昨天,笔者讲述了如何将CPU和IO撑满,这个其实很好理解,写个CPU密集型的程序让CPU忙个不停就可以撑满CPU;弄个程序一直写就可以让IO也撑满。有兴趣的同学可以看下昨天的这篇文章《看我如何作死 | 将CPU、IO撑满》,不过里面的做法分别是使用openssl speed和linux dd工具来实现这两个功能。
面对CPU和IO时,相信大家都能很快的反应出如何实现,那么面对网络问题时,大家的反应又是如何呢?不会是拔网线吧。。。
在故障注入,或者说故障演练,甚至说混沌工程中,可以设计很多类型的故障,今天要介绍的就是网络故障。
混沌系统是在分布式系统上进行实验的学科,目的是建立对系统抵御生产环境中失控条件的能力以及信心。
在复杂的网络环境下,数据包发送和接收的时间间隔或长或短。在网络状况较差时,调用下游服务时可能要过很久才能收到返回,这时服务的反应如何,直接关系到稳定性与高可用。
我们这里索要模拟的网络故障有三类,分别是:网络延时、网络中断以及网络丢包。
一、tc工具介绍
笔者也不卖关子,本文模拟的网络故障是通过linux的tc工具来实现的。Linux内核网络协议栈从2.2.x开始,就实现了对服务质量的支持模块。具体的代码位于net/sched/目录。在Linux里面,对这个功能模块的称呼是Traffic Control ,简称TC。TC是一个在上层协议处添加Qos功能的工具,原理上看,它实质是专门供用户利用内核Qos调度模块去定制Qos的中间件。
Linux操作系统中的流量控制器TC(Traffic Control)用于Linux内核的流量控制,主要是通过在输出端口处建立一个队列来实现流量控制。
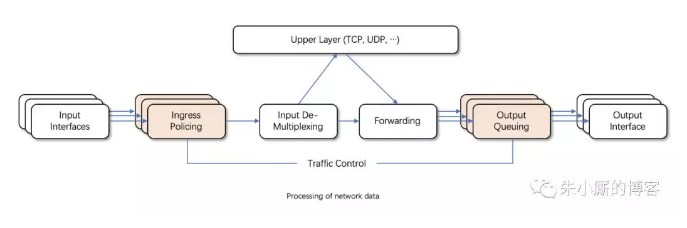
接收包从输入接口(Input Interface)进来后,经过流量限制(Ingress Policing)丢弃不符合规定的数据包,由输入多路分配器(Input De-Multiplexing)进行判断选择:如果接收包的目的是本主机,那么将该包送给上层处理;否则需要进行转发,将接收包交到转发块(Forwarding Block)处理。转发块同时也接收本主机上层(TCP、UDP等)产生的包。转发块通过查看路由表,决定所处理包的下一跳。然后,对包进行排列以便将它们传送到输出接口(Output Interface)。一般我们只能限制网卡发送的数据包,不能限制网卡接收的数据包,所以我们可以通过改变发送次序来控制传输速率。Linux流量控制主要是在输出接口排列时进行处理和实现的。
tc工具的语法还是很复杂的,笔者(微信公众号:朱小厮的博客)试图想要在本文中详细的讲解一下tc的用法,最后还是放弃了,篇幅太长,难以穷尽。所以本文中只是针对前面说的三种故障简单的演示一下tc的用法以及对应故障的实现方式,希望能够能大家有个小小的印象。如果以后遇到类似问题,或者说对这个东西感兴趣,可以再深度的学习一下。
二、paping工具介绍
在正式介绍如何模拟网络故障之前,还要介绍一个工具来查看模拟的效果如何。
通常我们测试数据包能否通过IP协议到达特定主机,都习惯使用Ping命令,工作时发送一个ICMP Echo,等待接受Echo响应,但是Ping使用的是ICMP协议,如果防火墙放通了此协议,依旧能够ping通,但是无法确定通过tcp传送的数据包是否正常到达对端。
而paping可以在Linux平台上测试网络的连通性及网络延时等。它的用法很简单:
1 | -p, --port N 指定被测试服务的 TCP 端口(必须); |
比如下面的示例(记得先要开启一个以80为端口的服务, 示例中的xxx.xxx.xxx.xxx代表ip地址):
1 | ./paping -p 80 -c 5 xxx.xxx.xxx.xxx |
可以看到平均链接时间为58.43ms。
如果你的机器上没有安装paping,那么可以采用如下的方式安装:
1 | wget https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/paping/paping_1.5.5_x86_linux.tar.gz |
如果有以下的错误:
./paping: error while loading shared libraries: libstdc++.so.6: cannot open shared object file: No such file or directory
可以先安装对应的库来解决:
1 | sudo apt-get install libstdc++6 |
三、模拟网络延时
使用tc命令模拟延迟300ms(对应的删除命令为tc qdisc del dev eth0 root netem):
1 | tc qdisc add dev eth0 root netem delay 300ms |
此时再次执行paping命令:
1 | ./paping -p 80 -c 5 xxx.xxx.xxx.xxx |
与之前的58.43ms相比相差了291.52ms ≈ 300ms。
更真实的情况下,延迟值不会这么精确,会有一定的波动,我们可以用下面的情况来模拟出带有波动性的延迟值:
1 | tc qdisc add dev eth0 root netem delay 300ms 50ms |
四、模拟网络中断
这次使用如下的命令:
1 | tc qdisc add dev eth0 root netem corrupt 10% |
此时再次执行paping命令:
1 | ./paping -p 80 -c 100 xxx.xxx.xxx.xxx |
注意这里的次数改成了100,为了更能清楚的看到中断的实际效果。
运行这个命令的过程中,会有“Connection timed out”字样报出,类似:
1 | <snip> |
最终的统计结果如下:
1 | Connection statistics: |
结果显而易见,验证了此次故障模拟所对应的效果。
五、模拟网络丢包
使用如下命令:
1 | tc qdisc add dev eth0 root netem loss 7% 25% |
再次执行paping命令时,也会有Connection timed out报出,最终的统计结果如下:
1 | Connection statistics: |
7%*25%的值在1%-2%之间,符合测试的结果预期。
tc还可以模拟一些其它的网络故障,比如网络包重复、网络包错序等等,有兴趣的同学可以继续深入了解一下。
六、引申混沌工程和传统测试之间的区别
很多同学在进行一些故障测试的时候,会认为其正在进行混沌实验,其实混沌工程和传统的测试之间是有区别的。
混沌工程和传统测试(故障注入FIT、故障测试)在关注点和工具集上都有很大的重叠。譬如,在Netflix(如果还不知道Netflix是谁,可以先看看这篇《明星公司之Netflix》了解一下)的很多混沌工程实验研究的对象都是基于故障注入来引入的。混沌工程和这些传统测试方法的主要区别在于:混沌工程是发现新信息的实践过程,而故障注入则是对一个特定的条件、变量的验证方法。
当你希望探究复杂系统如何应对异常时,对系统中的服务注入通信故障(如超时、错误等)不失为一种很好的方法。但有时我们希望探究更多其他的非故障类的场景,如流量激增、资源竞争条件、拜占庭故障(例如性能差或有异常的节点发出有错误的响应、异常的行为、对调用者随机性的返回不同的响应,等等)、非计划中的或非正常组合的消息处理等等。因为如果一个面向公众用户的网站突然收到激增的流量,从而产生更多的收入时我们很难称之为故障,但我们仍然需要探究清楚系统在这种情况下的影响。
和故障注入类似,故障测试方法通过对预先设想到的可以破坏系统的点进行测试,但是并没能去探究上述这类更广阔领域里的、不可预知的、但很可能发生的事情。
在传统测试中,我们可以写一个断言(assertion),即我们给定一个特定的条件,产生一个特定的输出。测试一般来说只会产生二元的结果,验证一个结果是真还是假,从而判定测试是否通过。严格意义上来说,这个过程并不能让我们发掘出对于系统未知的、尚不明确的认知,它仅仅是对我们已知的系统属性可能的取值进行测验。而实验可以产生新的认知,而且通常还能开辟出一个更广袤的对复杂系统的认知空间。
混沌工程是一种帮助我们获得更多的关于系统的新认知的实验方法。它和已有的功能测试、集成测试等以测试已知属性的方法有本质上的区别。
七、后续
后面还会有几篇相同主题的文章发出,不出意外,下一篇应该是《怎么让进程假死》,如果有兴趣的话,可以持续关注本公众号(朱小厮的博客)。如果你还有有什么需要进一步了解的可以在下方留言,或者也聊聊你对这一块的认知和想法。