目录
2.5.1、搜索入门
2.5.2、多域搜索(MultiFieldQueryParse)
2.5.3、词项搜索(TermQuery)
2.5.4、布尔搜索(BooleanQuery)
2.5.5、范围搜索(RangeQuery)
2.5.6、前缀搜索(PrefixQuery)
2.5.7、多关键字搜索(PhraseQuery)
2.5.8、模糊搜索(FuzzyQuery)
2.5.9、通配符搜索(WildcardQuery)
-—————————————————
文档索引完成以后就能对其进行搜索;
当用户输入一个关键字,
–> 首先 对这个关键字 进行 分析和处理, 转化成后台可以理解的形式
–> 进行检索
2.5.1、搜索入门
处理关键词 <==> 构建Query对象的过程;
搜索文档 <==> 实例化 IndexSearcher 对象,使用search()方法完成;
参数:Query对象
结果:保存在 TopDocs 类型的文档集合中;
删除indexdir下的索引文件后,重新使用CreateIndex.java 生成索引
1 | package com.learn.lucene.chapter2.queries; |
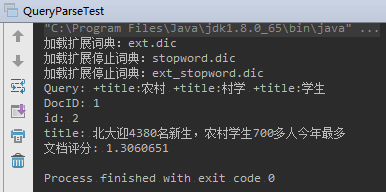
运行结果:
修改后再运行:
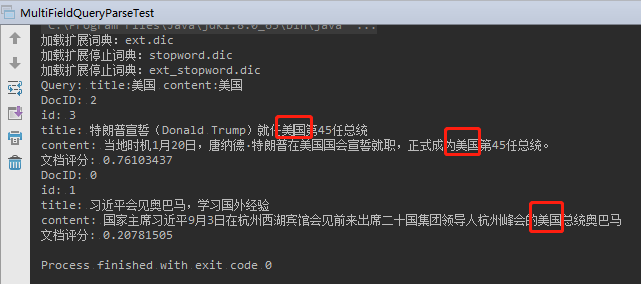
2.5.2、多域搜索(MultiFieldQueryParse)
根据多个字段搜索
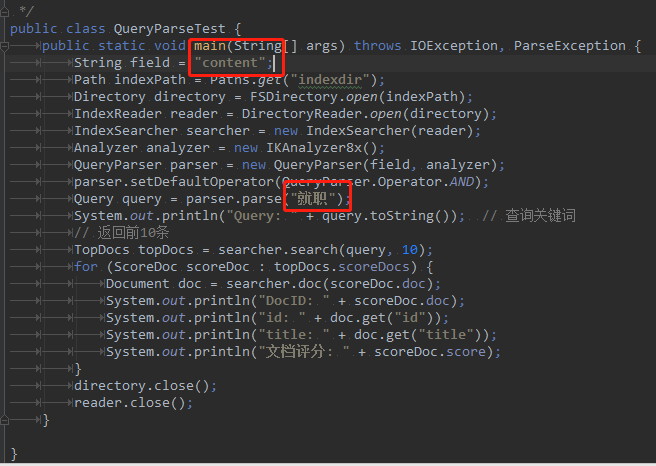
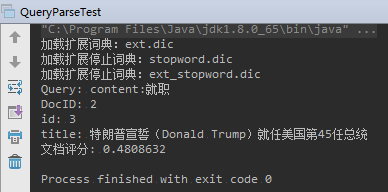
1 | package com.learn.lucene.chapter2.queries; |
运行结果:
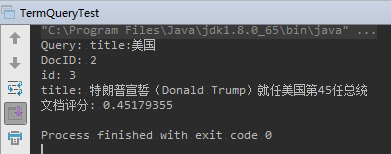
2.5.3、词项搜索(TermQuery)
TermQuery 是 最常用的 Query
TermQuery 是 Lucene中搜索的最基本单位
本质上:一个词条就是一个 key/value 对
使用TermQuery:
- 首先构造一个 Term对象;Term term = new Term(“title”, “美国”);
- 然后使用Term对象为参数,构造一个TermQuery对象;TermQuery query = new TermQuery(term);
1 | package com.learn.lucene.chapter2.queries; |
运行结果:
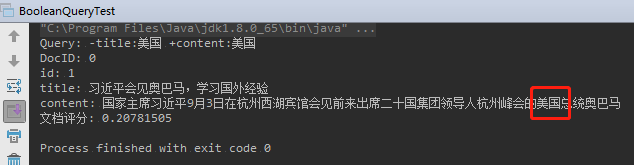
2.5.4、布尔搜索(BooleanQuery)
BooleanQuery 可以 组合 其他 Query,并标明他们的逻辑关系;
例如:查询 content 中包含美国,并且 title 不包含美国的文档;
1 | package com.learn.lucene.chapter2.queries; |
运行结果:
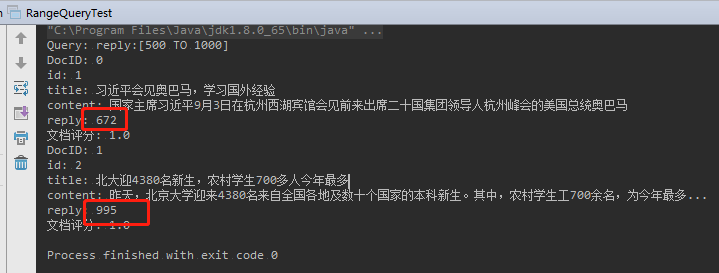
2.5.5、范围搜索(RangeQuery)
举例:查询新闻回复条数在 500~1000 之间的文档
1 | package com.learn.lucene.chapter2.queries; |
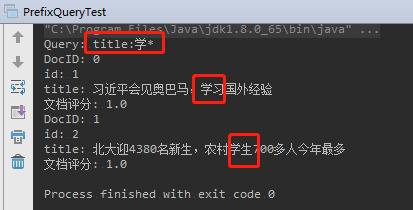
2.5.6、前缀搜索(PrefixQuery)
举例:搜索 包含以“学”开头的词项 的文档
1 | package com.learn.lucene.chapter2.queries; |
运行结果:
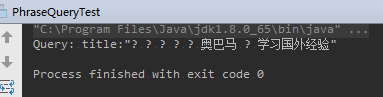
2.5.7、多关键字搜索(PhraseQuery)
- PhraseQuery 可以 通过add方法添加多个关键字
- 还可以通过 setSlop() 设定“坡度”,允许关键字之间 无关词汇存在量
1 | package com.learn.lucene.chapter2.queries; |
运行结果(感觉没有成功):
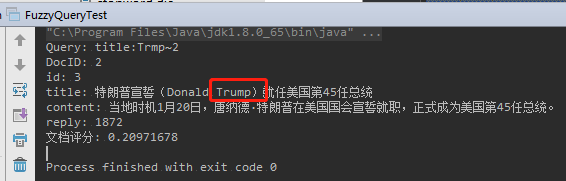
2.5.8、模糊搜索(FuzzyQuery)
它可以简单的识别两个相近的词语。
举例:“Trump”,写成“Trmp”,拼写错误,仍然可以搜索得到正确的结果
1 | package com.learn.lucene.chapter2.queries; |
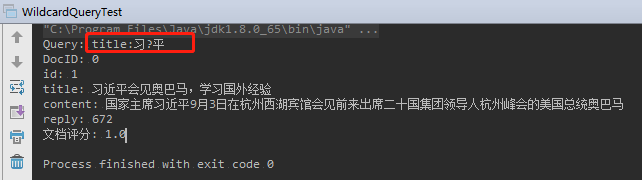
2.5.9、通配符搜索(WildcardQuery)
1 | package com.learn.lucene.chapter2.queries; |