目录
流水线入门
什么是Jenkins的流水线?
Jenkins 流水线 (或简单的带有大写”P”的”Pipeline”) 是一套插件,它支持实现和集成 continuous delivery pipelines 到Jenkins。
_continuous delivery (CD) pipeline_是你的进程的自动表达,用于从版本控制向用户和客户获取软件。 你的软件的每次的变更 (在源代码控制中提交)在它被释放的路上都经历了一个复杂的过程 on its way to being released. 这个过程包括以一种可靠并可重复的方式构建软件, 以及通过多个测试和部署阶段来开发构建好的软件 (c成为 “build”) 。
流水线提供了一组可扩展的工具,通过 Pipeline domain-specific language (DSL) syntax. [1]对从简单到复杂的交付流水线 “作为代码” 进行建模。
对Jenkins 流水线的定义被写在一个文本文件中 (成为 Jenkinsfile),该文件可以被提交到项目的源代码的控制仓库。 [2] 这是”流水线即代码”的基础; 将CD 流水线作为应用程序的一部分,像其他代码一样进行版本化和审查。 创建 Jenkinsfile并提交它到源代码控制中提供了一些即时的好处:
- 自动地为所有分支创建流水线构建过程并拉取请求。
- 在流水线上代码复查/迭代 (以及剩余的源代码)。
- 对流水线进行审计跟踪。
- 该流水线的真正的源代码 [3], 可以被项目的多个成员查看和编辑。
While定义流水线的语法, 无论是在 web UI 还是在 Jenkinsfile 中都是相同的, 通常认为在Jenkinsfile 中定义并检查源代码控制是最佳实践
声明式和脚本化的流水线语法
Jenkinsfile 能使用两种语法进行编写 - 声明式和脚本化。
声明式和脚本化的流水线从根本上是不同的。 声明式流水线的是 Jenkins 流水线更近的特性:
- 相比脚本化的流水线语法,它提供更丰富的语法特性,
- 是为了使编写和读取流水线代码更容易而设计的。
然而,写到Jenkinsfile中的许多单独的语法组件(或者 “步骤”), 通常都是声明式和脚本化相结合的流水线。 在下面的 [pipeline-concepts] 和 [pipeline-syntax-overview] 了解更多这两种语法的不同。
Why Pipeline?
本质上,Jenkins 是一个自动化引擎,它支持许多自动模式。 流水线向Jenkins中添加了一组强大的工具, 支持用例 简单的持续集成到全面的CD流水线。通过对一系列的相关任务进行建模, 用户可以利用流水线的很多特性:
- Code: 流水线是在代码中实现的,通常会检查到源代码控制, 使团队有编辑, 审查和迭代他们的交付流水线的能力。
- Durable: 流水线可以从Jenkins的主分支的计划内和计划外的重启中存活下来。
- Pausable: 流水线可以有选择的停止或等待人工输入或批准,然后才能继续运行流水线。
- Versatile: 流水线支持复杂的现实世界的 CD 需求, 包括fork/join, 循环, 并行执行工作的能力。
- Extensible:流水线插件支持扩展到它的DSL [1]的惯例和与其他插件集成的多个选项。
然而, Jenkins一直允许以将自由式工作链接到一起的初级形式来执行顺序任务, [4] 流水线使这个概念成为了Jenkins的头等公民。
构建一个的可扩展的核心Jenkins值, 流水线也可以通过 Pipeline Shared Libraries 的用户和插件开发人员来扩展。 [5]
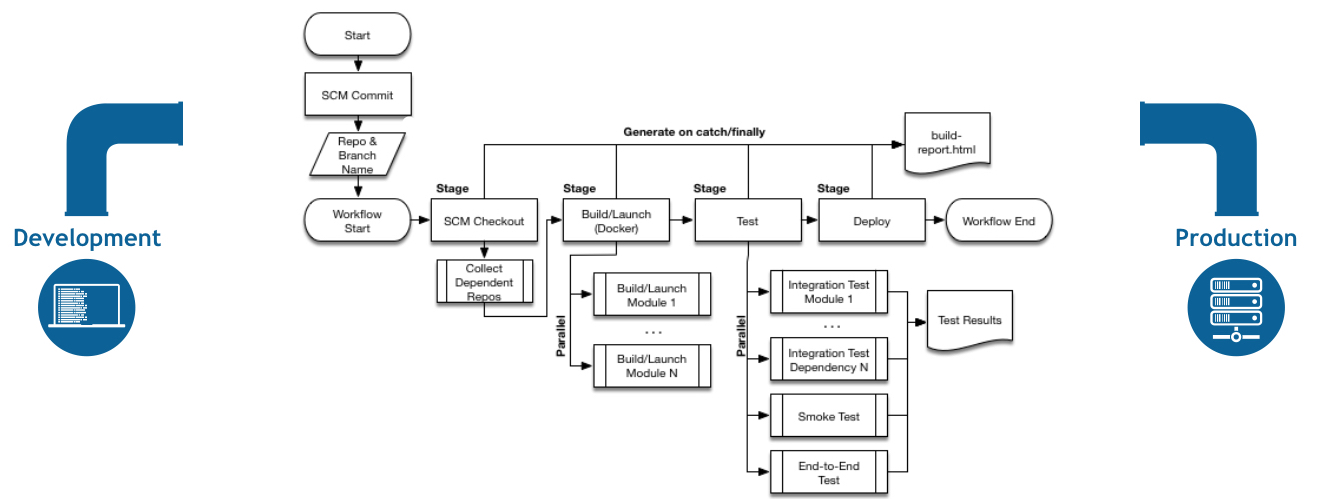
下面的流程图是一个 CD 场景的示例,在Jenkins中很容易对该场景进行建模:
流水线概念
下面的概念是Jenkins流水线很关键的一方面 , 它与流水线语法紧密相连 (参考 overview below).
流水线
流水线是用户定义的一个CD流水线模型 。流水线的代码定义了整个的构建过程, 他通常包括构建, 测试和交付应用程序的阶段 。
另外 , pipeline 块是 声明式流水线语法的关键部分.
节点
节点是一个机器 ,它是Jenkins环境的一部分 and is capable of执行流水线。
另外, node块是 脚本化流水线语法的关键部分.
阶段
stage 块定义了在整个流水线的执行任务的概念性地不同的的子集(比如 “Build”, “Test” 和 “Deploy” 阶段), 它被许多插件用于可视化 或Jenkins流水线目前的 状态/进展. [6]
步骤
本质上 ,一个单一的任务, a step 告诉Jenkins 在特定的时间点要做what (或过程中的 “step”)。 举个例子,要执行shell命令 ,请使用 sh 步骤: sh 'make'。当一个插件扩展了流水线DSL, [1] 通常意味着插件已经实现了一个新的 step。
流水线语法概述
下面的流水线代码骨架说明了声明式流水线语法和 脚本化流水线语法之间的根本差异。
请注意 阶段 and 步骤 (上面的) 都是声明式和脚本化流水线语法的常见元素。
声明式流水线基础(推荐)
在声明式流水线语法中, pipeline 块定义了整个流水线中完成的所有的工作。

- 在任何可用的代理上,执行流水线或它的任何阶段。
- 定义 “Build” 阶段。
- 执行与 “Build” 阶段相关的步骤。
- 定义”Test” 阶段。
- 执行与”Test” 阶段相关的步骤。
- 定义 “Deploy” 阶段。
- 执行与 “Deploy” 阶段相关的步骤。
脚本化流水线基础
在脚本化流水线语法中, 一个或多个 node 块在整个流水线中执行核心工作。 虽然这不是脚本化流水线语法的强制性要求, 但它限制了你的流水线的在node块内的工作做两件事:
- 通过在Jenkins队列中添加一个项来调度块中包含的步骤。 节点上的执行器一空闲, 该步骤就会运行。
- 创建一个工作区(特定为特定流水间建立的目录),其中工作可以在从源代码控制检出的文件上完成。
Caution: 根据你的 Jenkins 配置,在一系列的空闲后,一些工作区可能不会自动清理 。参考 JENKINS-2111 了解更多信息。

- 在任何可用的代理上,执行流水线或它的任何阶段。
- 定义 “Build” 阶段。 stage 块 在脚本化流水线语法中是可选的。 然而, 在脚本化流水线中实现 stage 块 ,可以清楚的显示Jenkins UI中的每个 stage 的任务子集。
- 执行与 “Build” 阶段相关的步骤。
- 定义 “Test” 阶段。
- 执行与 “Test” 阶段相关的步骤。
- 定义 “Deploy” 阶段。
- 执行与 “Deploy” 阶段相关的步骤。
流水线示例
这有一个使用声明式流水线的语法编写的 Jenkinsfile 文件 - 可以通过点击下面 Toggle Scripted Pipeline 链接来访问它的等效的脚本化语法:

Toggle Scripted Pipeline (Advanced)
pipeline是声明式流水线的一种特定语法,他定义了包含执行整个流水线的所有内容和指令的 “block” 。- 是声明式流水线的一种特定语法,它指示 Jenkins 为整个流水线分配一个执行器 (在节点上)和工作区。
stage是一个描述 stage of this Pipeline的语法块。在 Pipeline syntax 页面阅读更多有关声明式流水线语法的stage块的信息。如 above所述, 在脚本化流水线语法中,stage块是可选的。steps是声明式流水线的一种特定语法,它描述了在这个stage中要运行的步骤。sh是一个执行给定的shell命令的流水线 step (由 Pipeline: Nodes and Processes plugin提供) 。junit是另一个聚合测试报告的流水线 step (由 JUnit plugin提供)。node是脚本化流水线的一种特定语法,它指示 Jenkins 在任何可用的代理/节点上执行流水线 (和包含在其中的任何阶段)这实际上等效于 声明式流水线特定语法的agent。
在 Pipeline Syntax 页面阅读了解更多流水线语法的相关信息。
使用 Jenkinsfile
本节基于 流水线入门 所涵盖的信息,介绍更多有用的步骤、常见的模式,并且演示 Jenkinsfile 的一些特例。
创建一个检入到源码管理系统中 [1] 的 Jenkinsfile 带来了一些直接的好处:
- 流水线上的代码评审/迭代
- 对流水线进行审计跟踪
- 流水线的单一可信数据源 [2],能够被项目的多个成员查看和编辑。
流水线支持 两种语法:声明式(在 Pipeline 2.5 引入)和脚本式流水线。 两种语法都支持构建持续交付流水线。两种都可以用来在 web UI 或 Jenkinsfile 中定义流水线,不过通常认为创建一个 Jenkinsfile 并将其检入源代码控制仓库是最佳实践
创建 Jenkinsfile
正如 在 SCM 中定义流水线中所讨论的,Jenkinsfile 是一个文本文件,它包含了 Jenkins 流水线的定义并被检入源代码控制仓库。下面的流水线实现了基本的三阶段持续交付流水线。
1 | Jenkinsfile (Declarative Pipeline) |
不是所有的流水线都有相同的三个阶段,但为大多数项目定义这些阶段是一个很好的开始。下面这一节将在 Jenkins 的测试安装中演示一个简单流水线的创建和执行。
假设已经为项目设置了一个源代码控制仓库并在 Jenkins 下的 these instructions中定义了一个流水线
使用文本编辑器,最好支持 Groovy 语法高亮,在项目的根目录下创建一个 Jenkinsfile。
上面的声明式流水线示例包含了实现持续交付流水线的最小必要结构。agent指令是必需的,它指示 Jenkins 为流水线分配一个执行器和工作区。没有 agent 指令的话,声明式流水线不仅无效,它也不可能完成任何工作!默认情况下,agent 指令确保源代码仓库被检出并在后续阶段的步骤中可被使用。
一个合法的声明式流水线还需要 stages 指令和 steps 指令,因为它们指示 Jenkins 要执行什么,在哪个阶段执行。
想要使用 脚本式流水线 的更高级用法,上面例子中的
node是关键的第一步,因为它为流水线分配了一个执行者和工作区。实际上,没有node,流水线无法工作!在node内,业务的第一步是检出这个项目的源代码。由于Jenkinsfile已经从源代码控制中直接拉取出来,流水线提供了一个快速且简单的方式来访问正确的源代码修订版本。
2
3
4
5
6
> node {
> checkout scm
> /* .. snip .. */
> }
>
checkout步骤将会从源代码控制中检出代码;scm是一个特殊的变量, 它指示checkout步骤克隆触发流水线运行的特定修订版本。
构建
对于许多项目来说,流水线“工作”的开始就是“构建”阶段。通常流水线的这个阶段包括源代码的组装、编译或打包。Jenkinsfile 文件不能替代现有的构建工具,如 GNU/Make、Maven、Gradle 等,而应视其为一个将项目的开发生命周期的多个阶段(构建、测试、部署等)绑定在一起的粘合层。
Jenkins 有许多插件可以用于调用几乎所有常用的构建工具,不过这个例子只是从 shell 步骤(sh)调用 make。sh 步骤假设系统是基于 Unix/Linux 的,对于基于 Windows 的系统可以使用 bat 替代。
Jenkinsfile (Declarative Pipeline)
1 | pipeline { |
Toggle Scripted Pipeline (Advanced)
sh步骤调用make命令,只有命令返回的状态码为零时才会继续。任何非零的返回码都将使流水线失败。archiveArtifacts捕获符合模式(**/target/*.jar)匹配的交付件并将其保存到 Jenkins master 节点以供后续获取。
制品归档不能替代外部制品库(例如 Artifactory 或 Nexus),而只应当认为用于基本报告和文件存档。
测试
运行自动化测试是任何成功的持续交付过程的重要组成部分。因此,Jenkins 有许多测试记录,报告和可视化工具,这些都是由各种插件提供的。最基本的,当测试失败时,让 Jenkins 记录这些失败以供汇报以及在 web UI 中可视化是很有用的。下面的例子使用由 JUnit 插件提供的 junit 步骤。
在下面的例子中,如果测试失败,流水线就会被标记为“不稳定”,这通过 web UI 中的黄色球表示。基于测试报告的记录,Jenkins 还可以提供历史趋势分析和可视化。
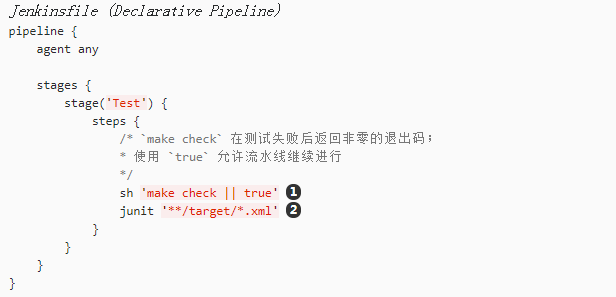
Toggle Scripted Pipeline (Advanced)
- 使用内联的 shell 条件(
sh 'make || true')确保sh步骤总是看到退出码是零,使junit步骤有机会捕获和处理测试报告。在下面处理故障一节中,对它的替代方法有更详细的介绍。 junit捕获并关联与包含模式(\**/target/*.xml)匹配的 JUnit XML 文件。
部署
部署可以隐含许多步骤,这取决于项目或组织的要求,并且可能是从发布构建的交付件到 Artifactory 服务器,到将代码推送到生产系统的任何东西。 在示例流水线的这个阶段,“Build(构建)” 和 “Test(测试)” 阶段都已成功执行。从本质上讲,“Deploy(部署)” 阶段只有在之前的阶段都成功完成后才会进行,否则流水线会提前退出。

Toggle Scripted Pipeline (Advanced)
- 流水线访问
currentBuild.result变量确定是否有任何测试的失败。在这种情况下,值为UNSTABLE。
假设在示例的 Jenkins 流水线中所有的操作都执行成功,那么每次流水线的成功运行都会在 Jenkins 中存档相关的交付件、上面报告的测试结果以及所有控制台输出。
脚本式流水线包含条件测试(如上所示),循环,try/catch/finally 块甚至函数。下一节将会详细的介绍这个高级的脚本式流水线语法
使用 Jenkinsfile 工作
接下来的章节提供了处理以下事项的细节:
Jenkinsfile中的流水线特有语法- 流水线语法的特性和功能,这对于构建应用程序或流水线项目非常重要。
字符串插值
Jenkins 使用与 Groovy 相同的规则进行字符串插值。 Groovy 的字符串插值支持可能会使很多新手感到困惑。尽管 Groovy 支持使用单引号或双引号声明一个字符串,例如:
1 | def singlyQuoted = 'Hello' |
只有后面的字符串(双引号字符串)才支持基于美元符($)的字符串插值,例如:
1 | def username = 'Jenkins' |
其结果是:
1 | Hello Mr. ${username} |
理解如何使用字符串插值对于使用一些流水线的更高级特性是至关重要的。
使用环境变量
Jenkins 流水线通过全局变量 env 提供环境变量,它在 Jenkinsfile 文件的任何地方都可以使用。Jenkins 流水线中 可访问的完整的环境变量列表 记录在 ${YOUR_JENKINS_URL}/pipeline-syntax/globals#env,并且包括:
BUILD_ID
当前构建的 ID,与 Jenkins 版本 1.597+ 中创建的构建号 BUILD_NUMBER 是完全相同的。
BUILD_NUMBER
当前构建号,比如 “153”。
BUILD_TAG
字符串
jenkins-${JOB_NAME}-${BUILD_NUMBER}。可以放到源代码、jar 等文件中便于识别。BUILD_URL
可以定位此次构建结果的 URL(比如 http://buildserver/jenkins/job/MyJobName/17/ )
EXECUTOR_NUMBER
用于识别执行当前构建的执行者的唯一编号(在同一台机器的所有执行者中)。这个就是你在“构建执行状态”中看到的编号,只不过编号从 0 开始,而不是 1。
JAVA_HOME
如果你的任务配置了使用特定的一个 JDK,那么这个变量就被设置为此 JDK 的 JAVA_HOME。当设置了此变量时,PATH 也将包括 JAVA_HOME 的 bin 子目录。
JENKINS_URL
Jenkins 服务器的完整 URL,比如 https://example.com:port/jenkins/ (注意:只有在“系统设置”中设置了 Jenkins URL 才可用)。
JOB_NAME
本次构建的项目名称,如 “foo” 或 “foo/bar”。
NODE_NAME
运行本次构建的节点名称。对于 master 节点则为 “master”。
WORKSPACE
workspace 的绝对路径。
引用或使用这些环境变量就像访问 Groovy Map 的 key 一样, 例如:
Jenkinsfile (Declarative Pipeline)
1 | pipeline { |
Toggle Scripted Pipeline (Advanced)
设置环境变量
在 Jenkins 流水线中,取决于使用的是声明式还是脚本式流水线,设置环境变量的方法不同。
声明式流水线支持 environment 指令,而脚本式流水线的使用者必须使用 withEnv 步骤。
Jenkinsfile (Declarative Pipeline) 声明式
1 | pipeline { |
Toggle Scripted Pipeline (Advanced)
- 用在最高层的
pipeline块的environment指令适用于流水线的所有步骤。 - 定义在
stage中的environment指令只适用于stage中的步骤。
动态设置环境变量
环境变量可以在运行时设置,然后给 shell 脚本(sh)、Windows 批处理脚本(batch)和 Powershell 脚本(powershell)使用。各种脚本都可以返回 returnStatus 或 returnStdout。
下面是一个使用 sh(shell)的声明式脚本的例子,既有 returnStatus 也有 returnStdout:

agent必须设置在流水线的最高级。如果设置为agent none会失败- 使用
returnStdout时,返回的字符串末尾会追加一个空格。可以使用.trim()将其移除。
处理凭据
Jenkins 中配置的凭据可以在流水线中处理以便于立即使用。请前往 使用凭据页面阅读更多关于在 Jenkins 中使用凭据的信息。
Secret 文本,带密码的用户名,Secret 文件
Jenkins 的声明式流水线语法有一个 credentials() 辅助方法(在environment 指令中使用),它支持 secret 文本,带密码的用户名,以及 secret 文件凭据。如果你想处理其他类型的凭据,请参考其他凭据类型一节(见下)。
Secret 文本
下面的流水线代码演示了如何使用环境变量为 secret 文本凭据创建流水线的示例。
在该示例中,将两个 secret 文本凭据赋予各自的环境变量来访问 Amazon Web 服务(AWS)。这些凭据已在 Jenkins 中配置了各自的凭据 ID jenkins-aws-secret-key-id 和 jenkins-aws-secret-access-key。

你可以在该阶段的步骤中用语法 $AWS_ACCESS_KEY_ID 和 $AWS_SECRET_ACCESS_KEY 来引用两个凭据环境变量(定义在流水线的 environment 指令中)。比如,在这里,你可以使用分配给这些凭据变量的 secret 文本凭据对 AWS 进行身份验证。 为了保持这些凭据的安全性和匿名性,如果任务试图从流水线中显示这些凭据变量的值(如 echo
$AWS_SECRET_ACCESS_KEY),Jenkins 只会返回 “” 来降低机密信息被写到控制台输出和任何日志中的风险。凭据 ID 本身的任何敏感信息(如用户名)也会以 “” 的形式返回到流水线运行的输出中。
这只能降低意外暴露的风险。它无法阻止恶意用户通过其他方式获取凭据的值。使用凭据的流水线也可能泄漏这些凭据。不要允许不受信任的流水线任务使用受信任的凭据。- 在该流水线示例中,分配给两个
AWS_...环境变量的凭据在整个流水线的全局范围内都可访问,所以这些凭据变量也可以用于该阶段的步骤中。然而,如果流水线中的environment指令被移动到一个特定的阶段(比如下面的 带密码的用户名流水线示例),那么这些AWS_...环境变量就只能作用于该阶段的步骤中。
带密码的用户名
下面的流水线代码片段展示了如何创建一个使用带密码的用户名凭据的环境变量的流水线。
在该示例中,带密码的用户名凭据被分配了环境变量,用来使你的组织或团队以一个公用账户访问 Bitbucket 仓库;这些凭据已在 Jenkins 中配置了凭据 ID jenkins-bitbucket-common-creds。
当在 environment 指令中设置凭据环境变量时:
1 | environment { |
这实际设置了下面的三个环境变量:
BITBUCKET_COMMON_CREDS- 包含一个以冒号分隔的用户名和密码,格式为username:password。BITBUCKET_COMMON_CREDS_USR- 附加的一个仅包含用户名部分的变量。BITBUCKET_COMMON_CREDS_PSW- 附加的一个仅包含密码部分的变量。
按照惯例,环境变量的变量名通常以大写字母中指定,每个单词用下划线分割。 但是,你可以使用小写字母指定任何合法的变量名。请记住,
credentials()方法(见上)所创建的附加环境变量总是会有后缀_USR和_PSW(即以下划线后跟三个大写字母的格式)。

下面的凭据环境变量(定义在流水线的 environment 指令中)可以在该阶段的步骤中使用,并且可以使用下面的语法引用:
$BITBUCKET_COMMON_CREDS$BITBUCKET_COMMON_CREDS_USR$BITBUCKET_COMMON_CREDS_PSW
- 比如,在这里你可以使用分配给这些凭据变量的用户名和密码向 Bitbucket 验证身份。
为了维护这些凭据的安全性和匿名性,如果任务试图从流水线中显示这些凭据变量的值,那么上面的 Secret 文本 描述的行为也同样适用于这些带密码的用户名凭据变量类型。
同样,这只能降低意外暴露的风险。它无法阻止恶意用户通过其他方式获取凭据的值。使用凭据的流水线也可能泄漏这些凭据。不要允许不受信任的流水线任务使用受信任的凭据。 - 在该流水线示例中,分配给三个
COMMON_BITBUCKET_CREDS...环境变量的凭据仅作用于Example stage 1,所以在Example stage 2阶段的步骤中这些凭据变量不可用。然而,如果马上把流水线中的environment指令移动到pipeline块中(正如上面的 Secret 文本流水线示例一样),这些COMMON_BITBUCKET_CREDS...环境变量将应用于全局并可以在任何阶段的任何步骤中使用。
Secret 文件
就流水线而言,secret 文件的处理方式与 Secret 文本 完全相同。
实际上,secret 文本和 secret 文件凭据之间的唯一不同是,对于 secret 文本,凭据本身直接输入到 Jenkins 中,而 secret 文件的凭据则原样保存到一个文件中,之后将传到 Jenkins。
与 secret 文本不同的是,secret 文件适合:
- 太笨拙而不能直接输入 Jenkins
- 二进制格式,比如 GPG 文件
其他凭据类型
如果你需要在流水线中设置除了 secret 文本、带密码的用户名、secret 文件(见上)以外的其他凭据——即 SSH 秘钥或证书,那么请使用 Jenkins 的片段生成器特性,你可以通过 Jenkins 的经典 UI 访问它。
要从你的流水线项目访问片段生成器:
- 从 Jenkins 主页(即 Jenkins 的经典 UI 工作台)点击流水线项目的名字。
- 在左侧,点击流水线语法并确保 Snippet Generator/片段生成器的链接在右上角粗体显示(如果没有,点击它的链接)。
- 从示例步骤字段中,选择 withCredentials: Bind credentials to variables。
- 在绑定下面,点击新增并从下拉框中选择:
- SSH User Private Key - 要处理 SSH 公私钥对凭据,你可以提供:
- Key 文件变量 - 将要绑定到这些凭据的环境变量的名称。Jenkins 实际上将此临时变量分配给 SSH 公私钥对身份验证过程中所需的私钥文件的安全位置。
- 密码变量(可选)- 将要被绑定到与 SSH 公私钥对相关的 密码 的环境变量的名称。
- 用户名变量(可选)- 将要绑定到与 SSH 公私钥对相关的用户名的环境变量的名称。
- 凭据 - 选择存储在 Jenkins 中的 SSH 公私钥对证书。该字段的值是凭据 ID,Jenkins 将其写入生成的代码片段中。
- Certificate - 要处理 PKCS#12 证书,你可以提供:
- 密钥库变量 - 将要绑定到这些凭据的环境变量的名称。Jenkins 实际上将这个临时变量分配给要求进行身份验证的证书密钥库的安全位置。
- 密码变量(可选) - 将会被绑定到与证书相关的密码的环境变量的名称。
- 别名变量(可选) - 将会被绑定到与证书相关的唯一别名的环境变量的名称。
- 凭据 - 选择存储在 Jenkins 中的证书。该字段的值是凭据 ID,Jenkins 将其写入生成的代码片段中。
- Docker client certificate - 用于处理 Docker 主机证书的身份验证。
- SSH User Private Key - 要处理 SSH 公私钥对凭据,你可以提供:
- 点击 生成流水线脚本,Jenkins 会为你指定的凭据生成一个
withCredentials( ... ) { ... }的流水线步骤片段,你可以将其复制并粘贴到你的声明式或脚本化流水线代码中。
注意:- 凭据 字段(见上)显示的是 Jenkins 中配置的证书的名称。然而,这些值在点击 生成流水线脚本 之后会被转换成证书 ID。
- 要在一个
withCredentials( ... ) { ... }流水线步骤组合多个证书,请查看 在一个步骤中组合使用凭据(见下)的详细信息。
SSH User Private Key 示例
1 | withCredentials(bindings: [sshUserPrivateKey(credentialsId: 'jenkins-ssh-key-for-abc', \ |
可选的 passphraseVariable 和 usernameVariable 定义可以在最终的流水线代码中删除。
Certificate 示例
1 | withCredentials(bindings: [certificate(aliasVariable: '', \ |
可选的 aliasVariable 和 passwordVariable 变量定义可以在最终的流水线代码中删除。
下面的代码片段展示了一个完整的示例流水线,实现了上面的 SSH User Private Key 和 Certificate 片段:

- 在该步骤中,你可以使用语法
$SSH_KEY_FOR_ABC引用凭据环境变量。比如,在这里你可以使用配置的 SSH 公私钥对证书对 ABC 应用程序进行身份验证,它的 SSH User Private Key 文件被分配给$SSH_KEY_FOR_ABC。 - 在该步骤中,你可以使用语法
$CERTIFICATE_FOR_XYZ和$XYZ-CERTIFICATE-PASSWORD引用凭据环境变量。比如,在这里你可以使用配置的证书凭据对 XYZ 应用程序进行身份验证。证书 Certificate 的秘钥存储文件和密码分别被分配给$CERTIFICATE_FOR_XYZ和$XYZ-CERTIFICATE-PASSWORD变量。 - 在流水线示例中,分配给
$SSH_KEY_FOR_ABC、$CERTIFICATE_FOR_XYZ和$XYZ-CERTIFICATE-PASSWORD的环境变量的凭据只适用于它们各自withCredentials( ... ) { ... }步骤中,所以这些凭据变量在Example stage 2阶段的步骤中不可用。
为了维护这些证书的安全性和匿名性,如果你试图从 withCredentials( ... ) { ... } 步骤中检索这些凭据变量的值,在 Secret 文本 示例(见上)中的相同行为也适用于这些 SSH 公私钥对证书和凭据变量类型。
- 在 片段生成器 的示例步骤中使用 withCredentials: Bind credentials to variables 选项时,只有当前流水线项目有访问权限的凭据才可以从凭据字段中选择。 虽然你可以为你的流水线手动编写
withCredentials( ... ) { ... }步骤( 如上所示),但更建议使用 片段生成器 来防止指定超出该流水线访问范围的证书,可以避免运行步骤时失败。- 你也可以用 片段生成器 来生成处理 secret 文本,带密码的用户名以及 secret 文件的
withCredentials( ... ) { ... }步骤。但是,如果你只需要处理这些类型的证书的话,为了提高你流水线代码的可读性,更建议你使用在上面一节中描述的相关过程- 在 Groovy 中使用单引号而不是双引号来定义脚本(
sh的隐式参数)。单引号将使 secret 被 shell 作为环境变量展开。双引号可能不太安全,因为这个 secret 是由 Groovy 插入的,所以一般操作系统的进程列表(以及 Blue Ocean 和经典 UI 中的流水线步骤树)会意外地暴露它:
2
3
4
5
6
7
8
9
10
11
12
13
> withCredentials([string(credentialsId: 'mytoken', variable: 'TOKEN')]) {
> sh /* 错误! */ """
> set +x
> curl -H 'Token: $TOKEN' https://some.api/
> """
> sh /* 正确 */ '''
> set +x
> curl -H 'Token: $TOKEN' https://some.api/
> '''
> }
> }
>
在一个步骤中组合使用凭据
使用 片段生成器,你可以在单个 withCredentials( ... ) { ... } 步骤中提供多个可用凭据,操作如下:
- 从 Jenkins 的主页中(即 Jenkins 的经典 UI 工作台)点击流水线项目的名称。
- 在左侧,点击 流水线语法 确保片段生成器链接在左上加粗显示(如果没有,点击该链接)。
- 从 示例步骤 字段,选择 withCredentials: Bind credentials to variables。
- 点击 绑定 下的 新增。
- 从下拉列表中选择要添加到
withCredentials( ... ) { ... }步骤的凭据类型。 - 指定凭据绑定的细节。请在操作过程中阅读其他凭据类型。
- 重复“点击 新增 …”将每个(组)凭据添加到
withCredentials( ... ) { ... }步骤。 - 点击 生成流水线脚本 生成最终的
withCredentials( ... ) { ... }步骤片段。
处理参数
声明式流水线支持参数开箱即用,允许流水线在运行时通过parameters 指令接受用户指定的参数。配置脚本式流水线的参数是通过 properties 步骤实现的,可以在代码生成器中找到。
如果你使用 Build with Parameters 选项将流水线配置为接受参数,这些参数将作为 params 变量的成员被访问。
假设在 Jenkinsfile 中配置了名为 “Greeting” 的字符串参数,它可以通过 ${params.Greeting} 访问该参数:
Jenkinsfile (Declarative Pipeline)
1 | pipeline { |
Toggle Scripted Pipeline (Advanced)
处理故障
声明式流水线默认通过 post 节段支持强大的故障处理,它允许声明许多不同的 “post 条件”,比如: always、unstable、success、failure 和 changed。流水线语法 提供了关于如何使用各种 post 条件的更多细节。
Jenkinsfile (Declarative Pipeline)
1 | pipeline { |
Toggle Scripted Pipeline (Advanced)
然而脚本化的流水线依赖于 Groovy 的内置的
try/catch/finally语义来处理流水线运行期间的故障。在上面的测试示例中,
sh步骤被修改为永远不会返回非零的退出码(sh 'make check || true')。虽然这种方法合法,但意味着接下来的阶段需要检查currentBuild.result来了解测试是否失败。该问题的另一种处理方式是使用一系列的
try/finally块,它保留了流水线中前面的失败退出的行为,但仍然给了junit捕获测试报告的机会。
使用多个代理
在之前所有的示例中都只使用了一个代理。这意味着 Jenkins 会分配一个可用的执行者而无论该执行者是如何打标签或配置的。流水线不仅可以覆盖这种行为,还允许在 Jenkins 环境中使用 同一个 Jenkinsfile 中的多个代理,这将有助于更高级的用例,例如跨多个平台的执行构建/测试。
在下面的示例中,“Build” 阶段将会在一个代理中执行,并且构建结果将会在后续的 “Test” 阶段被两个分别标记为 “linux” 和 “windows” 的代理重用。

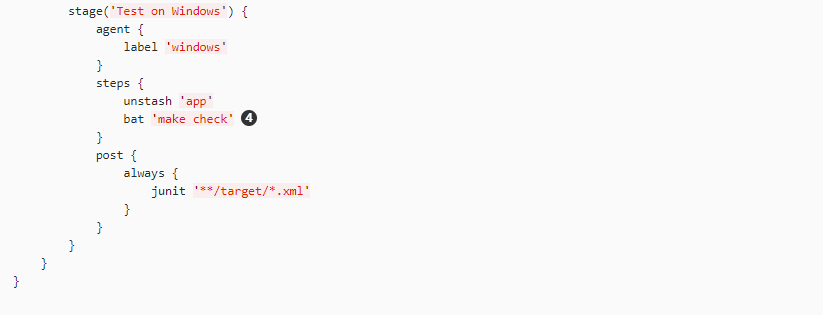
Toggle Scripted Pipeline (Advanced)
stash步骤允许捕获与包含模式(\**/target/*.jar)匹配的文件,以便在同一个流水线中重用。一旦流水线执行完成,就会从 Jenkins master 中删除暂存文件。agent/node中的参数允许使用任何可用的 Jenkins 标签表达式。参考 流水线语法 部分了解更多信息。unstash将会从 Jenkins master 中取回命名的 “stash” 到流水线的当前工作区中bat脚本允许在基于 Windows 的平台上执行批处理脚本。
可选的步骤参数
流水线遵循 Groovy 语言允许在方法周围省略括号的惯例。
许多流水线步骤也使用命名参数语法作为在 Groovy 中创建的 Map(使用语法 [key1: value1, key2: value2] )的简写 。下面的语句有着相同的功能:
1 | git url: 'git://example.com/amazing-project.git', branch: 'master' |
为了方便,当调用只有一个参数的步骤时(或仅一个强制参数),参数名称可以省略,例如:
1 | sh 'echo hello' /* short form */ |
高级脚本式流水线
脚本式流水线是一种基于 Groovy 的领域特定语言 [3] ,大多数 Groovy 语法都可以无需修改,直接在脚本式流水线中使用。
并行执行
上面这节中的示例跨两个不同的平台串联地运行测试。在实践中,如果执行 make check 需要30分钟来完成,那么 “Test” 阶段就需要 60 分钟来完成!
幸运的是,流水线有一个内置的并行执行部分脚本式流水线的功能,通过贴切的名为 parallel 的步骤实现。
使用 parallel 步骤重构上面的示例:

测试不再在标记为 “linux” 和 “windows” 节点中串联地执行,而是并行执行。
分支和pull请求
在previous section 中,实现了一个能够检入到源代码控制中的 Jenkinsfile。 本节将介绍在Jenkinsfile的基础上构建的 Multibranch 流水线的概念,用来在Jenkins中提供更动态和自动的功能。
创建多分支流水线
Multibranch Pipeline 项目类型能够 在同一个项目的不同分支上实现不同的Jenkinsfile。 在多分支流水线项目中, Jenkins 自动的发现, 管理和执行在源代码控制中包含Jenkinsfile的分支的流水线。
这消除了手动创建和管理流水线的需要。
创建多分支流水线:
- 点击Jenkins主页上的 New Item 。
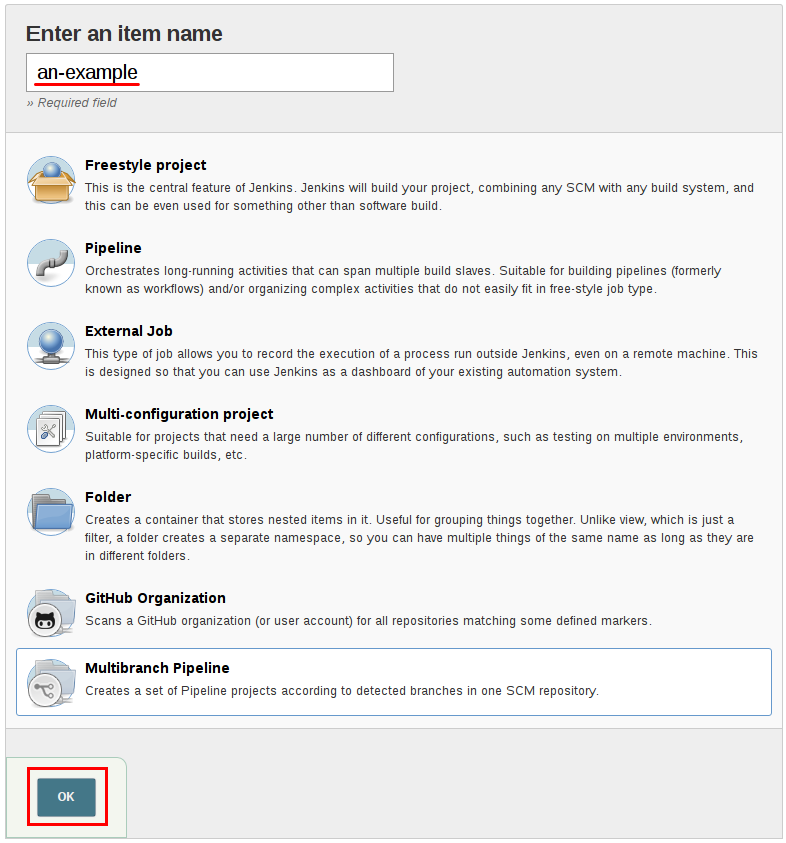
- 为你的流水线输入一个名称, 选择 Multibranch Pipeline 并点击 OK。
Jenkins 使用流水线的名称在磁盘上创建目录。 包含空格的流水线名称可能会在脚本中出现不希望在路径中出现空格的bug。
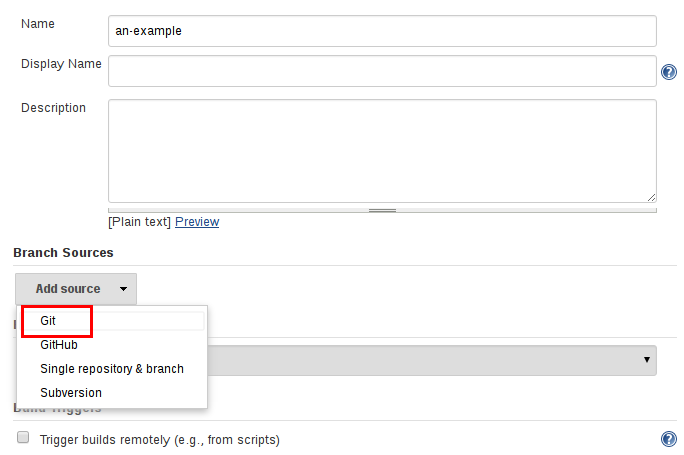
- 添加 Branch Source (比如, Git) 并输入仓库的位置。
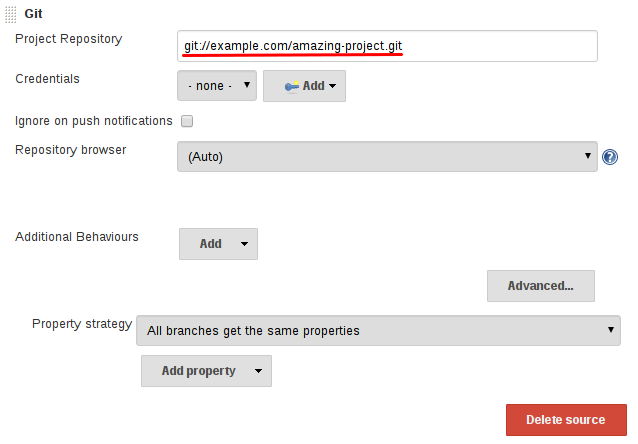
- Save 该多分支流水线项目。
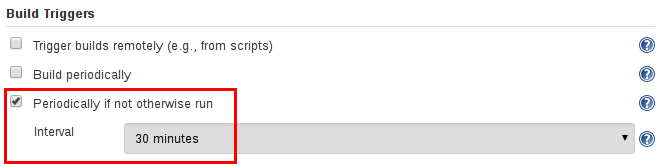
在 Save是, Jenkins 自动的扫描指定的存储库并为包含Jenkinsfile的仓库的每个分支创建合适的项目。默认情况下, Jenkins 不会自动的重新索引分支添加或删除的仓库(除非使用 组织文件夹), 所以周期性地重新索引有助于配置多分支流水线:
附加的环境变量
多分支流水线通过env 全局变量公开了额外的与分支构建相关的信息 , 比如:
BRANCH_NAME
该流水线正在执行的流水线的名称, 比如
master。CHANGE_ID
对应于某种形式的更改请求的标识符, 比如在 全局变量引用中列出了附加的环境变量的pull请求。
支持Pull请求
在 “GitHub” 或 “Bitbucket” 分支源, 可以使用多分支流水线来验证 pull/change 请求。 该功能分别由 GitHub 分支源 和 Bitbucket 分支源 插件提供。有关于如何使用这些插件的更多信息,请参考他们的文档。
使用组织文件夹
组织文件夹使Jenkins 能够监视整个 GitHub 组织或 Bitbucket 团队/P项目 并自动地为仓库创建一个新的多分支流水线,该流水线包括分支和含有Jenkinsfile文件的pull请求。
目前, 该功能只存在于 GitHub 和 Bitbucket, 该功能由 GitHub 组织文件夹 和 Bitbucket 分支源 插件提供。
在流水线中使用Docker
许多组织使用 Docker 在机器之间统一构建和测试环境, 并为部署应用程序提供有效的机制。从流水线版本 2.5 或以上开始, 流水线内置了与Jenkinsfile中的Docker进行交互的的支持。
虽然本节将介绍基础知识在 Jenkinsfile中使用Docker的基础,但它不会涉及 Docker 的基本原理, 可以参考 Docker入门指南。
自定义执行环境
设计流水线的目的是更方便地使用 Docker镜像作为单个 Stage或整个流水线的执行环境。 这意味着用户可以定义流水线需要的工具,而无需手动配置代理。 实际上,只需对 Jenkinsfile进行少量编辑,任何 packaged in a Docker container的工具, 都可轻松使用。
Jenkinsfile (Declarative Pipeline)
1 | pipeline { |
Toggle Scripted Pipeline (Advanced)
当流水线执行时, Jenkins 将会自动地启动指定的容器并在其中执行指定的步骤:
1 | [Pipeline] stage |
容器的缓存数据
许多构建工具都会下载外部依赖并将它们缓存到本地以便于将来的使用。 由于容器最初是由 “干净的” 文件系统构建的, 这导致流水线速度变慢, 因为它们不会利用后续流水线运行的磁盘缓存。 on-disk caches between subsequent Pipeline runs.
流水线支持 向Docker中添加自定义的参数, 允许用户指定自定义的 Docker Volumes 装在, 这可以用于在流水线运行之间的 agent上缓存数据。下面的示例将会在 流水线运行期间使用 maven container缓存 ~/.m2, 从而避免了在流水线的后续运行中重新下载依赖的需求。
Jenkinsfile (Declarative Pipeline)
1 | pipeline { |
Toggle Scripted Pipeline (Advanced)
使用多个容器
代码库依赖于多种不同的技术变得越来越容易。比如, 一个仓库既有基于Java的后端API 实现 and 有基于JavaScript的前端实现。 Docker和流水线的结合允许 Jenkinsfile 通过将 agent {} 指令和不同的阶段结合使用 multiple 技术类型。
Jenkinsfile (Declarative Pipeline)
1 | pipeline { |
Toggle Scripted Pipeline (Advanced)
使用Dockerfile
对于更需要自定义执行环境的项目, 流水线还支持从源仓库的Dockerfile 中构建和运行容器。 与使用”现成” 容器的 previous approach 不同的是 , 使用 agent { dockerfile true } 语法从 Dockerfile 中构建一个新的镜像而不是从 Docker Hub中拉取一个。
重复使用上面的示例, 使用一个更加自定义的 Dockerfile:
1 | FROM node:7-alpine |
通过提交它到源仓库的根目录下, 可以更改 Jenkinsfile 文件,来构建一个基于该 Dockerfile 文件的容器然后使用该容器运行已定义的步骤:
Jenkinsfile (Declarative Pipeline)
1 | pipeline { |
agent { dockerfile true } 语法支持大量的其它选项,这些选项的更详细的描述请参考 流水线语法 部分。
指定Docker标签
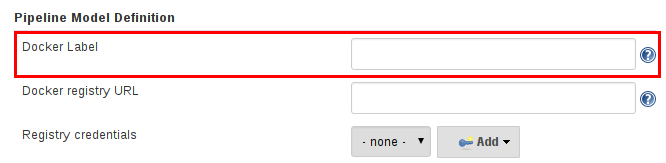
的了 agent 都能够运行基于Docker的流水线。 对于有macOS, Windows, 或其他代理的Jenkins环境, 不能运行Docker守护进程, 这个默认设置可能会有问题。 流水线在 Manage Jenkins 页面和 文件夹别提供一个了全局选项,用来指定运行基于Docker的流水线的代理 (通过 标签)。
脚本化流水线的高级用法
运行 “sidecar” 容器
在流水线中使用Docker可能是运行构建或一组测试的所依赖的服务的有效方法。类似于 sidecar 模式, Docker 流水线可以”在后台”运行一个容器 , 而在另外一个容器中工作。 利用这种sidecar 方式, 流水线可以为每个流水线运行 提供一个”干净的” 容器。
考虑一个假设的集成测试套件,它依赖于本地 MySQL 数据库来运行。使用 withRun 方法, 在 Docker Pipeline 插件中实现对脚本化流水线的支持, Jenkinsfile 文件可以运行 MySQL作为sidecar :
1 | node { |
该示例可以更进一步, 同时使用两个容器。 一个 “sidecar” 运行 MySQL, 另一个提供执行环境, 通过使用Docker 容器链接。
1 | ode { |
上面的示例使用 withRun公开的项目, 它通过 id 属性具有可用的运行容器的ID。使用该容器的 ID, 流水线通过自定义 Docker 参数生成一个到inside() 方法的链。
The id property can also be useful for inspecting logs from a running Docker container before the Pipeline exits:
1 | sh "docker logs ${c.id}" |
构建容器
为了构建 Docker 镜像,Docker 流水线 插件也提供了一个 build() 方法用于在流水线运行期间从存储库的Dockerfile 中创建一个新的镜像。
使用语法 docker.build("my-image-name") 的主要好处是, 脚本化的流水线能够使用后续 Docker流水线调用的返回值, 比如:
1 | node { |
该返回值也可以用于通过 push() 方法将Docker 镜像发布到 Docker Hub, 或 custom Registry,比如:
1 | node { |
镜像 “tags”的一个常见用法是 为最近的, 验证过的, Docker镜像的版本,指定 latest 标签。 push() 方法接受可选的 tag 参数, 允许流水线使用不同的标签 push customImage , 比如:
1 | node { |
在默认情况下, build() 方法在当前目录构建一个 Dockerfile。提供一个包含 Dockerfile文件的目录路径作为build() 方法的第二个参数 就可以覆盖该方法, 比如:
1 | node { |
从在
./dockerfiles/test/Dockerfile中发现的Dockerfile中构建test-image。
通过添加其他参数到 build() 方法的第二个参数中,传递它们到 docker build。 当使用这种方法传递参数时, 该字符串的最后一个值必须是Docker文件的路径。
该示例通过传递 -f标志覆盖了默认的 Dockerfile :
1 | node { |
从在
./dockerfiles/Dockerfile.test发现的Dockerfile构建my-image:${env.BUILD_ID}。
使用远程 Docker 服务器
默认情况下, Docker Pipeline 插件会与本地的Docker的守护进程通信, 通常通过 /var/run/docker.sock访问。
要选择一个非默认的Docker 服务器, 比如 Docker 集群, 应使用withServer() 方法。
通过传递一个URI, 在Jenkins中预先配置的 Docker Server Certificate Authentication的证书ID, 如下:
1 | node { |
inside()和build()不能正确的在Docker集群服务器中工作。对于
inside()工作, Docker 服务器和Jenkins 代理必须使用相同的文件系统, 这样才能安装工作区。目前,Jenkins 插件和Docker CLI 都不会自动的 检查服务器远程运行的情况; 典型的症状是嵌套的
sh命令的错误,比如
2
当 Jenkins 检查到代理本身在 Docker 容器中运行时, 它会自动地传递
--volumes-from参数到inside容器,确保它能够和代理共享工作区。另外,Docker集群的一些版本不支持自定义注册。
使用自定义注册表
默认情况下, Docker 流水线 集成了 Docker Hub默认的 Docker注册表。 .
为了使用自定义Docker 注册表, 脚本化流水线的用户能够使用 withRegistry() 方法完成步骤,传入自定义注册表的URL, 比如:
1 | node { |
对于需要身份验证的Docker 注册表, 从Jenkins 主页添加一个 “Username/Password” 证书项, 并使用证书ID 作为 withRegistry()的第二个参数:
1 | node { |
扩展共享库
流水线开发工具
流水线语法
本节是建立在 流水线入门内容的基础上,而且,应当被当作一个参考。 对于在实际示例中如何使用流水线语法的更多信息, 请参阅本章在流水线插件的2.5版本中的 使用 Jenkinsfile部分, 流水线支持两种离散的语法,具体如下对于每种的优缺点, 参见语法比较。
正如 本章开始讨论的, 流水线最基础的部分是 “步骤”。基本上, 步骤告诉 Jenkins 要做什么,以及作为声明式和脚本化流水线语法的基本构建块。
对于可用步骤的概述, 请参考 流水线步骤引用,它包含了一个构建到流水线的步骤和 插件提供的步骤的全面的列表。
声明式流水线
声明式流水线是最近添加到 Jenkins 流水线的 [1],它在流水线子系统之上提供了一种更简单,更有主见的语法。
所有有效的声明式流水线必须包含在一个 pipeline 块中, 比如:
1 | pipeline { |
在声明式流水线中有效的基本语句和表达式遵循与 Groovy的语法同样的规则, 有以下例外:
- 流水线顶层必须是一个 block, 特别地:
pipeline { } - 没有分号作为语句分隔符,,每条语句都必须在自己的行上。
- 块只能由 节段, 指令, 步骤, 或赋值语句组成。 *属性引用语句被视为无参方法调用。 例如, input被视为 input()
节段
代理agent
agent 部分指定了整个流水线或特定的部分, 将会在Jenkins环境中执行的位置,这取决于 agent 区域的位置。该部分必须在 pipeline 块的顶层被定义, 但是 stage 级别的使用是可选的。
| Required | Yes |
|---|---|
| Parameters | Described below |
| Allowed | In the top-level pipeline block and each stage block. |
参数
为了支持作者可能有的各种各样的用例流水线, agent 部分支持一些不同类型的参数。这些参数应用在pipeline块的顶层, 或 stage 指令内部。
any
在任何可用的代理上执行流水线或阶段。例如:
agent anynone
当在
pipeline块的顶部没有全局代理, 该参数将会被分配到整个流水线的运行中并且每个stage部分都需要包含他自己的agent部分。比如:agent nonelabel
在提供了标签的 Jenkins 环境中可用的代理上执行流水线或阶段。 例如:
agent { label 'my-defined-label' }node
agent { node { label 'labelName' } }和agent { label 'labelName' }一样, 但是node允许额外的选项 (比如customWorkspace)。docker
使用给定的容器执行流水线或阶段。该容器将在预置的 node上,或在匹配可选定义的
label参数上,动态的供应来接受基于Docker的流水线。docker也可以选择的接受args参数,该参数可能包含直接传递到docker run调用的参数, 以及alwaysPull选项, 该选项强制docker pull,即使镜像名称已经存在。 比如:agent { docker 'maven:3-alpine' }或
1 | agent { |
dockerfile
执行流水线或阶段, 使用从源代码库包含的 Dockerfile 构建的容器。为了使用该选项, Jenkinsfile 必须从多个分支流水线中加载, 或者加载 “Pipeline from SCM.” 通常,这是源代码仓库的根目录下的 Dockerfile : agent { dockerfile true }. 如果在另一个目录下构建 Dockerfile , 使用 dir 选项: agent { dockerfile {dir 'someSubDir' } }。如果 Dockerfile 有另一个名称, 你可以使用 filename 选项指定该文件名。你可以传递额外的参数到 docker build ... 使用 additionalBuildArgs 选项提交, 比如 agent { dockerfile {additionalBuildArgs '--build-arg foo=bar' } }。 例如, 一个带有 build/Dockerfile.build 的仓库,期望一个构建参数 version:
1 | agent { |
常见选项
有一些应用于两个或更多 agent 的实现的选项。他们不被要求,除非特别规定。
label
一个字符串。该标签用于运行流水线或个别的
stage。该选项对node,docker和dockerfile可用,node要求必须选择该选项。customWorkspace
一个字符串。在自定义工作区运行应用了
agent的流水线或个别的stage, 而不是默认值。 它既可以是一个相对路径, 在这种情况下,自定义工作区会存在于节点工作区根目录下, 或者一个绝对路径。比如:
1 | agent { |
该选项对 node, docker 和 dockerfile 有用 。
reuseNode
一个布尔值, 默认为false。 如果是true, 则在流水线的顶层指定的节点上运行该容器, 在同样的工作区, 而不是在一个全新的节点上。
这个选项对 docker 和 dockerfile 有用, 并且只有当 使用在个别的 stage 的 agent 上才会有效。
示例
规模 Pipelines
用 Blue Ocean 创建流水线
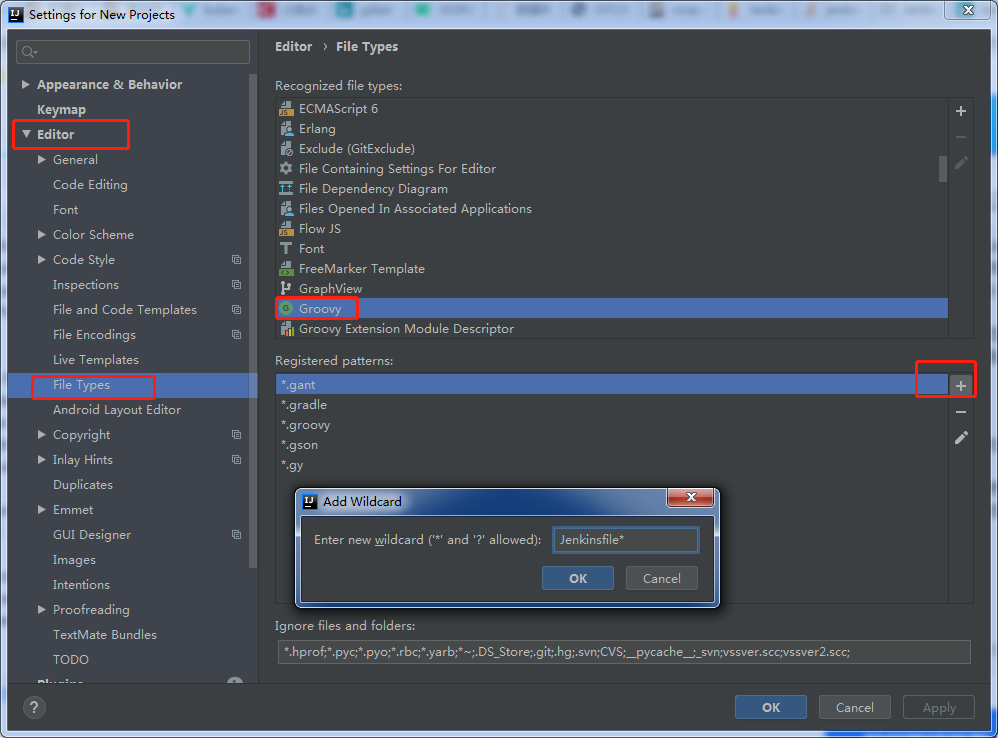
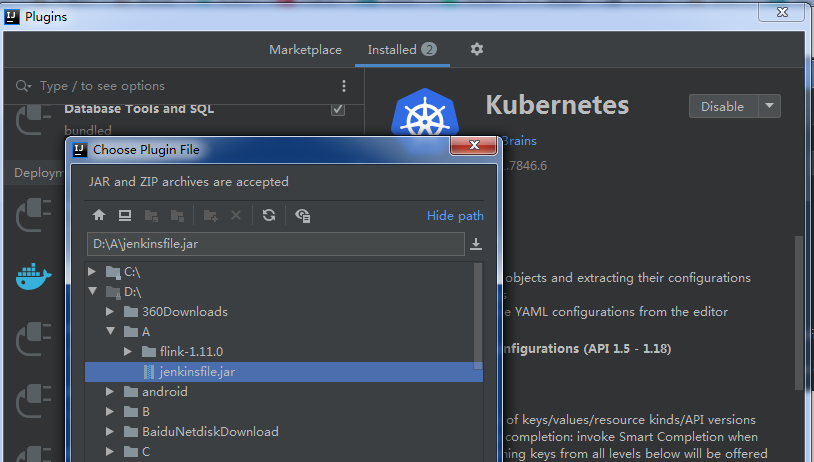
IDEA 集成Jenkinsfile插件(不好用)
https://plugins.jetbrains.com/plugin/10127-jenkinsfile-idea-plugin
插件作者没有上传到插件库,所以我拉下来打包自己本地安装测试后,就上传了
插件原地址:https://github.com/oliverlockwood/jenkinsfile-idea-plugin
The plugin author didn t upload it to the plugin library so I pulled it off and packed my local installation test and uploaded it
Plug in address :https://github.com/oliverlockwood/jenkinsfile-idea-plugin
most HTML tags may be used
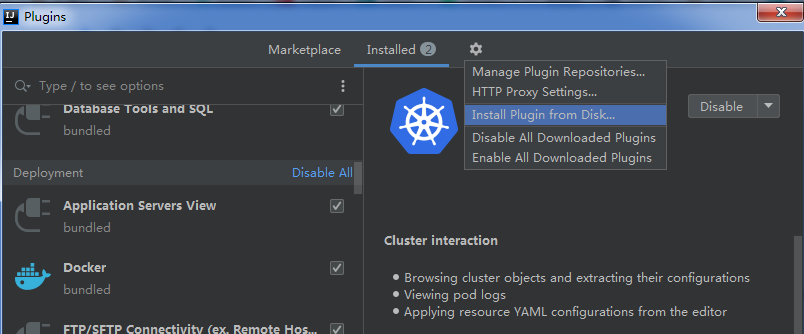
IDEA 设置 Jenkinsfile 为 Groovy 扩展类型