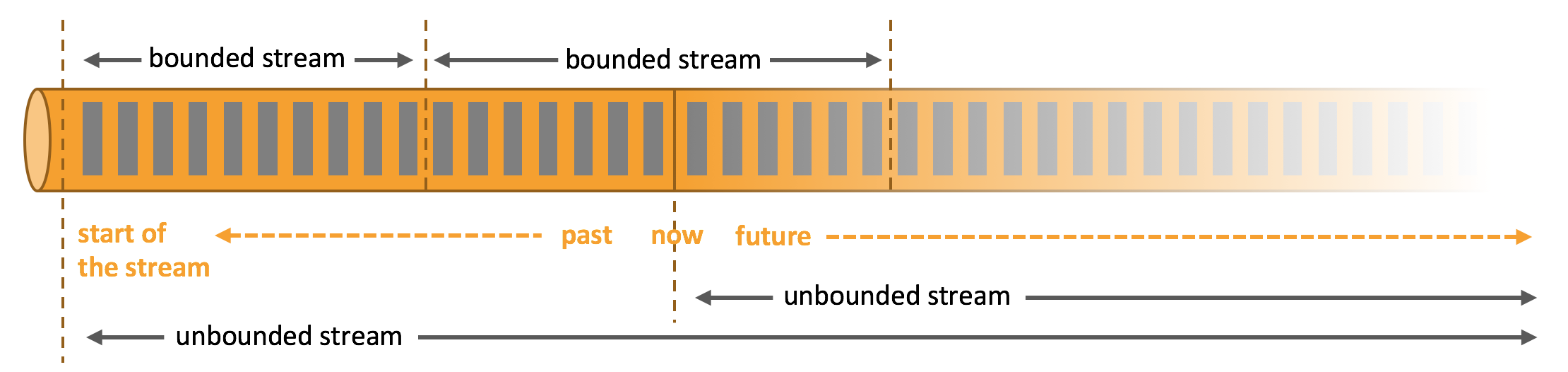
Apache Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
通过探索 Flink 之上构建的 用例 来加深理解。
部署应用到任意地方
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行。
Flink 被设计为能够很好地工作在上述每个资源管理器中,这是通过资源管理器特定(resource-manager-specific)的部署模式实现的。Flink 可以采用与当前资源管理器相适应的方式进行交互。
部署 Flink 应用程序时,Flink 会根据应用程序配置的并行性自动标识所需的资源,并从资源管理器请求这些资源。在发生故障的情况下,Flink 通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都是通过 REST 调用进行的,这可以简化 Flink 与各种环境中的集成。
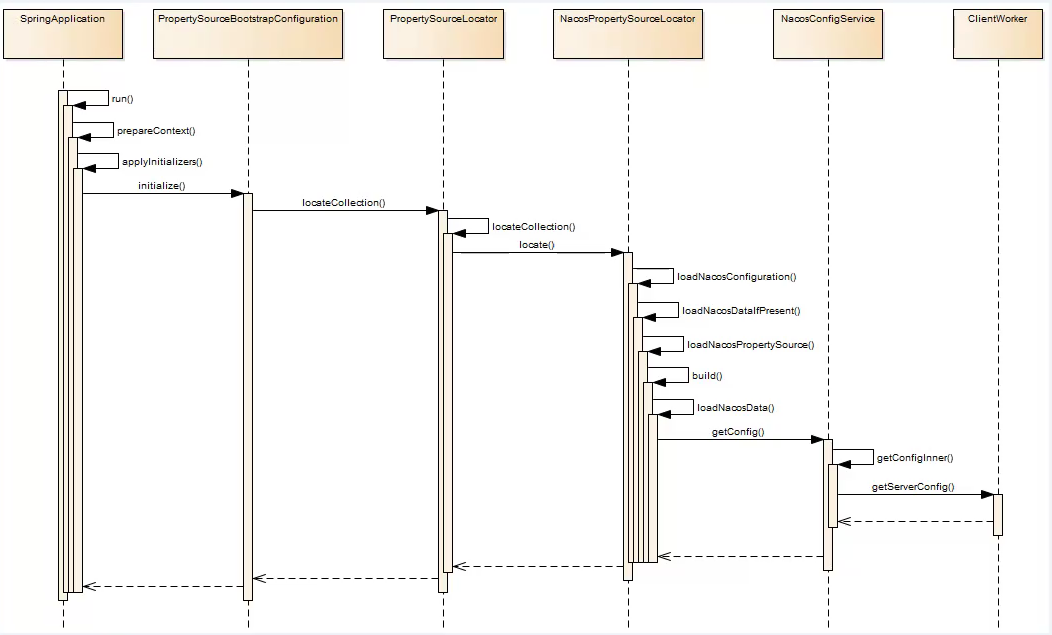
运行任意规模应用
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
Flink 用户报告了其生产环境中一些令人印象深刻的扩展性数字
- 处理每天处理数万亿的事件,
- 应用维护几TB大小的状态, 和
- 应用在数千个内核上运行。
利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。