11.1、单机版Hadoop安装
11.2、ES-Hadoop安装
11.3、从 HDFS 到 Elasticsearch
11.4、从Elasticsearch 到 HDFS
-—————————————————–
11.1、单机版Hadoop安装
hadoop分为 单机模式、伪分布式模式、完全分布式模式
1、ssh免密登录

vi /etc/ssh/ssh_config
文件尾添加:
1 | StrictHostKeyChecking no |

2、hadoop下载安装
[root@localhost data]# mkdir -p /data/hadoop
[root@localhost data]# cd /data/hadoop
[root@localhost hadoop]# wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
3、haoop 单机模式
[root@localhost hadoop]# tar -zxf hadoop-2.7.7.tar.gz
[root@localhost hadoop]# mkdir input
[root@localhost hadoop]# echo “hello world” > input/file1.txt
[root@localhost hadoop]# echo “hello hadoop” > input/file2.txt
[root@localhost hadoop]# ./hadoop-2.7.7/bin/hadoop jar ./hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /data/hadoop/input/ /data/hadoop/output
[root@localhost hadoop]# cat output/part-r-00000
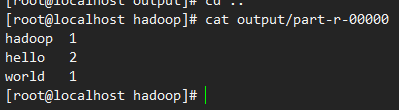
4、hadoop 伪分布式模式
[root@localhost hadoop]# vi hadoop-2.7.7/etc/hadoop/hadoop-env.sh
1 | 修改JAVA_HOME 为: |
[root@localhost hadoop]# mkdir -p /data/hadoop/hdfs/tmp
[root@localhost hadoop]# vi hadoop-2.7.7/etc/hadoop/core-site.xml
1 | <configuration> |
hadoop.tmp.dir 可以自定义;
fs.default.name 保存了NameNode的位置,HDFS和MapReduce组件都需要用到它;
[root@localhost hadoop]# vi hadoop-2.7.7/etc/hadoop/mapred-site.xml.template
1 | <configuration> |
mapred.job.tracker 保存JobTracker的位置,只有MapReduce需要知道;
[root@localhost hadoop]# vi hadoop-2.7.7/etc/hadoop/hdfs-site.xml
配置HDFS数据库的复制次数:
1 | <configuration> |
以上就配置完了,接下来格式化 namenode:
[root@localhost hadoop]# ./hadoop-2.7.7/bin/hadoop namenode -format
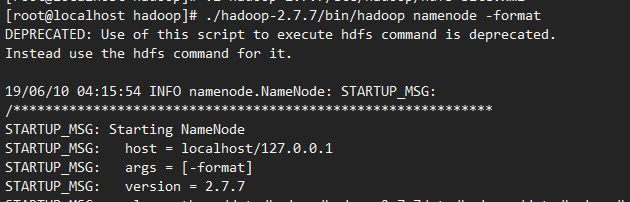
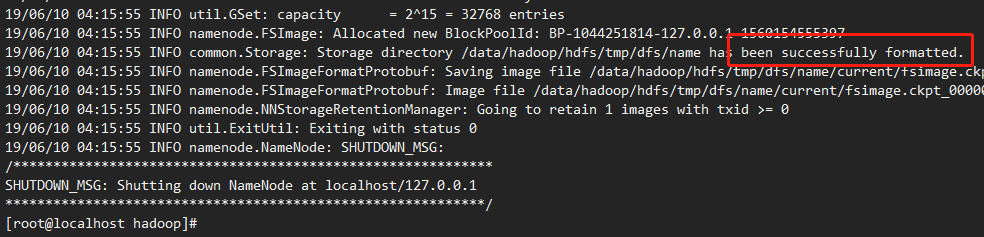
启动hadoop:
[root@localhost hadoop]# ./hadoop-2.7.7/sbin/start-all.sh

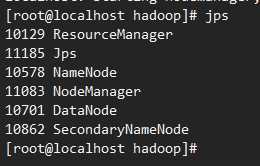
启动成功;
添加hadoop到环境变量:
[root@localhost hadoop-2.7.7]# vi /etc/profile
1 | export HADOOP_HOME=/data/hadoop/hadoop-2.7.7 |
[root@localhost hadoop-2.7.7]# source /etc/profile
5、HDFS常用操作
开放 50070 端口
[root@localhost hadoop-2.7.7]# firewall-cmd –permanent –add-port=50070/tcp
success
[root@localhost hadoop-2.7.7]# firewall-cmd –reload
success
[root@localhost hadoop-2.7.7]# firewall-cmd –query-port=50070/tcp
yes
访问hdfs:http://172.18.1.51:50070/
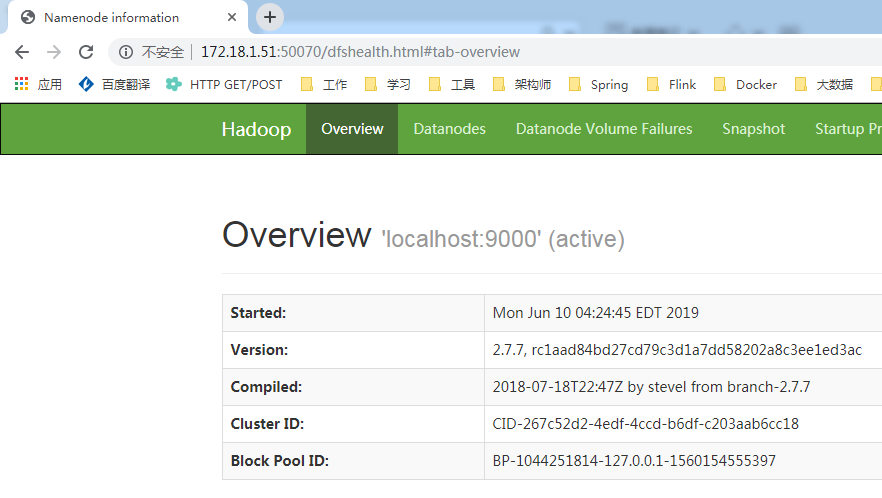
[root@localhost hadoop]# hadoop fs -ls /
[root@localhost hadoop]# hadoop fs -mkdir /work
[root@localhost hadoop]# touch aa.txt
[root@localhost hadoop]# hadoop fs -put aa.txt /work
[root@localhost hadoop]# hadoop fs -test -e /work/aa.txt
[root@localhost hadoop]# echo $?
0
[root@localhost hadoop]# echo “hello hdfs” > aa.txt
[root@localhost hadoop]# hadoop fs -appendToFile aa.txt /work/aa.txt
[root@localhost hadoop]# hadoop fs -cat /work/aa.txt
hello hdfs
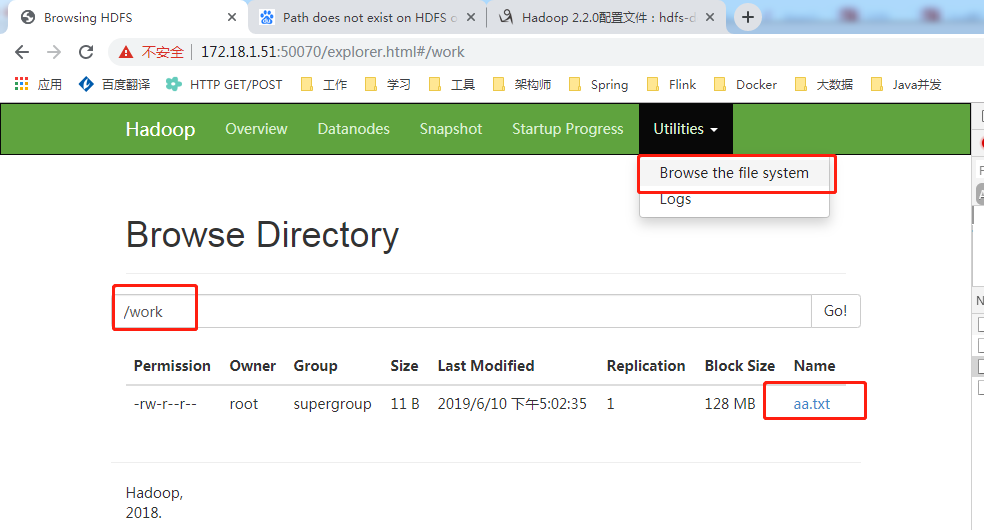
[root@localhost hadoop]# hadoop fs -rm /work/aa.txt
19/06/10 05:04:30 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /work/aa.txt
[root@localhost hadoop]# hadoop fs -rmr /work/a
rmr: DEPRECATED: Please use ‘rm -r’ instead.
rmr: `/work/a’: No such file or directory
[root@localhost hadoop]# hadoop dfsadmin -report
[root@localhost hadoop]#
11.2、引入ES-Hadoop依赖
1 | <dependencies> |
11.3、从 HDFS 到 Elasticsearch
准备json文档,上传到HDFS中
vi blog.json
1 | {"id":5,"title":"JavaScript高级程序设计","language":"javascript","author":"NicholasC.Zakas","price":66.4,"publish_time":"2012-03-02","desc":"JavaScript技术经典名著。"} |
[root@localhost hadoop]# hadoop fs -put blog.json /work 
编写代码,从 hdfs 读取数据,写入到 Elasticsearch:
1 | package com.learn.eshdoop; |
pom中指定主类:
1 | <build> |
运行:mvn clean package 生成对应的jar 包
[root@localhost hadoop]# mv es-hadoop-learn-1.0-SNAPSHOT-jar-with-dependencies.jar HdfsToEs.jar
[root@localhost hadoop]# hadoop jar HdfsToEs.jar /work/blog.json

在Kibana 中 查看
GET blog/_mapping
GET blog/_search

11.4、从Elasticsearch 到 HDFS
1、将索引 blog 保存到 hdfs
添加Java类:
1 | package com.learn.eshdoop; |
修改pom.xml中的主类为:com.learn.eshdoop.EsToHdfs。
mvn clean package 重新打包
上传以后执行:
[root@localhost hadoop]# mv es-hadoop-learn-1.0-SNAPSHOT-jar-with-dependencies.jar EsIndexToHdfs.jar
[root@localhost hadoop]# hadoop jar EsIndexToHdfs.jar /work/blog_mapping
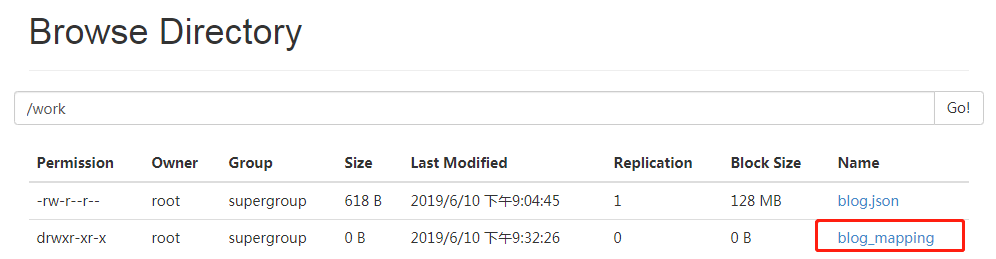
[root@localhost hadoop]# hadoop fs -cat /work/blog_mapping/part-r-00000

2、将带条件查询 blog 的 数据 保存到 hdfs
1 | package com.learn.eshdoop; |
在pom.xml中修改主类名称为:com.learn.eshdoop.EsQueryToHdfs;
mvn clean package 重新打包,然后上传;
[root@localhost hadoop]# mv es-hadoop-learn-1.0-SNAPSHOT-jar-with-dependencies.jar EsQueryToHdfs.jar
[root@localhost hadoop]# hadoop jar EsQueryToHdfs.jar /work/EsQueryToHdfs
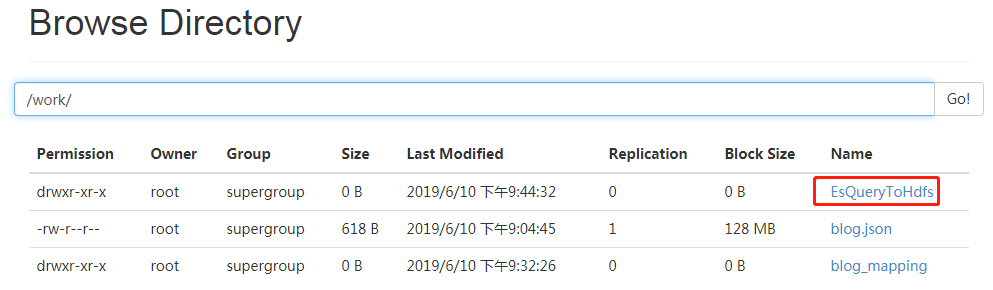
[root@localhost hadoop]# hadoop fs -cat /work/EsQueryToHdfs/part-r-00000
