假设有一批文档,文档格式有 DOC、DOCX、PPT、PPTX、TXT、PDF
要实现类似于百度文库的文件检索系统。
需求如下:
- 能够对文件名进行检索;
- 能够对文件内容进行检索;
- 能够下载检索到的文件;
- 能够实现关键字的高亮;
假设有一批文档,文档格式有 DOC、DOCX、PPT、PPTX、TXT、PDF
要实现类似于百度文库的文件检索系统。
需求如下:
2.7.1、问题提出
2.7.2、需求分析
2.7.3、编程实现
-———————————————-
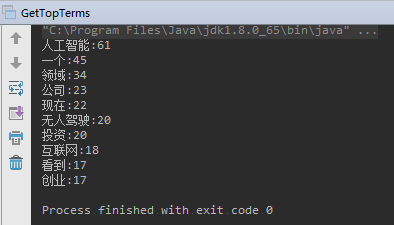
统计 一篇新闻文档,统计出现频率最高的哪些词语
文本关键词提取算法、开源工具很多
本文:《从Lucene索引中 提取 词项频率Top N》
词条化:从文本中 去除 标点、停用词等;
索引过程的本质:词条化 生成 倒排索引的过程;
代码思路:IndexReader的getTermVector获取文档的某一个字段 Terms,从 terms 中获取 tf(term frequency),拿到词项的 tf 以后,放到map中 降序排序,取出 Top-N.
网上找到新闻稿《李开复:无人驾驶进入黄金时代 AI有巨大投资机会》,放在 testfile/news.txt 文件中。
对 testfile/news.txt 生成索引:
1 | package com.learn.lucene.chapter2.highfrequency; |
运行。
提取高频词:
1 | package com.learn.lucene.chapter2.highfrequency; |
找到需要高亮的片段
1 | package com.learn.lucene.chapter2.hignlight; |

2.5.1、搜索入门
2.5.2、多域搜索(MultiFieldQueryParse)
2.5.3、词项搜索(TermQuery)
2.5.4、布尔搜索(BooleanQuery)
2.5.5、范围搜索(RangeQuery)
2.5.6、前缀搜索(PrefixQuery)
2.5.7、多关键字搜索(PhraseQuery)
2.5.8、模糊搜索(FuzzyQuery)
2.5.9、通配符搜索(WildcardQuery)
-—————————————————
文档索引完成以后就能对其进行搜索;
当用户输入一个关键字,
–> 首先 对这个关键字 进行 分析和处理, 转化成后台可以理解的形式
–> 进行检索
处理关键词 <==> 构建Query对象的过程;
搜索文档 <==> 实例化 IndexSearcher 对象,使用search()方法完成;
参数:Query对象
结果:保存在 TopDocs 类型的文档集合中;
删除indexdir下的索引文件后,重新使用CreateIndex.java 生成索引
1 | package com.learn.lucene.chapter2.queries; |
运行结果:
修改后再运行:
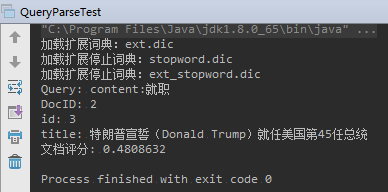
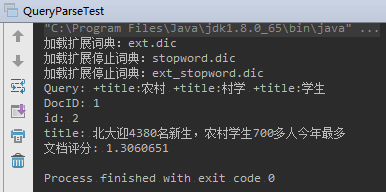
根据多个字段搜索
1 | package com.learn.lucene.chapter2.queries; |
运行结果:
TermQuery 是 最常用的 Query
TermQuery 是 Lucene中搜索的最基本单位
本质上:一个词条就是一个 key/value 对
使用TermQuery:
1 | package com.learn.lucene.chapter2.queries; |
运行结果:
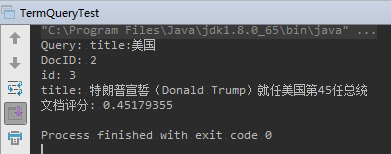
BooleanQuery 可以 组合 其他 Query,并标明他们的逻辑关系;
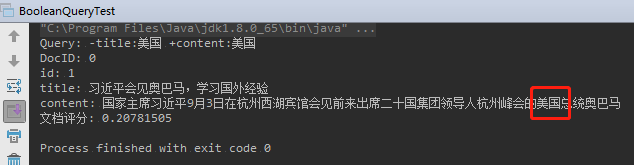
例如:查询 content 中包含美国,并且 title 不包含美国的文档;
1 | package com.learn.lucene.chapter2.queries; |
运行结果:
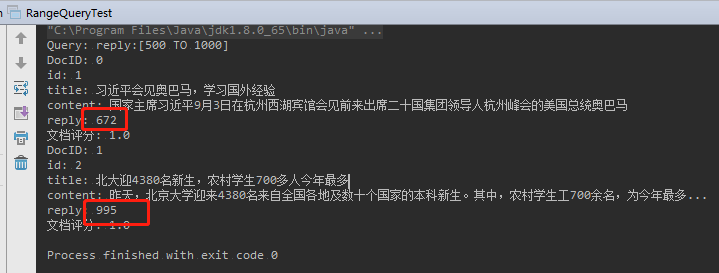
举例:查询新闻回复条数在 500~1000 之间的文档
1 | package com.learn.lucene.chapter2.queries; |
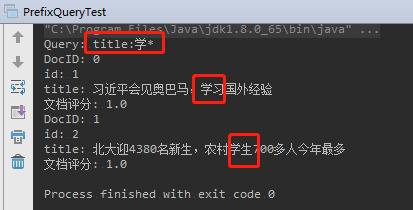
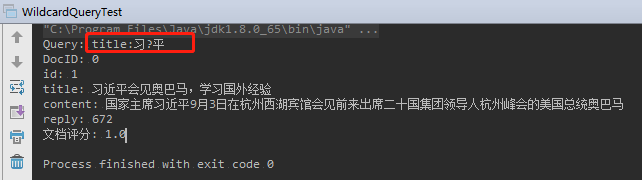
举例:搜索 包含以“学”开头的词项 的文档
1 | package com.learn.lucene.chapter2.queries; |
运行结果:
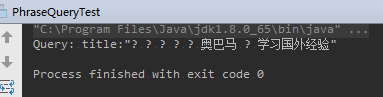
1 | package com.learn.lucene.chapter2.queries; |
运行结果(感觉没有成功):
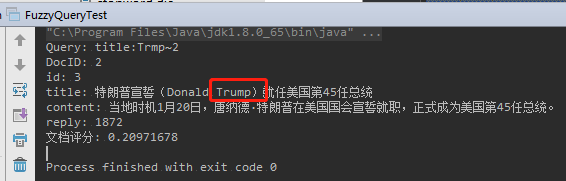
它可以简单的识别两个相近的词语。
举例:“Trump”,写成“Trmp”,拼写错误,仍然可以搜索得到正确的结果
1 | package com.learn.lucene.chapter2.queries; |
1 | package com.learn.lucene.chapter2.queries; |
时间规划:每周2小时词汇速记【每次上课30分钟即可】
学习策略:1~300词根是中高考的核心
学习顺序:
① 词根词缀完全默写:汉语意思完全掌握【结合词元理解词根】
② 总结:根据每个词根下历次进行重复的词缀统计
③ 熟记核心词:模仿老师的教学笔记,尝试通过词根词缀拆分核心词,之后根据核心词的含义和词性
④ 根据教学内容:准确划分思维导图【不需要增加汉语意思】
⑤ 读单词必须依据音标:学音标没有为什么,只有是什么
学习强度:每周至少3小时词汇速记【3节课】
学习策略:
① 思维导图务必采用软件制作
② 单词的发音务必及时掌握
③ 要在固定的英语文章当中刻意寻找刻意拆分的单词
④ 针对考研学生:所有的考研历年真题都是拆分单词的核心试题,最好通过词源网站的英文解释来加深考研词汇的印象。abbreviate 查词元 -> 拆单词:ab-brev-i-ate
考研单词很多词频都在10000~20000之间 = 400 词根
时间规划:一周零碎时间学习
模式一(特别忙):
模式二:
① 通过枚举和BBC类型的纪录片 学习词根和词缀。凡是出现再片中的词根都是高频词根
② 每周的学习频率至少保持在2~4节课
学习策略
① 强度:
如果在国外的学生,每天务必学习单词1小时
如果实在国内备战的学生:雅思托福的准备时间:3~6个月(不能再长)
单词速记要求一周之内:
②
上课听讲 - 记笔记, 下课回放 看三轮
每节作业保质量,课后作业要自觉;
分布考查要自信,分级练习要坚持;
思维导图是核心
2.4.1、Lucene 字段类型
2.4.2、索引文档示例
2.4.3、在Luke中查看索引
2.4.4、索引的删除
2.4.5 索引的更新
-———————————————–
上一节 介绍完了 Lucene 分词器,这节介绍 Lucene 是如何索引文档的。
文档:文档是 Lucene索引的基本单位;
字段:比文档更小的单位,字段是文档的一部分;
每个字段 由 3部分组成:名称(name),类型(type),取值(value);
字段的取值(value)一般为:文本、二进制、数值
Lucene的主要字段类型:
Lucene 使用 倒排索引 快速搜索 <===> 建立 词项和文档id的关系映射;
搜索过程:
通过 类似hash算法 -> 定位到 搜索关键词 -> 读取文档id集合
上述过程的缺陷:
当我们需要对数据做 聚合操作,排序、分组时,Lucene会提取所有出现在文档集合中的排序字段,再次构建一个排好序的文件集合;这个过程全部在内存中进行,如果数据量巨大,会造成 内存溢出 和 性能缓慢;
Lucene 4.X 之后出现了 DocValues,DocValues是 Lucene 构建索引时,额外建立的一个有序的基于 document => field/value 的映射列表。
代表新闻的实例类 News.java
1 | package com.learn.lucene.chapter2.index; |
创建索引文件的CreateIndex.java
1 | package com.learn.lucene.chapter2.index; |
运行结果:
生成对应的索引文件
打开索引文件目录:D:\java\oschina\lucene-learn\lucene-chapter2\indexdir
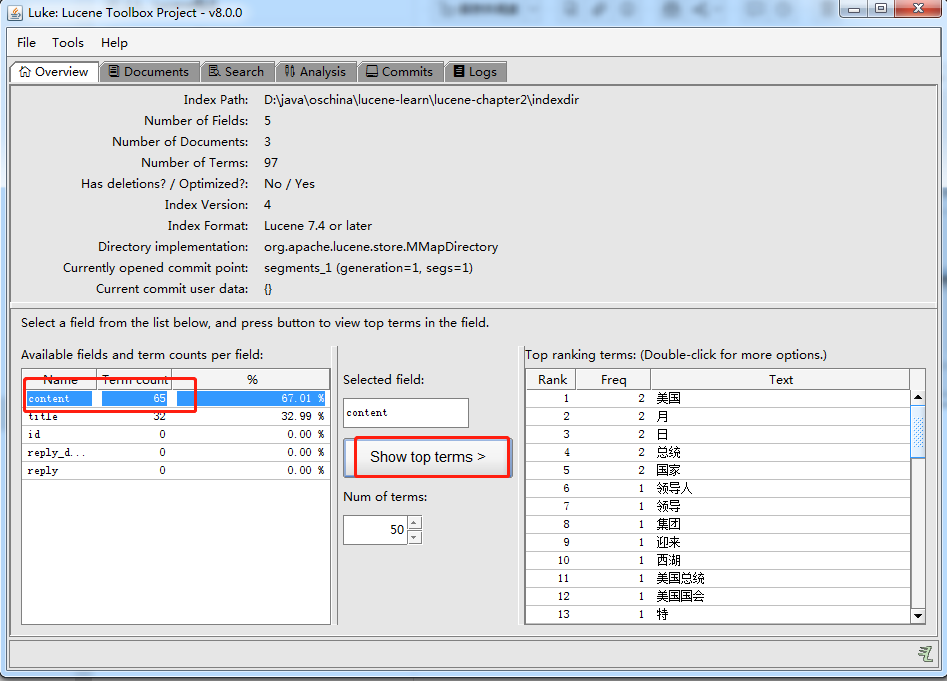
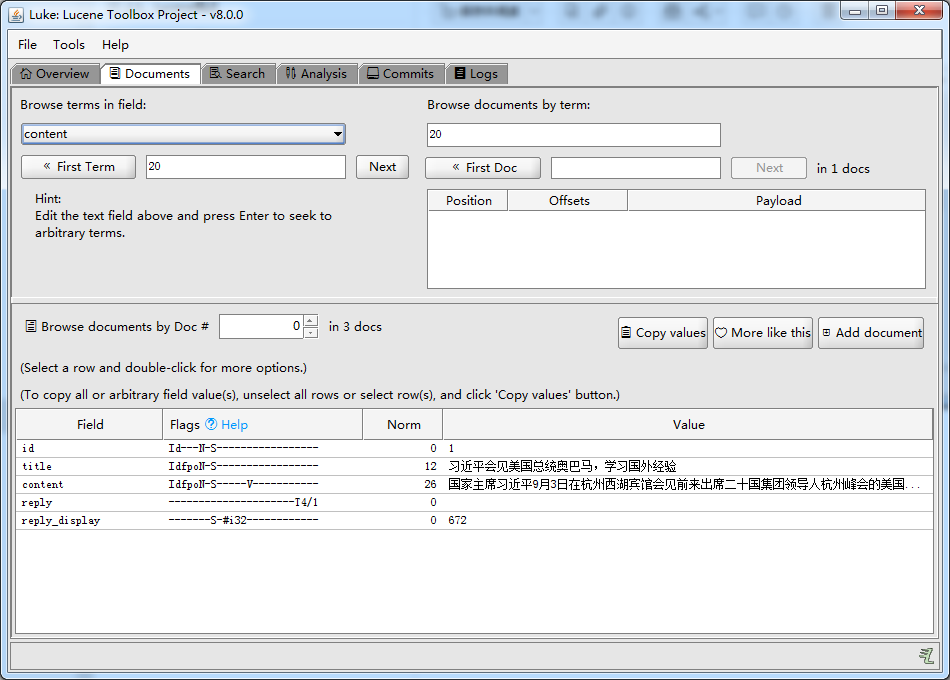
索引同样存在 CRUD 操作
本节演示 根据 Term 来删除点单个或多个Document,删除 title 中 包含关键词“美国”的文档。
1 | package com.learn.lucene.chapter2.index; |
运行结果:
除此之外,IndexWriter还提供了以下方法:
使用IndexWriter进行Document删除操作时,文档并不会立即被删除,而是把这个删除动作缓存起来,当IndexWriter.Commit() 或 IndexWriter.Close()时,删除操作才会真正执行。
使用Luke 重新打开 索引之后,只剩下了一个索引文档:
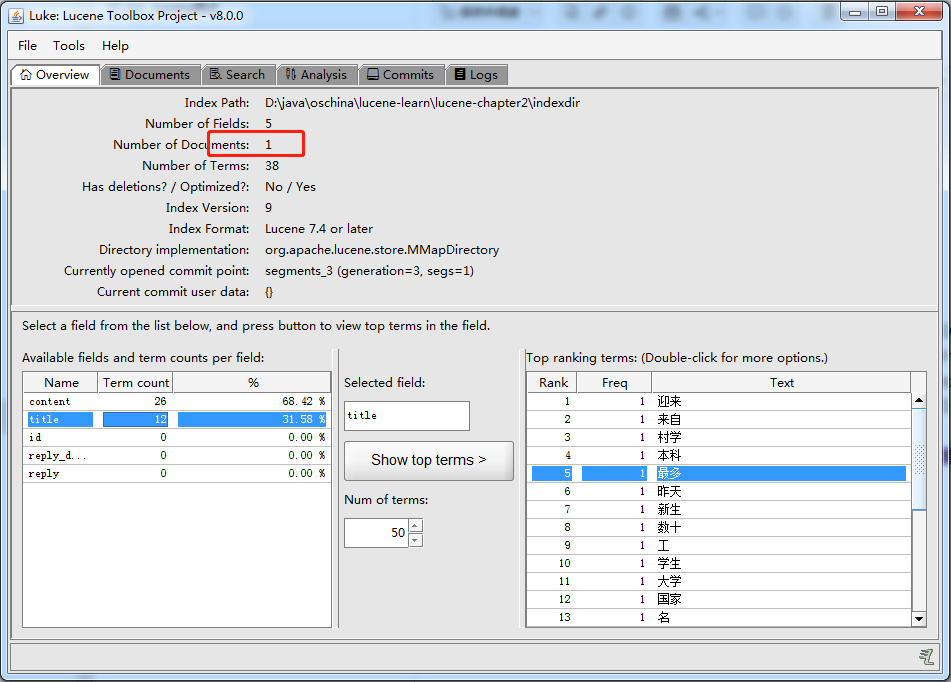
本质:先删除索引,再建立新的文档。
1 | package com.learn.lucene.chapter2.index; |
运行结果:
修改前: 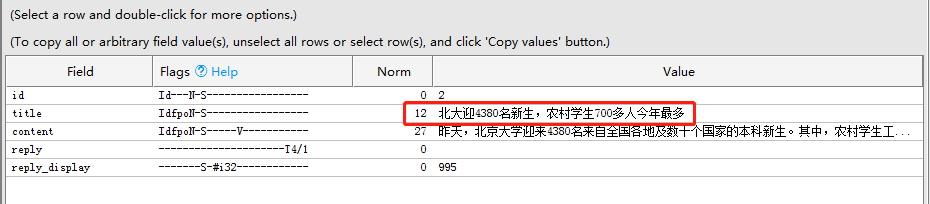
修改后: 
2.3.1、Lucene分词系统
2.3.2、分词测试
2.3.3、IK分词器配置
2.3.4、中文分词器对比
2.3.5、扩展停用词词典
2.3.6、扩展自定义词典
-——————————————————————
索引和查询 都是以 词项 为基本单位
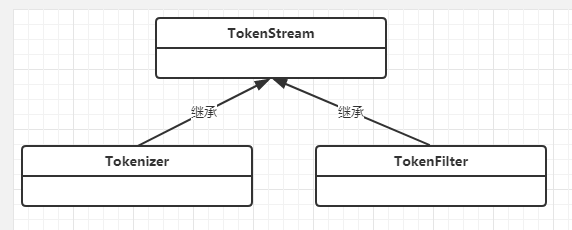
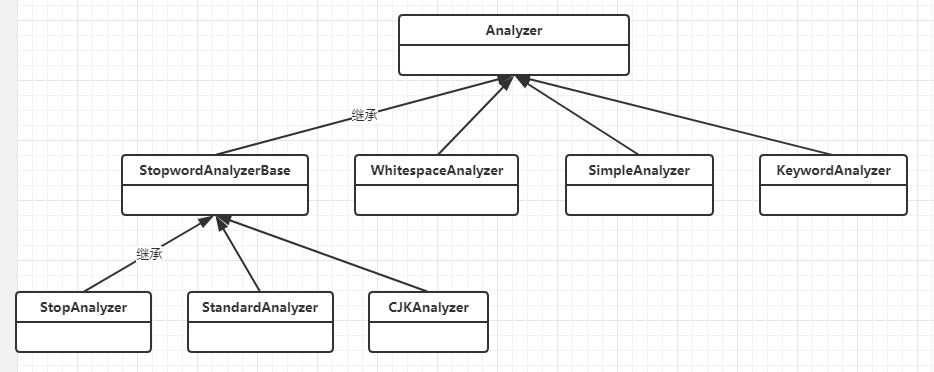
Lucene中,分词 主要依靠 Analyzer类 解析实现
Analyzer是抽象类,内部调用 TokenStream 实现
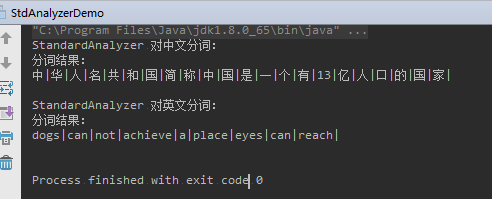
StandardAnalyzer 分词器测试:
1 | package com.learn.lucene.chapter2.analyzer; |
运行结果:
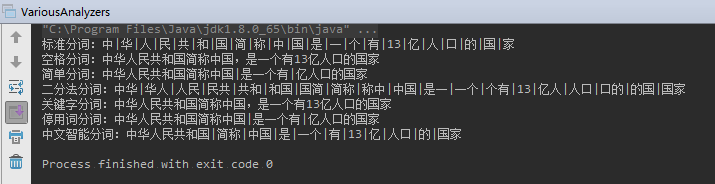
测试多种Analyzer,注意要特意指定 jdk8:
1 | package com.learn.lucene.chapter2.analyzer; |
运行结果:
Lucene 8.0 实用 IK分词器需要修改 IKTokenizer 和 IKAnalyzer
在 com.learn.lucene.chapter2.ik 下 新建 IKTokenizer8x.java 和 IKAnalyzer8x.java
1 | package com.learn.lucene.chapter2.ik; |
1 | package com.learn.lucene.chapter2.ik; |
实例化 IKAnalyzer8x 就能实用IK分词器了
1、 默认使用细粒度切分算法:
Analyzer analyzer = new IKAnalyzer8x();
2、创建智能切分算法的 IKAnalyzer:
Analyzer analyzer = new IKAnalyzer8x(true);
分词效果会直接影响文档搜索的准确性
我们对比一下 Lucene自带的 SmartChineseAnalyzer 和 IK Analyzer的效率。
1 | package com.learn.lucene.chapter2.analyzer; |
IK Analyzer 默认的停用词词典为 IKAnalyzer2012_u6/stopword.dic
这个词典只有30多个英文停用词,并不完整
推荐使用扩展额停用词词表:https://github.com/cseryp/stopwords
在工程中新建 ext_stopword.dic,放在IKAnalyzer.cfg.xml同一目录;
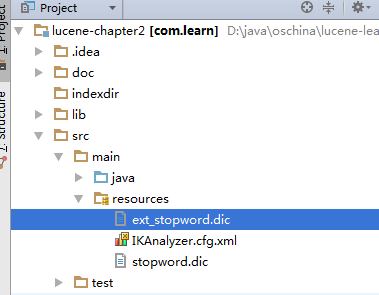
编辑IKAnalyzer.cfg.xml,
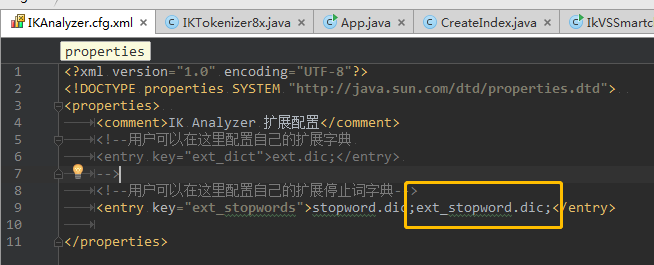
-—————————————————
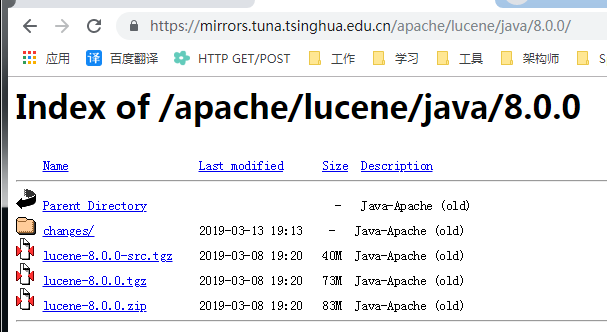
https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/java/8.0.0/
或者在工程中添加maven依赖
https://mvnrepository.com/artifact/org.apache.lucene/lucene-core/
1 | <dependency> |
主要功能:
注意:Luke的版本要跟Lucene保持一致
项目地址:https://github.com/DmitryKey/luke/releases
独立于Lucene,面向Java的公用分词组件
同时提供了 对Lucene的默认优化实现
IK Analyzer2012的特性:
下载地址(需要翻墙):https://code.google.com/p/ik-analyzer/downloads/list
也可有上我的 oschina上下载:
安装包文件列表:
部署步骤:
把 IKAnalyzer2012_u6.jar 放在部署项目的lib目录下
把 stopword.dic 和 IKAnalyzer.cfg.xml 放在 class根目录,对于web工程时 WEB-INFO/classes 目录下
1、maven 安装 IKAnalyzer2012_u6.jar
mvn install:install-file -Dfile=D:\java\oschina\lucene-learn\lucene-chapter2\lib\IKAnalyzer2012_u6.jar -DgroupId=org.wltea.analyzer -DartifactId=IKAnalyzer -Dversion=2012_u6 -Dpackaging=jar -DgeneratePom=true -DcreateChecksum=true
2、在pom.xml中添加
1 | <dependency> |
3、 stopword.dic 和 IKAnalyzer.cfg.xml 放在 src\main\resources 目录下
这样编译完成后,它就会放在 classes 目录下