目录
- 官网
- 下载Lucune文件库
- 下载Luke——查看索引的GUI工具
- 下载 IK 分词工具 —— 轻量级中文分词工具包
- 工程搭建
-—————————————————
官网
下载Lucune文件库
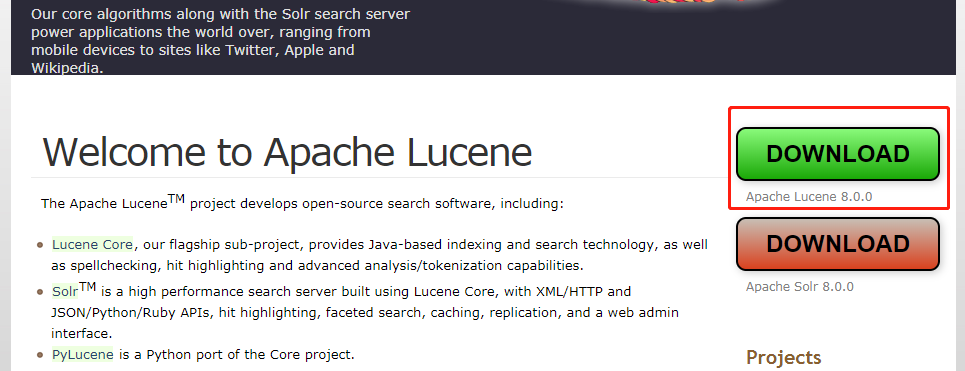
https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/java/8.0.0/
或者在工程中添加maven依赖
https://mvnrepository.com/artifact/org.apache.lucene/lucene-core/
1 | <dependency> |
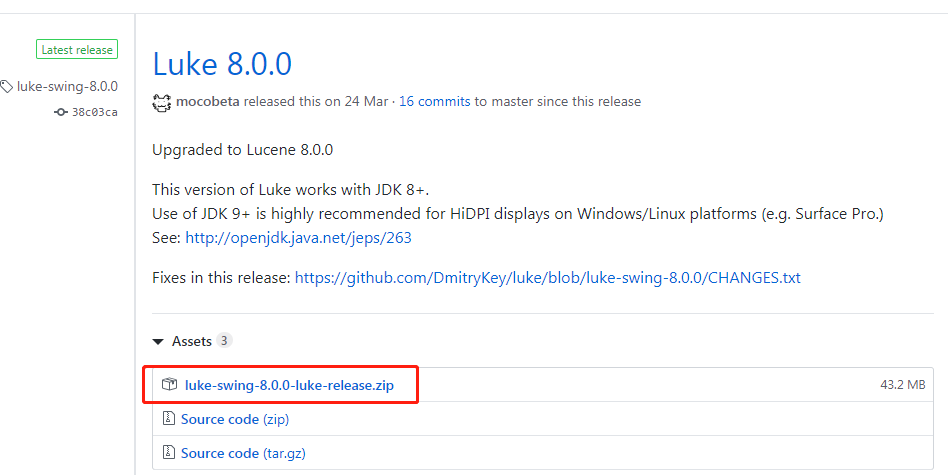
下载Luke——查看索引的GUI工具
主要功能:
- 查看文档和分析字段内容;
- 搜索索引;
- 执行索引维护;
- 从HDFS读取索引;
- 将全部或部分索引转换为XML格式导出;
- 测试自定义的Lucene分词器;
注意:Luke的版本要跟Lucene保持一致
项目地址:https://github.com/DmitryKey/luke/releases
下载 IK 分词工具 —— 轻量级中文分词工具包
独立于Lucene,面向Java的公用分词组件
同时提供了 对Lucene的默认优化实现
IK Analyzer2012的特性:
- 采用“正向迭代最细力度切分算法”,支持细粒度和智能分词两种切分模式;
- 具有 160万字/s 的高速处理能力,i73.4G双核、4G内存,win7 64位,jdk1.6;
- 支持简单的分词排歧义处理、数量词合并输出;
- 多子处理器分析模式,支持英文字母、数字、中文词汇等分词处理、兼容韩文、日文字符;
- 优化词典存储,更小的内存占用。
下载地址(需要翻墙):https://code.google.com/p/ik-analyzer/downloads/list
也可有上我的 oschina上下载:
安装包文件列表:
- drwxr-xr-x 1 doc/ —— API 文档说明
- -rw-r–r– 1 IKAnalyzer.cfg.xml —— 分词器扩展配置文件
- -rw-r–r– 1 IKAnalyzer2012_u6.jar —— 主jar包
- -rw-r–r– 1 IKAnalyzer中文分词器V2012_U5使用手册.pdf
- -rw-r–r– 1 IKAnalyzer中文分词器V2012使用手册.pdf
- -rw-r–r– 1 LICENSE.txt —— Apache版权申明
- -rw-r–r– 1 NOTICE.txt —— Apache版权申明
- -rw-r–r– 1 stopword.dic —— 停止词典
部署步骤:
把 IKAnalyzer2012_u6.jar 放在部署项目的lib目录下
把 stopword.dic 和 IKAnalyzer.cfg.xml 放在 class根目录,对于web工程时 WEB-INFO/classes 目录下
工程搭建
1、maven 安装 IKAnalyzer2012_u6.jar
mvn install:install-file -Dfile=D:\java\oschina\lucene-learn\lucene-chapter2\lib\IKAnalyzer2012_u6.jar -DgroupId=org.wltea.analyzer -DartifactId=IKAnalyzer -Dversion=2012_u6 -Dpackaging=jar -DgeneratePom=true -DcreateChecksum=true
2、在pom.xml中添加
1 | <dependency> |
3、 stopword.dic 和 IKAnalyzer.cfg.xml 放在 src\main\resources 目录下
这样编译完成后,它就会放在 classes 目录下