目录
2.3.1、Lucene分词系统
2.3.2、分词测试
2.3.3、IK分词器配置
2.3.4、中文分词器对比
2.3.5、扩展停用词词典
2.3.6、扩展自定义词典
-——————————————————————
2.3.1、Lucene分词系统
索引和查询 都是以 词项 为基本单位
Lucene中,分词 主要依靠 Analyzer类 解析实现
Analyzer是抽象类,内部调用 TokenStream 实现
2.3.2、分词测试
StandardAnalyzer 分词器测试:
1 | package com.learn.lucene.chapter2.analyzer; |
运行结果:
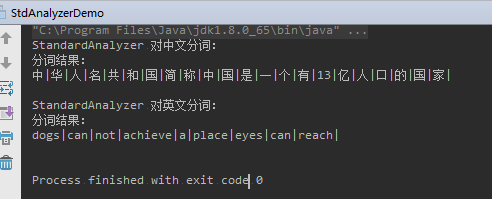
测试多种Analyzer,注意要特意指定 jdk8:
1 | package com.learn.lucene.chapter2.analyzer; |
运行结果:
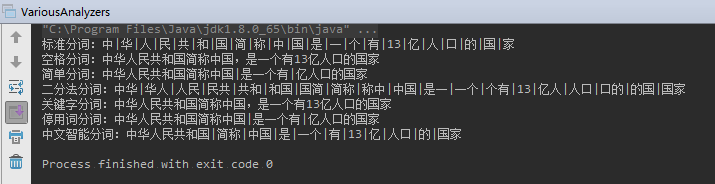
2.3.3、IK分词器配置
Lucene 8.0 实用 IK分词器需要修改 IKTokenizer 和 IKAnalyzer
在 com.learn.lucene.chapter2.ik 下 新建 IKTokenizer8x.java 和 IKAnalyzer8x.java
1 | package com.learn.lucene.chapter2.ik; |
1 | package com.learn.lucene.chapter2.ik; |
实例化 IKAnalyzer8x 就能实用IK分词器了
1、 默认使用细粒度切分算法:
Analyzer analyzer = new IKAnalyzer8x();
2、创建智能切分算法的 IKAnalyzer:
Analyzer analyzer = new IKAnalyzer8x(true);
2.3.4、中文分词器对比
分词效果会直接影响文档搜索的准确性
我们对比一下 Lucene自带的 SmartChineseAnalyzer 和 IK Analyzer的效率。
1 | package com.learn.lucene.chapter2.analyzer; |
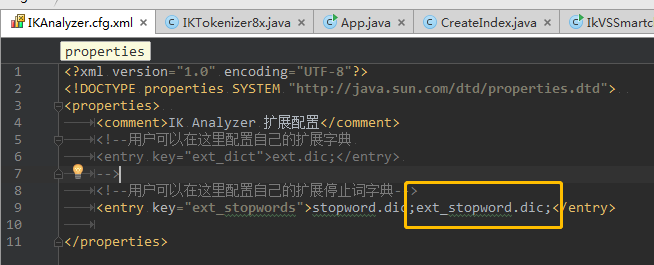
2.3.5、扩展停用词词典
IK Analyzer 默认的停用词词典为 IKAnalyzer2012_u6/stopword.dic
这个词典只有30多个英文停用词,并不完整
推荐使用扩展额停用词词表:https://github.com/cseryp/stopwords
在工程中新建 ext_stopword.dic,放在IKAnalyzer.cfg.xml同一目录;
编辑IKAnalyzer.cfg.xml,