

CDC:在数据迁移场景非常实用
PyFink:提升对Pandas UDF的支持,扩展python在支持分布式上的能力
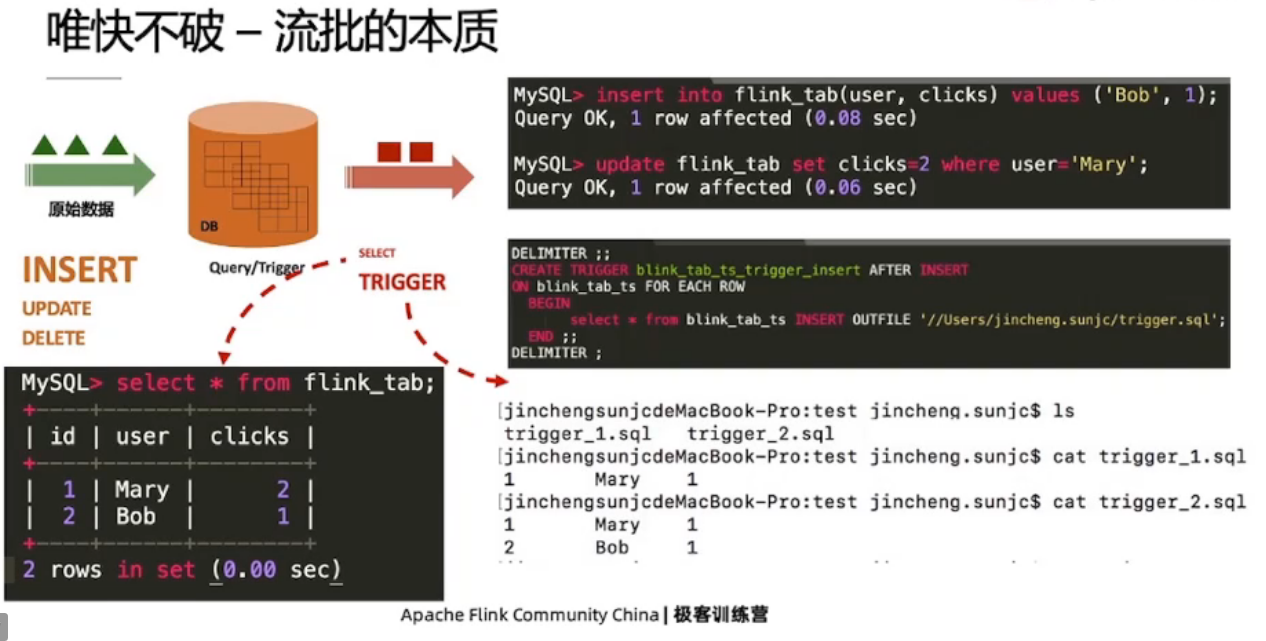
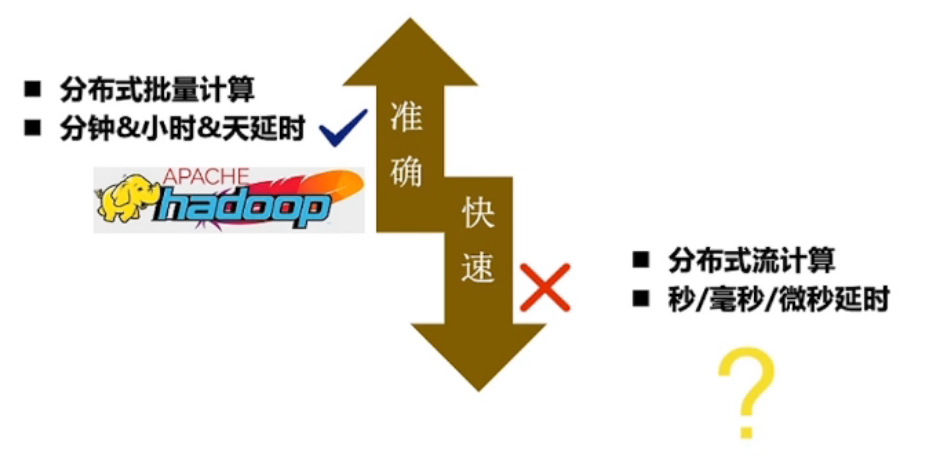
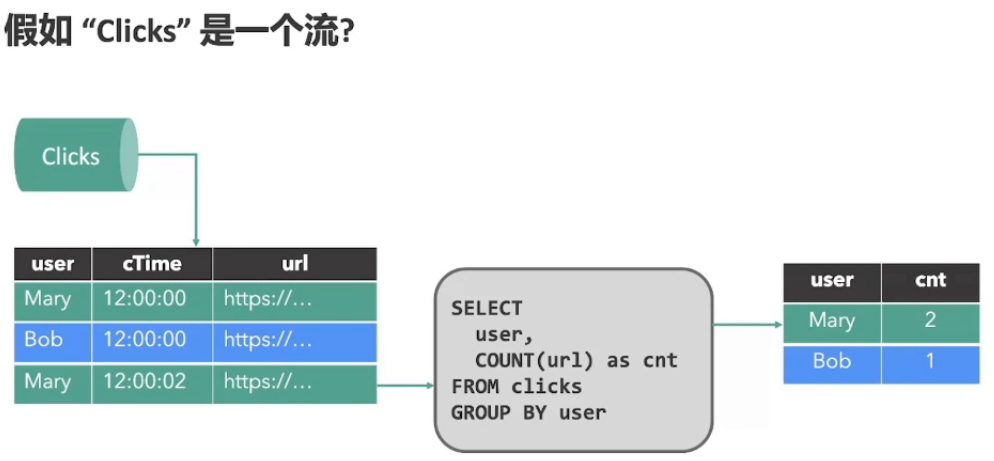
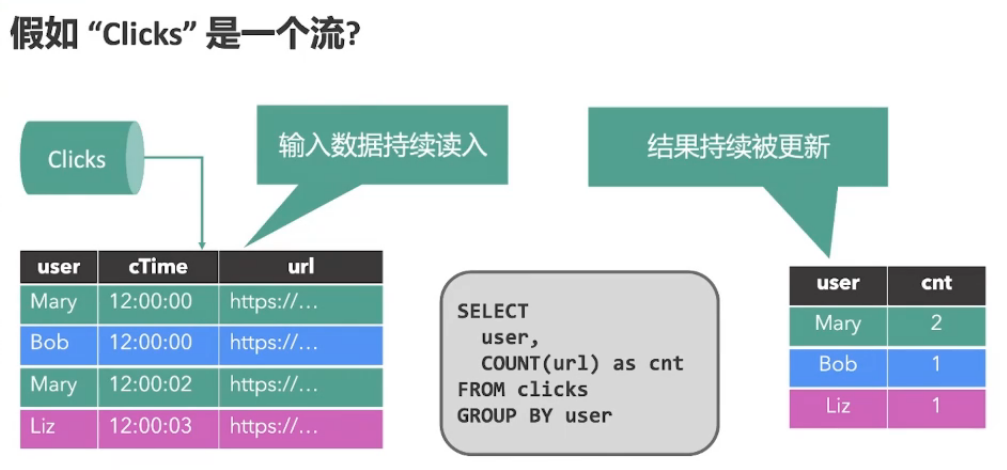
1.1、流批的本质
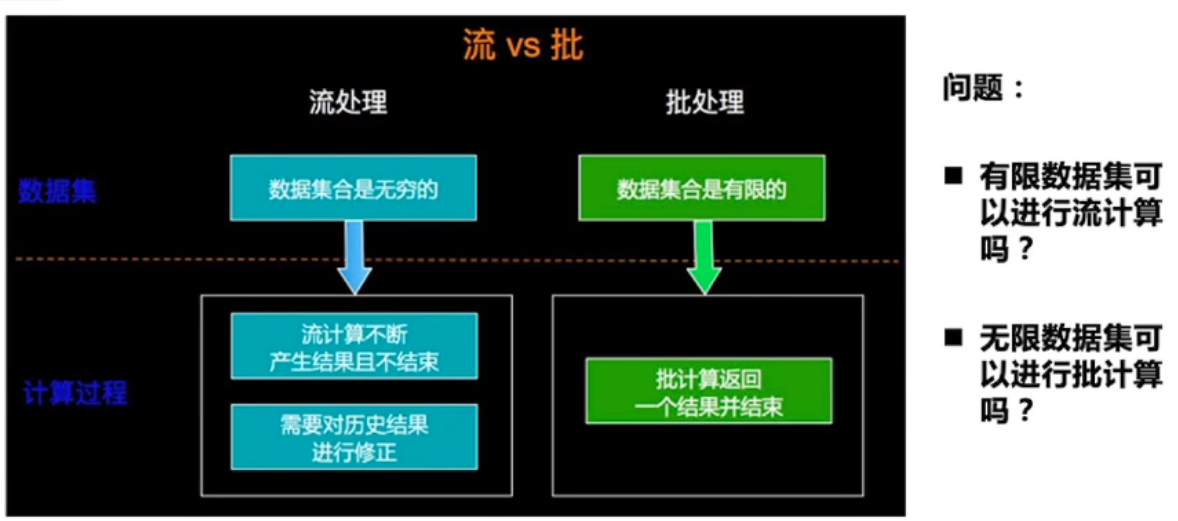
有界的数据是批,无界的数据是流
海量数据处理三辆马车
GFS
BigTable
MapReduce
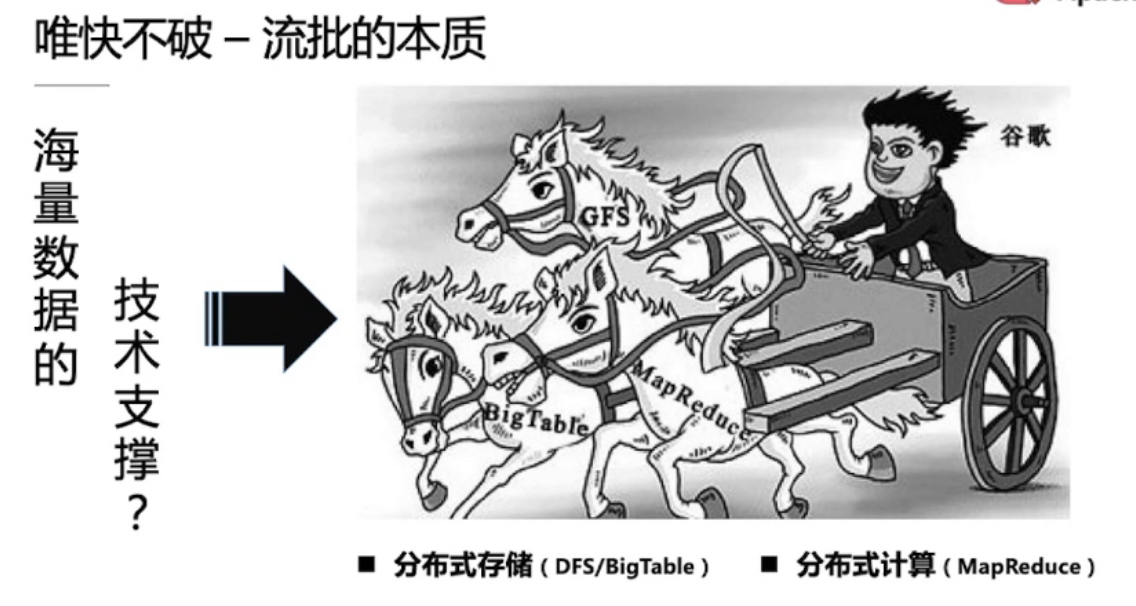
对应的开源框架
- Hadoop
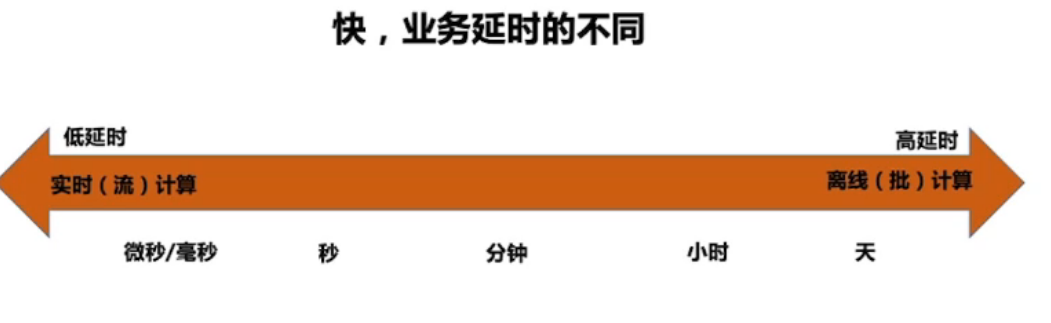
流与批的区别:业务延时的不同

流是批的特例,Flink(Native-Streaming)
批是流的特例,Spark(Micro-Batching)

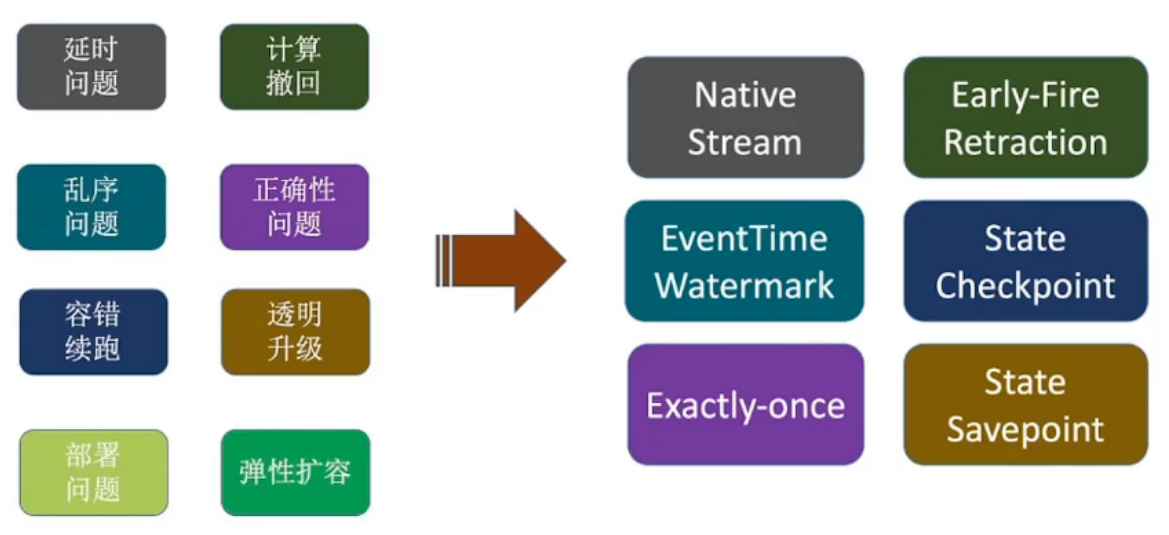
1.2、流计算的核心问题
问题:
- 延问题
- 更新撤回:
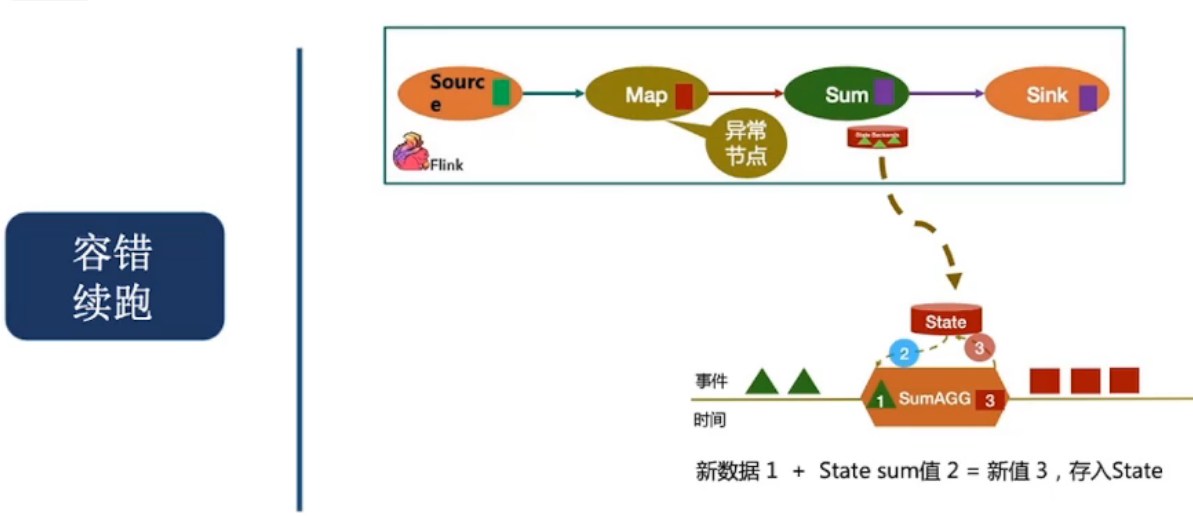
- 容错续跑:机器故障以后,可以继续跑
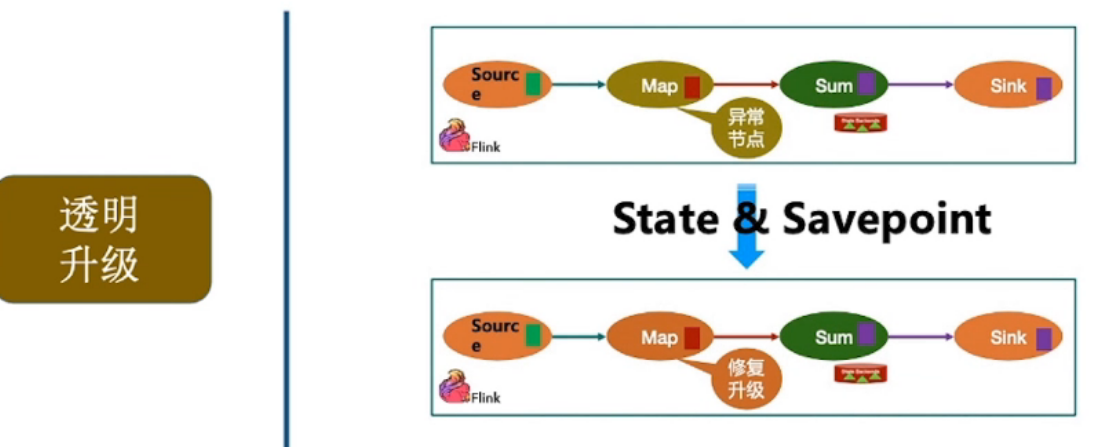
- 透明升级:某个Job升级以后,可以继续前面的任务跑
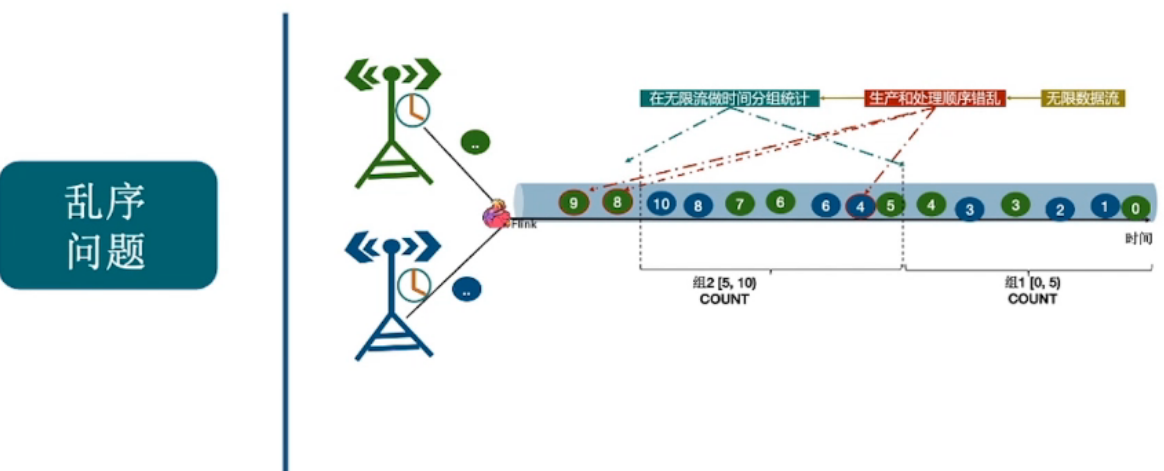
- 乱序问题:数据到达顺序问题
- 正确性问题:
- 部署问题
- 弹性扩容问题
延时问题
Native Stream + Early-Fire
更新撤回
告诉下游节点上一次计算结果无效
使用”-“标记上一次计算结果失效
容错续跑
透明升级
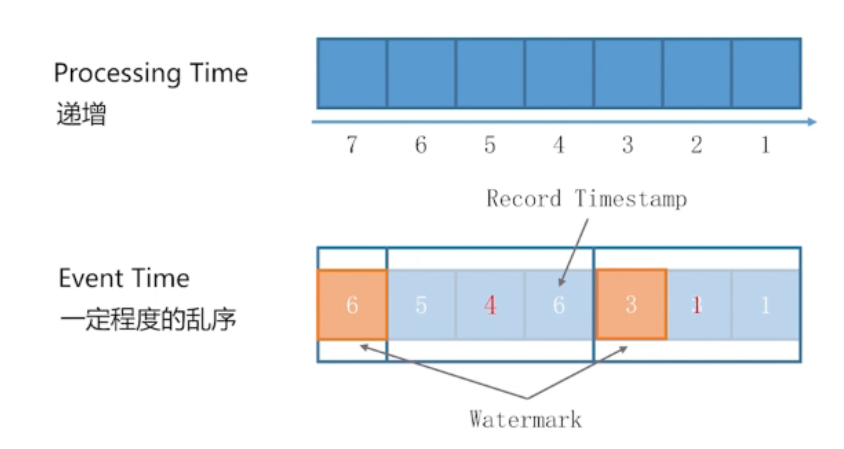
乱序问题
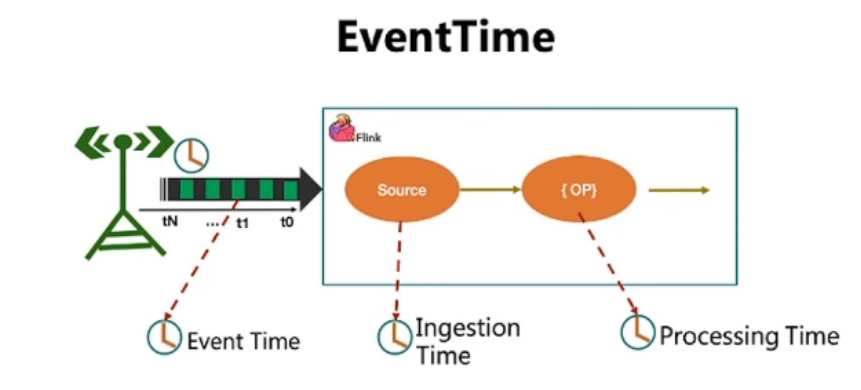
数据产生时间 EventTime
数据进入流计算引擎的时间 Watermark
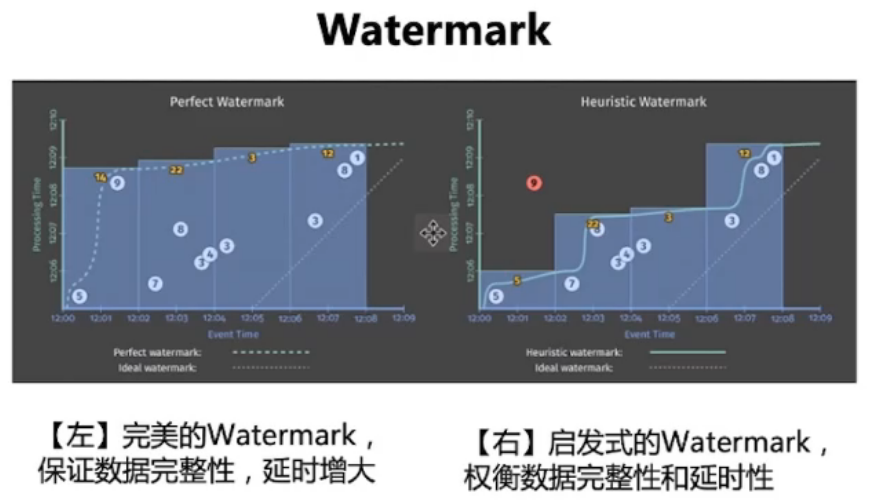
正确性问题
- 数据是否有丢失
- 数据是否只参与了一次计算
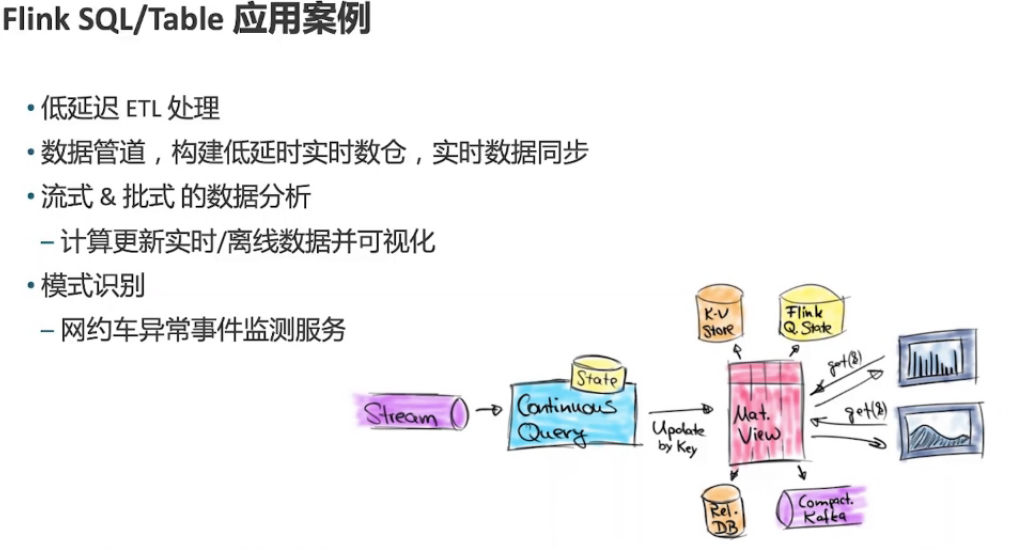
1.3、Flink应用场景
事件驱动型应用
社交:关注事件 引发的 后续操作
网购:恶意差评事件 -> 封号
金融:欺诈 -> 反欺诈
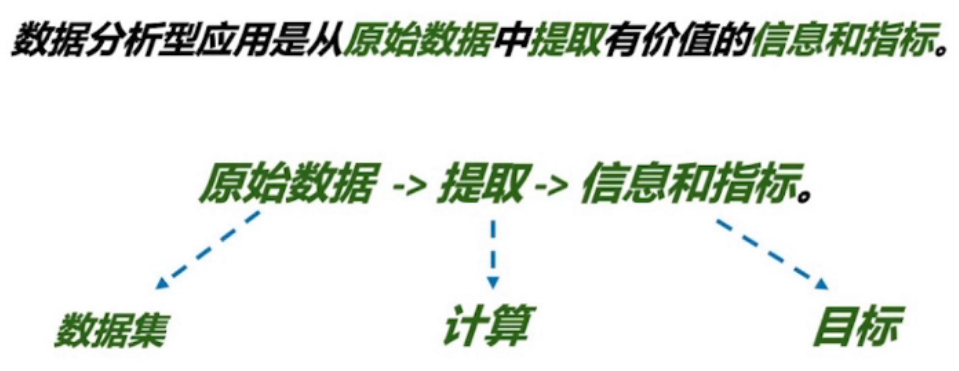
数据分析型应用

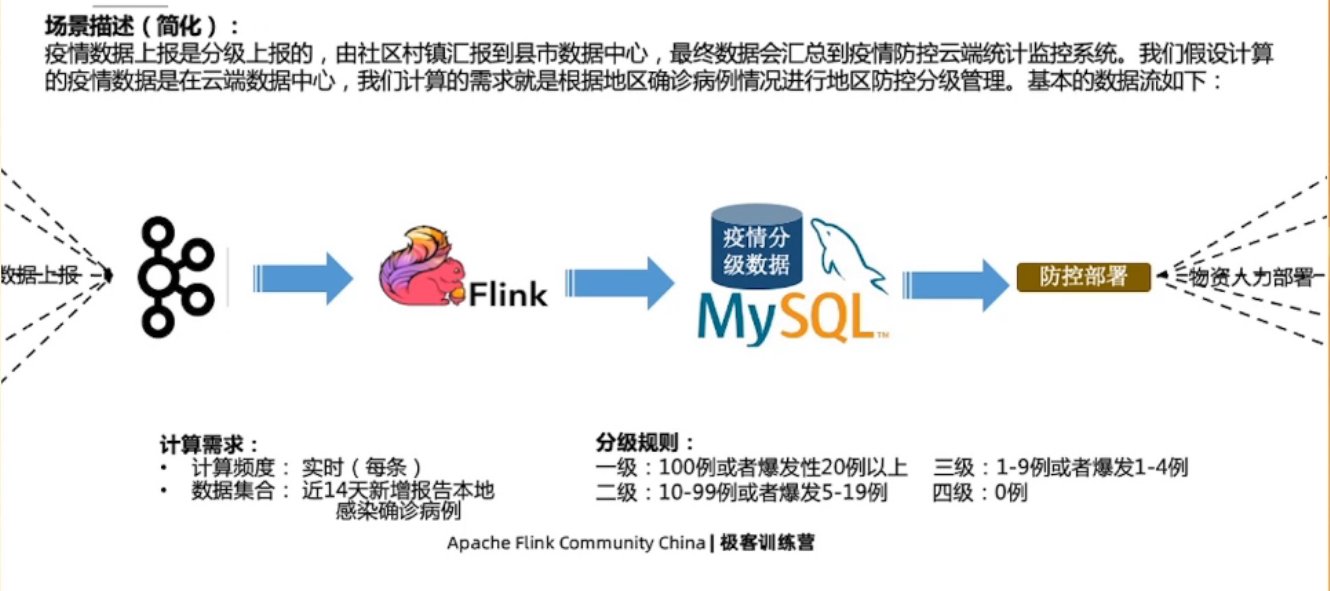


数据管道型应用
数据清洗
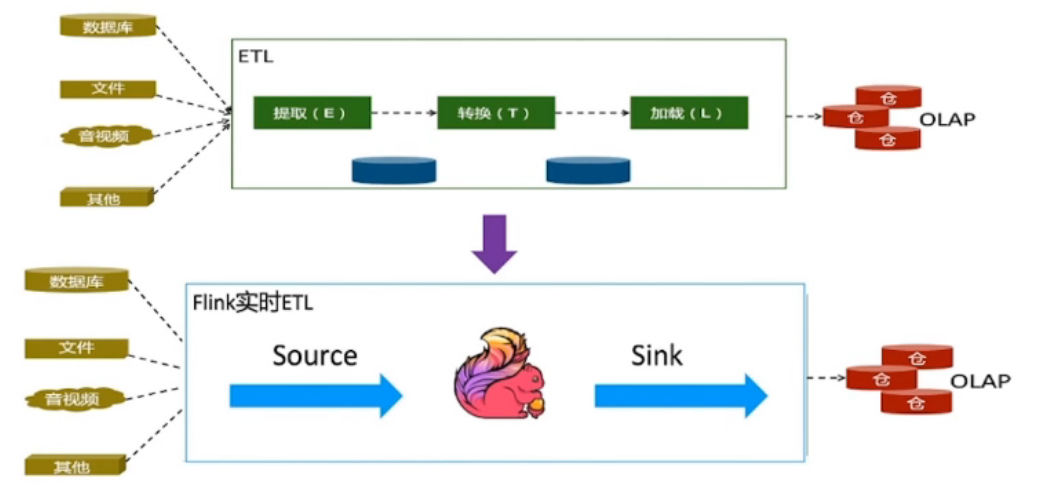
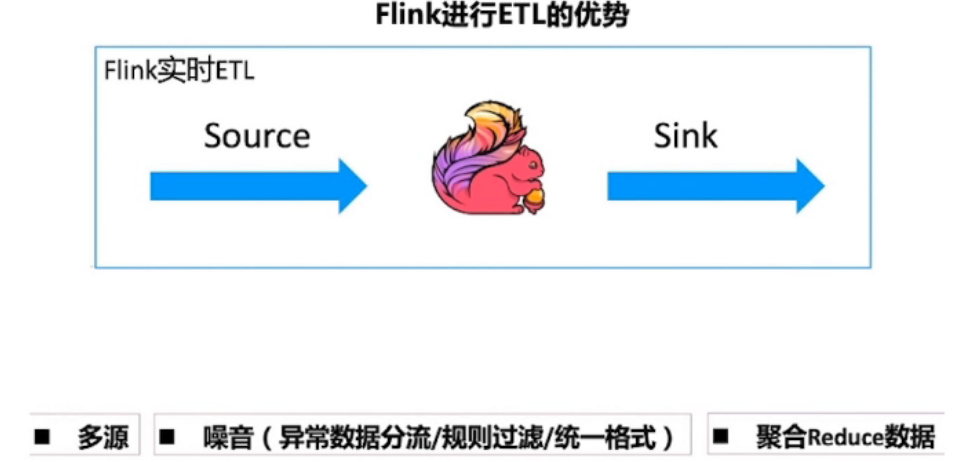
1.4、怎样理解流批一体融合?
用户、运行、运维 三个维度看
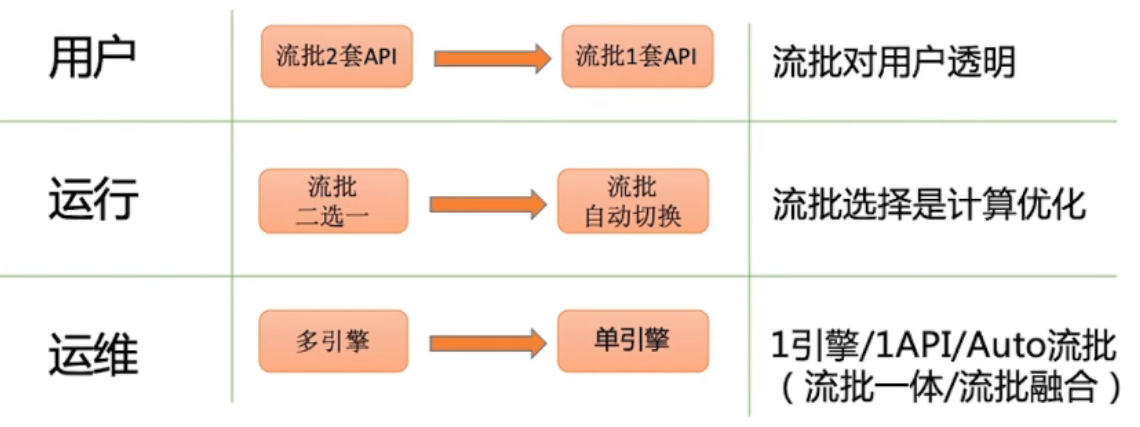
第二章 Stream Process 在 Flink 的实现

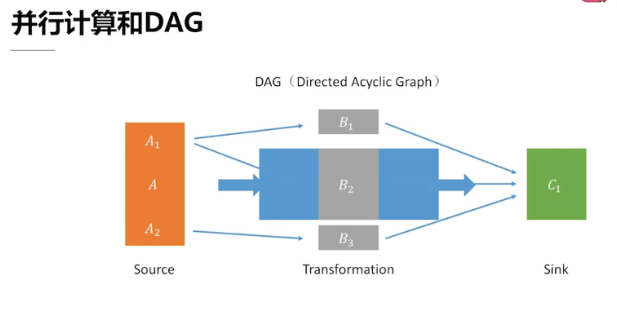
2.1、并行处理和编程范式
任务划分 类似 有向无环图(DAG)的

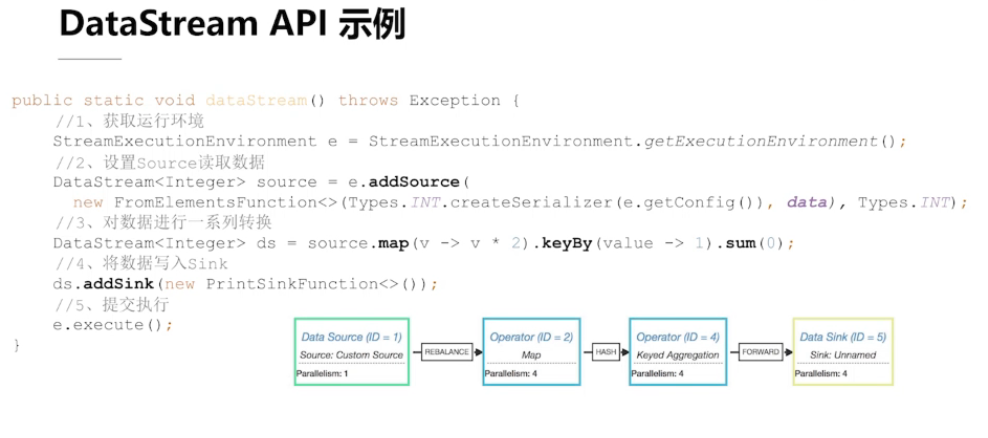
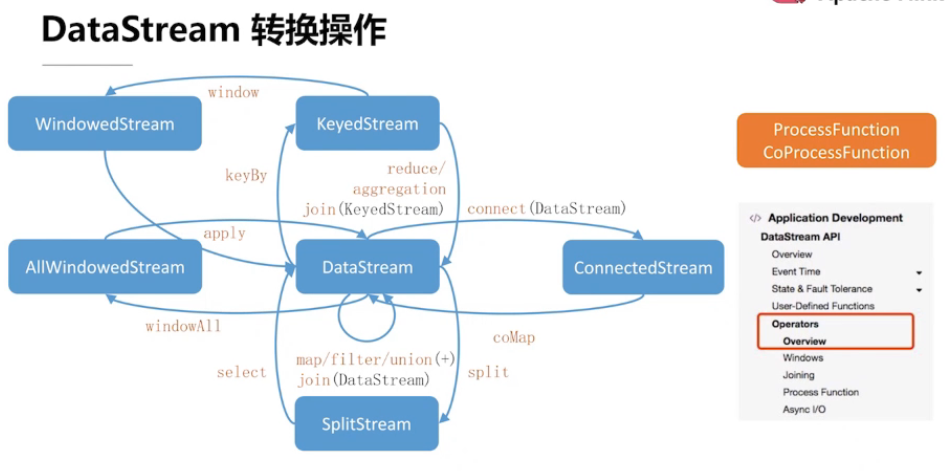
2.2、DataStream API 概览

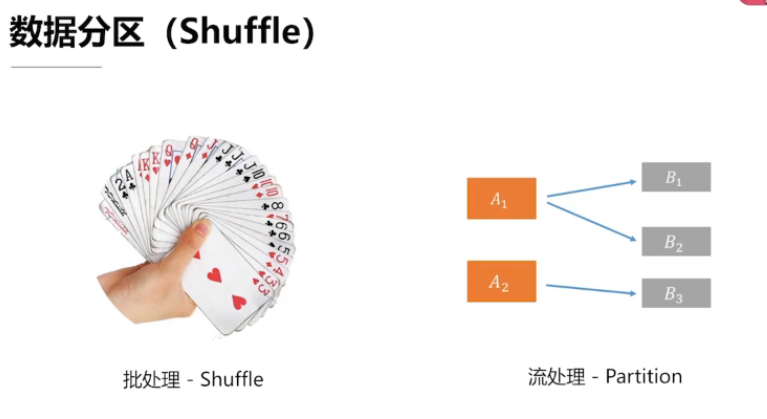
批处理 的数据分区类似于洗牌,将相关的牌放在一起
流处理 分区是随着数据的到来 动态完成的

2.3、状态和时间
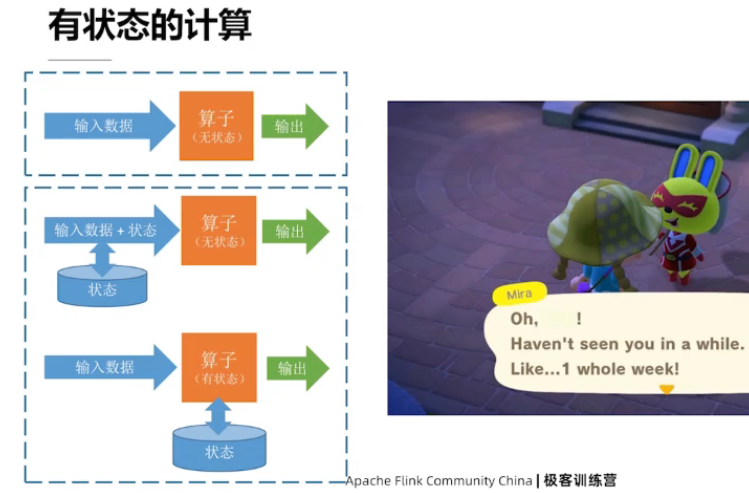

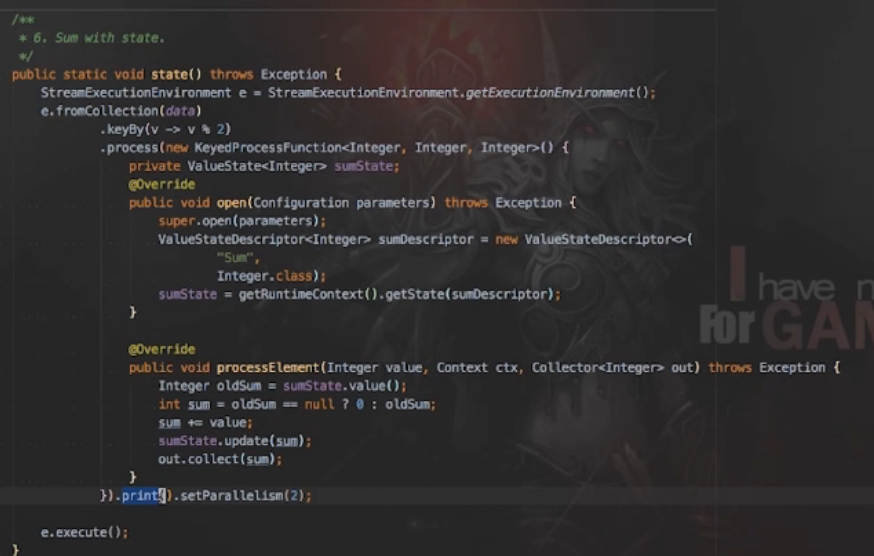



时间的使用案例:
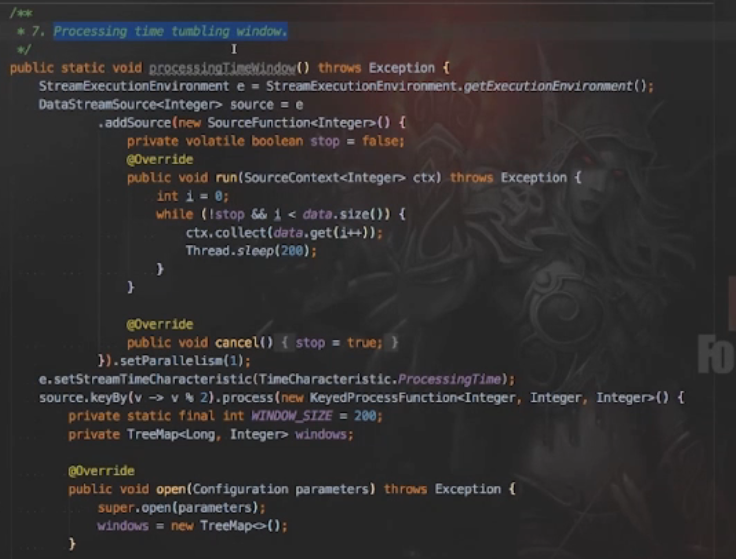
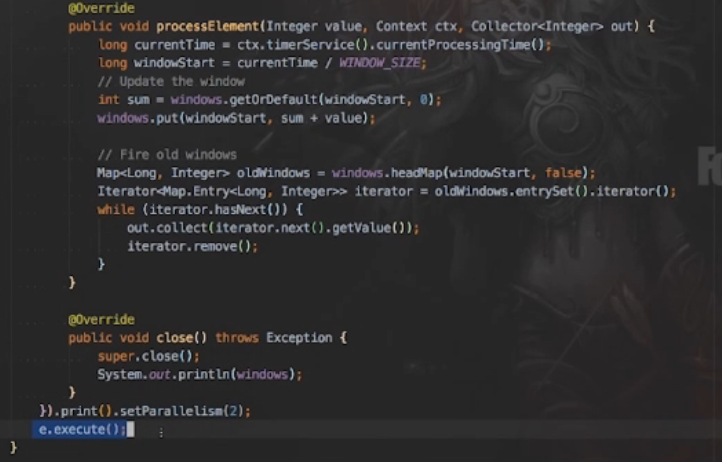
运行结果:

作业框架,基于框架进行开发
【Stream Processing with Apache Flink】
讲师:崔星灿,Apache Flink Committer
时间:7月14日 20:00-21:00(UTC+8)
【作业内容】
- 准备环境:能clone和运行源码中的streaming-examples
- 下载地址:https://github.com/flink-china/Flink-Geek-Training/blob/master/Training2.java
第三章 运行时架构

3.1 、Runtime 总览
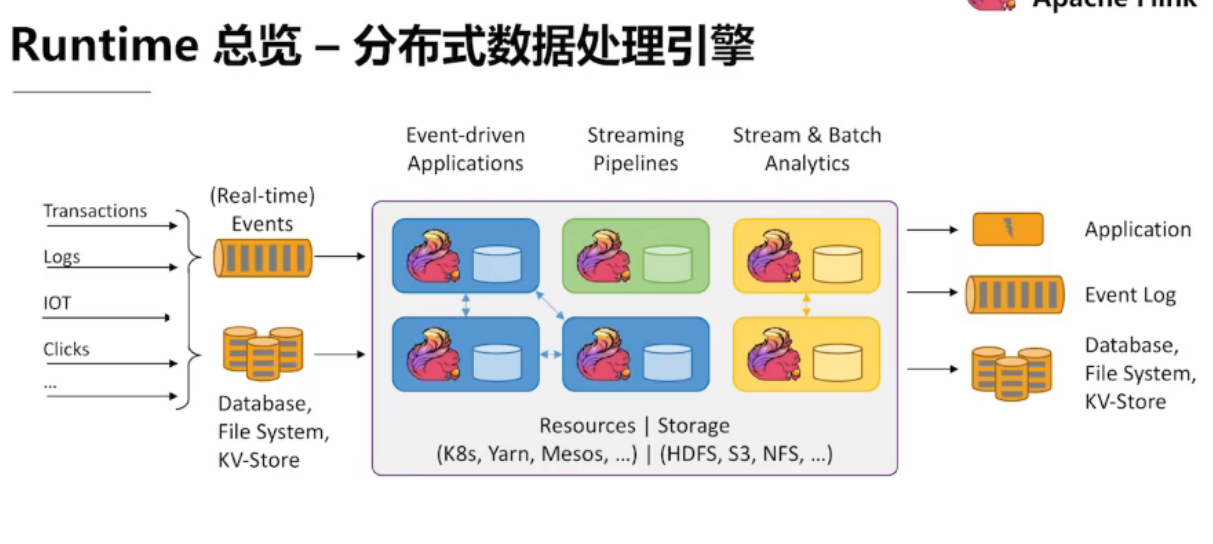
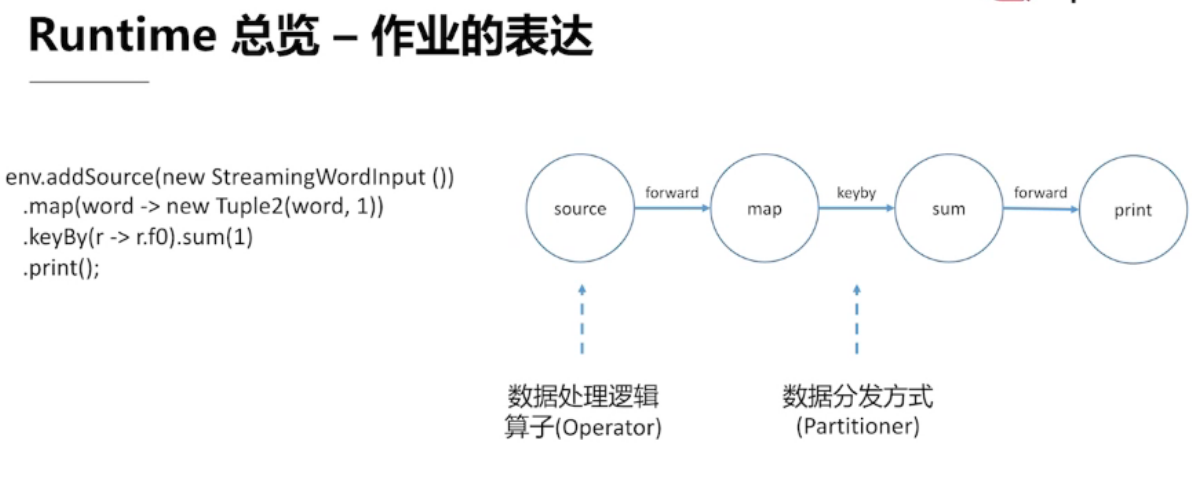
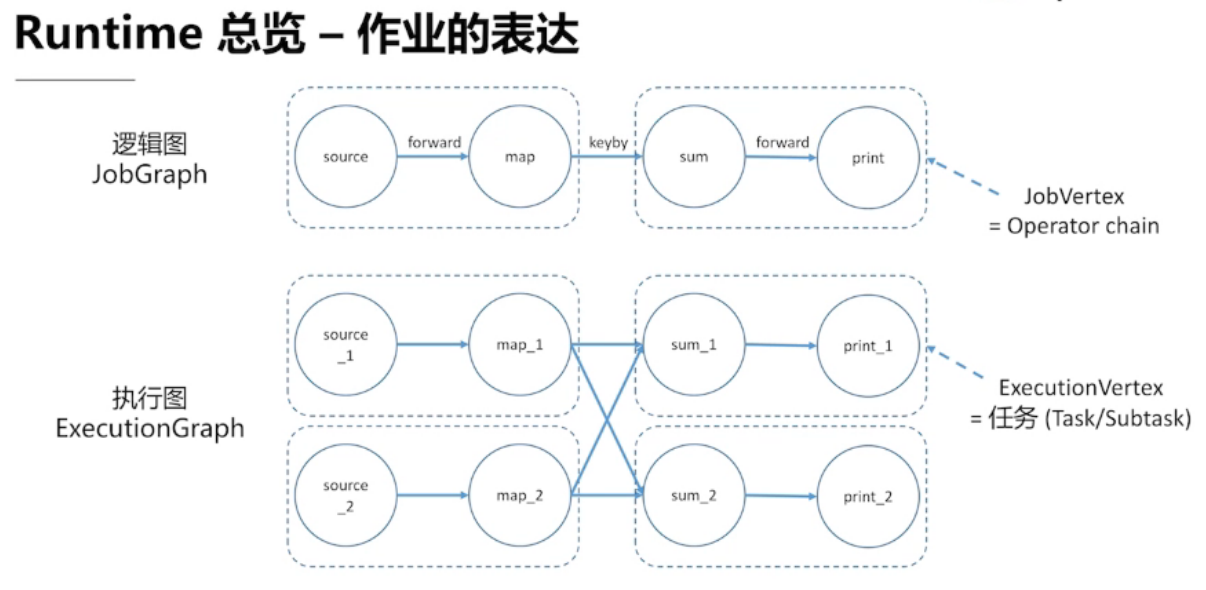
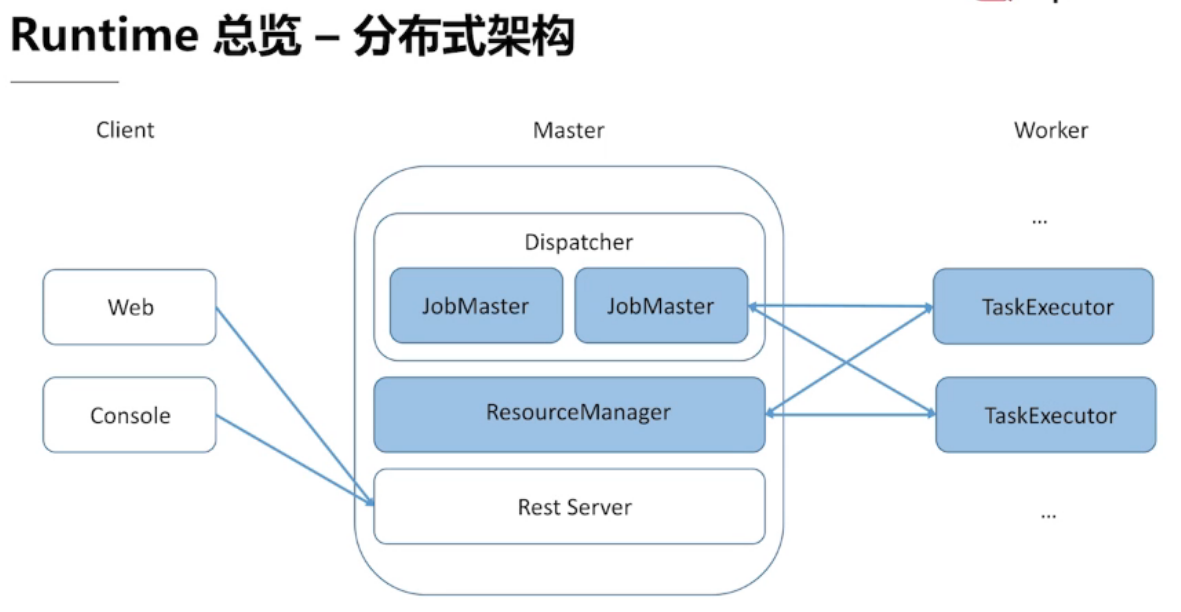
三大核心组件
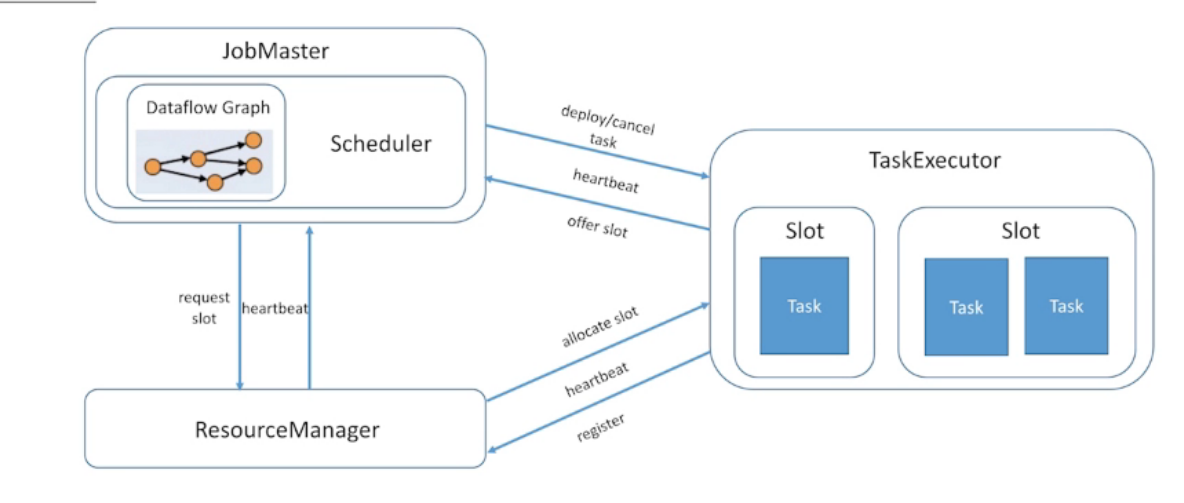
3.2、 JobMaster — 作业的控制中心
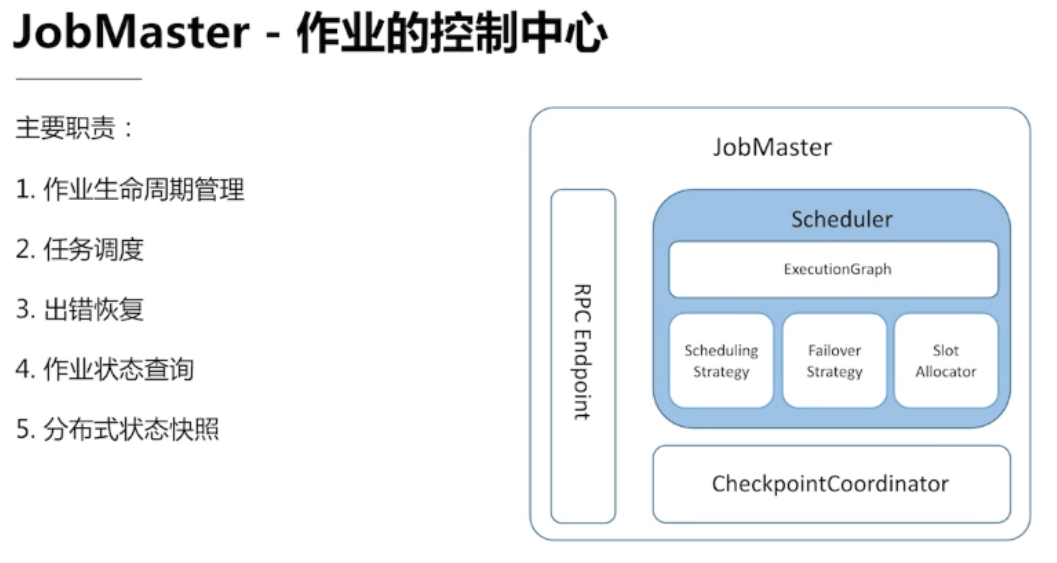
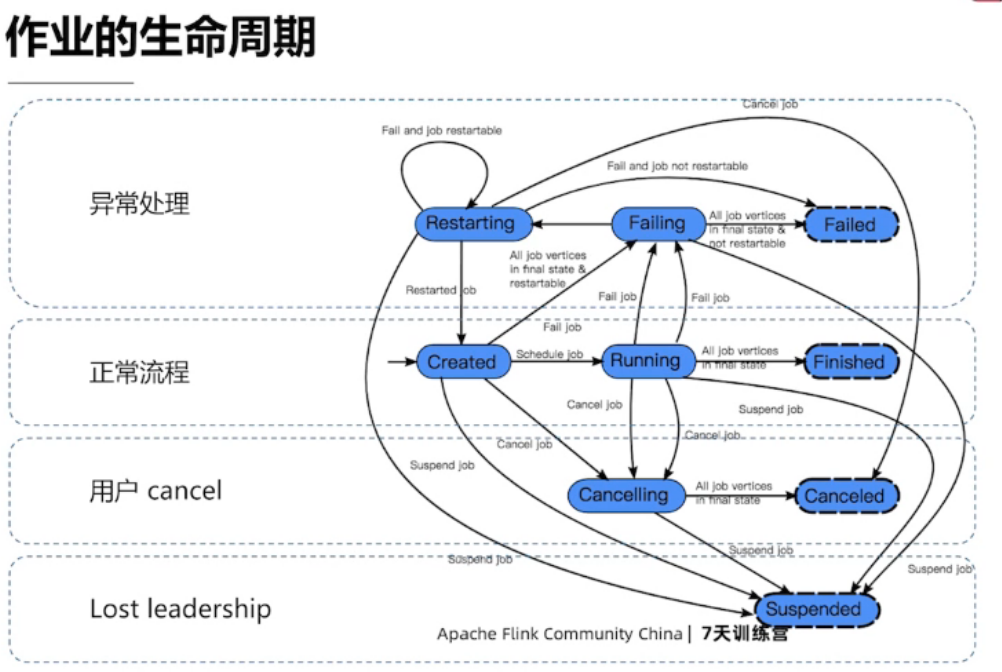
Lost Leadership:JobMaster出问题了,异常终止

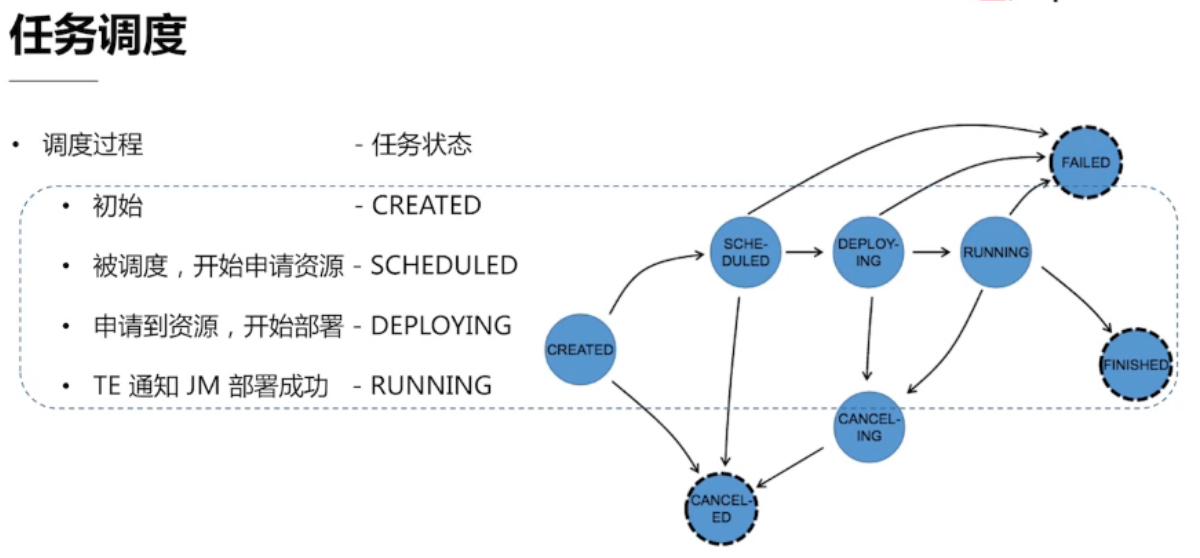
- Eager:服务于流式处理作业,节省调度花费的时间;
- Lazy from sources:服务于批处理作业,延迟下游资源的调度,避免空转浪费资源;
- (WIP)Piplined region based:类似Lazy from sources,既能减少调度时间,又能避免空转浪费资源;
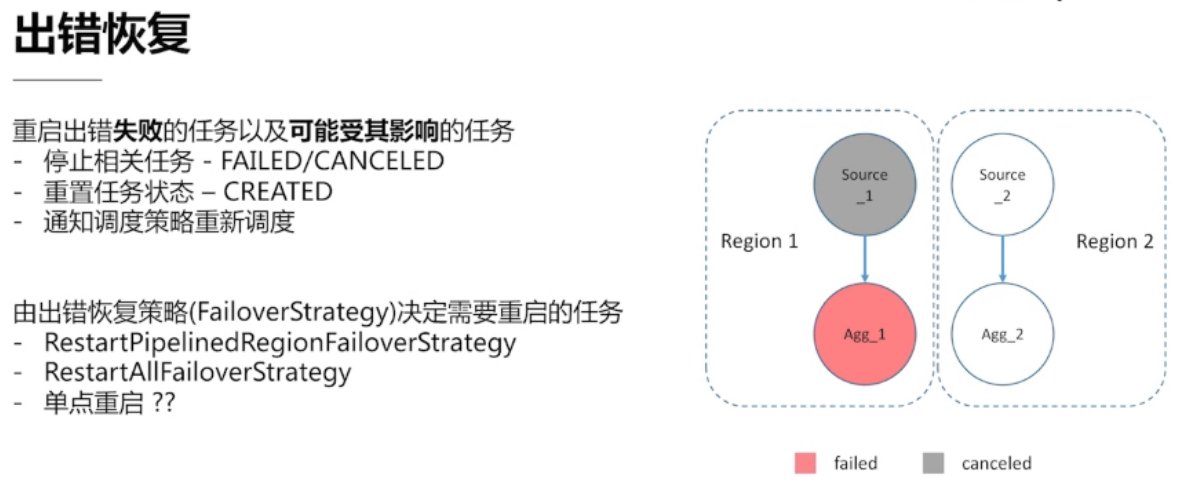
出错恢复策略 与 Pipiline 有关,出错后,会重新pipline里相关的任务
单点重启:只重启出错的节点,接下来的版本会牺牲数据一致性来实现
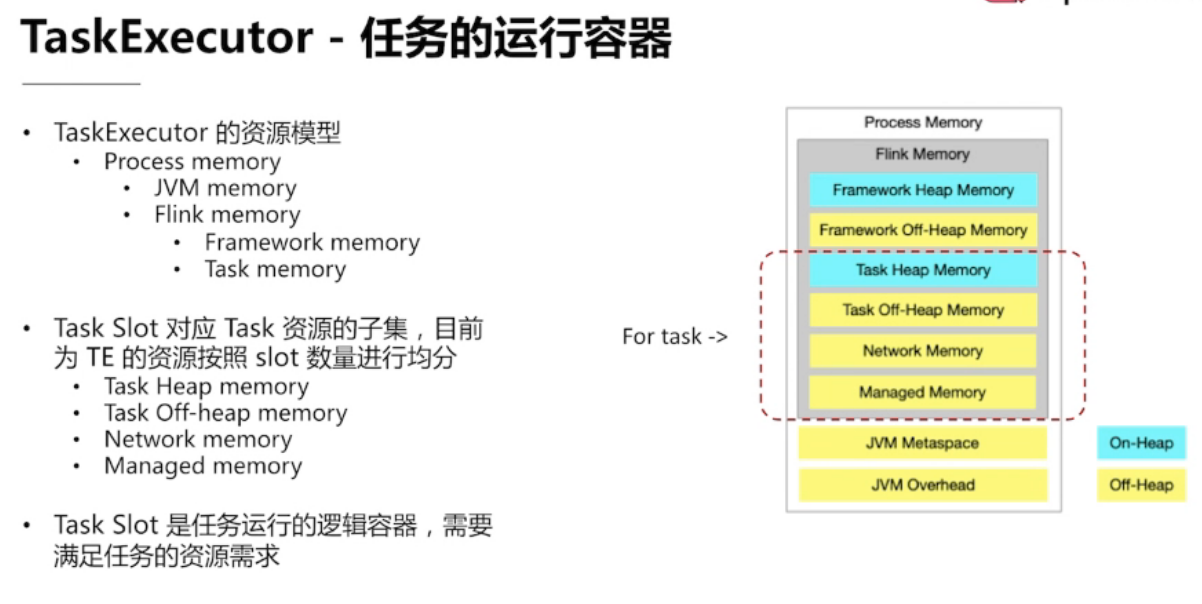
3.3、TaskExecutor — 任务的运行容器

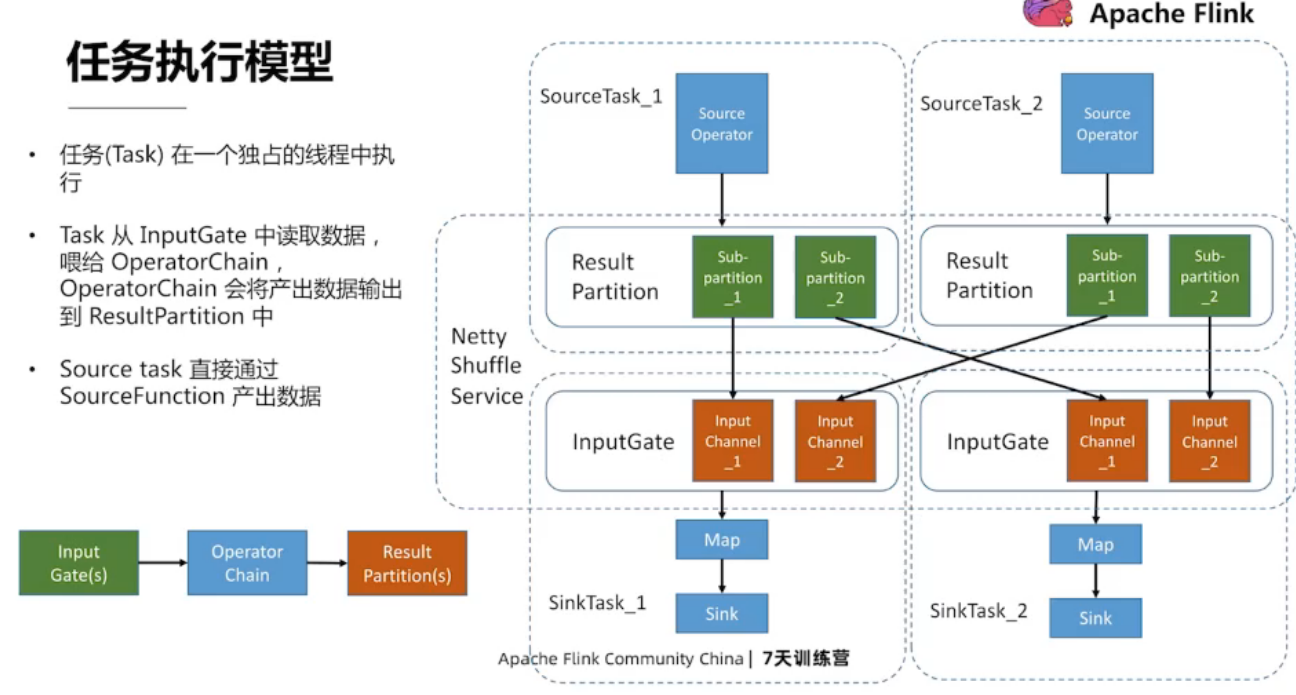
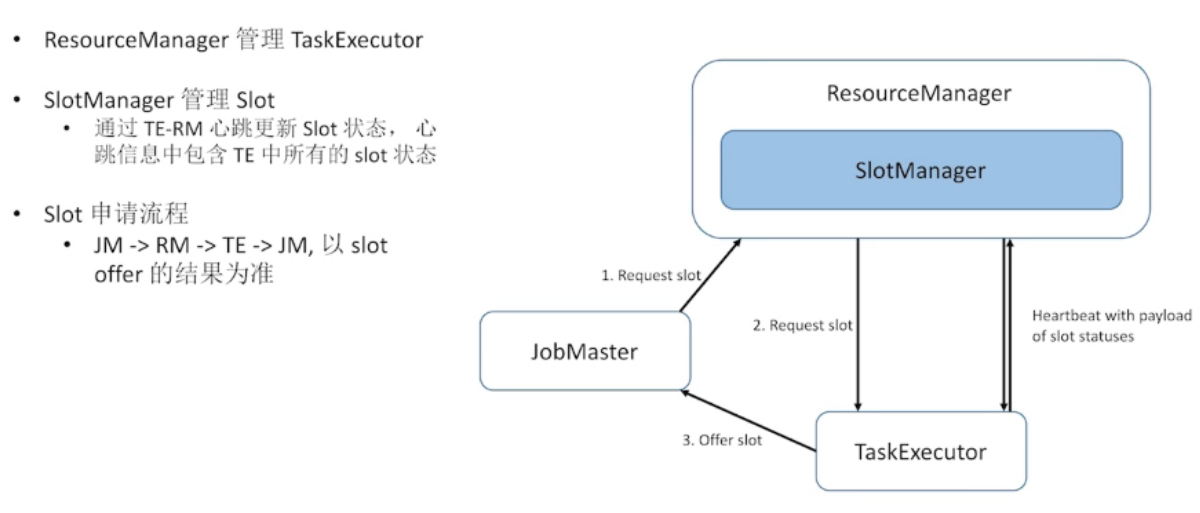
3.4、ResourceManager — 资源管理中心
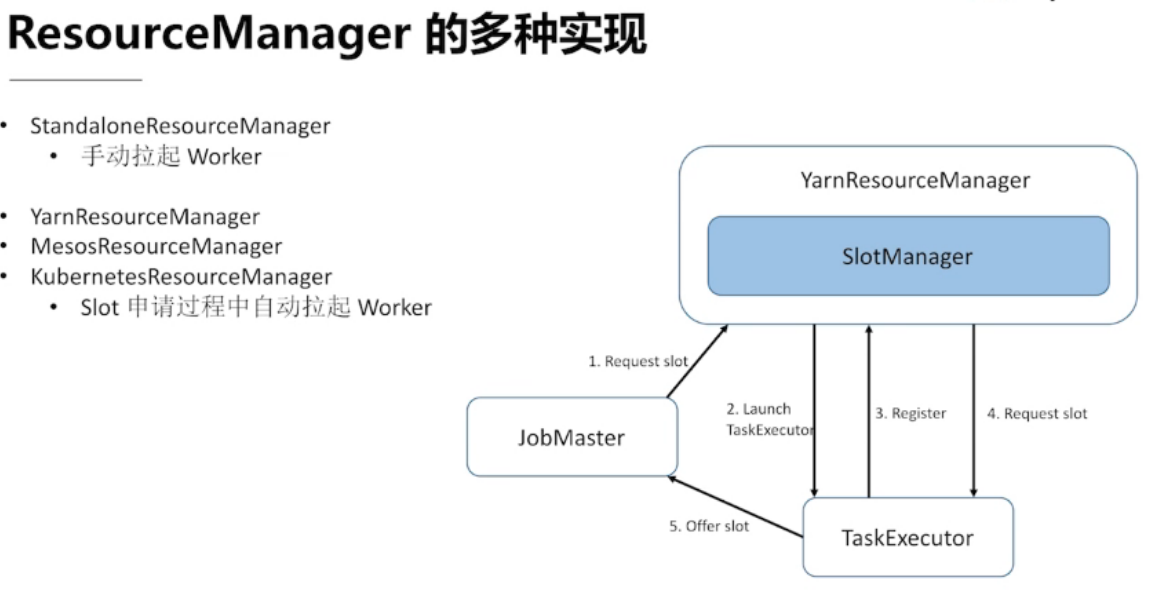
第四章 流计算的状态 和 容错机制

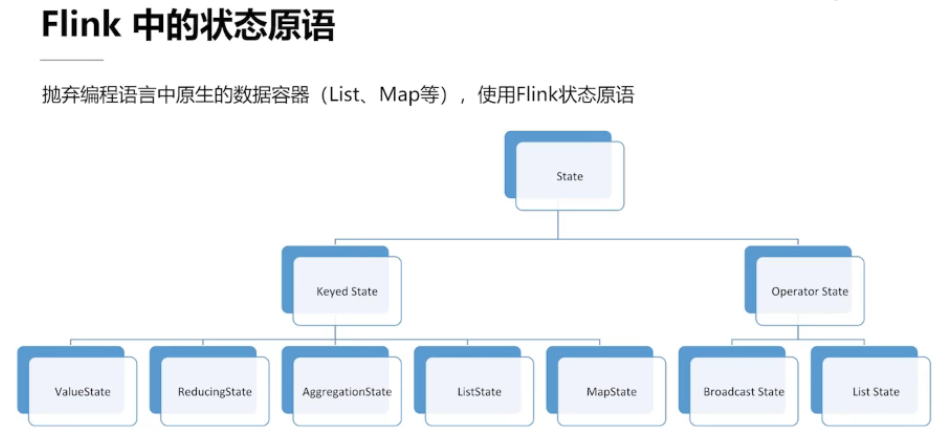
4.1、流计算中的状态

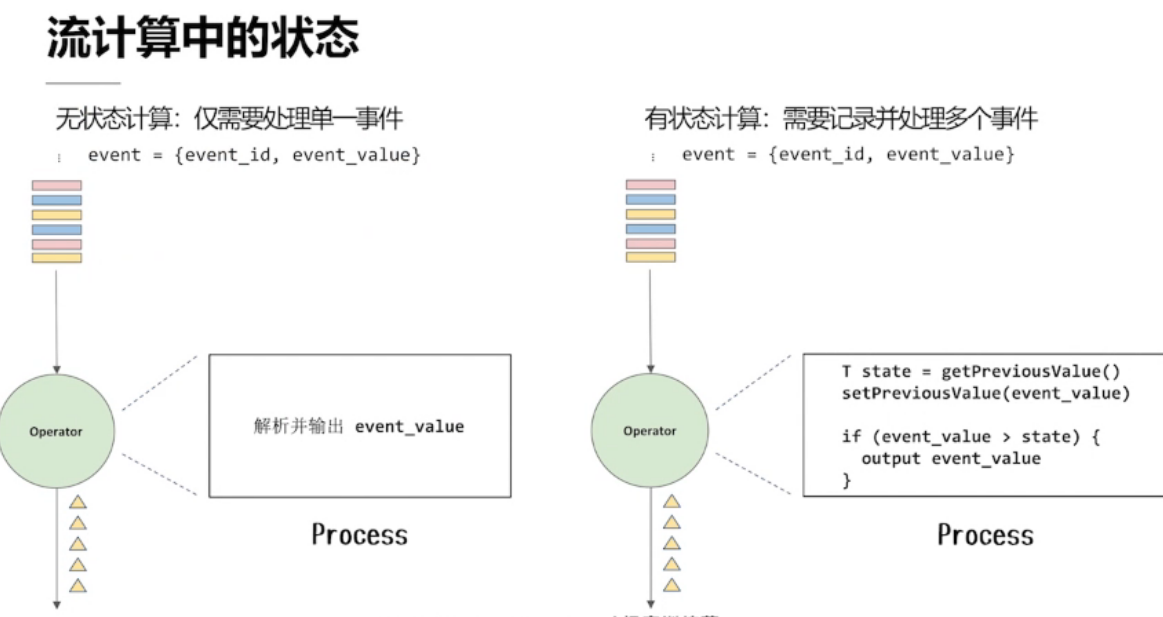
状态的种类

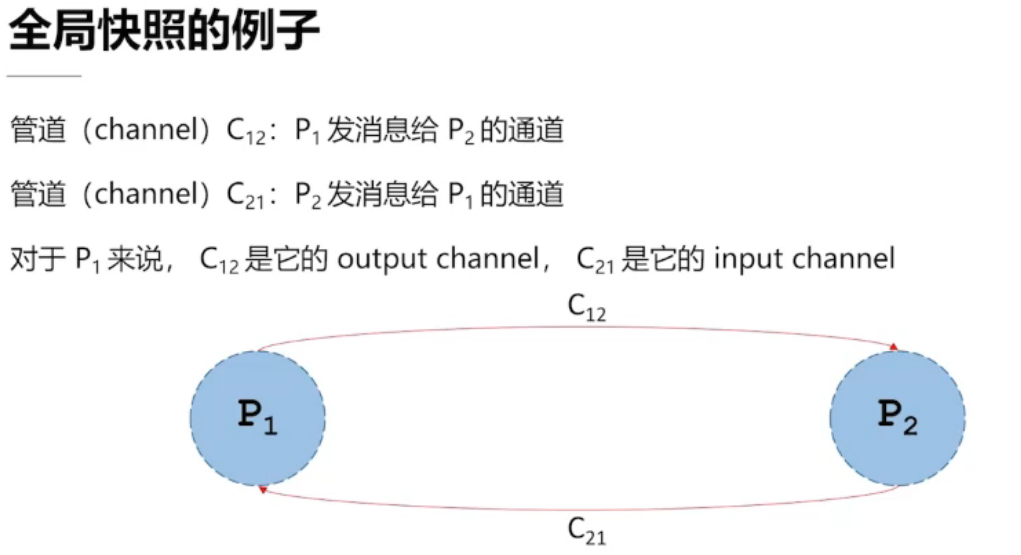
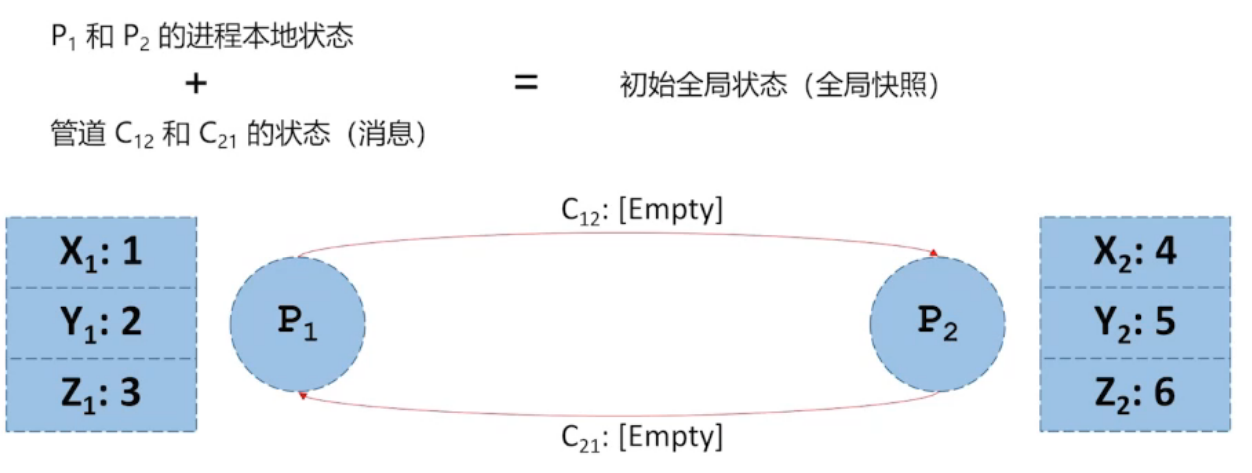
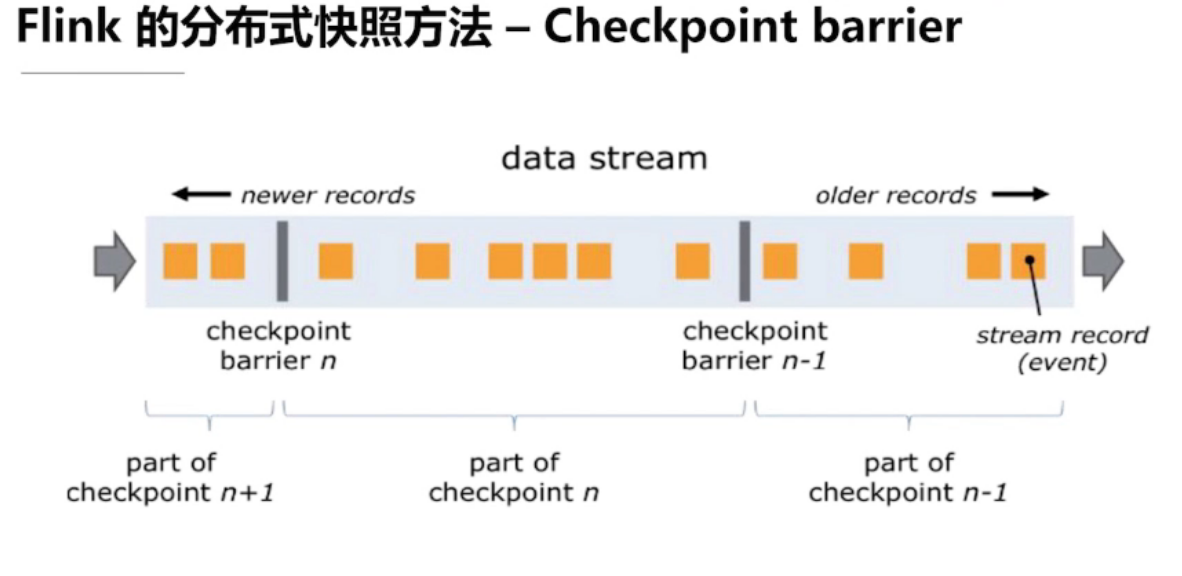
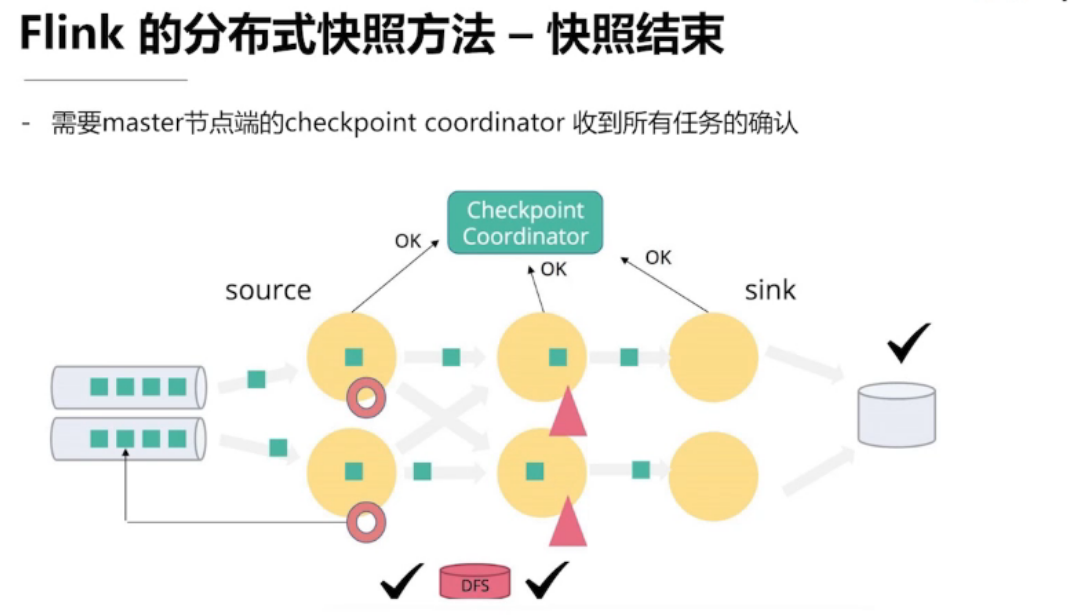
4.2、全局一致性快照



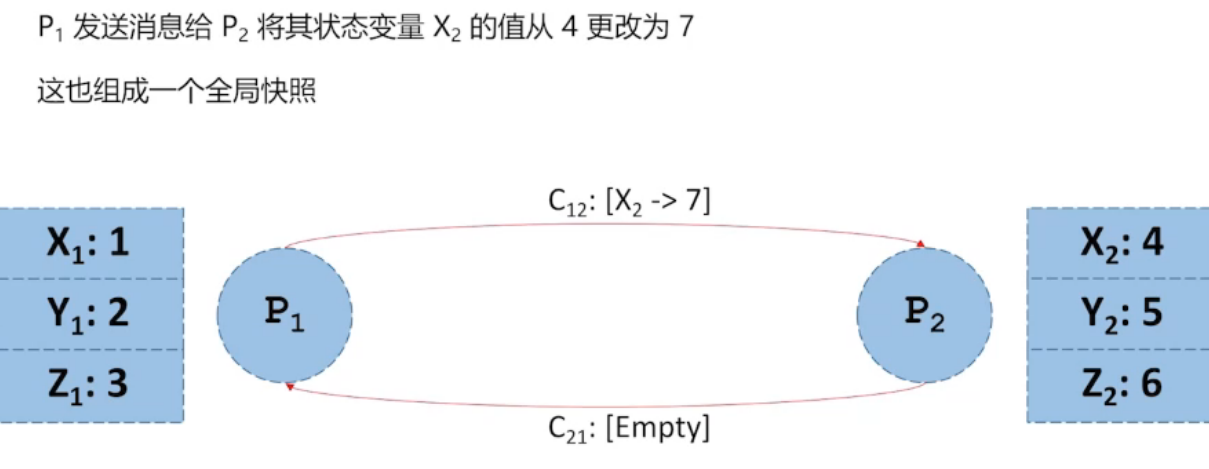
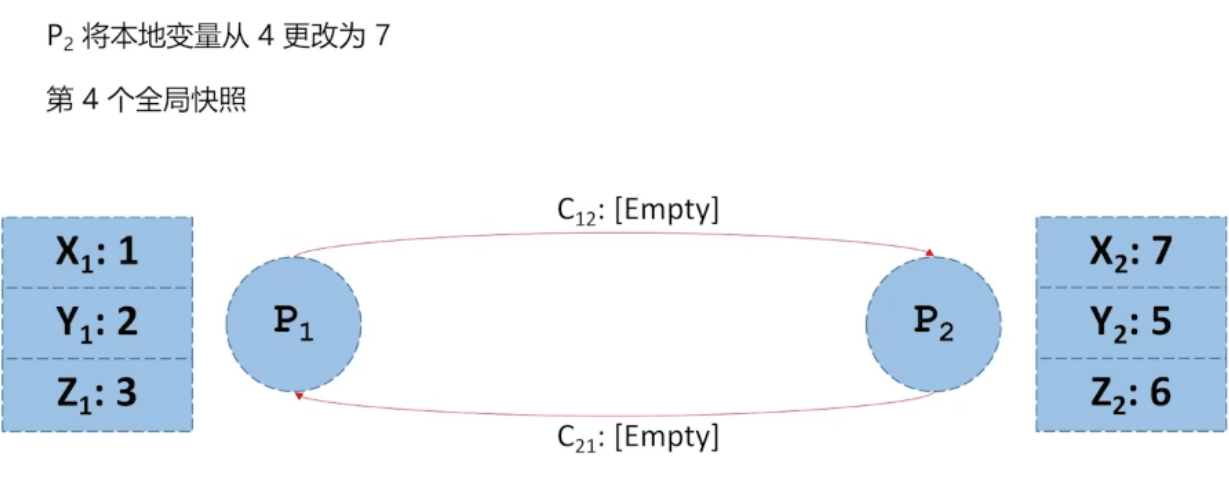

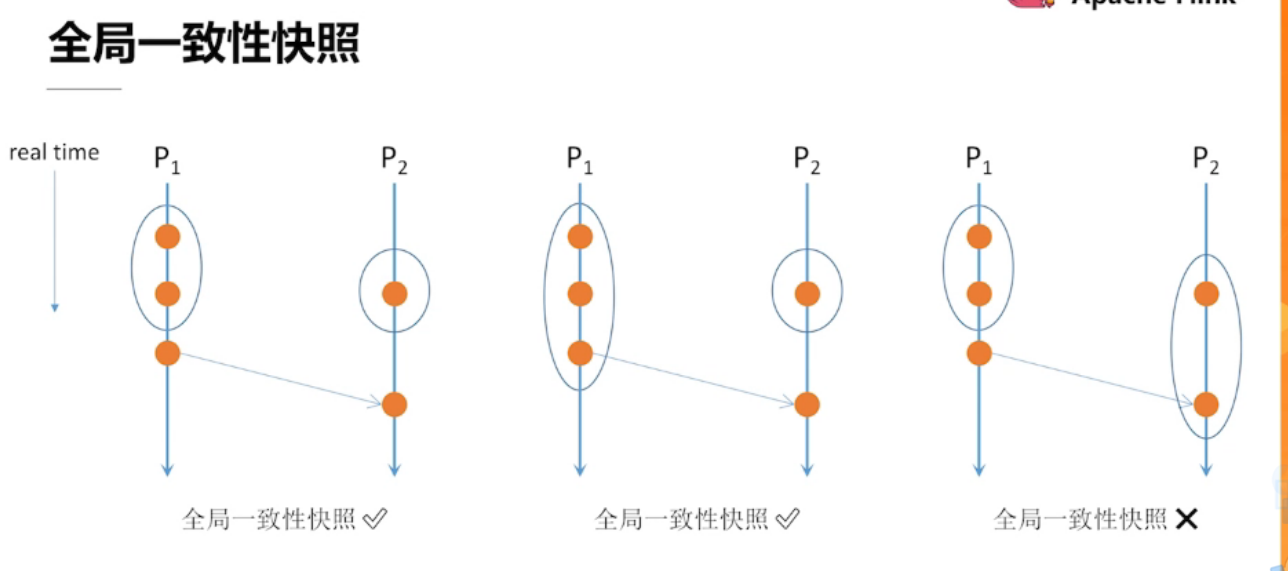
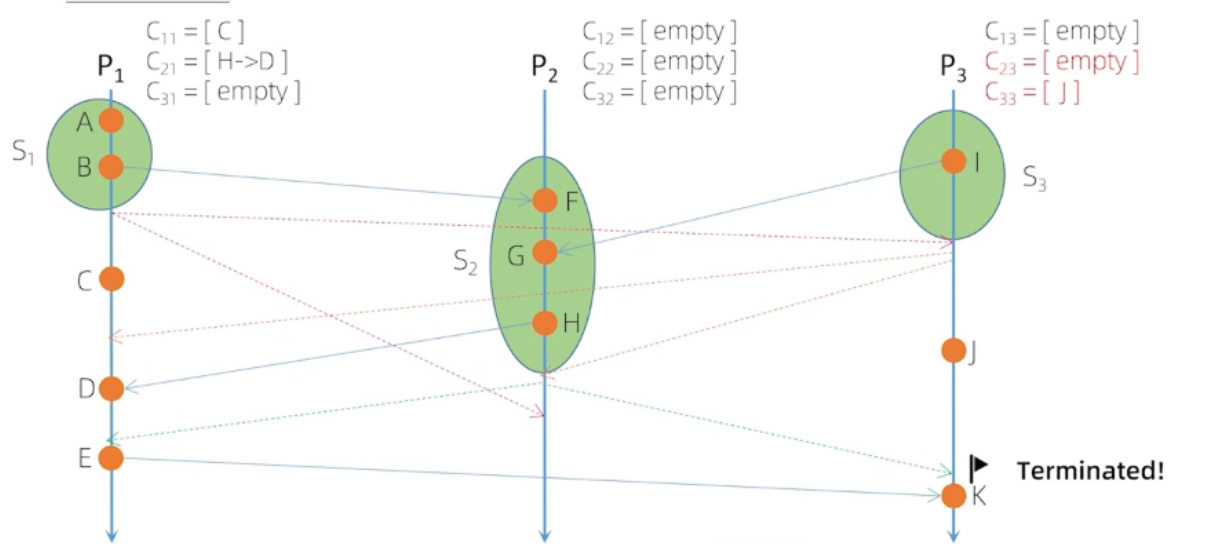
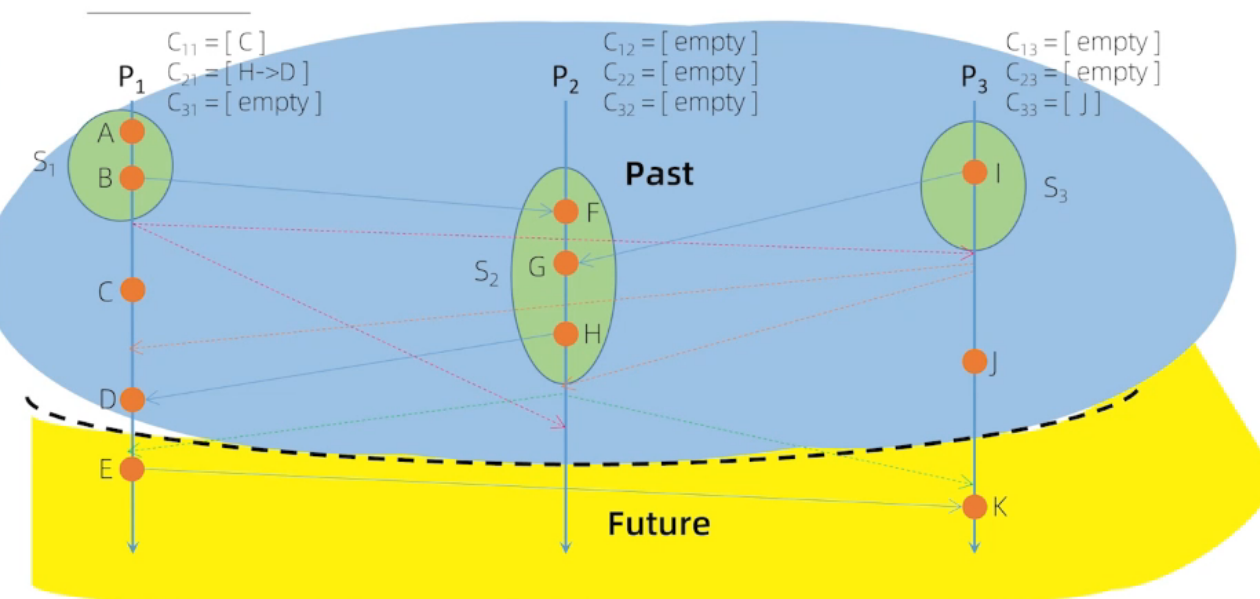
第三张图,后发生的事件包含在快照中,而 先发生的事件没有包含在快照中,所以不是 全局一致性快照
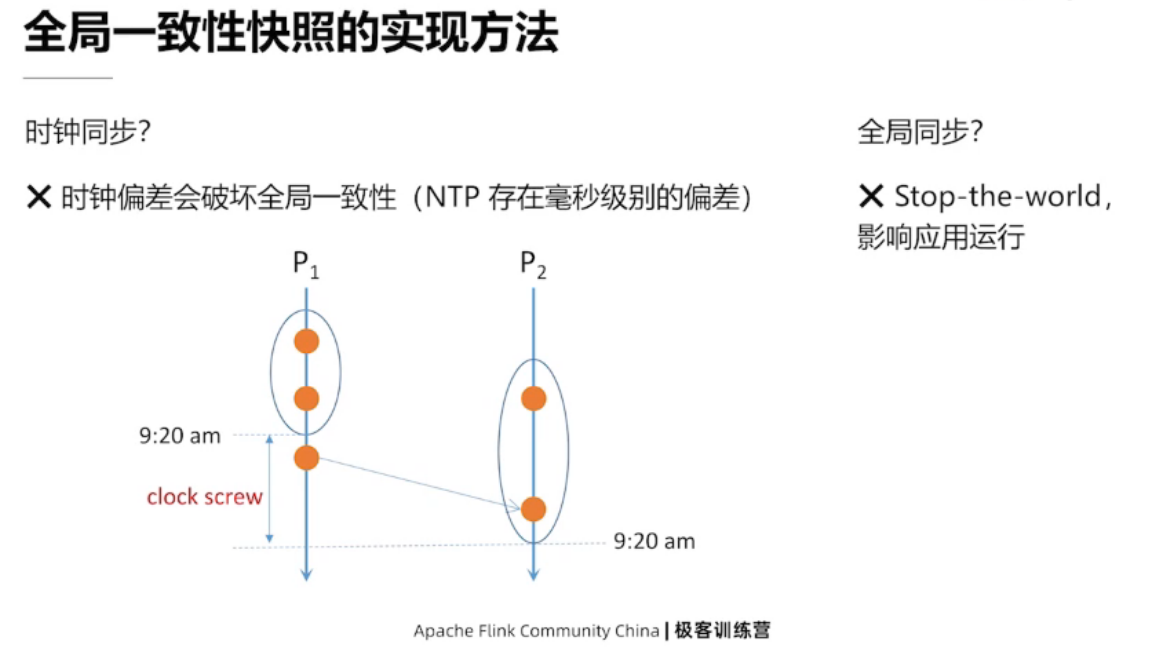
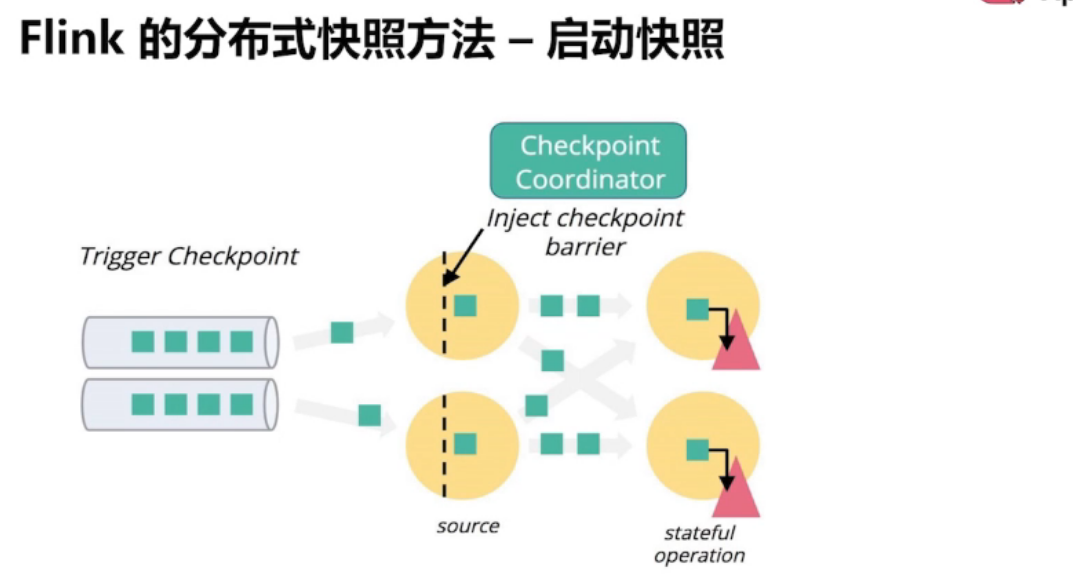
全局一致性快照的实现方法
异步全局一致性快照算法

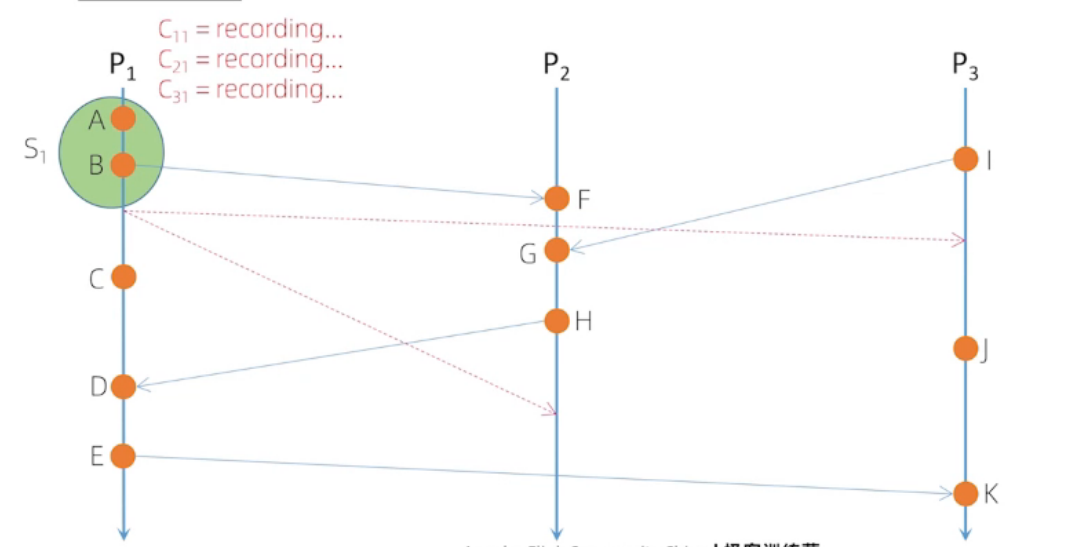
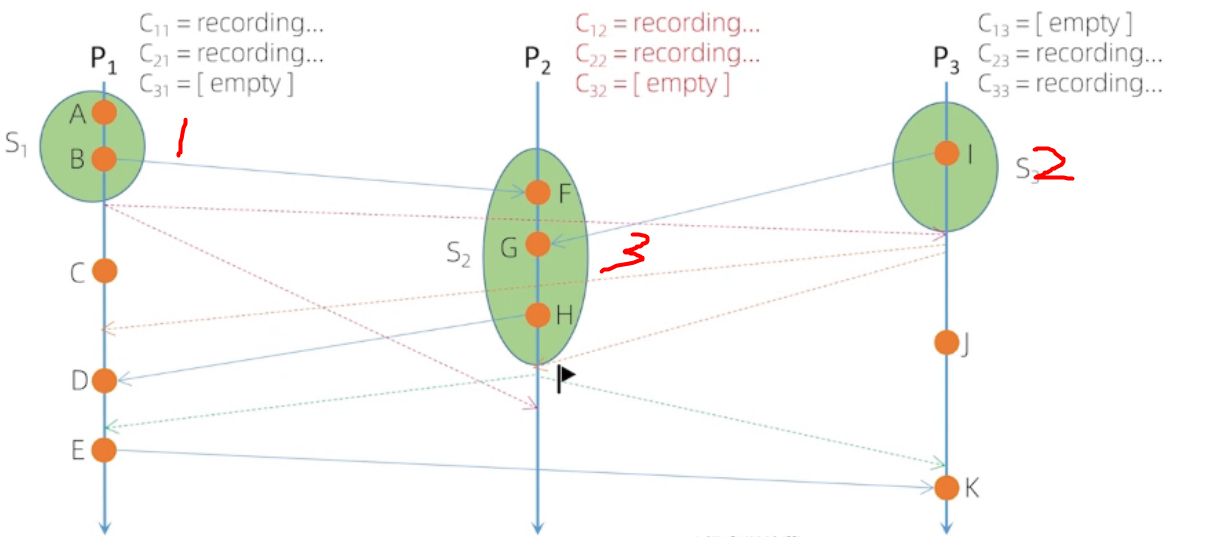
Chandy-Lamport 算法流程
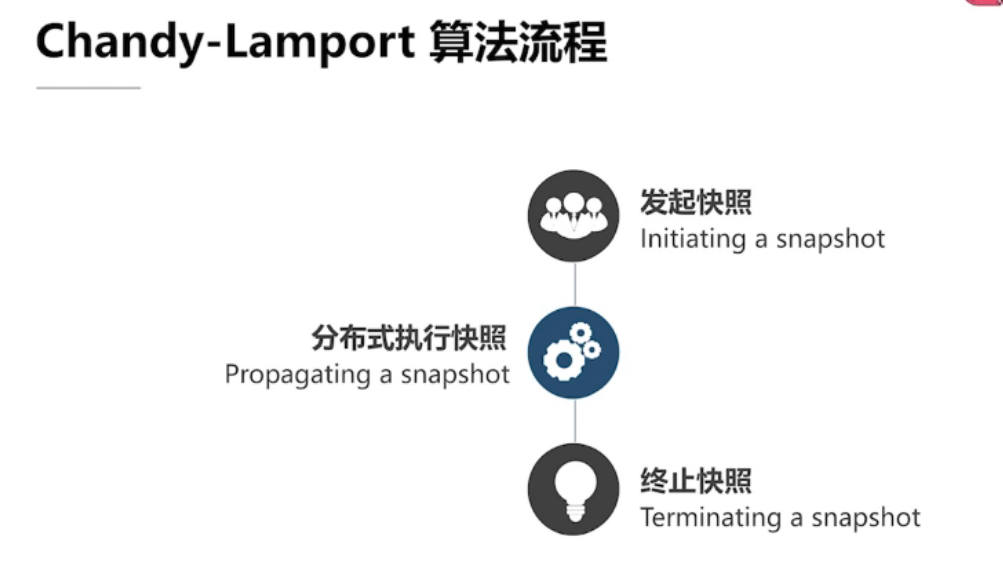
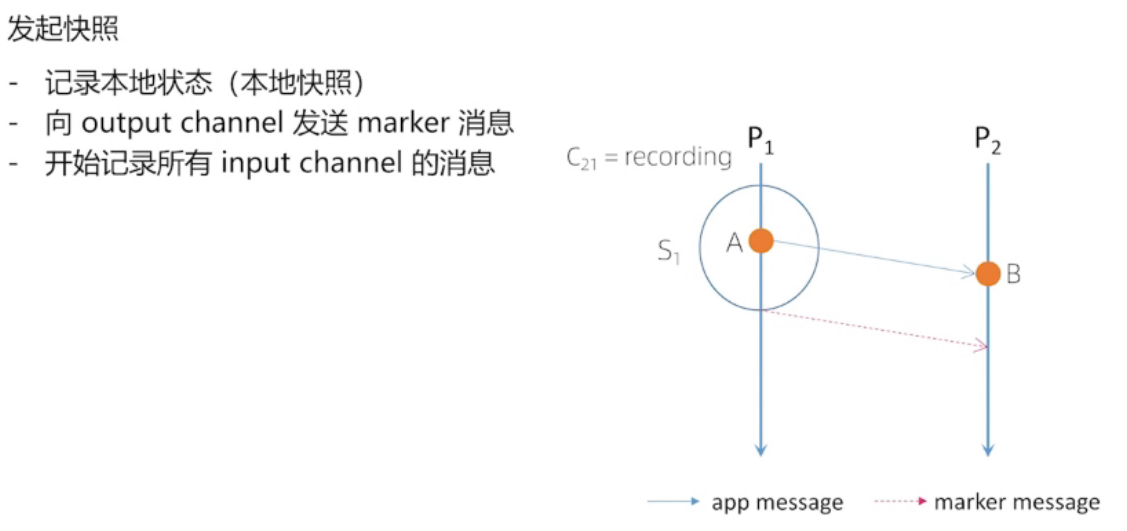
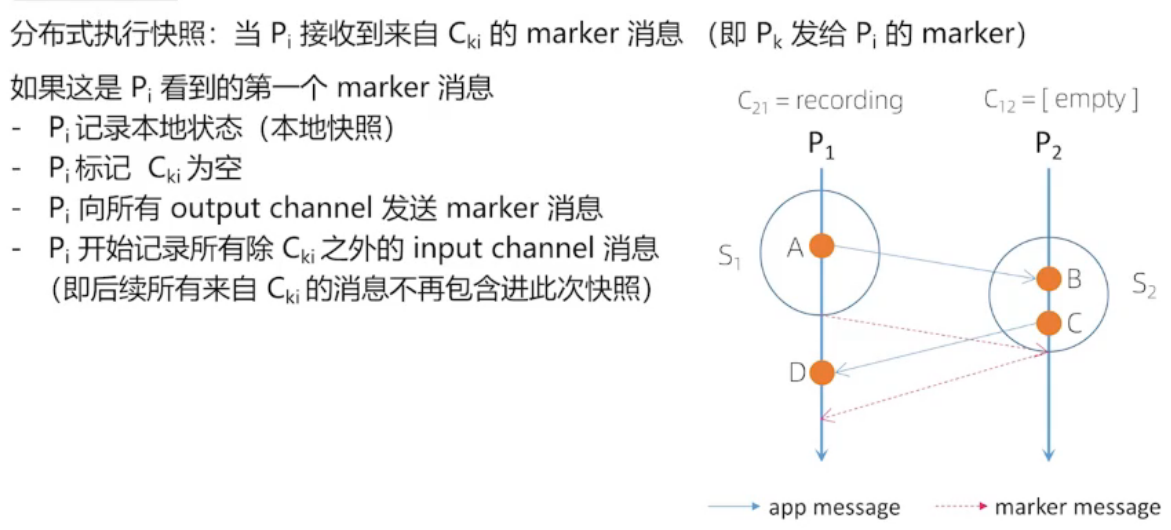
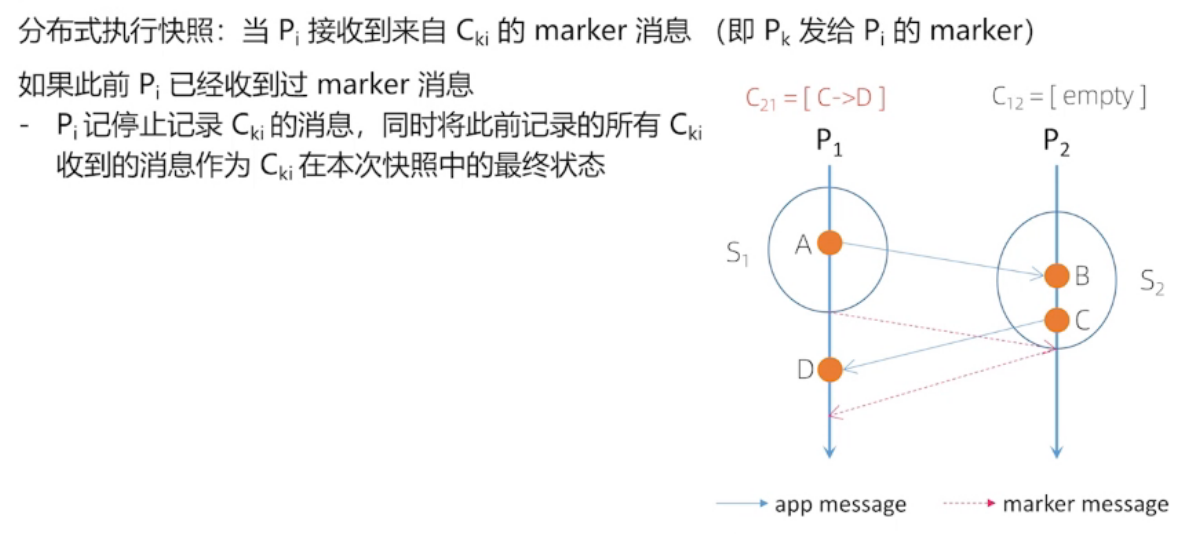
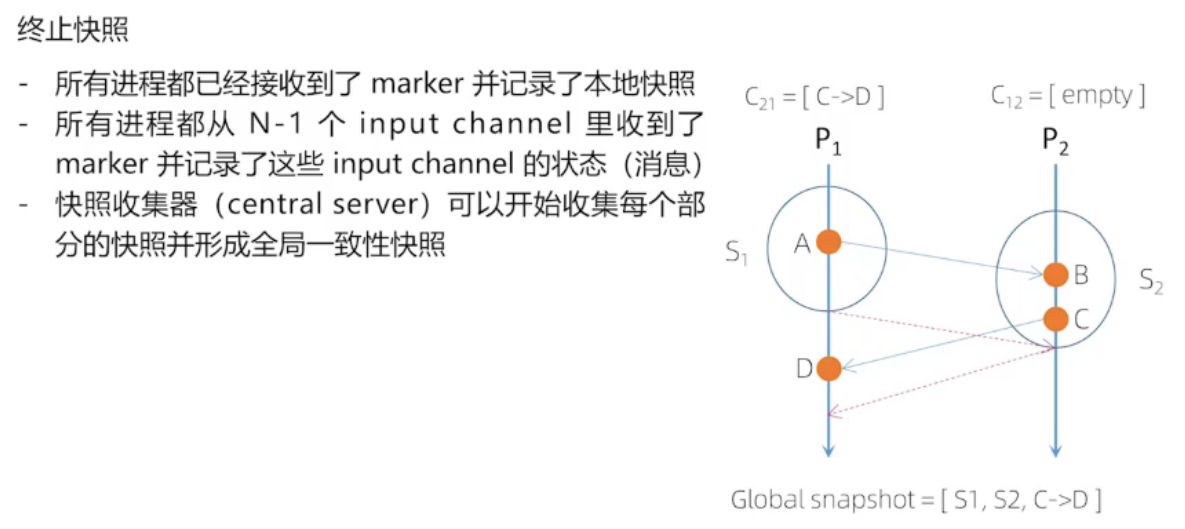
实线代表: 开始快照
虚线代表:结束快照
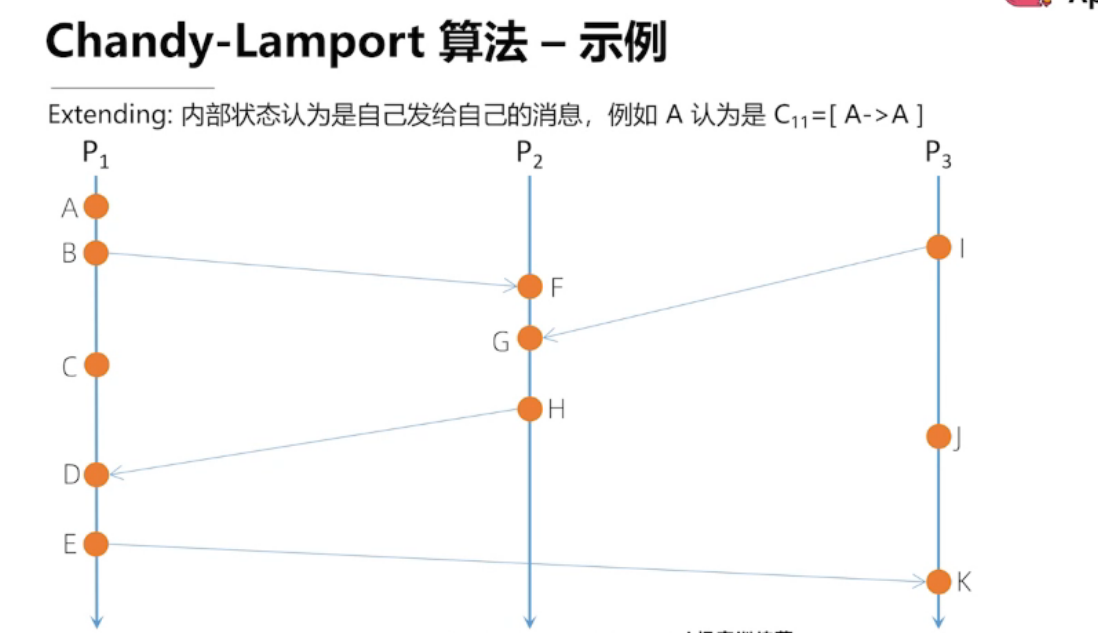
A 是自己内部发生的事件,与其他进程没有交互,我们认为是P1自己发给自己的消息

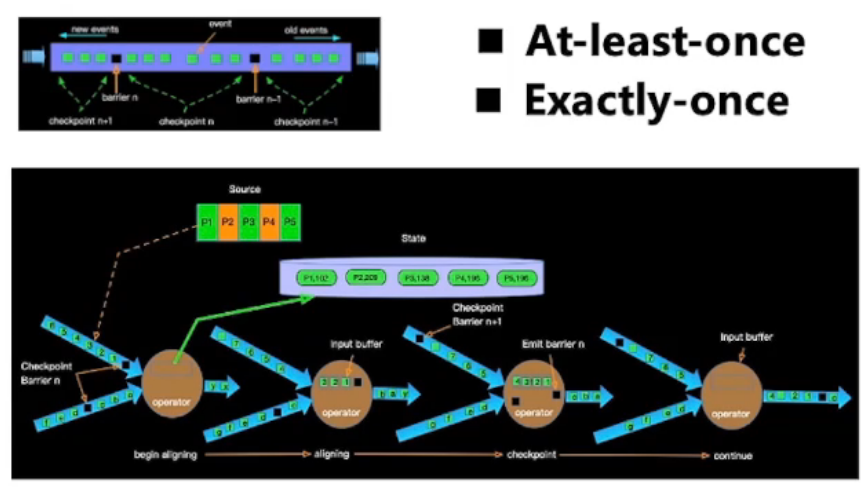
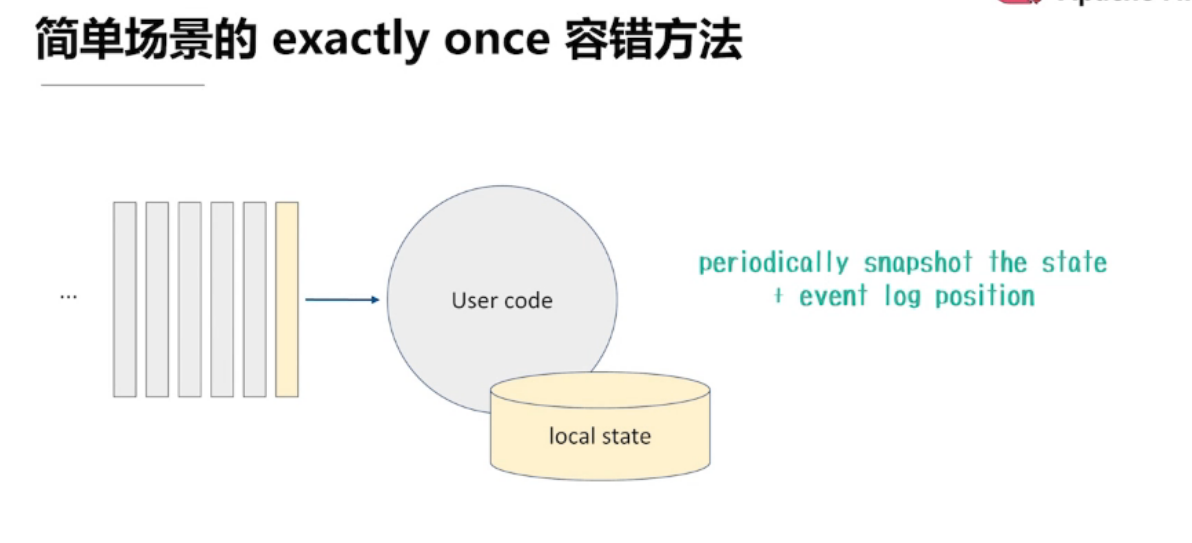
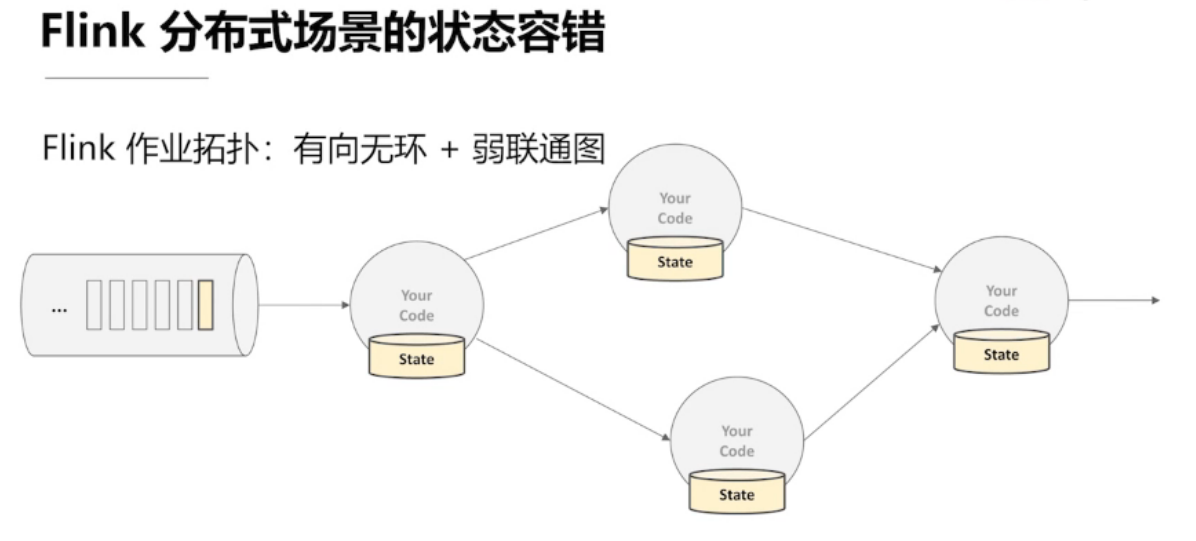
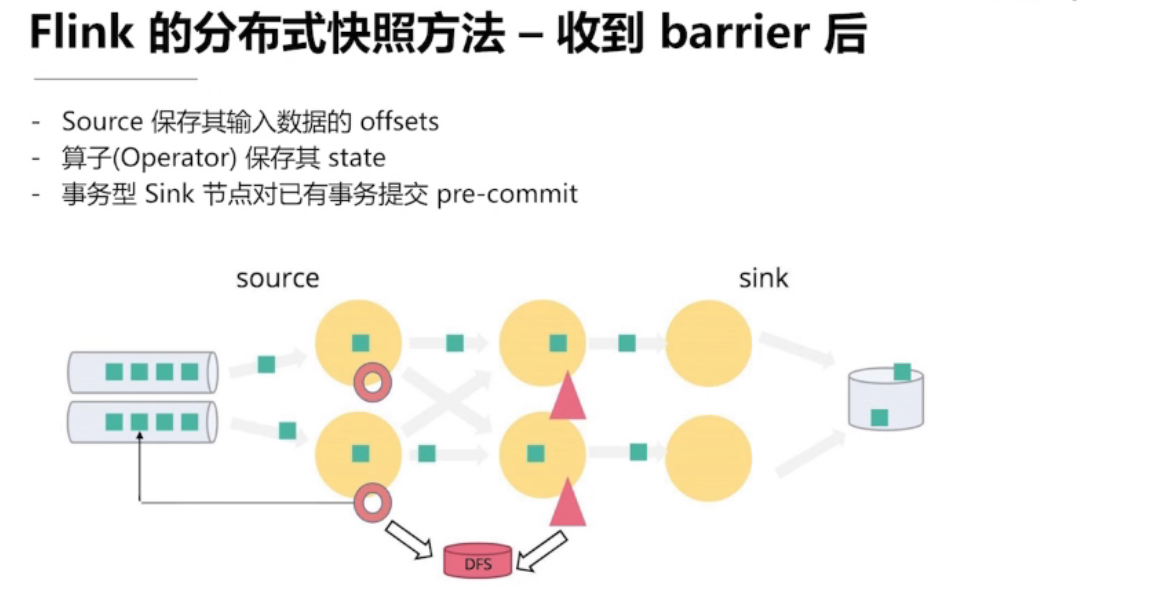
4.3、Flink的容错机制


如何保证 Exactly once

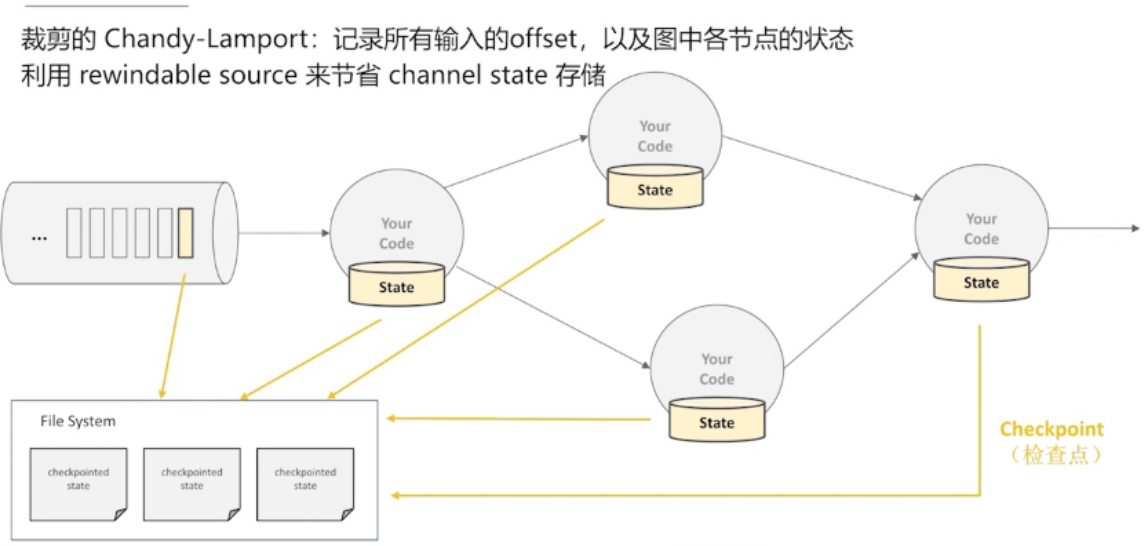
需要一个可回退的 source
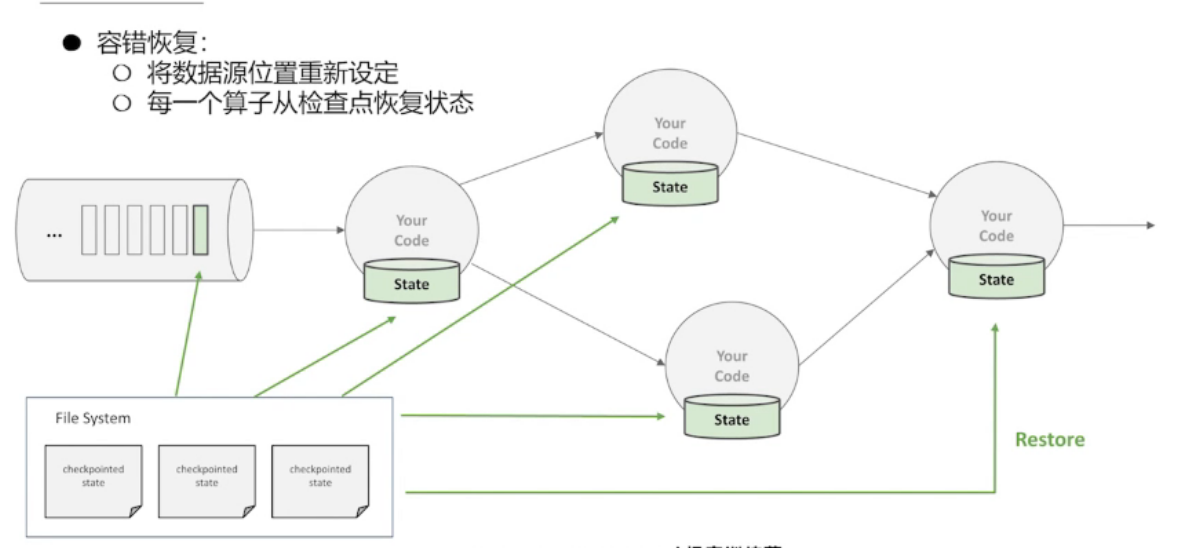
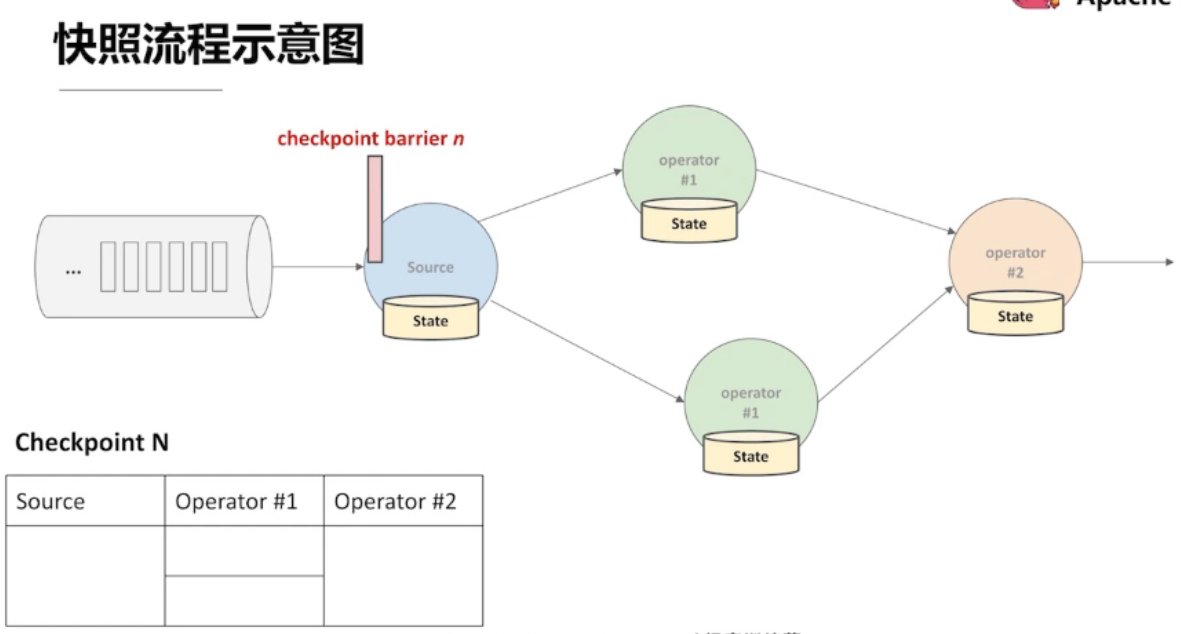
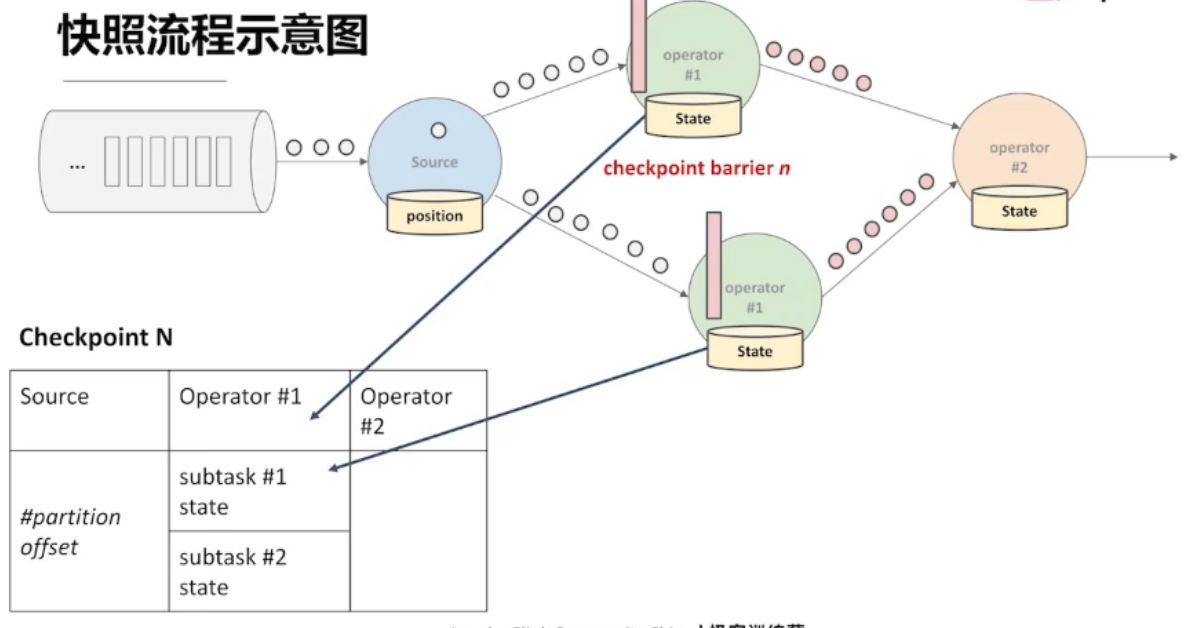
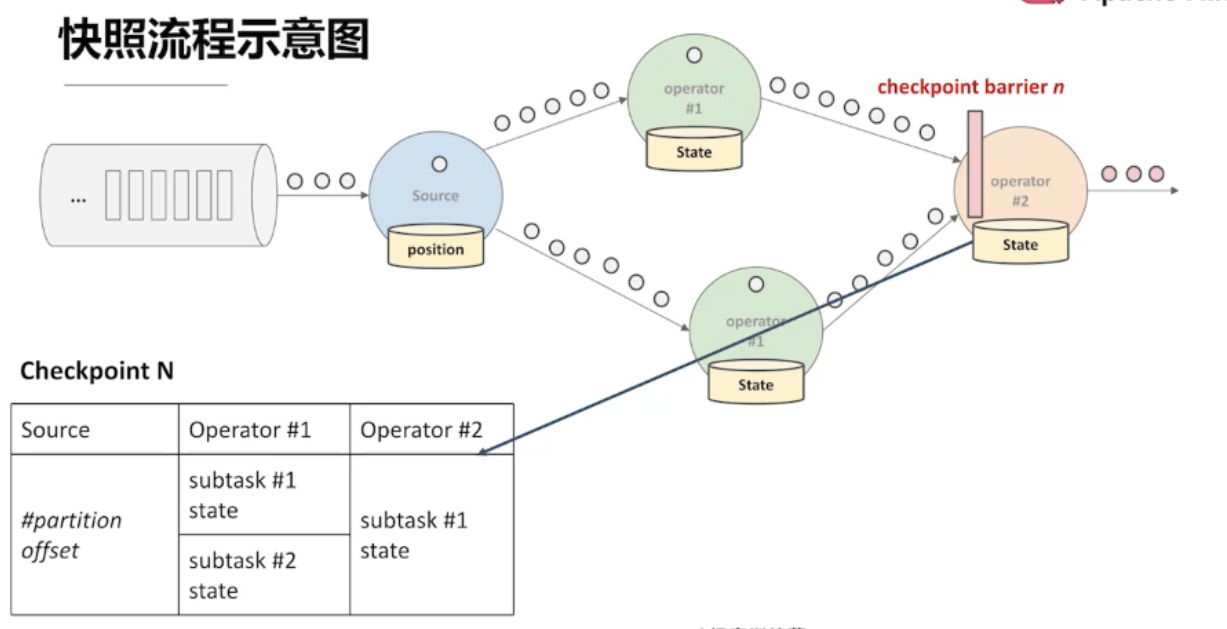
复杂场景 —— 多流输入

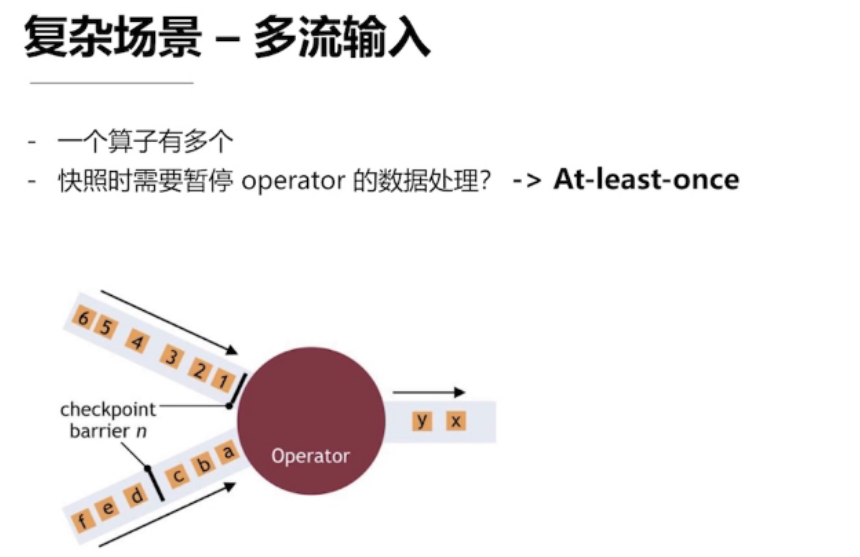
降低一致性要求
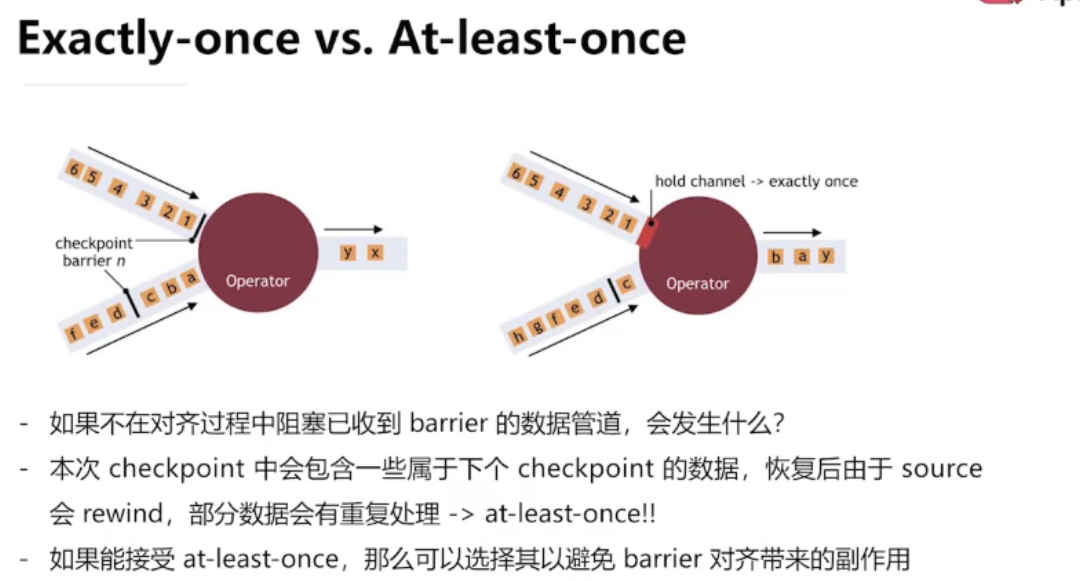
通过异步快照减少停顿

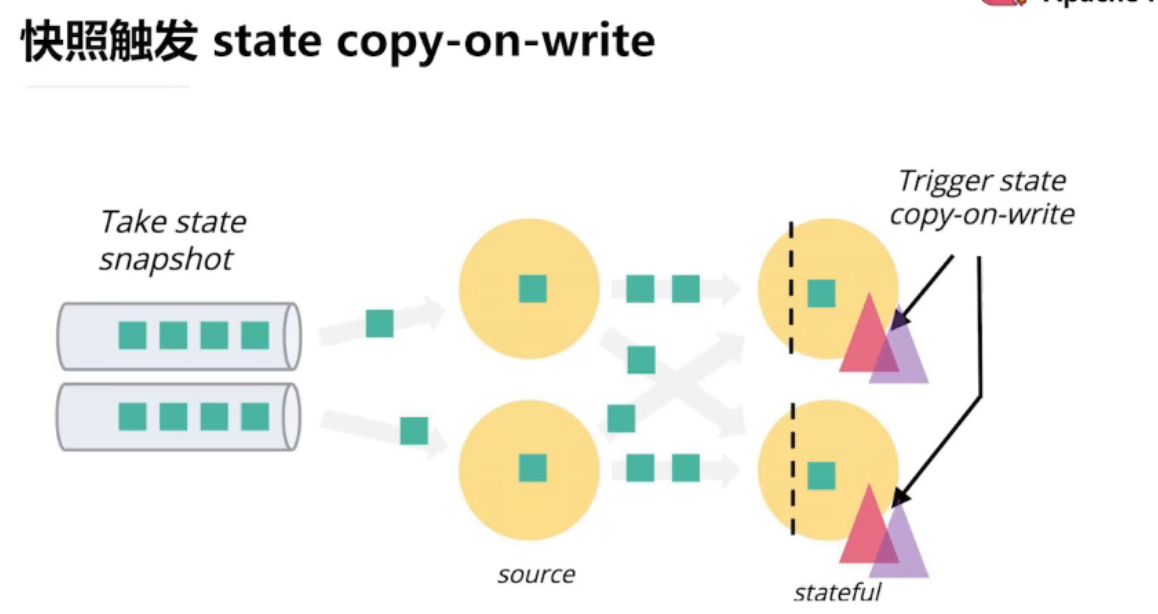
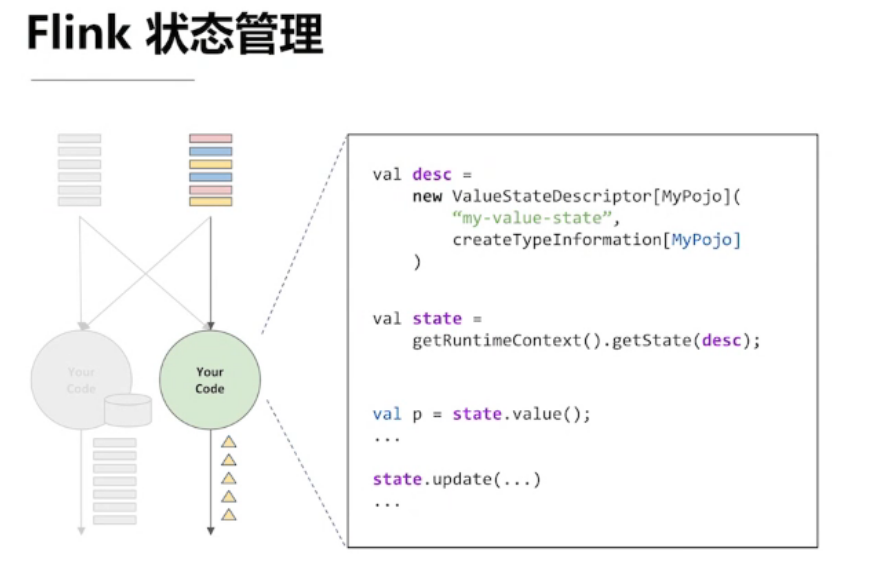
4.4、Flink的状态管理
定义一个状态
本地状态后端 JVM

形成快照的过程需要序列化
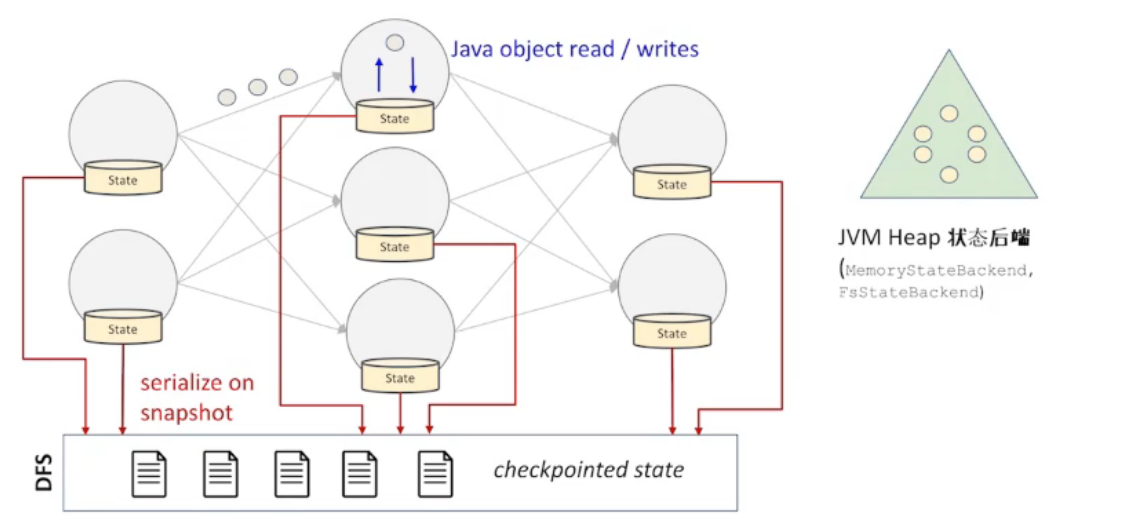
优点:
缺点:
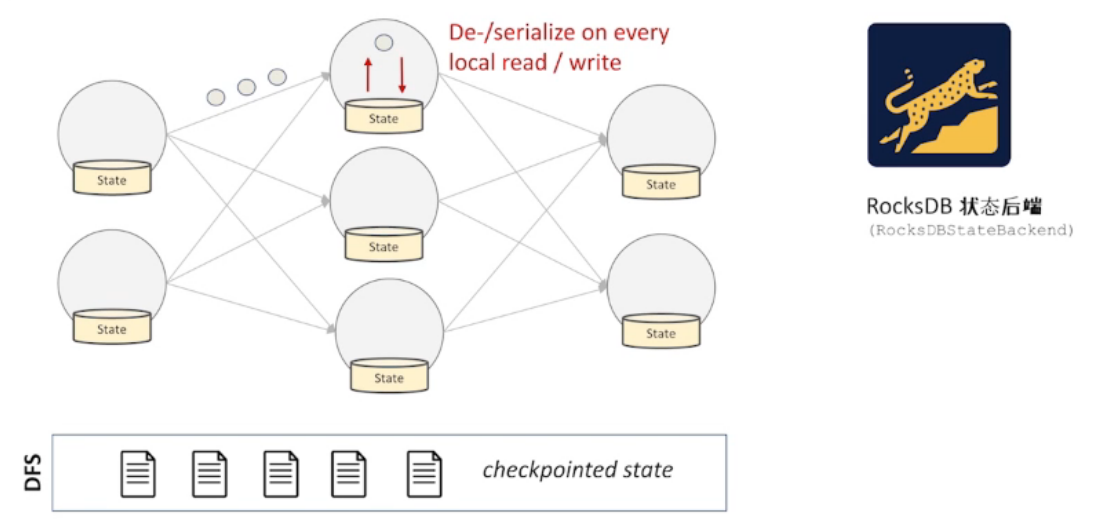
RocksDB 作为状态后端
第5章 Flink SQL/Table API 介绍与实战
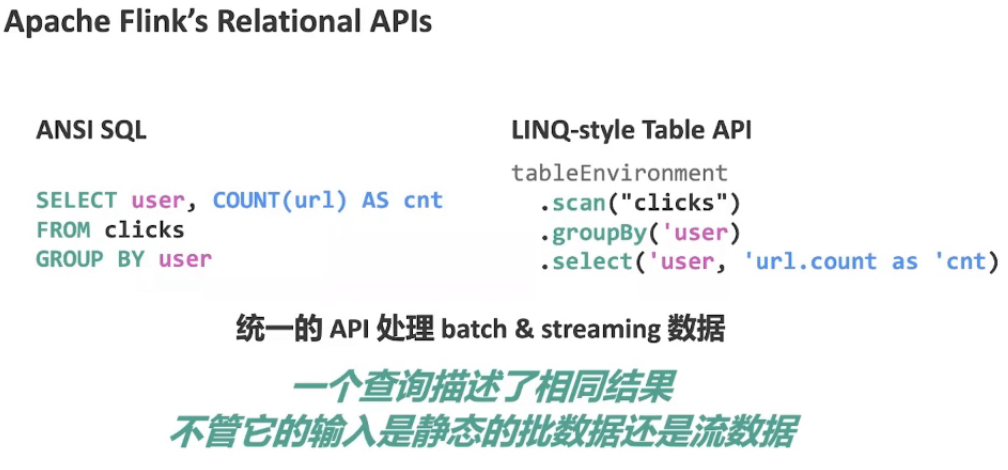
5.1、Flink SQL




声明式:用户只需要表达他需要什么,不需要关心怎么计算的
批流统一:SQL很容易做批处理,不管输入是静态的批数据,还是动态的流数据,结果是相同的
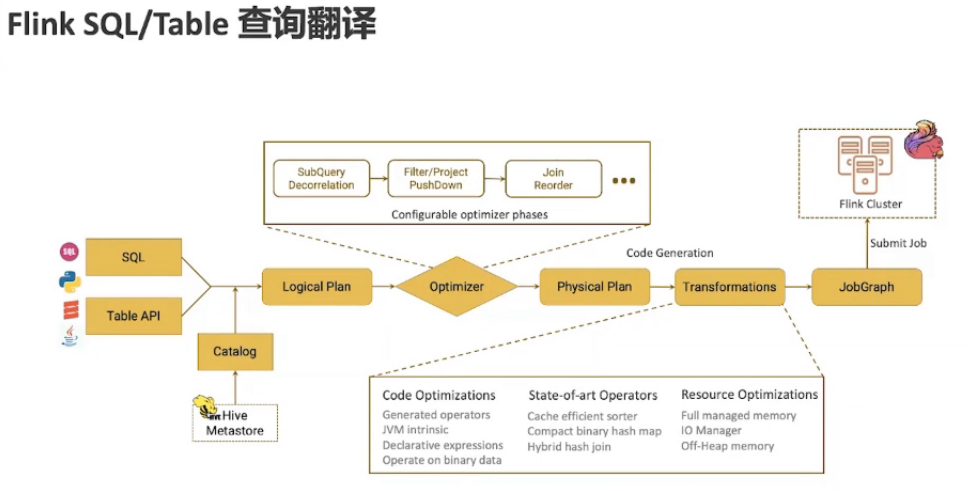
sql/python/scala/java 的api 被翻译成 Logical Plan,Logical Plan 被优化器 优化成 Physical Plan,然后翻译成 Transformations 的DAG,再交给 JobGraph 执行

- 完整的类型系统:数据的精度
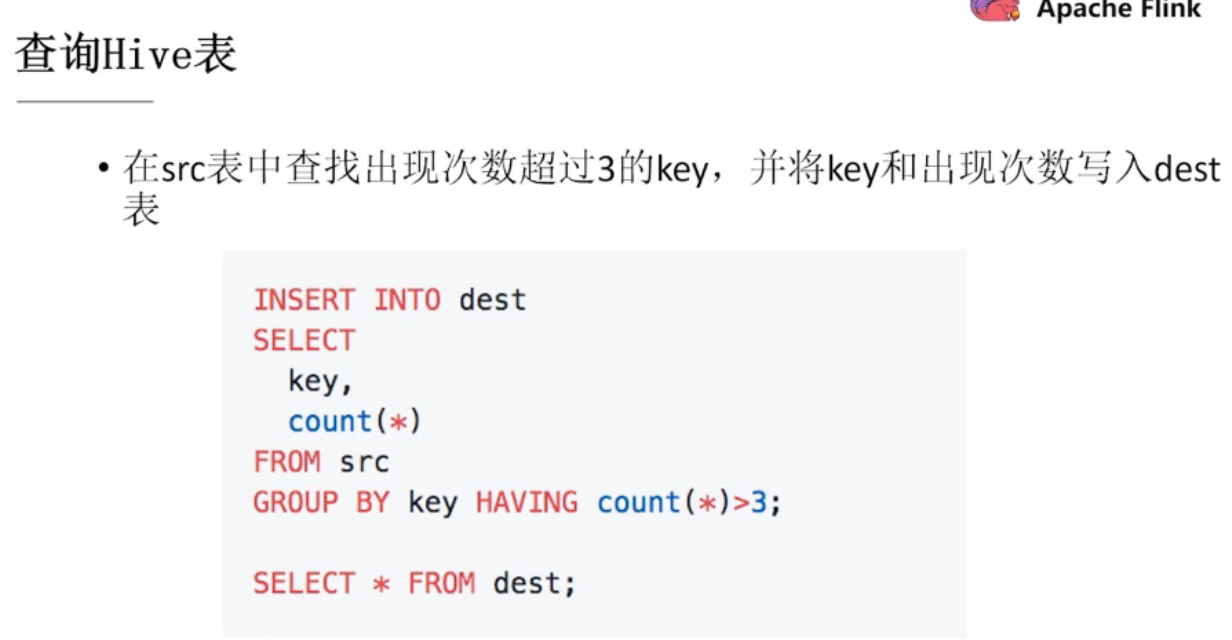
- TopN:
- 高效流式去重:在明细层去重,交给汇总层的时候才会精确
- 维表关联:Mysql、hive、hbase
- cdc:对接canal等 binlog的数据
- 内聚函数:超过230个内置函数
- MiniBash:
- 多种解热点手段:
- 完整的批处理支持
- Python Table API:多语言支持
- Hive集成:读写hive,支持hive sql 语法
5.3 实战Demo
- 前提条件:需要基础的 SQL 知识
- 准备环境:你将需要一个至少 8 GB 内存和安装了 Docker 的笔记本电脑。
- 下载地址:https://www.docker.com/get-started
- 代码:https://github.com/wuchong/flink-sql-demo


6.1、PyFlink简介

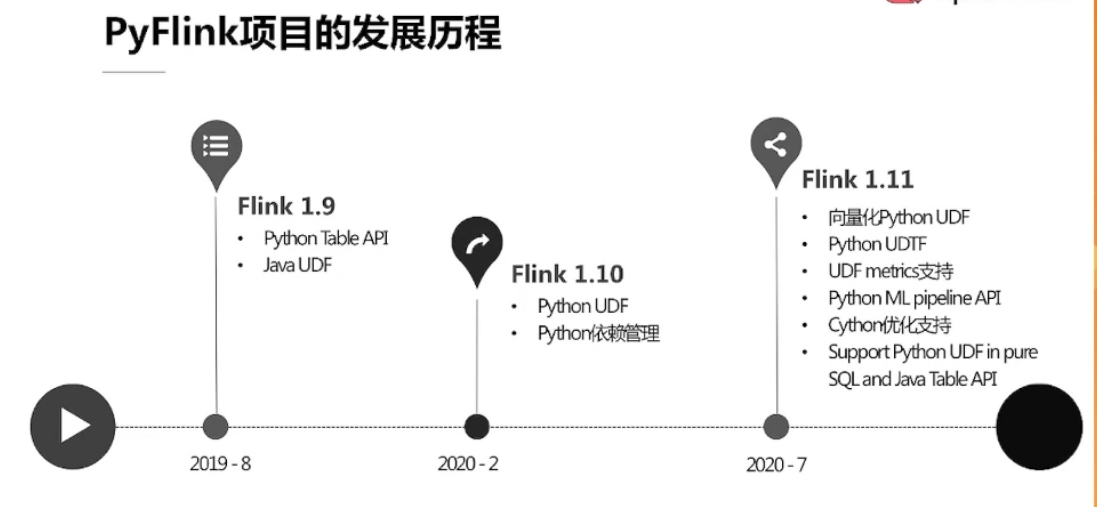
6.2、PyFlink 功能介绍

Python Table API

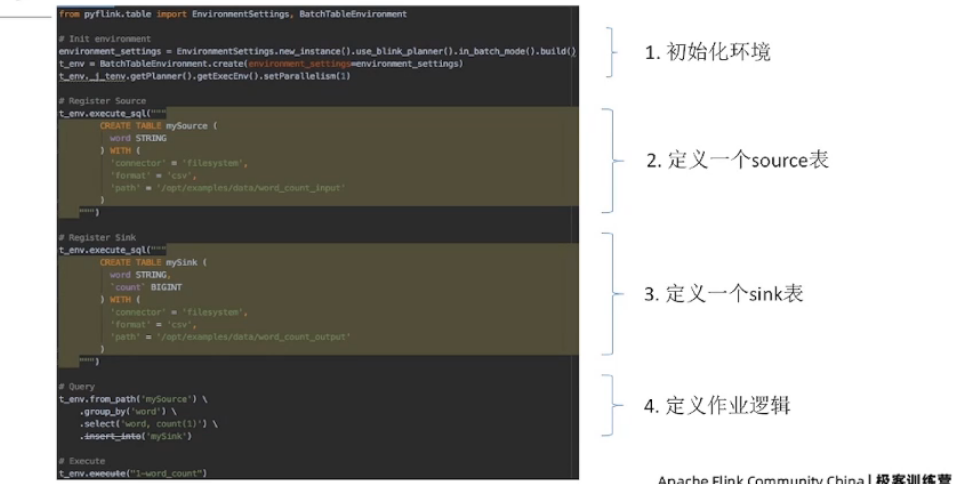
Python UDF



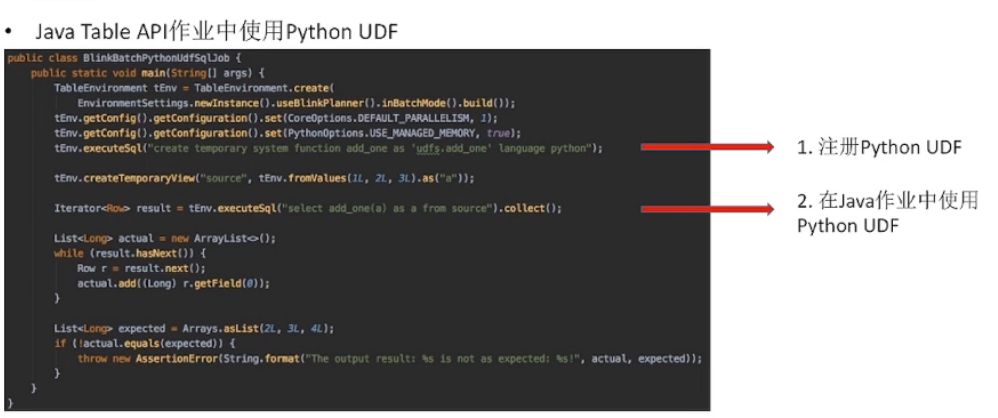
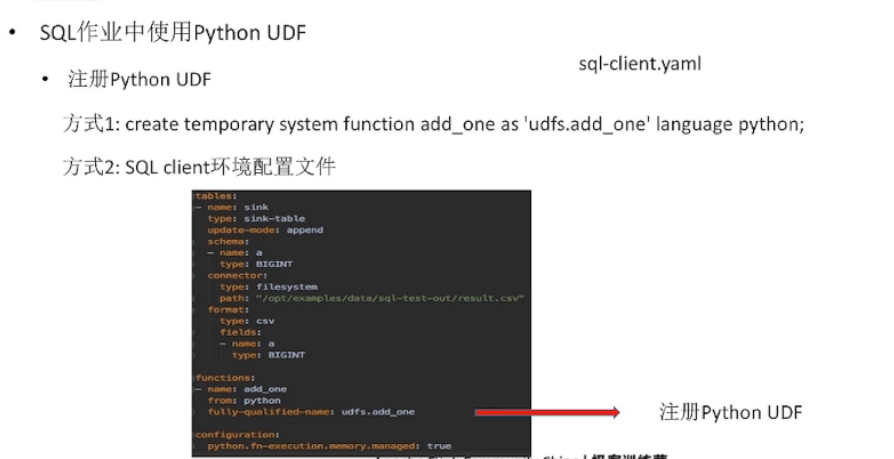

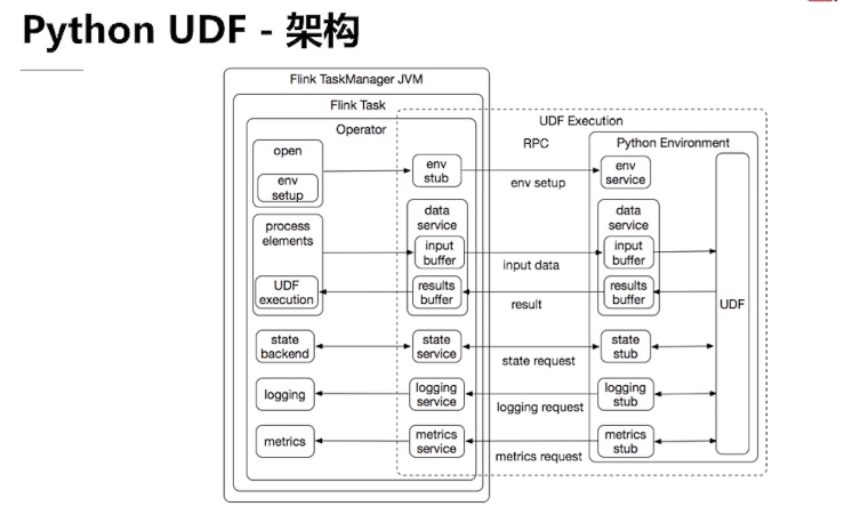
Python UDF 架构
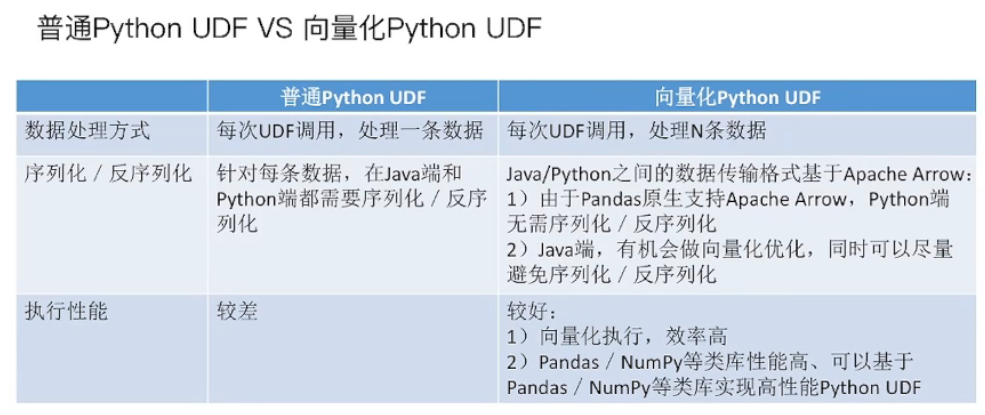
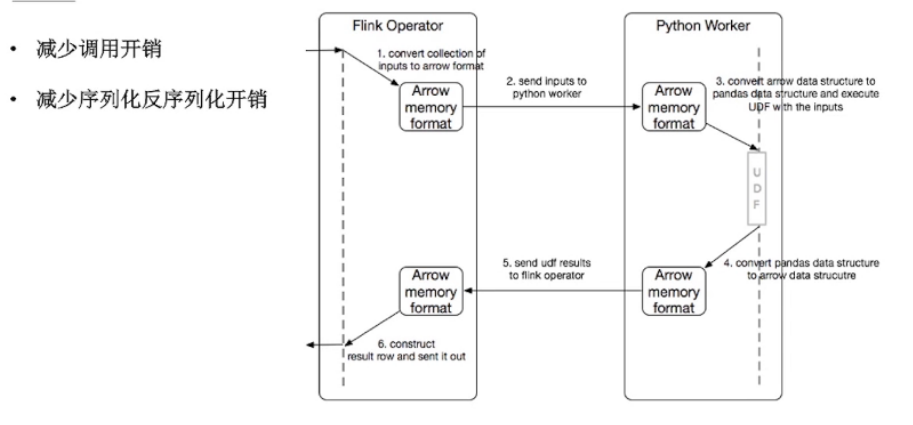
向量化 Python UDF

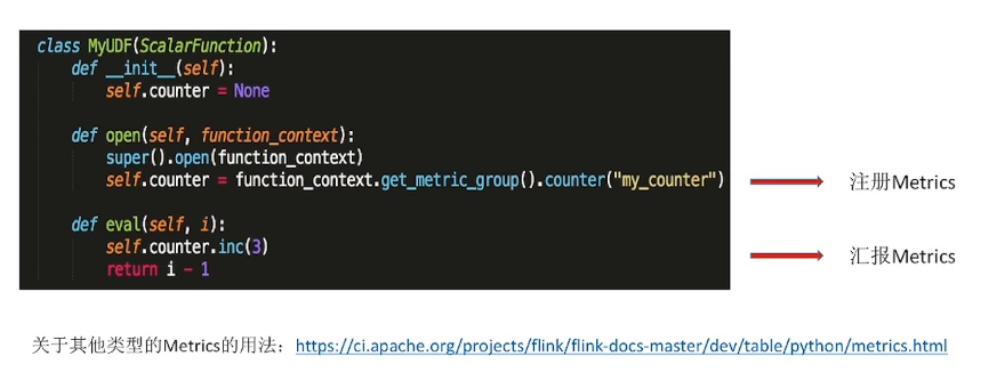
Python UDF Metrics
Python UDF 执行优化



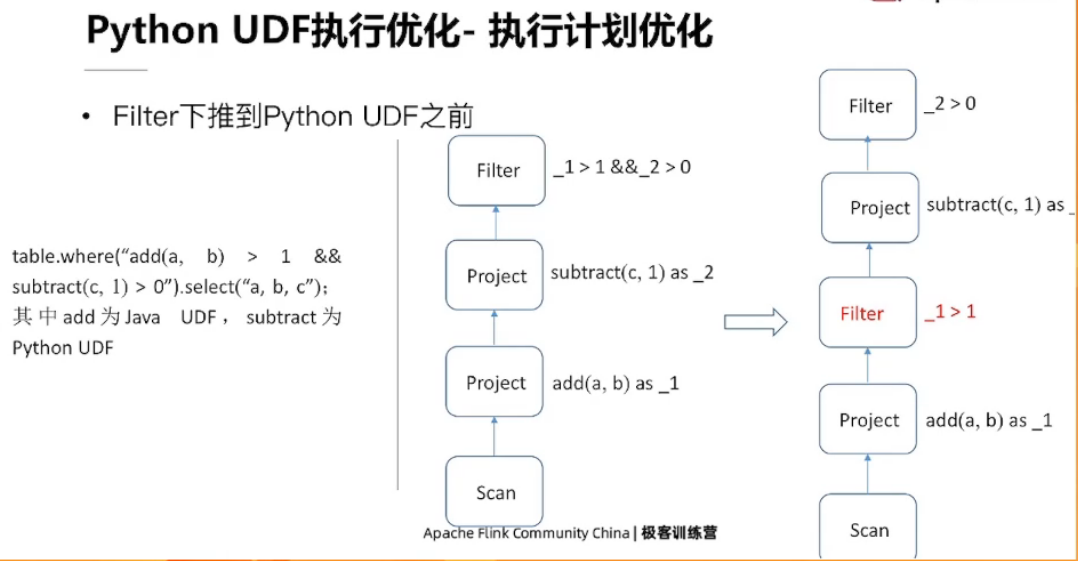

6.4、PyFlink 下一步规划


第七章 Flink Ecosystems 连接外部生态系统

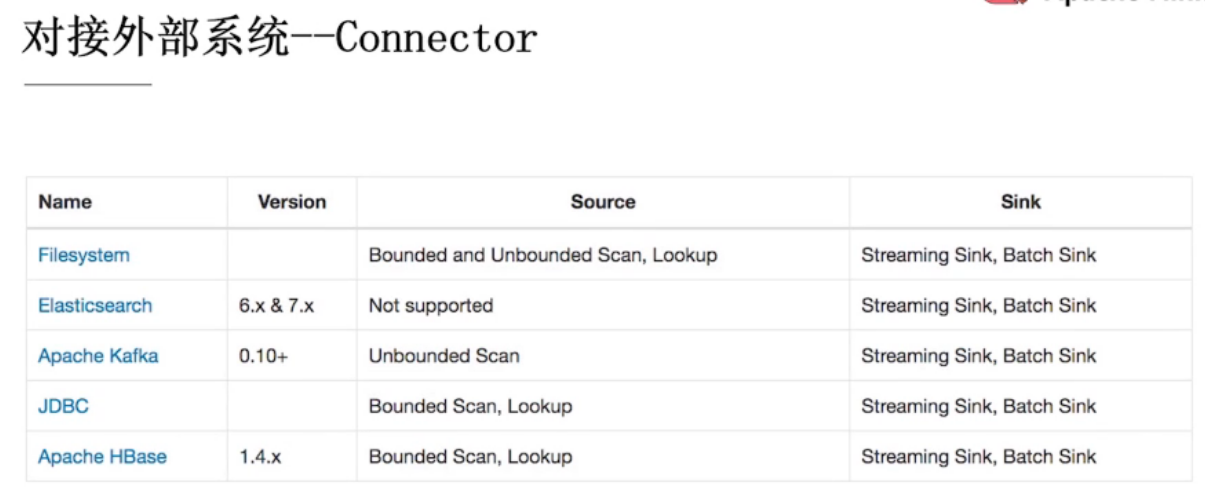
7.1、连接外部系统


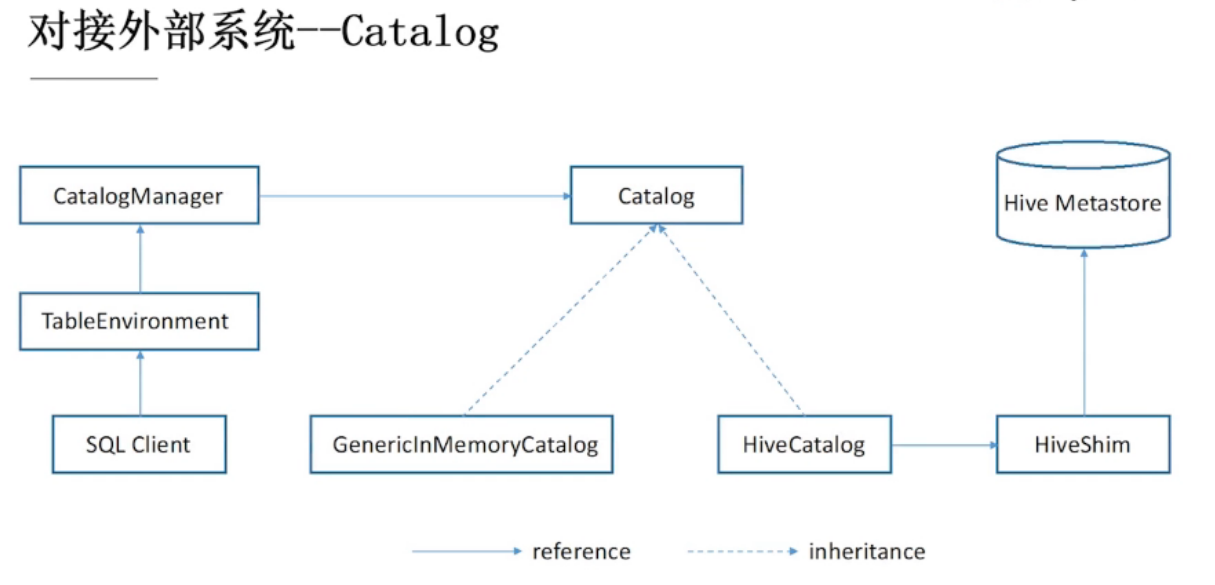
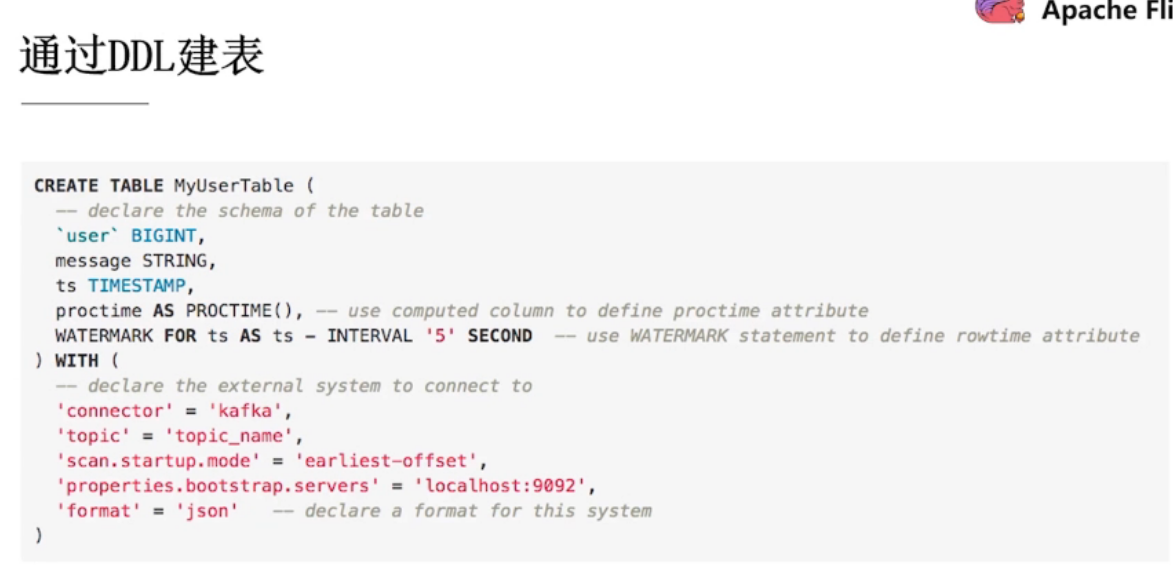
通过DDL创建的表是如何被使用的:
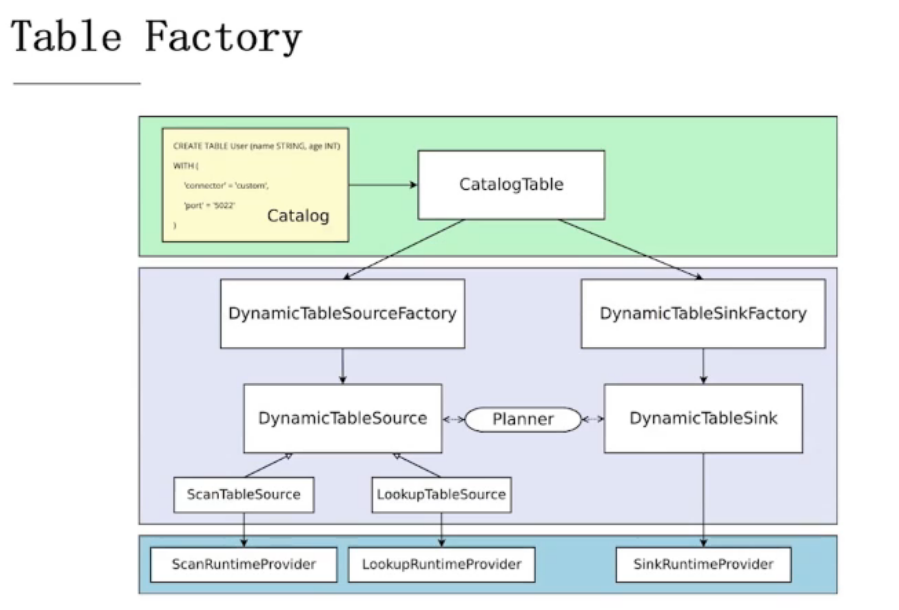
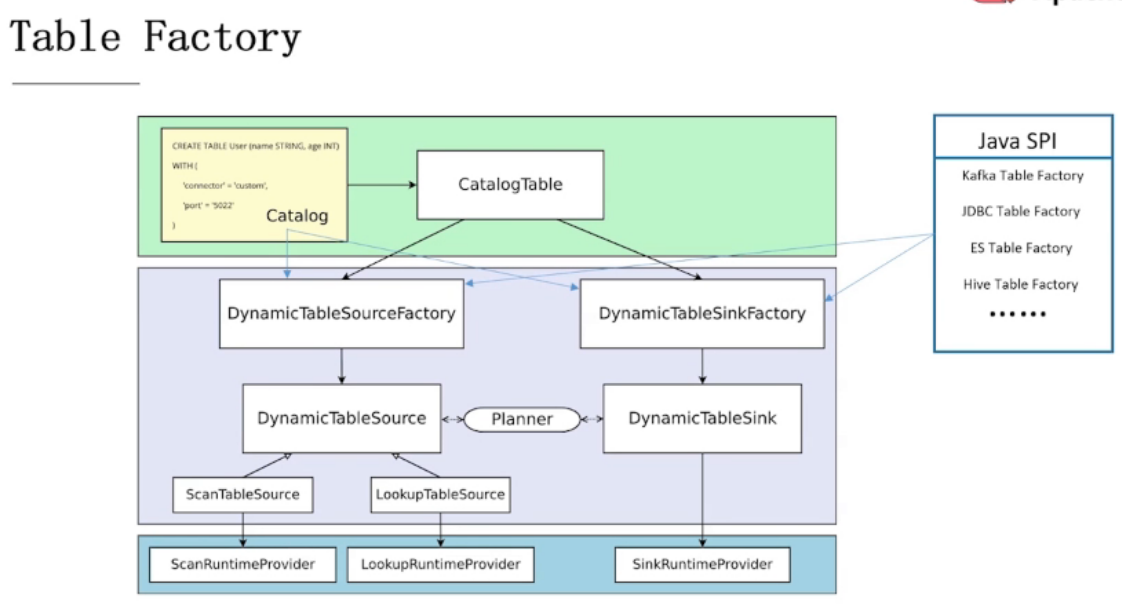
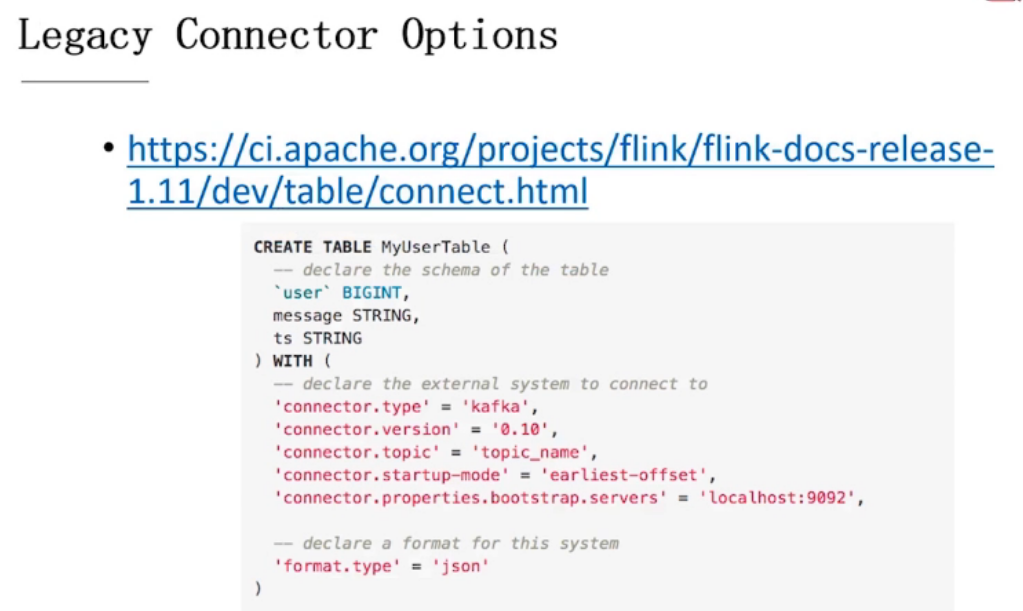
7.2、常用Connector
Kafka Connector
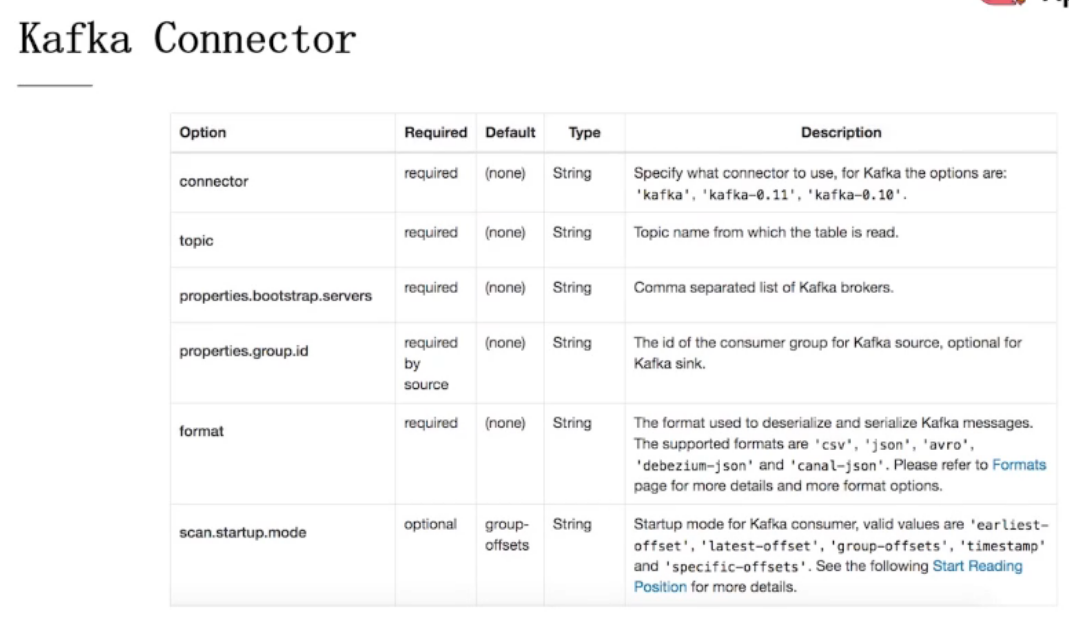

Elasticsearch Connector



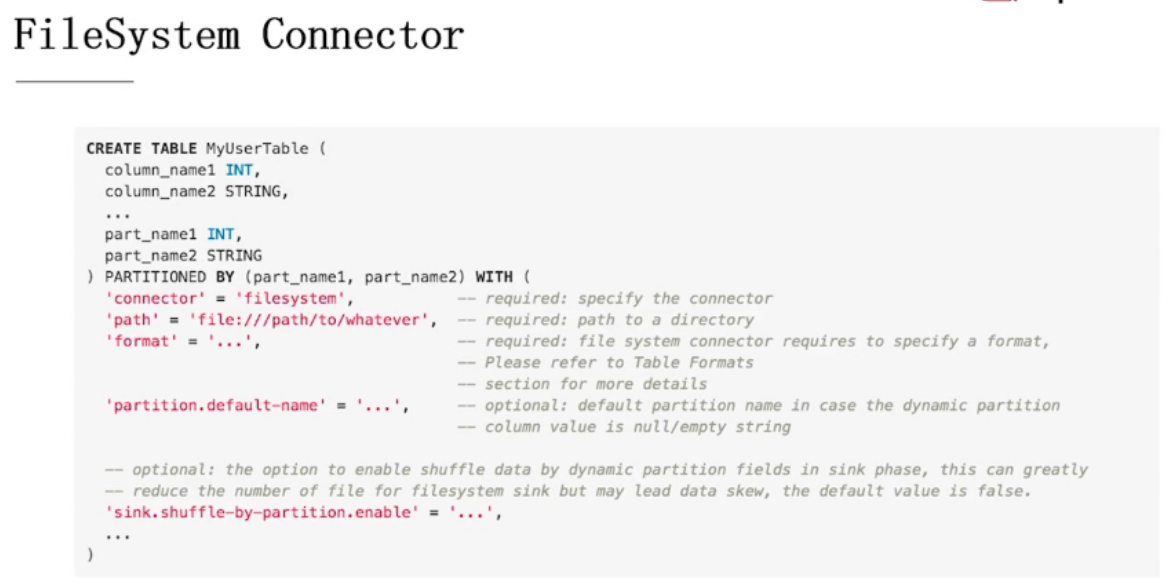
FileSystem Connector

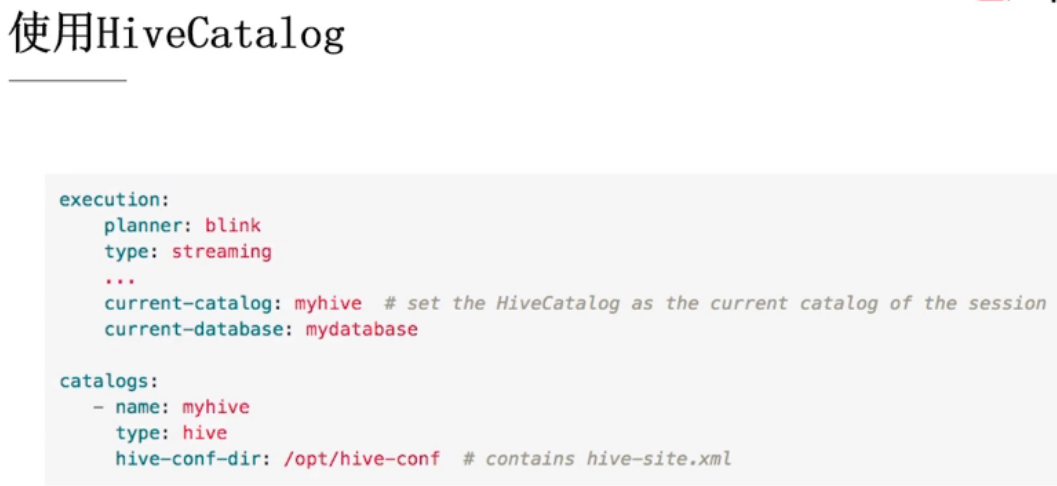
Hive Connector


DataGen Connector

Print Connector

BlackHole Connector
可以做性能测试,数据来了以后不做任何处理,直接丢弃

7.3、示例 & Demo
kafka交互



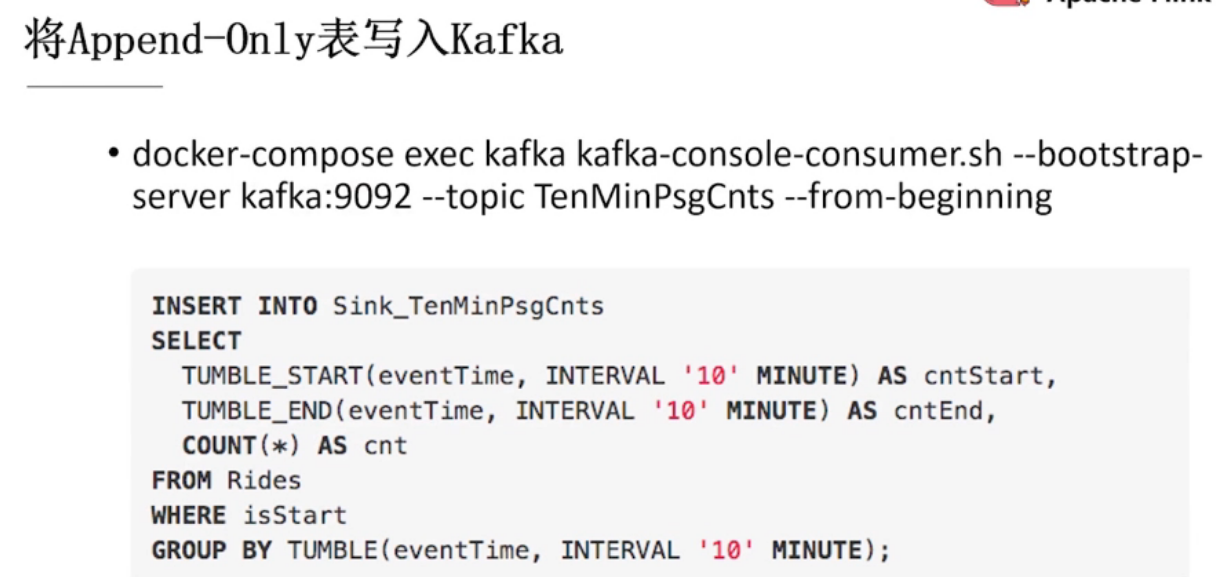
写入es

hive交互