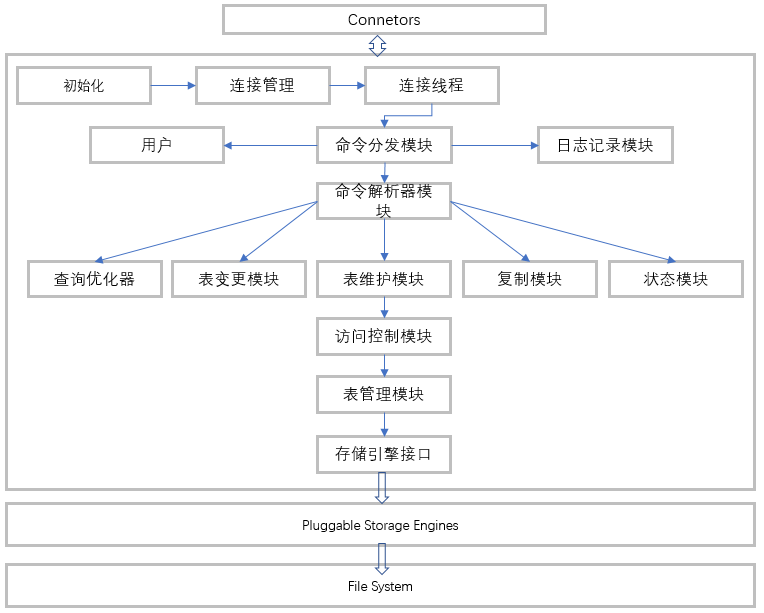
一、MySQL逻辑架构

二、MySQL基本架构
对于MySQL来说,虽然经历了多个版本迭代(MySQL5.5,MySQL 5.6,MySQL 5.7,MySQL 8),但每次的迭代,都是基于MySQL基架的,MySQL基架大致包括如下几大模块组件:
1、MySQL向外提供的交互接口(Connectors)
Connectors组件,是MySQL向外提供的交互组件,如java,.net,php等语言可以通过该组件来操作SQL语句,实现与SQL的交互。
2、管理服务组件和工具组件(Management Service & Utilities)
提供对MySQL的集成管理,如备份(Backup),恢复(Recovery),安全管理(Security)等
3、连接池组件(Connection Pool)
负责监听对客户端向MySQL Server端的各种请求,接收请求,转发请求到目标模块。每个成功连接MySQL Server的客户请求都会被创建或分配一个线程,该线程负责客户端与MySQL Server端的通信,接收客户端发送的命令,传递服务端的结果信息等。
4、SQL接口组件(SQL Interface)
接收用户SQL命令,如DML,DDL和存储过程等,并将最终结果返回给用户。
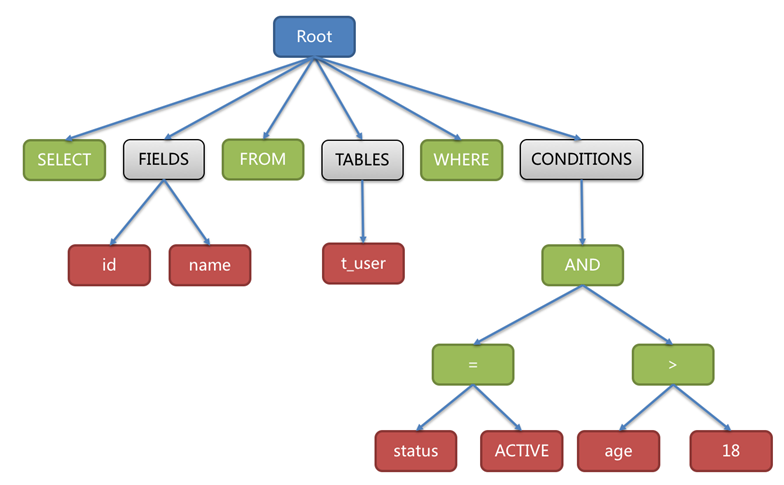
5、查询分析器组件(Parser)
首先分析SQL命令语法的合法性,并尝试将SQL命令解析成抽象语法树,若解析失败,则提示SQL语句不合理
1 | SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18 |
6、优化器组件(Optimizer)
对SQL命令按照标准流程进行优化分析。
1 | explain select c_user.*, t.cust_id, ifnull(tcc.tradeamt, 0) tradeamt, ifnull(tcc.commission,0) commission, ifnull(ih.is_hadtrade, 0) is_hadtrade |

7、缓存主件(Caches & Buffers)
缓存和缓冲组件
8、插件式存储引擎(Pluggable Storage Engines)
9、物理文件(File System)

三、InnoDB存储引擎
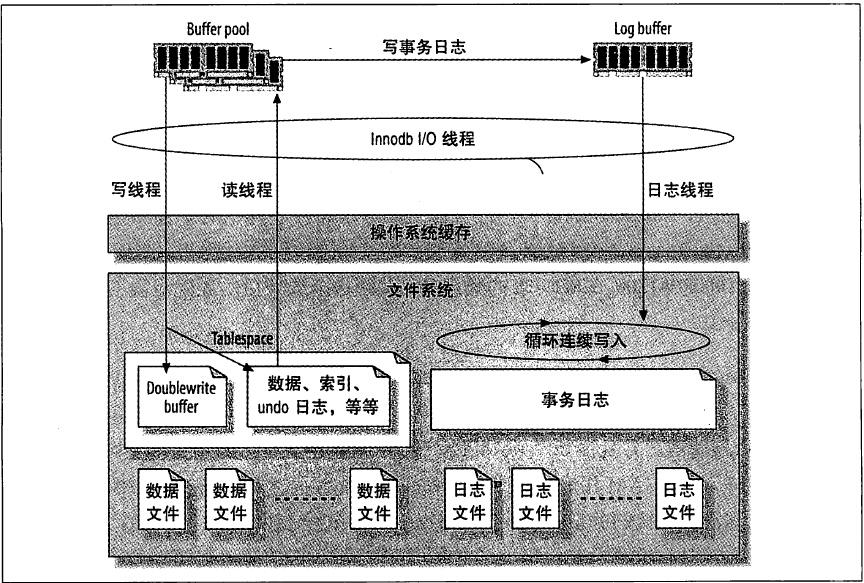
1)、 当事务要修改一条记录时,Innodb需要将该记录从Disk中读到BP(Buffer Pool)中。当事务提交后(commit),BP当中的page的记录被修改,这时BP中page就和Disk中的page不一致了,所以这时候BP中的page就是Dirty Page, 需要等待刷新到Disk中;
2)、假如在BP的Dirty Pages刷新到Disk前,系统断电了那么Dirty Page中的数据修改是不是就全部丢失了呢?答案是不会的,这就是Redo Log(innodb_flush_log_at_trx_commit=1)要做的事情了。在事务提交时候,事务中的更新操作会立即保存到Redo Log. 所以就算BP中的Dirty Page在断电后全部丢失,MySQL在重启时,仍可以根据Redo Log来恢复数据;
3)、好了,现在想象一下,假如Dirty Page在flush到disk的过程中发生断电,导致部分数据丢失,Redo Log还能不能恢复这部分数据。答案是不行的,因为mysql在恢复的时候是根据page的checksum来决定这个page是否需要恢复,而这个checksum就是这个page最后一个事务的事务号。这就是partial write的问题,这时候就需要double write了;
partial write是指mysql在将数据写到数据文件的时候, 会出现只写了一半但由于某种原因剩下的数据没有写到innodb file上. 出现这种问题可能是由于系统断电, mysql crash造成的, 而造成这个问题更根本的原因是由于mysql 的page size跟系统文件的page size不一致, 导致在写数据的时候, 系统并不是把整个buffer pool page一次性写到disk上,所以当写到一半时, 系统断电,partial write也就产生了; 如果partial write产生, 会发生什么问题呢? 因为我们知道在flush buffer cache的时候,其实redo log已经写好了. 为什么还需要担心partial write呢? 这是因为mysql在恢复的时候是通过检查page的checksum来决定这个page是否需要恢复的, checksum就是当前这个page最后一个事务的事务号; 如果系统找不到checksum, mysql也就无法对这行数据执行写入操作;
4)、double write的作用就是在mysql将数据刷新到硬盘的时候,先将数据写到double write的空间,然后再某个时刻再把数据写到Disk中。
InnoDB架构
下图显示了组成InnoDB存储引擎架构的内存和磁盘结构。
有关每个结构的信息,请参阅第15.5节“InnoDB内存结构”和第15.6节“InnoDB磁盘结构”。
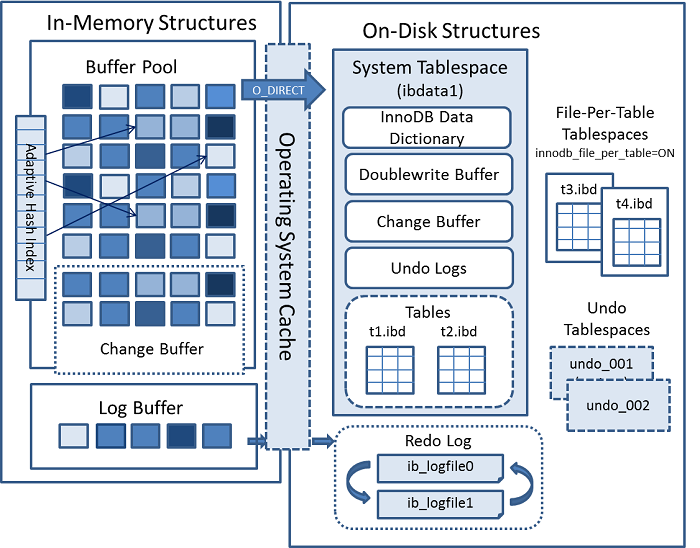
InnoDB内存结构
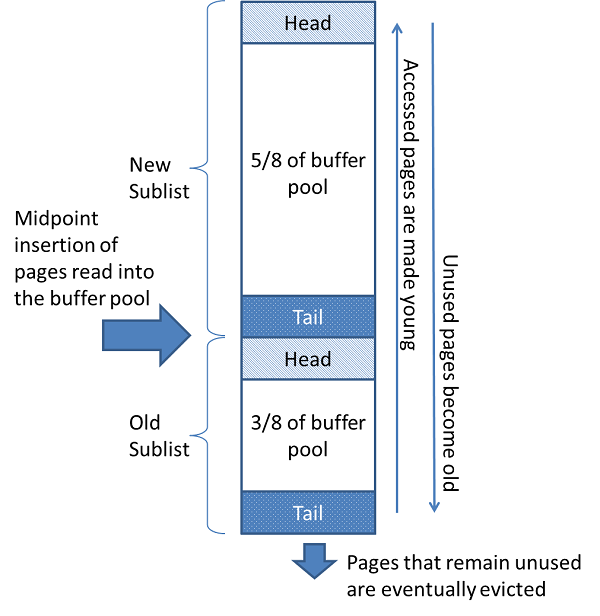
缓冲池(buffer pool)
1)、innodb_buffer_pool缓冲池提高数据库整体性能。
2)、innodb读取页操作时,先将从磁盘读到的页放在缓冲池中,下次再次读取,先判断是否缓存命中,若否,则读磁盘中的页
3)、事务提交后,InnoDB首先在buffer pool中找到对应的页,把事务更新到 buffer poll 中.
当刷新脏页到磁盘时,缓冲区都干了什么? 缓冲区把脏页拷贝到doublewrite buffer,doublewirte buffer把脏页刷新到double write磁盘(这也是一次顺序IO),再把脏页刷新到数据文件中。当然buffer pool中还有其他组件,也非常重要,如插入缓冲(change buffer),该缓冲区是为了高效维护二级非唯一索引所做的优化,把多次IO转化为一次IO来达到快速更新的目的
4)、mysql crash时,buffer pool中的数据都会丢失。
innodb数据文件中,会存储
checkpoint信息,redo log中也存储checkpoint信息。InnoDB会对比数据文件ibd和redo log中的checkpoint信息,找出最后一次checkpoint对应的log sequence number,通过redo log的变更记录重新应用到数据库
更改缓冲区(change buffer)
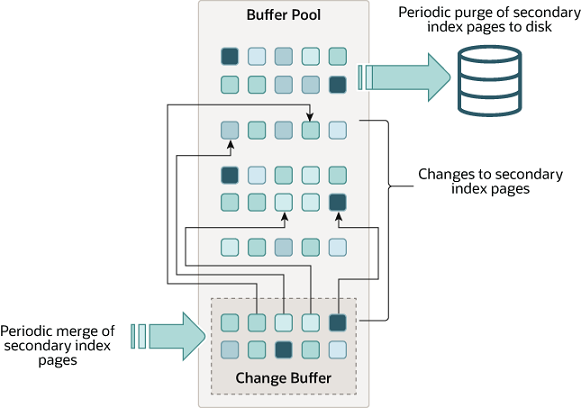
原来就是insert buffer,后来随着update和delete缓冲加入改为change buffer。
缓存对二级索引的变更。二级索引通常是非唯一的,并且二级索引中的插入以相对随机的顺序发生。


log buffer
1、概念
1)、InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理
bp(
buffer pool):InnoDB数据库page的缓存。page:
对InnoDB中数据的任何修改,首先在bp的page上进行。修改后的page标记为dirty page。flush list:
存放dirty page,后续由专门的thread写入磁盘中。2)、使用bp的好处:
避免每次对page的修改都进行IO操作,将多次对页面的修改合并成一次IO操作。
- 引入问题:
会造成数据的不一致性,RAM和Disk中数据不一致。- 解决(
数据不一致性):使用redo log,将所有对page进行的修改操作,都写入一个专门的文件中数据库启动时,会从中恢复。- redo log的影响:
延迟了bp中page刷新到磁盘,提高了数据库的吞吐量。 额外的redo log顺序IO的写入开销,以及数据库启动时使用redo log恢复所需时间。2、redo log相关参数
show variables like “%innodb_log%”;
innodb_log_file_size 指定redo log日志文件大小,默认48M
innodb_log_files_in_group redo log日志文件组中文件的数量,默认2个,ib_logfile0和ib_logfile1
innodb_log_buffer_size redo log buffer的大小,默认为16M
日志组中的文件大小是一致的,以循环的方式运行。ib_logfile0写满时,切换到ib_logfile1,ib_logfile1写满时,再次切换到ib_logfile0。
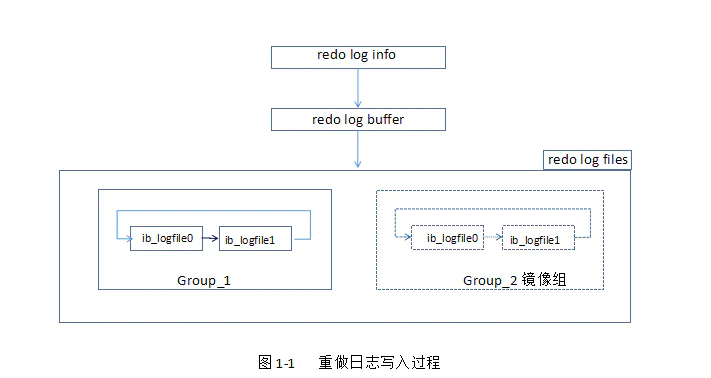
3、redo log写入过程
1)、
redo log buffer 向 redo log file 写,是按512个字节,也就是一个扇区的大小进行写入。扇区是写入的最小单位。
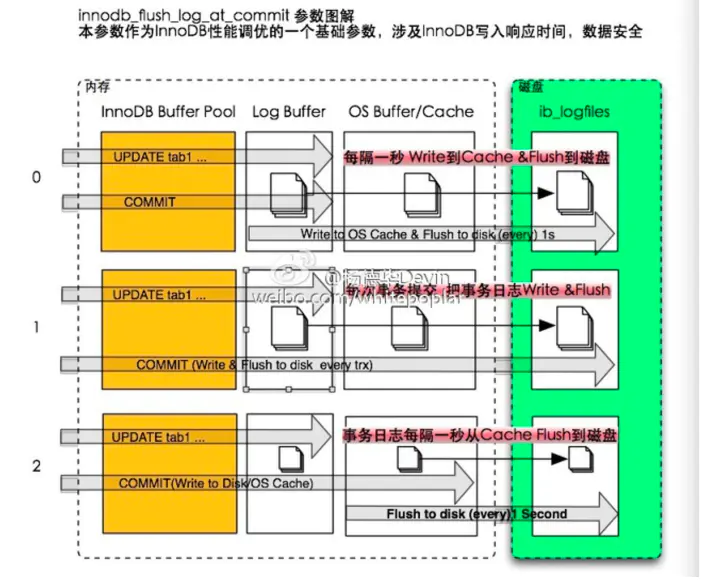
参数innodb_flush_log_at_trx_commit用来控制事务日志刷新到磁盘的策略。
2)、将redo log buffer中的内容刷新到磁盘的redo log file(
ib_logfile)中的条件。
- 保证
日志先行,每次事务commit前,都会将redo log刷新到磁盘上。redo log是一个环(ring)结构,当redo空间快占满时,将会将部分dirty pages flush到disk上,然后释放部分redo log。
4、对比binlog
5、对比undo log
1)、
Undo Log 是为了实现事务的原子性(rollback),在MySQL数据库InnoDB存储引擎中,还用Undo Log来实现多版本并发控制(简称:MVCC)。2)、Undo log是InnoDB MVCC事务特性的重要组成部分。当我们对记录做了变更操作时就会产生undo记录,Undo记录默认被记录到系统表空间(ibdata)中,但从5.6开始,也可以使用独立的Undo 表空间。
3)、Undo记录中存储的是老版本数据,当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要顺着undo链找到满足其可见性的记录。



InnoDB磁盘结构
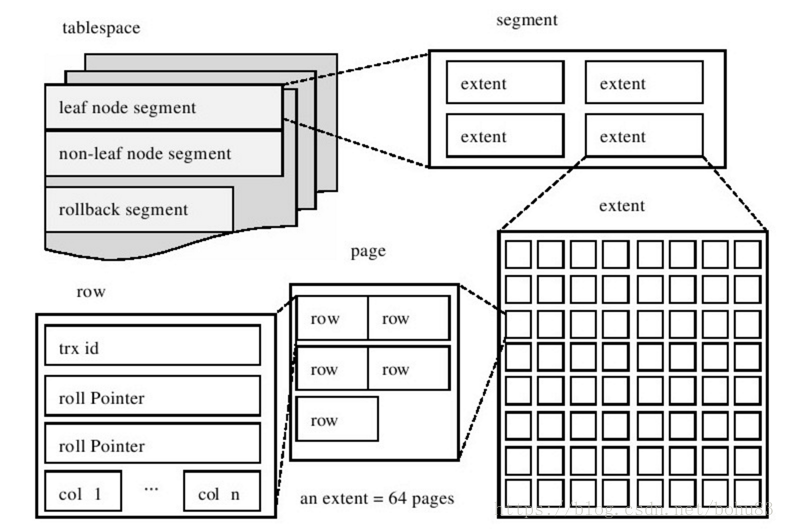
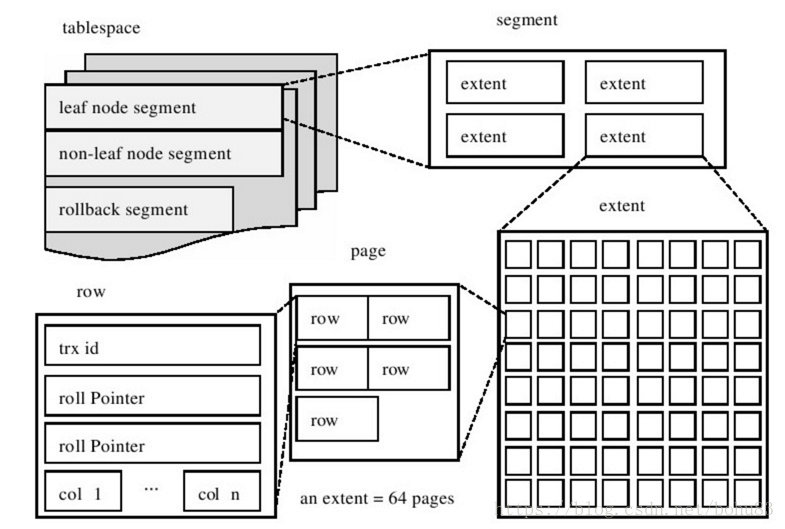
- tablespace:表空间
- segment 段:
- extent 簇:物理上连续的几个页; 1MB一个簇 = 64 * 16KB = 128 * 8KB = 256 * 4KB,一个簇包含多少Page取决于Page的大小
- page 页:16KB
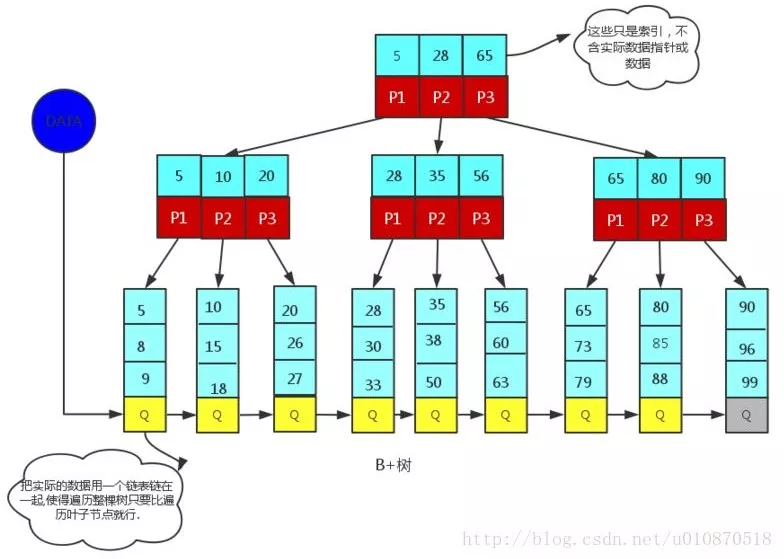
索引组织表
doublewrite buffer
doublewrite buffer 是 InnoDB 的 system tablespace 中的一个区域。在 把 buffer pool 中的内容写入对应的 data file 之前,先要把数据写入 doublewirte buffer 中;
如果 storage 或者 mysqld 在写 page的过程中 进程崩溃,InnoDB 可以在 doublewrite buffer 中找到完成的 page 的拷贝 用来恢复;
尽管数据总是写两次,但 doublewrite buffer 不需要两倍的 I/O开销 或 两倍的 I/O 操作。数据作为一个大的连续块 写入 doublwrite buffer,只需对操作系统执行一次 fsync() 调用;
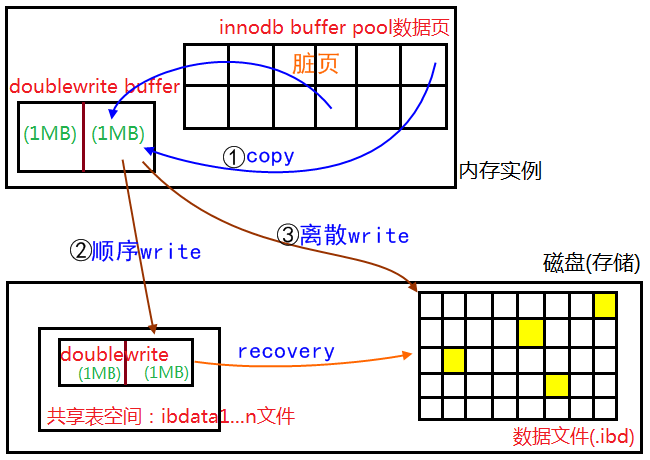
double write的缺点是什么?
虽然mysql称double write是一个buffer, 但其实它是开在物理文件上的一个buffer, 其实也就是file, 所以它会导致系统有更多的fsync操作, 而我们知道硬盘的fsync性能是很慢的, 所以它会降低mysql的整体性能. 但是并不会降低到原来的50%. 这主要是因为: 1) double write是一个连接的存储空间, 所以硬盘在写数据的时候是顺序写, 而不是随机写, 这样性能更高. 另外将数据从double write buffer写到真正的segment中的时候, 系统会自动合并连接空间刷新的方式, 每次可以刷新多个pages;
redo log
Redo Log是基于磁盘的数据结构,在崩溃恢复期间用于纠正不完整事务写入的数据。
默认情况下,Redo Log在磁盘上由两个名为ib_logfile0和的 文件物理表示ib_logfile1。MySQL以循环方式写入Redo Log文件。Redo Log中的数据按照受影响的记录进行编码;此数据统称为重做。
undo log
功能:事务回滚、MVCC
undo log是与单个读写事务关联的 undo Log 记录的集合。undo Log 记录包含如何 撤消事务对 聚簇索引 记录的最新更改 的信息。如果另一个事务读取原始数据,就需要在 undo Log记录读取。
undo log存在于 undo log segment。默认情况下,undo log segment 实际上是 system tablespace 的一部分 ,但它们也可以驻留在 undolog tablespace 中
•undo:相当于数据修改前的备份
•redo: 相当于数据修改后的备份,为了保证事务的持久化,redo会一直写
•Undo + Redo**事务的简化过程**
假设有A、B两个数据,值分别为1,2.
A.事务开始.
B.记录A=1到undo log.
C.修改A=3.
D.记录A=3到redo log.
E.记录B=2到undo log.
F.修改B=4.
G.记录B=4到redo log.
H.将redo log写入磁盘
I.事务提交完成•- Undo + Redo**事务的特点**
A. 为了保证持久性,必须在事务提交前将Redo Log持久化 —一般每个事务提交时或每秒刷盘
B. 数据不需要在事务提交前写入磁盘,而是缓存在内存中。 —data在此时不需要写磁盘,但是如果redo文件过小也会触发事务未提交前数据落盘
C. Redo Log 保证事务的持久性
D. Undo Log 保证事务的原子性。
E. 有一个隐含的特点,数据必须要晚于redo log写入持久存储。
一个查询流程图