5.3.1、映射分类
5.3.2、动态映射
5.3.3、日期检测
5.3.4、静态映射
5.3.5、字段类型
5.3.6、元字段
5.3.7、映射参数
5.3.8、映射模板
-—————————————
映射 即 Mapping, 定义 一个文档及其所包含的字段 如何被存储和索引。
映射中 事先定义 数据类型、分词器
5.3.1、映射分类
动态映射:ES 根据 字段类型 自动识别; —— 偷懒方式
静态映射:写入数据之前 对字段的属性 手工设置;
5.3.2、动态映射
1 | PUT sinablog/user/1?routing=user123 |
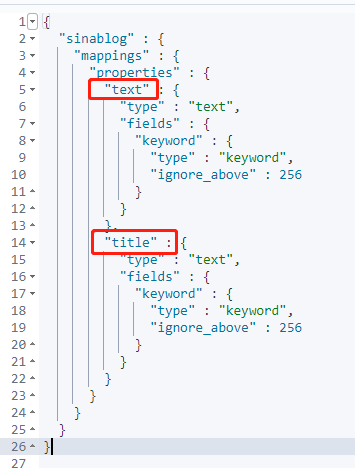
id 被推测为 long 类型
posttime被推测为 date 类型
title 和 content 被推测为 text 类型
如果 要把Elasticsearch当做 主要的数据存储 使用,动态Mapping 并不适用;
在 Mapping 中通过 dynamic 设置 是否自动新增字段,接收以下参数:
- true —— 自动新增;
- false —— 忽略新字段;
- strict —— 严格模式,发现新字段 抛出异常;
1 | PUT sinablog/user/1?routing=user123 |
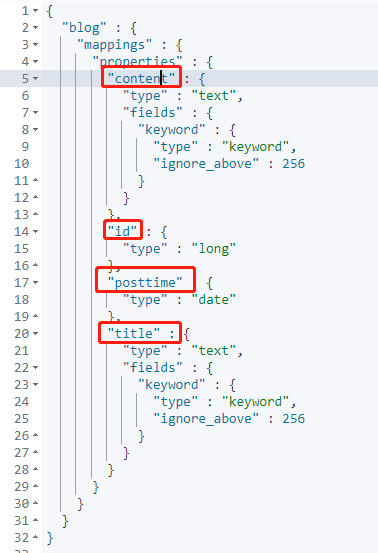
自定义Mapping:
1 | PUT tblog |
写数据:
Elasticsearch 6.0的时候默认一个 index 只能有一个type,7.0的时候已经有移除type的趋势,默认用_doc代替表示默认type;
参考文档:《Elasticsearch 移除 type 之后的新姿势》

1 | POST tblog/_doc/1 |
查询 Mapping:GET tblog/_mapping
查询:GET tblog/_search
删除:DELETE tblog
5.3.3、日期检测
Elasticsearch碰到一个新的字符串类型的字段时,会检查是否是一个日期;
一旦检测为是,以后,如果写入的字段不是type,就会报错;
预先设置不自动检测日期,可避免:
1 | PUT blog |
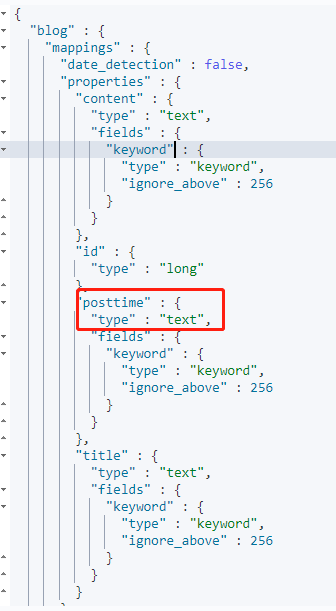
GET blog/article/2
GET blog/_mapping
GET blog/_search
DELETE blog
5.3.4、静态映射
定义:创建索引时,手动指定索引映射;
5.3.5、字段类型

文本:
string:在 5.X 之后不再支持;
text: 可以被全文检索的的,字段会被分拆,分词、生成倒排索引,不会用于 排序,基本不用于聚合;
keyword: 只能用于精确搜索,用于排序、聚合
数字:
对于 float、half_float、scaled_float,-0.0 和 +0.0 是不同的值;
es 底层会把 scaled_float 作为整形存储,节省空间,可以优先使用;
日期 date:
格式化的字符串,如 ‘2015-01-02’, ‘2015/01/02 12:10:31’;
代表epoch到今天的秒数的一个长整数,epoch 指 1970-01-01 00:00:00 UTC
二进制binary:接收base64编码的字符串,默认不存储(store=false),也不可搜索
数组**array**:es默认任何字段都可以包含一个或多个值,array的值 默认一个数组的值必须是统一类型;
object:
nested:object的一个特例,可以让数组独立索引和哈希
地理坐标 geo_point:存储 经纬度坐标点, 或 地理坐标的hash值;
- 可用来查找点周围的区域;
- 根据到点的距离排序;
地理图形 geo_shape:存储一块区域,矩形,三角形,或者 其他多边形,GeoJson;
ip:存储 ipv4 或者 ipv6;
range:常用于 时间选择表单 和 年龄范围选择表单:
integer_range
float_range
long_range
double_range:
date_range:64bit整数,毫秒计时;
1 | PUT range_inde |
令牌计数类型 token_count:用于统计字符串分词后的 词项个数。
1 | PUT my_index |
5.3.6、元字段
定义:映射中,描述文档本身的字段
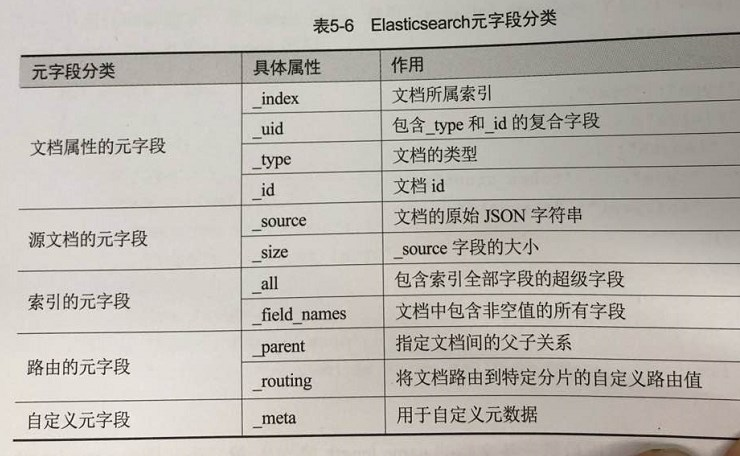
分类:
描述文档属性;
源文档的元字段;
索引的元字段;
路由的元字段;
5.3.7、映射参数
analyzer:指定文本字段的分词器,对索引和查询都有效;
search_analyzer:索引 和 搜索 都应该指定相同的分词器;但有时候就 需要指定不一样的,
默认 查询 会使用 analyzer指定的分词器,但也可以被 search_analyzer 指定 搜索分词器;
1 | PUT analyzer_index |

normalizer:用于解析前的标准配置, 比如把所有字符串转化为小写
1 | DELETE my_index |
boost:设置字段的权重,比如 设置关键字 在 title的权重是 content的2倍;
DELETE my_index
mapping指定(不重新索引文档,权重无法更改):
1 | PUT my_index |
查询时指定(推荐):
1 | PUT my_index/_doc/1 |
corece:用于清除脏数据,默认值 true;
copy_to:用于自定义 _all 字段,可以把 多个字段 复制合并成一个超级字段;
doc_values:为了加快排序、聚合操作,建立 倒排索引的时候,额外增加一个列式存储映射,是一种空间换时间的做法
- 默认是开启的,如果确定不需要聚合或排序,可以关闭 以节省空间;
- 注:text 类型 不支持 doc_values;
1 | DELETE my_index |
enabled:es会默认索引搜有字段,而有些字段只需存储,不需要查询、聚合,设置mapping时,enabled设置为false的字段,es就会跳过字段内容,只能从_source中获取,不能被搜索;也能禁用映射;
fielddata:
搜索解决的问题:包含查询关键词的文档哪些;
聚合要解决的:文档包含哪些词项;
fielddata 默认是关闭的,开启非常耗内存;
format:用于指定 date的格式;
ignore_above:用于指定字段分词和索引的字符串最大长度;超多最大值会被忽略,只能用于keyword 类型;
ignore_malformed:忽略不规则数据,设为true,异常会被忽略,出异常的字段不会被索引,其他字段正常索引;
index_options:控制哪些信息存储到 倒排索引中;
fields:让同一字段有多种不同的索引方式;
position_increment_gap:支持近似 或者 短语查询;
properties:
similarty:用于指定 文档评分模型;参数:BM25,classic(TF/IDF评分),boolean 布尔评分模型;
store:字段默认是被索引的,也可以搜索,但不存储。store可以指定 存储某个字段;
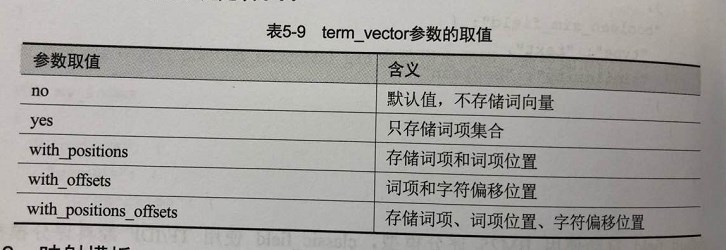
term_vector:词向量,包含文本别解析以后的信息:词项集合、词项位置、词项起始字符映射到原始文档的位置;
5.3.8、映射模板
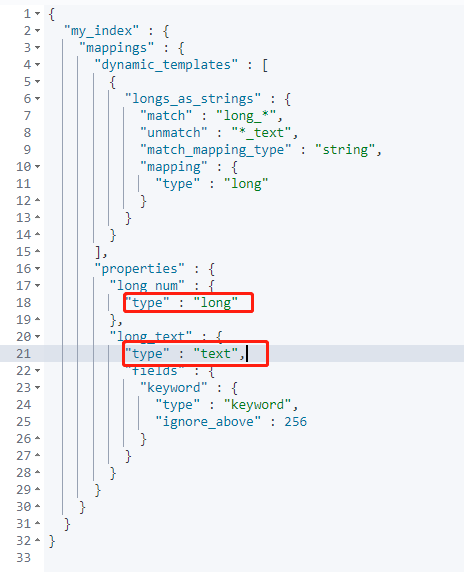
举例:如果字段已 long_ 开头,则将字符串转化为 long 类型;
1 | DELETE my_index |