分布式计算总站:https://equn.com/wiki/%E9%A6%96%E9%A1%B5
知乎·分布式计算:https://www.zhihu.com/topic/19552071/hot
批计算
MapReduce 是一种 分而治之 的计算模式,在分布式领域中,除了典型的 Hadoop 的 MapReduce(Google MapReduce 的开源实现),还有 Fork-Join,Fork-Join 是 Java 等语言或库提供的原生多线程并行处理框架,采用线程级的分而治之计算模式。它充分利用多核 CPU 的优势,以递归的方式把一个任务拆分成多个“小任务”,把多个“小任务”放到多个处理器上并行执行,即 Fork 操作。当多个“小任务”执行完成之后,再将这些执行结果合并起来即可得到原始任务的结果,即 Join 操作。
虽然 MapReduce 是进程级的分而治之计算模式,但与 Fork-Join 的核心思想是一致的。因此,Fork-Join 又被称为 Java 版的 MapReduce 框架。但,MapReduce 和 Fork-Join 之间有一个本质的区别:Fork-Join 不能大规模扩展,只适用于在单个 Java 虚拟机上运行,多个小任务虽然运行在不同的处理器上,但可以相互通信,甚至一个线程可以“窃取”其他线程上的子任务。
MapReduce 可以大规模扩展,适用于大型计算机集群。通过 MapReduce 拆分后的任务,可以跨多个计算机去执行,且各个小任务之间不会相互通信。
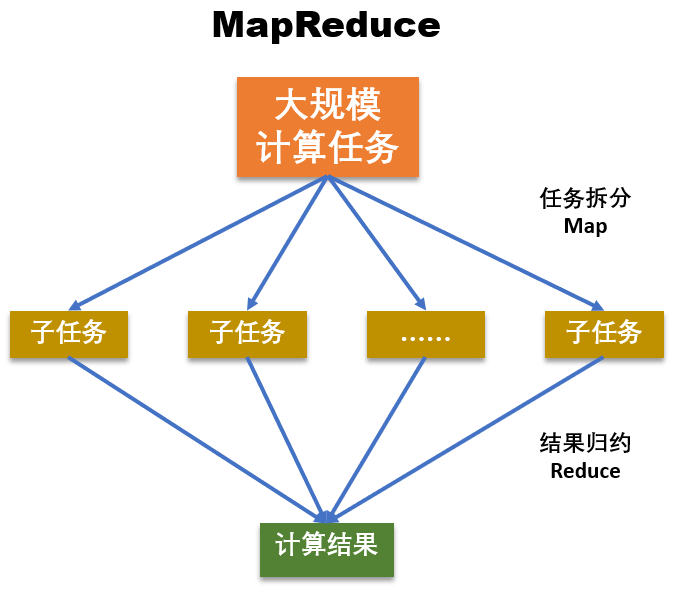

MapReduce 模式的核心思想是,将大任务拆分成多个小任务,针对这些小任务分别计算后,再合并各小任务的结果以得到大任务的计算结果,任务运行完成后整个任务进程就结束了,属于短任务模式。但任务进程的启动和停止是一件很耗时的事儿,因此 MapReduce 对处理实时性的任务就不太合适了
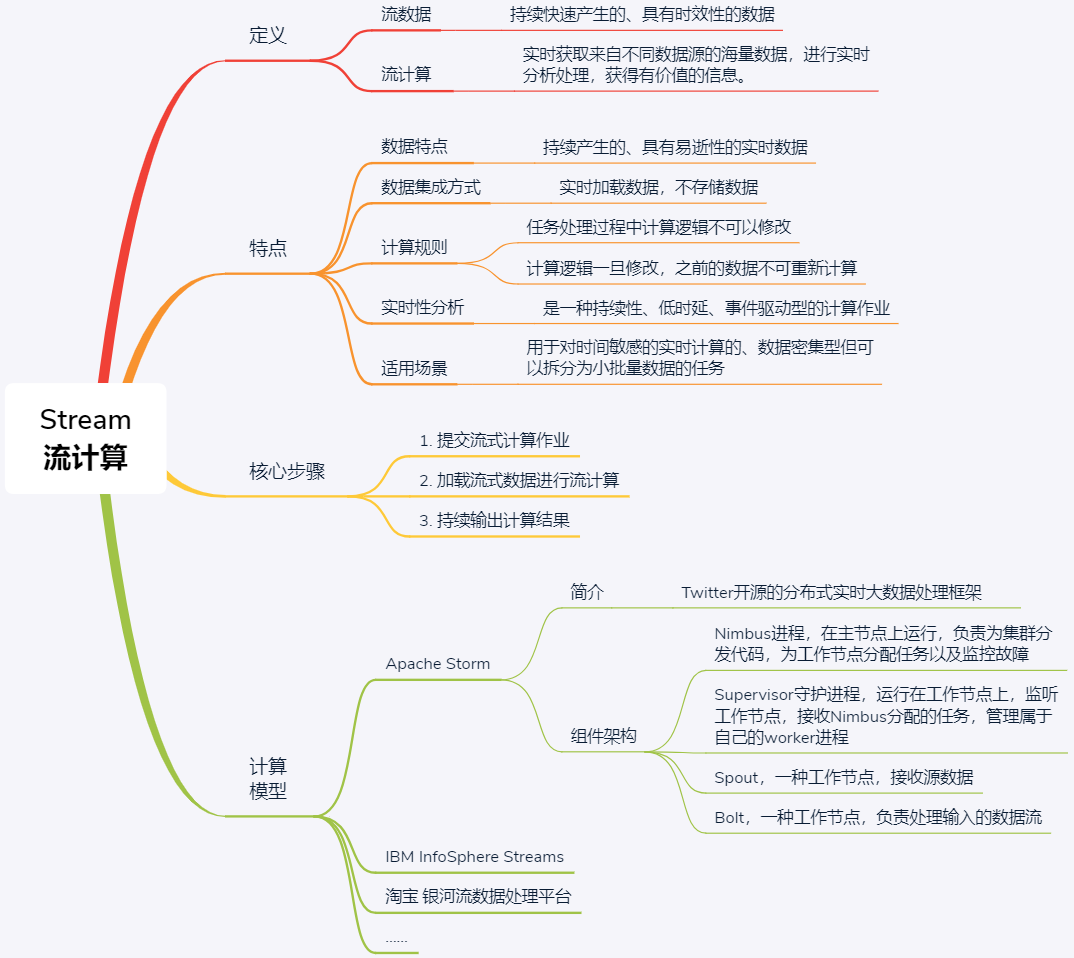
流计算
实时性任务主要是针对流数据的处理,对处理时延要求很高,通常需要有常驻服务进程,等待数据的随时到来随时处理,以保证低时延。处理流数据任务的计算模式,在分布式领域中叫作 Stream。近年来,由于网络监控、传感监测、AR/VR 等实时性应用的兴起,一类需要处理流数据的业务发展了起来。比如各种直播平台中,我们需要处理直播产生的音视频数据流等。这种如流水般持续涌现,且需要实时处理的数据,我们称之为流数据。
总结来讲,流数据的特征主要包括以下 4 点:
- 数据如流水般持续、快速地到达;
- 海量数据规模,数据量可达到 TB 级甚至 PB 级;
- 对实时性要求高,随着时间流逝,数据的价值会大幅降低;
- 数据顺序无法保证,系统无法控制将要处理的数据元素的顺序。
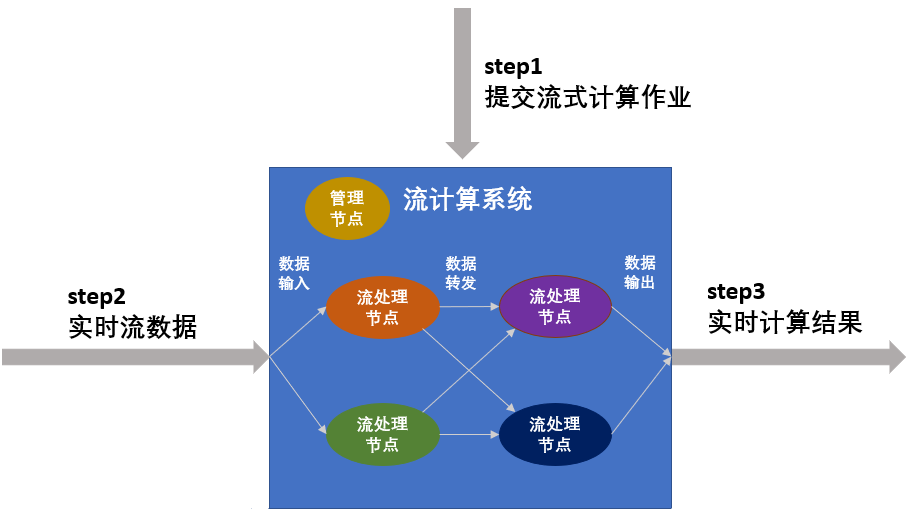
第一步,提交流式计算作业
第二步,加载流式数据进行流计算
第三步,持续输出计算结果。