1、什么是消息中间件
消息队列中间件 (Message Queue Middleware,简称为 MQ) 是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可以在分布式环境下扩展进程间的通信。提供了以松散藕合的灵活方式集成应用程序的一种机制。它们提供了基于存储和转发的应用程序之间的异步数据发送,即应用程序彼此不直接通信,而是与作为中介的消息中间件通信。消息中间件提供了有保证的消息发送,应用程序开发人员无须了解远程过程调用 ( RPC) 和网络通信协议的细节。

2、消息中间件的作用
- 异步(解决不必要的阻塞):消息中间件提供了异步处理机制,允许应用把一些消息放入消息中间件中,但并不立即处理它,在之后需要的时候再慢慢处理 。
- 解耦(降低模块间的耦合关系):消息中间件在处理过程中间插入了一个隐含的、基于数据的接口层。
- 削峰(峰值任务的平滑处理):在访问量剧增的情况下,应用仍然需要继续发挥作用。
- 冗余(存储、补偿机制):有些情况下,处理数据的过程会失败。消息中间件可以把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。
- 顺序保证:数据的处理顺序
3、AMQP协议
AMQP协议是一套开放标准,支持不同语言的不同产品。
AMQP组件
生产者:消息的创建者,将消息发送到消息中间件
消费者:连接到消息中间件上,订阅在队列上,进行消息的消费。
消息:包括有效载荷与标签。有效载荷:要传输的数据;标签:描述有效载荷的属性;RabbitMQ通过标签决定谁获得该消息,消费者只能得到有效载荷。
信道:可理解为一个虚拟的连接,建立在真实的TCP/IP连接之上。所有AMQP上的消息都通过信道传输,TCP/IP连接的建立和释放 对服务器有很大的消耗、昂贵的资源。信道的创建没有数量限制,保护资源的利用。
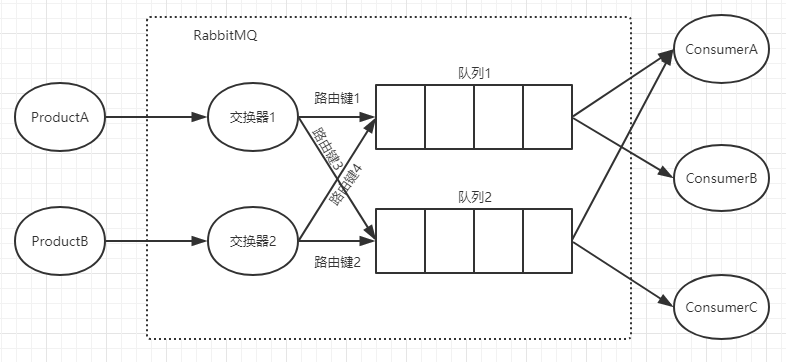
交换器、队列、绑定、路由键:队列通过路由键(routing key)绑定到交换器,生产者把消息发送到交换器,交换器根据绑定的路由键把消息路由到特定的队列中,再由订阅该队列的消费者进行消息的消费。
5、客户端开发
5.1、连接rabbitmq
connection
channel
1 | connection = new AMQPStreamConnection(Yii::$app->params['AMQP']['host'],Yii::$app->params['AMQP']['port'], Yii::$app->params['AMQP']['user'],Yii::$app->params['AMQP']['password']); |
5.2、声明exchange和queue
1 |
|
举例
1 | $channel->exchange_declare(self::FXC_EXCHANGE, 'direct', false, true, false); |
5.3、发送消息
1 | public function basic_publish( |
5.4、消费消息
1)推模式
broker向消费者持续不断的推消息
1 | public function basic_consume( |
2)拉模式
消费者一条条从broker拉取消息
1 | public function basic_get($queue = '', $no_ack = false, $ticket = null) |
举例
1 | while (true) { |
3) 幂等性
1 | f(x) = f(f(x)) |
5.5、消费端的确认与拒绝
确认消息已消费
1 | public function basic_ack($delivery_tag, $multiple = false){} |
拒绝消息
1 | // 拒绝单条信息 |
5.6、关闭连接
1 | channel->close(); |
6、rabbitmq使用进阶
6.1、消息何去何从
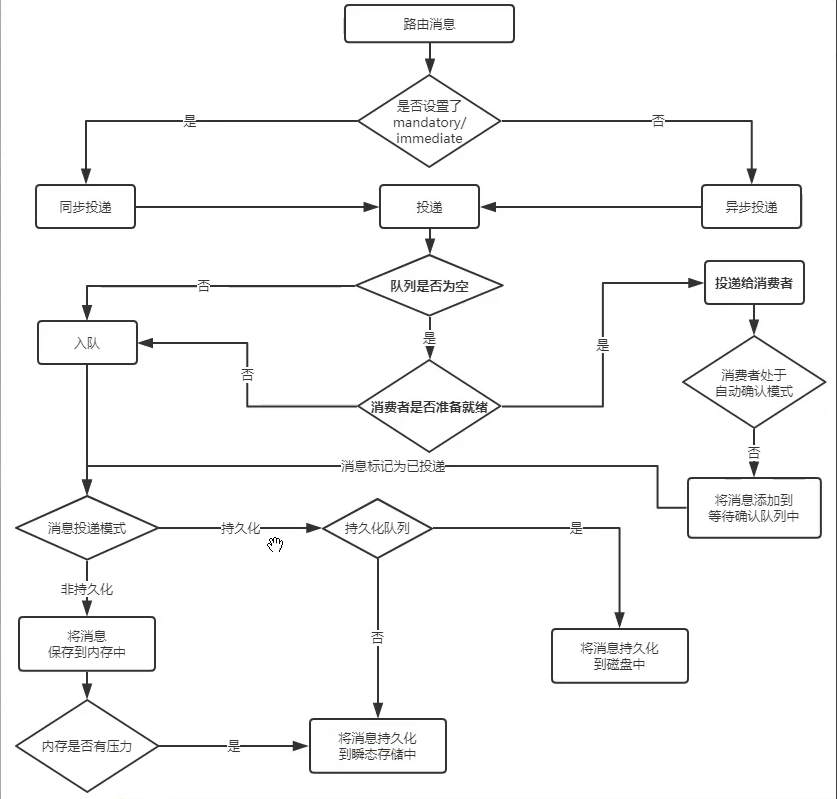
只有交换器没有绑定队列的消息会发送到哪?
1)mandatory
交换器无法根据 exchange和路由键找到对应的队列时,$mandatory 为 true,则会basic.return给生产者;如果为false,则直接丢弃
2)immediate
true-如果消息路由到队列以后,发现队列上没有任何消费者则返回给生产者,有消费者则立刻投递给消费者
6.2、过期时间TTL
1)设置消息的TTL
1 | x-message-ttl 6000 |
2)设置队列的TTL
1 | x-expires 180000 |
当队列上没有任何消费者,且过期时间内没有调用basic.get 则会被删除
如果broker重启了,持久化的队列的过期时间会被重新计算
6.3、死信队列
1 | x-dead-letter-exchange |
6.4、延迟队列
rabbitmq本身并没有实现延迟队列,不过可以用 TTL + 死信队列 达到延迟队列的效果
6.5、优先级队列
1 | 1. 将队列设置成优先级队列 |
6.6、RPC实现
文档:https://www.rabbitmq.com/tutorials/tutorial-six-python.html
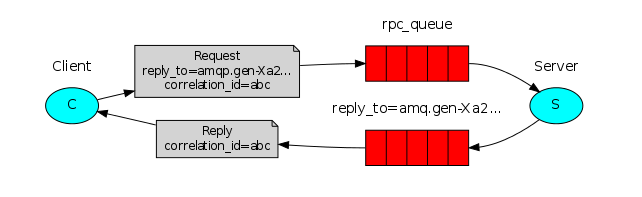
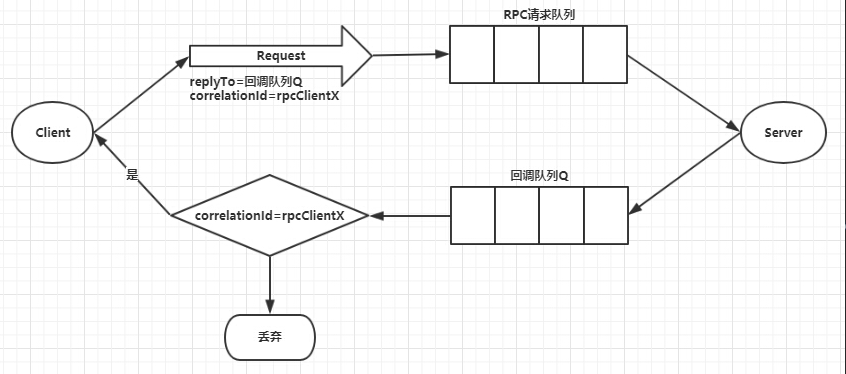
RPC处理流程如下:
- 客户端启动时,创建一个匿名回调队列(由rabbitmq自动创建);
- 客户端为RPC请求设置2个属性:replyTo用来告知RPC服务端回复请求时的目的队列,即回调队列;correlationId 用来标记一个请求;
- 请求被发送到 rpc_queue队列中;
- RPC 服务端 监听 rpc_queue 队列中的请求,当请求到来时,服务端会处理并且把带有结果的消息发送给客户端。接收的队列就是 replyTo设定的回调队列;
- 客户端监听回调队列,当有消息时,检查correlationId属性,如果与请求匹配,那就是结果了;
RPCClient.java
1 | import com.rabbitmq.client.AMQP; |
RPCServer.java
1 | import com.rabbitmq.client.*; |
6.7、持久化
- 交换器持久化
- 队列持久化
- 消息持久化
只有 queue 和 msg 都持久化,broker重启之后才会存在;
queue不持久化,msg持久化,broker重启之后消息也会丢失;
- 重要的消息要考虑持久化,但持久化会严重影响rabbitmq的性能。在 可靠性和吞吐量之间要做取舍;
- 持久化并不能保证消息不会丢失。还可以考虑镜像队列、发送方确认、事务机制
6.8、生产者确认
生产者将消息发送出去以后,消息是否到达了 broker呢?
1)事务机制
1 | try { |
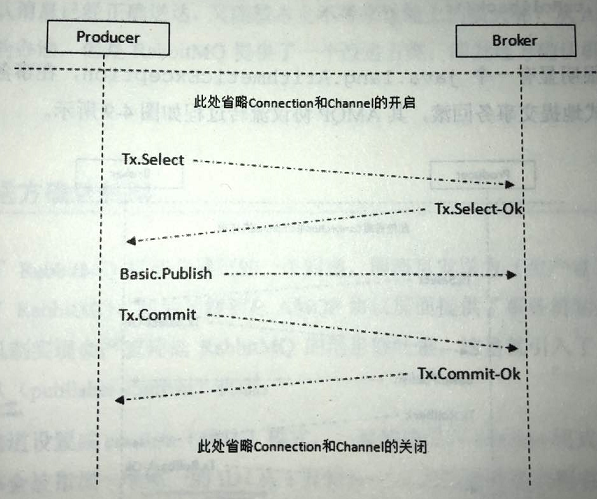
不足:事务机制会吸干rabbitmq的性能。所以有些场景考虑用发送方确认机制来达到相同的目的
2)发送方确认机制
生产者将新到设置为confirm模式,一旦进入confirm模式,所有在该信到上发布的消息都会被指派一个唯一ID,一旦消息被投递到匹配的队列,rabbitmq就会发送一个确认(basic.Ack)给生产者(包含唯一ID);
如果消息和队列是持久化的,则会在消息写入磁盘后发出。
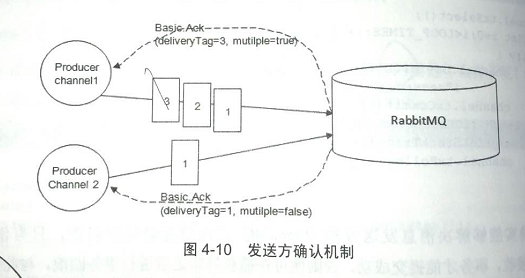
对比
- 事务机制在一条消息发送之后使发送端阻塞,以等待rabbitmq的回应,之后才能发送下一条消息;
- 发送方确认最大的好处是它是异步的
同步确认
1 | try { |
批量确认
1 | try { |
异步确认
1 | channel.confirmSelect(); |
6.9、消费端要点确认
1)消息分发
默认清空下,通过轮询将消息发送给每个消费者,但如果有些消费者负载已经满了,另一些消费者空闲,就会造成整体吞吐量下降。
可以通过 channel.basicQos(n) 设置信道上最大未确认消息数量,如果未确认消息数量已达到n,则不会再向这个消费者发送消息;
注意:channel.BasicQos 对 拉模式无效
1 | channel.basicQos(int perfetchCount); |
- perfetchCount:预取个数,0表示无限;大于0,则信道跟队列需要协调发送的消息没有超过限定的值;
- prefetchSize:未确认消息个数,0表示无限;大于0,则需要协调
| global参数 | AMQP 0-9-1 | rabbitmq |
|---|---|---|
| false | 信道上所有消费者都要遵循 prefetchCount 限制 | 信道上新的消费者需要遵循prefetchCount限定 |
| true | 当前链路(Connection)上所有消费者都要遵循 | 信道上所有消费者都要遵循 prefetchCount 限制 |
2)消息顺序性
在只有一个生产者一个消费者的情况下,且不使用任何rabbitmq的高级特性的情况下,消息是有序的。否则需要自己保证消息有序
3)弃用QueueingConsumer
- 有内存溢出问题
- 会拖累一个connection下的所有信道
- 同步递归调用会产生死锁
- 不是时间驱动的
6.10、消息传输保障
- At most once:最多一次
- At least once:至少一次
- Exactly once:恰好一次
7、rabbitmq核心设计
7.1、存储机制
1 | bash-5.0# pwd |
1)队列的结构
rabbitmq 中的消息可能处于一下4中状态:
- alpha:消息内容、索引都存在内存中;
- beta:消息内容保存在磁盘中,索引保存在内存中;
- gamma:消息内容保存在磁盘中,消息索引保存在磁盘和内存中;
- delta:消息内容和索引都在磁盘中;
这4种状态的主要作用是满足不同的内存和CPI需求。 alpha最耗内存,最少耗cpu;delta基本不耗内存,却最耗cpu和I/O;

- Q1 和 Q4 只包含 alpha 状态的消息
- Q2 和 Q3 包含 beta 和 gamma 状态的消息
- Delta 只包含 delta 状态的消息
2)惰性队列
惰性队列会尽可能的 将消息存入磁盘,减少内存的小号,增加 I/O 的使用
队列具备两种模式:default 和 lazy
1 | x-queue-mode lazy |
7.2、内存和磁盘告警
1)内存告警
Connection 处于 blocking 或 blocked 状态下
可以通过 rabbitmq.conf 来设置
1 | vm_memory_high_watermark |
因为erlang虚拟机的垃圾回收可能占用 2被的内存,所以 vm_memory_high_watermark 一般不超过 70%, 取值范围为 [0.4, 0.66]
vm_memory_high_watermark_paging_ratio 表示 当 vm_memory_high_watermark 范围内的内存占用超过 vm_memory_high_watermark_paging_ratio时,就会从内存swap到磁盘上
2)磁盘告警
默认情况下,当系统磁盘占用只剩 50MB时,就会报警。但50MB可能不够用,一个谨慎的做法是 设置为和操作系统的内存一样大
1 | 建议范围 1.0 ~ 2.0 之间 |
rabbitmq 每 10s 会进行一次检测
7.3、流控
1)流控的原理
信用证算法(credit-based algorithm):当消息堆积到一定程度时,就会阻塞 接收上游新消息
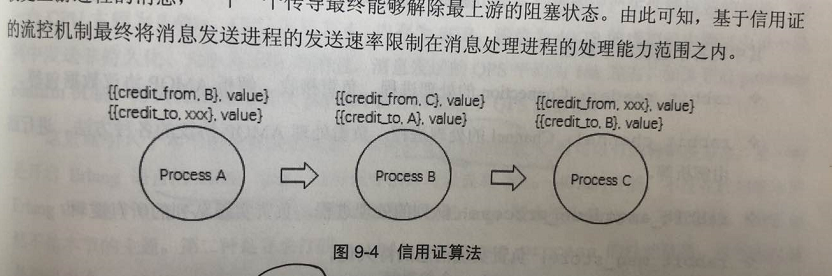
当 connection 、channel、queue 处于 flow 状态时,表示触发了限流,在 blocked 和 unblock 之间切换
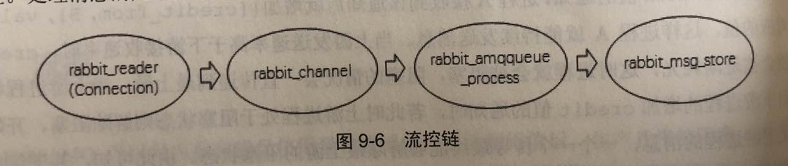
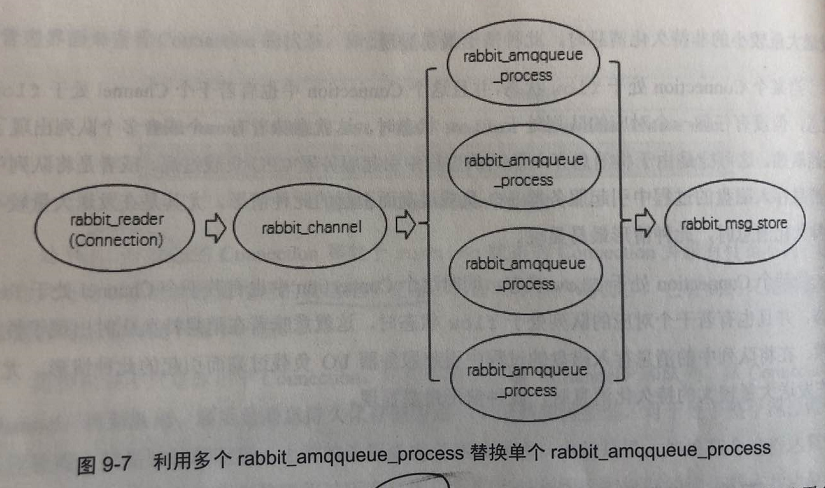
- rabbit_reader:connection 的 处理进程,负责接收、解析 AMQP 协议数据包;
- rabbit_channel: channel 处理进程,负责处理 AMQP 协议的各种方法,进而进行路由解析;
- rabbit_amqqueue_process:队列的处理进程,负责实现队列的所有逻辑;
- rabbit_msg_store:负责实现消息的持久化;
2)打破队列的瓶颈
向一个队列中推送消息时,往往会在 rabbit_amqqueue_process 中 产生瓶颈。
提升性能方案:
- 使用HiPE功能,保守估计可以提升 30%~40% 的 性能(不过erlang的版本至少为 18.X)
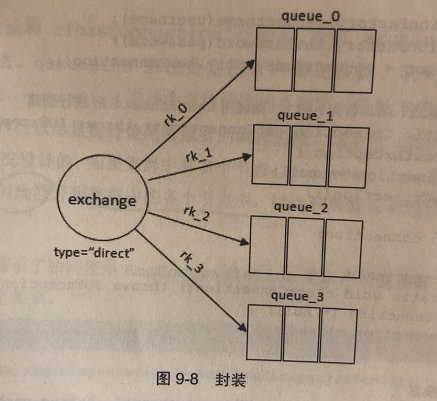
- 使用多个rabbit_amqqueue_process, 负载均衡的方案(创建多个队列,不同的队列绑定不同的路由键)