2.7.1、问题提出
2.7.2、需求分析
2.7.3、编程实现
-———————————————-
2.7.1、问题提出
统计 一篇新闻文档,统计出现频率最高的哪些词语
2.7.2、需求分析
文本关键词提取算法、开源工具很多
本文:《从Lucene索引中 提取 词项频率Top N》
词条化:从文本中 去除 标点、停用词等;
索引过程的本质:词条化 生成 倒排索引的过程;
代码思路:IndexReader的getTermVector获取文档的某一个字段 Terms,从 terms 中获取 tf(term frequency),拿到词项的 tf 以后,放到map中 降序排序,取出 Top-N.
2.7.3、编程实现
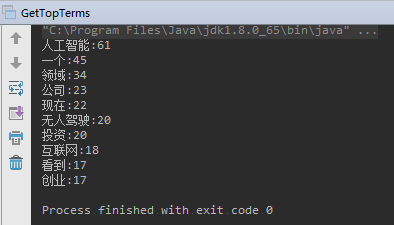
网上找到新闻稿《李开复:无人驾驶进入黄金时代 AI有巨大投资机会》,放在 testfile/news.txt 文件中。
对 testfile/news.txt 生成索引:
1 | package com.learn.lucene.chapter2.highfrequency; |
运行。
提取高频词:
1 | package com.learn.lucene.chapter2.highfrequency; |