3.3.1 Tika 简介
3.3.2、Tika下载
3.3.3、搭建工程
3.3.4、内容抽取
3.3.5、自动解析
-—————————————–
代码仓库:https://gitee.com/carloz/lucene-learn/tree/master/tika-demo
-—————————————–
3.3.1 Tika 简介
Apache Tika 用于 文件类型检测 和 文件内容提取;
使用目标群体: 搜索引擎、 内容索引和分析工具;
编程语言:Java;
- Tika 可以检测超过1000种不同类型的文档,比如 DOC、DOCX、PPT、PPTX、TXT、PDF;
- 所有的文本类型 都可以通过一个简单的接口被解析;
- 广泛应用于 搜索引擎、内容分析、文本翻译、数字资产管理 等领域;
- 通过一个通用的API提取 多种文件格式 的内容;
Tika特点:
- 统一解析器接口
- 低内存占用
- 快速处理
- 灵活元数据
- 解析器集成
- MIME类型检测
- 语言检测
3.3.2、Tika下载
官网:https://tika.apache.org/download.html

下载地址:http://mirror.bit.edu.cn/apache/tika/tika-app-1.20.jar
以 GUI 的方式打开:java -jar tika-app-1.20.jar -g
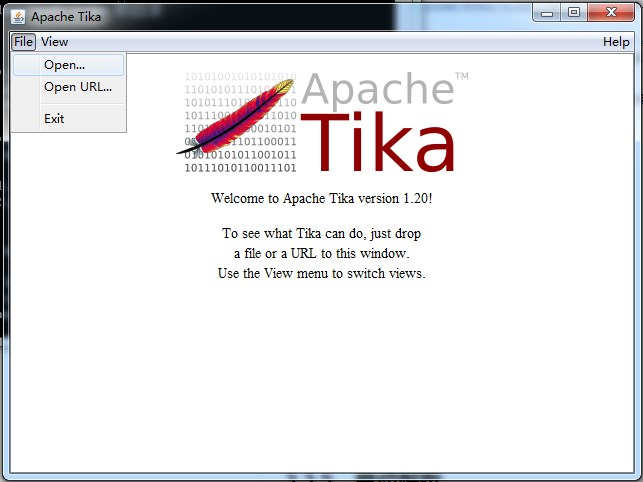
使用 File -> open 代开一个本地文件,查看提取完成以后的数据

3.3.3、搭建工程——Java中使用Tika
1、创建Maven工程 TikaDemo
2、添加pom引用
1 | <dependency> |
3、工程根目录下 新建 files文件夹, 存放 待提取的测试文件
4、新建名为 TikaParsePdfDemo.java

3.3.4、内容抽取——提取PDF文件的内容
1 | package com.learn.tikademo; |

- PDFParser —— 用于解析 PDF 文件; PDFParser pdfParser = new PDFParser();
- OOXMLParser —— 用于解析 MS Office 文件;OOXMLParser ooxmlParser = new OOXMLParser();
- TXTParser —— 用于解析 文本文件; TXTParser txtParser = new TXTParser();
- HtmlParser —— 用于解析 HTML 文件;HtmlParser htmlParser = new HtmlParser();
- XMLParser —— 用于解析 XML 文件;XMLParser xmlParser = new XMLParser();
- ClassParser —— 用于解析 class 文件;ClassParser classParser = new ClassParser();
Tika还可以解析 图像、音频(如 MP3)、视频(如MP4)等多种类型的文件
3.3.5、自动解析
上述解析pdf的例子如下:确定PDF文件 -> 实例化PDFParser -> 提取内容;
强大之处:Tika可以 先判断文件类型, 再根据文档类型实例化解析接口;
自动解析文档过程:
- 传任意类型文件到 Tika ==> Tika 自身检测文件类型;
- Tika解析器库,根据 文件类型,选择合适的解析器;
- 解析完成后,对文档内容 进行提取,元数据提取;
两种解析方案:
- 使用Tika对象解析
- 使用Parse接口解析
使用Tika对象解析:
1 | package com.learn.tikademo; |
使用Parse接口解析
1 | package com.learn.tikademo; |
运行结果查询: 