查看系统tcp参数
1 | [root@centos7cz ~]# sysctl -a|grep ipv4|grep -i --color tcp |
查看系统tcp参数
1 | [root@centos7cz ~]# sysctl -a|grep ipv4|grep -i --color tcp |
虎嗅注:3月12日,字节跳动发布公开信宣布组织升级。张一鸣在信中表示,字节跳动人员数量的激增带来了员工敬业度和满意度的下降。他声称未来将更专注于全球组织管理研究,改进字节跳动的管理。
虎嗅Pro在去年10月份发布了一篇剖析字节跳动组织管理的深案例文章,我们详细研究了字节跳动组织架构、工作文化、业务发展这三者间的关联和因果关系,并得出一个出乎意料的结论,而此次字节跳动和张一鸣的变化也多少印证了我们当时的判断。这个判断究竟是什么,请读者移步正文查看:
流行观点相信字节跳动(下称“字节”)精于管理的判断可能并不准确。
作为过去十年间最成功的科技新贵之一,字节走向壮大可被归结为任意一种主义的胜利,唯独与管理无关——是他们的管理很糟糕吗?
其实,他们根本没有“管理”。
我们必须明确何谓管理,或者在什么语境下来理解管理。可以肯定的是,在国内语境下的绝大多数管理,都更像管控,它们遵循“管理者发号施令,执行者落实”模式。其中一部分施令因为高度重复性,逐渐固化成流程、制度,并不断优化以供复制。
在绝大多数人力密集型产业中——餐饮、快递物流、零售——都能见到上述管理方式。而这些产业里,越是规模庞大的公司,其流程、制度的复杂程度就越高,管理难度就越大。
中通快递有30万员工,这家公司的研究院院长金任群认为人类具备普遍的潜在破坏冲动,而管理者能做的就是,“不断优化流程制度,并祈祷少出问题。”他接受虎嗅pro采访时说。
2017年~2019年,字节的员工数量翻了10倍不止(万,年底有望到达10万),这是被外界误认为字节善于管理的重要原因之一——瞧,他们不仅没失控,还做成了抖音。
但事实可能恰恰相反,正是因为没怎么在管理上花功夫,尤其是避免那些让员工循规蹈矩()的管理,才让字节取得了重要的商业进展。里德·霍夫曼在《闪电式扩张》写道,只有那些满足于每年增长15%的公司才会不慌不忙地招募理想员工并沉迷于企业文化。
字节完全是另一种公司,这家公司的创业史就是一部战争史。过去几年里,字节是最善于发动闪电战的标志性公司,一个在各领域神出鬼没的刺客(尽管并不总能得手)。不久前,他们又突袭了“优爱腾”阵营和快手,顺带捉弄了院线公司一把。据说那场行动从谋划到实施完毕只用了36小时。
让这样一家公司停止扩张有违其生存信条,他们那句“始终创业”口号背后所反映的经营理念,与“打江山易,守江山难”的朝代更迭规律不谋而合。
对字节来说,倒在路上的几率要远小于什么都不做,证据是他们在绝大多数项目未达预期后还生龙活虎。他们没时间管理,因为旧经验的参考价值不大,所有人要么正在战斗,要么正准备战斗。
所以,如果说字节成立至今真有什么管理秘诀,那只能是一张张令员工为之奋进、名为高速增长的“空头支票”,幸运的是,最关键的几张支票都被兑现了。竞技体育里有一种说法,大意是胜利能掩盖一切更衣室矛盾——是的,谁知道字节的管理究竟好不好呢?他们从未真正展示过(强管理换效益),因为还没必要。
(编者注:字节无管理模型建立在持续的高效扩张之上,一旦这种势头停滞,就会陷入管理陷阱。比如抖音诞生的两年多来,字节鲜有现象级产品出现,直接造成员工满意度和敬业度下滑。挽救这种颓势的办法正是在全球范围内寻找新引擎)
事实上字节唯一需要管理的,是如何让员工更快速高效地达成目标。曾任今日头条副总裁的谢欣(现为飞书负责人)在几年前的公开活动中提及管理根本,他的观点是,管理的最终目的是为了达成公司的高绩效目标,只有人可以做到这点,而不是规章制度。
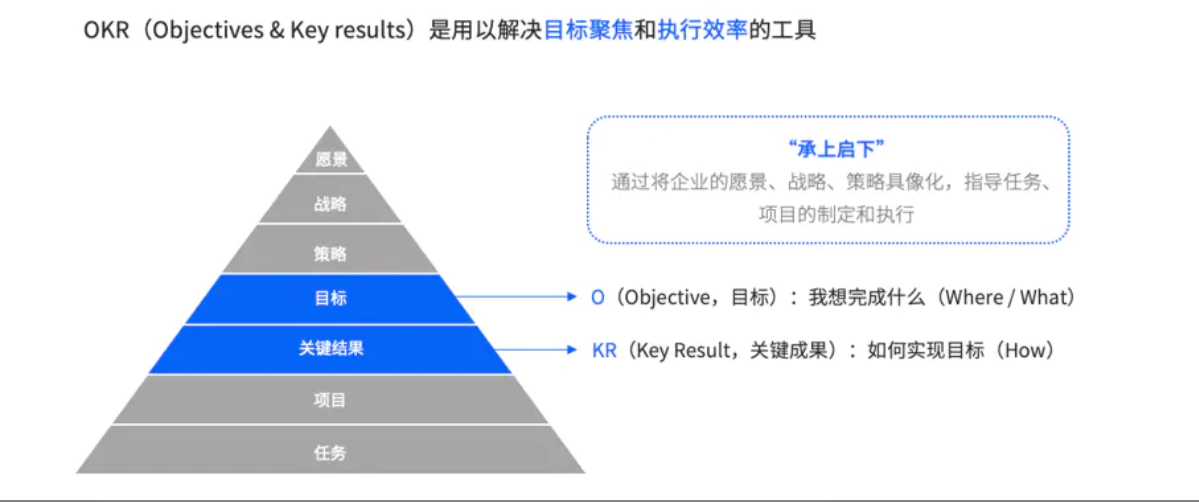
正因如此,字节在创办伊始就采用了最大限度解放员工创造力的OKR管理工具,此管理非彼管理,正如字节内部一名参与企业文化建设的负责人向我们表达的,他认为与其说OKR是管理手段,不如说OKR是达成目标前的工作方式。这些工作方式旨在减少沟通成本,强化协同能力、调动个人积极性,从而向集体目标快速突进。
#本文为字节跳动OKR应用解析深案例删减版,约1.1万字,于2019年10月29日刊发在虎嗅Pro会员-深案例,即刻加入虎嗅Pro会员,解锁全文#
“现代科学管理之父”弗雷德里克·温斯洛·泰勒(下称“泰勒”)在《科学管理原理》一书中主张将管理者与非管理者区分开来:
管理者需要预先制定任务计划并实施计划,要告诉员工每项任务要做什么、如何做以及何时完成。
非管理者则要消除一切虚假的、慢的和无用的动作,按部就班地完成任务。
将泰勒理论变得具有实质意义的举动发生在福特汽车生产线上,福特T型车的生产过程被分解为84个步骤,并将底盘配装流程从12个小时30分钟的时间减少到2个小时40分钟。
泰勒理论影响至今,但这套管理思路的运转以“剥夺”员工思考能力、主观能动性为前提。反过来讲,员工的无能,要求管理者必须全知全能。
显然,任何管理者也做不到。除非市场环境极度友好,几乎不存在竞争。福特汽车就是那个特定时间点下的幸运儿。
早期的管理者做决策通常与真实市场需求无关(事实上今天同样如此),比如福特在1913~1918年期间卖出了全美数量最多的黑色款T型车,却不是因为车主喜欢,而是黑色漆干得快,可以第一时间上市。随着市场竞争加剧,福特风光不再。
失去市场信任的福特随后在员工工资上做文章,他们把计件工资的单件工资调低,或是延长工作时长,引得工人闹罢工。这大概可算作历史上第一次由KPI引起的罢工。
在对OKR的描述中,KPI是常常被拿来说事的负面教材。在字节也不例外,他们认为KPI往往建立在对固定指标和强制结果的追求上,并且与员工绩效强行挂钩。最令人懊恼的是,一旦管理者制定了违背市场规律的决策,员工不仅没办法发挥专长,还要为错误的决策买单。

(图片来源:字节跳动)
事实上,在那些不依赖员工创造性,或是交互较差的岗位之上,KPI往往能发挥最大效果——比如餐饮业的后厨岗位,只需要保证出品速率和稳定。前厅服务岗位由于长期和顾客打交道,随机性较大,就不完全适合KPI考核。
字节成立至今通过不断拓展新业务来扩大市场规模,这就是我们为什么说字节没时间管理的原因,字节并不是一家停留在单一业务上的公司,他们自然也没有什么固有经验可以照搬然后执行。这构成了字节使用OKR的第一个前提。
字节使用OKR的第二个前提是业务属性。字节的所有业务几乎都直接面向C端用户,即便是2B向的飞书,其功能设计也充分考虑了C端使用体验。2B生意往往标准化程度高,2C生意则面临各式各样的不确定性,一款产品上市之前,需反复内测打磨,收集用户意见,上市后还要不断迭代版本。可以说,一款2C类产品的运营周期内的所有业务决策,都不可能完全由管理者制订,更合理的办法是把一部分决策权交给能听到炮火声的一线员工手里。
这是字节天然适用OKR的一个关键,他们在过去几年中开辟了如此之多的C端产品航道,对精通所有这些产品的本领要求已经远远超出了张一鸣和字节管理团队的能力范围之外,因此他们在业务决策上要更为仰仗中、基层员工。
“不要雇用聪明人,然后告诉他们去做什么;而是要让他们告诉我们,应该做什么。”——史蒂夫·乔布斯
“与组织中心相比,创新通常更容易发生在组织的边缘。”——保罗•格雷厄姆
(图片来源:字节跳动)
事实上,在那些不依赖员工创造性,或是交互较差的岗位之上,KPI往往能发挥最大效果——比如餐饮业的后厨岗位,只需要保证出品速率和稳定。前厅服务岗位由于长期和顾客打交道,随机性较大,就不完全适合KPI考核。
字节成立至今通过不断拓展新业务来扩大市场规模,这就是我们为什么说字节没时间管理的原因,字节并不是一家停留在单一业务上的公司,他们自然也没有什么固有经验可以照搬然后执行。这构成了字节使用OKR的第一个前提。
字节使用OKR的第二个前提是业务属性。字节的所有业务几乎都直接面向C端用户,即便是2B向的飞书,其功能设计也充分考虑了C端使用体验。2B生意往往标准化程度高,2C生意则面临各式各样的不确定性,一款产品上市之前,需反复内测打磨,收集用户意见,上市后还要不断迭代版本。可以说,一款2C类产品的运营周期内的所有业务决策,都不可能完全由管理者制订,更合理的办法是把一部分决策权交给能听到炮火声的一线员工手里。
这是字节天然适用OKR的一个关键,他们在过去几年中开辟了如此之多的C端产品航道,对精通所有这些产品的本领要求已经远远超出了张一鸣和字节管理团队的能力范围之外,因此他们在业务决策上要更为仰仗中、基层员工。
“不要雇用聪明人,然后告诉他们去做什么;而是要让他们告诉我们,应该做什么。”——史蒂夫·乔布斯
“与组织中心相比,创新通常更容易发生在组织的边缘。”——保罗•格雷厄姆
(图片来源:字节跳动)
尽管在承担责任的重要程度上,字节的普通员工无法与管理层相比,但双方在各自位置上发挥才干的权利是平等的。OKR正是构建平等的基础(如上图所示)。OKR在蓝图和现实中找到了中间地带,一个由公司确定大方向、调动资源,员工自主行动、获得相应回报的中间地带。
因此,在字节内部,制定OKR遵循“自上而下”、“自下而上”两种方式(事实上这也是OKR基本规则)。
“自上而下”适用于宏观类型的O(objective,即目标)——比如字节2017年决定布局短视频领域(此为公司战略类O),今日头条孵化抖音火山版,或者抖音孵化剪映(此为团队业务发展类O)。“自上而下”途径下,公司和业务团队成员可以就总O进行逐级理解和承接,形成各自小O。
“自下而上”适用于微观类型的O,假设抖音决定提高日活和用户时长(此为具体业务策略O)。那么“自下而上“途径下,业务团队一般成员可发起向上发起O的制定,之后由部门负责人统一对下属的O进行选择、认定和总结,形成自身的O。
值得注意的是,字节遵循了OKR基本规则,即“在自下而上途径里,上级OKR不能单纯为下属OKR的汇总,且上级应确保团队重要且最关注的事项出现在自己的OKR中。”这说明字节比较看重腰部管理层的能力培养。通常而言,腰部管理层的质量决定了一家公司的长远发展。
当一项公司战略被公布后,字节对总O的承接方式分为三种,顺序如下:
第一种是分解式承接,此时上级的O往往涉及多个维度的描述,例如上级O为“提高XX产品的市场竞争力和份额”,需要产品、市场、销售、人力同时提供支撑。此时对应的业务/职能部门负责人即可将上级的O按照自己对应的职责范围进行分解,形成自己部门的O;
第二种是转换式承接,若上级的KR(Key Results,即“关键结果”)与下级的职责范围直接对应,则下级的O可从上级的KR出发进行转换,再根据自己的O定义相应KR();
第三种是直接承接,该方式适用于上级的O与下级职责范围重合,下级填写O时可以直接引用上级的O
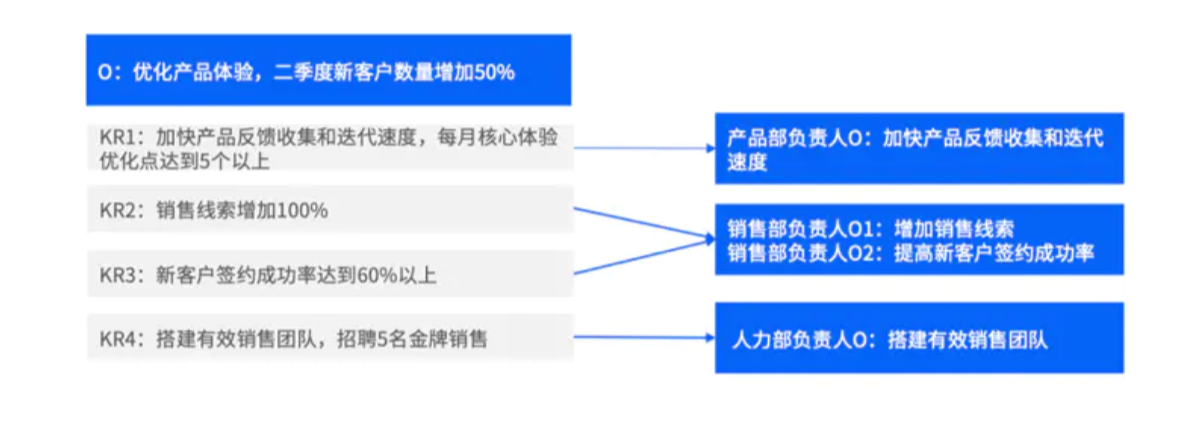
(内容来源:字节跳动虚拟案例展示)
一般来说,第二种和第三种转换方式多发生在微观类型O,描述方式较为精确单一,例如上图展示的“加快产品反馈收集和迭代速度”。第一种转换方式以宏观类型O为主。
OKR在对目标追踪上,一改KPI的结果导向至上。当然,并非结果不重要,但结果往往是包含市场环境、对手竞争、资源投入在内的多方面因素的复杂产物。因此在效益之外,要重视多个关键结果(),对员工的工作状态形成全方位评估。
关键结果的引入,扭转了KPI对员工创新扼杀的弊端,另一方面也使下一次制订目标更加科学(字节允许员工根据实际反馈随时调整O的设定,前提是合情合理)。
那既然如此,如何准确公允地衡量员工的KR完成情况,又不纵容员工有意降低KR实现难度,就成了避免OKR沦为形式主义的重中之重。
【字节怎么给员工的工作结果打分?想知道更多有关字节跳动的OKR细节研究,可查看会员专享的1.1万字原文】
在去年虎嗅Pro对字节内部员工的采访中,他们承认了字节的企业文化先于OKR诞生的事实。一个在2017年之前就入职的员工表示,他刚进字节时根本不知道什么是OKR,但他的适应速度很快。
字节的企业文化与OKR所倡导的行为高度一致,下面是两者的对比关系,左为字节文化——他们称之为“字节范儿”,右为OKR倡导行为:
追求极致——追求困难目标
务实敢为——自下而上设定目标
开放谦逊——与他人协同合作
坦诚清晰——保持信息快速流动,互相透明
始终创业——不设边界,自主思考
(编者注:3月11日,字节基于全球化布局增添了名为“多元兼容“新一项企业文化,此项不在本文讨论范围内)
任何企业文化都来自企业自身对过往一致的良好行动的提炼、总结、概括。正如英国哲学家约翰·洛克所说,“我认为人类的行为是思想的最佳译员。”
反过来,企业文化又将进一步强化或者暗示企业上下的行为准则。“基因论”是最近几年企业经营领域的一个热门说法,恐怕和企业文化也不无关系。
字节在过去几年吸纳了大量来自各领域、各岗位的人员。因此,字节需要采取措施保证原有文化不被破坏的同时,让新员工快速融入这种文化。因此字节做的第一件事就是取消工号,这么做是为了避免排资轮辈氛围的滋生。他们喜欢用一个案例对此说明,那就是在内部跨部门合作中,往往到结束,有一方都不知道对接工作的另一方是实习生(字节要求所有人直呼其名)。
除此之外,他们也取消了职级和等级概念——起码在工作中是很难被察觉到的。淡化甚至闭口不谈头衔是最常见的做法,那些出现在新闻稿上的职位头衔,据说是为出席活动的人临时准备的,一旦活动结束,这些人又将恢复到没有头衔的状态。谢欣2015年出席QCon大会时也说过这点,“其实公司没有人知道互相是什么头衔,我们觉得这个不重要,知道了反而会耽误事。”
调整组织结构是字节强化平等的另一个补充,当然这个设计也在兼顾信息和创意流动的流畅性。字节跳动没有采用事业部编制,而是基于用户增长、技术和商业化等部门搭建中台,形成“你中有我、我中有你”的网状架构。这个表述可能更像是介于谷歌与脸书的组织结构之间的某种形态()。
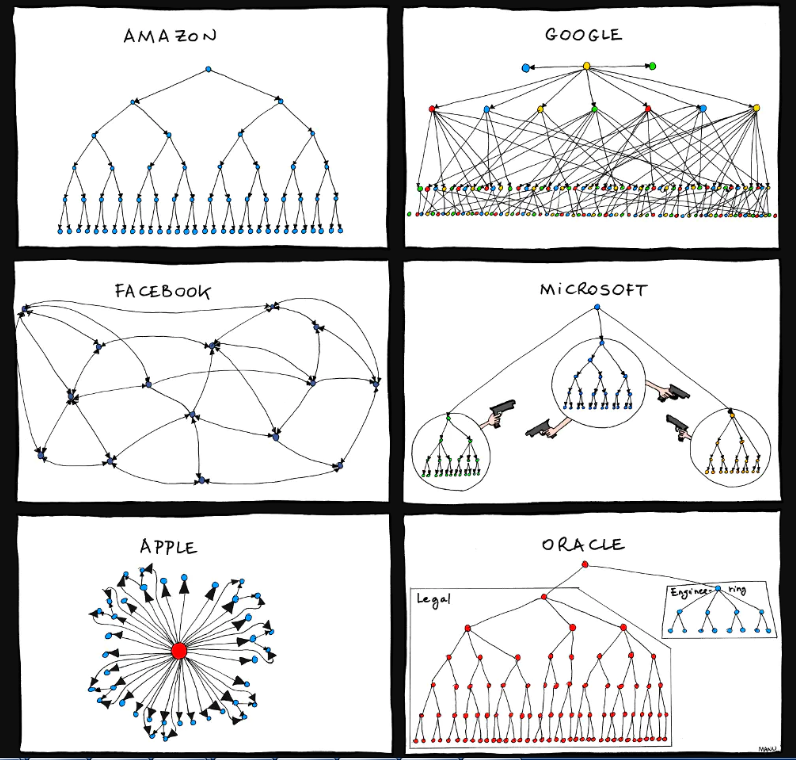
(图片作者:Manu Cornet)
在字节的办公区域、休闲区域都有他们称之为“字节范儿”的宣传,员工在食堂吃饭时可以听到、茶水间抬头可以看到、总结工作时(逢双月优化/点评OKR)可以用到……让员工成为企业文化的忠实拥趸没有取巧的办法,必须不厌其烦地反复讲述。
字节非常喜欢启用年轻人,他们5万人的平均年龄只有28岁,抖音、多闪的项目主管都是90后。年轻人更容易被塑形,他们或许在业务素养上还需要培养,但初入社会的那份干净更被看重。
张一鸣的主要成果在于确立了“字节范儿”的基调并以此广纳人才。这一说法能从字节企业文化的管理团队处得到印证,“在内部,先于OKR诞生的企业文化正是由参与创办字节的成员们总结的。” 对方表示。
2005年,大学毕业的张一鸣加入酷讯后,仅用一年就从普通工程师升为管理全部后端技术、以及部分产品工作的主管。许多年后,当他评价起这段经历,张一鸣认为自己做对了几件事:
我工作时,不分哪些是我该做的、哪些不是我该做的。我做完自己的工作后,对于大部分同事的问题,只要能帮助解决,我都去做。
工作前两年,我基本上每天都是十二点一点回家,回家以后也编程到挺晚。确实是因为有兴趣,而不是公司有要求。
我负责技术,但遇到产品上有问题,也会积极地参与讨论、想产品的方案(包括与销售一起出去跑单)。很多人说这个不是我该做的事情。但我想说:希望把事情做好的动力,会驱动你做更多事情。
在上述描述中,基本每一条都能找到1~2处与OKR所主张的相似点。张一鸣离开酷讯后的几次创业公司/创业经历,让他有足够的阅历去沉淀这些特质,这些特质反过来又在帮张一鸣辨认志同道合者。例如,他在酷讯时期以产品主管身份主动请缨与销售总监见客户的经历,被他认为是“为今日头条招销售人才奠定了基础”。
“大力出奇迹”、“延迟满足感”这两句“鸣言鸣语”翻译过来即为OKR倡导的“追求困难目标”,三者没有本质区别。
源码资本曹毅说,张一鸣会对自己必须拿下的东西,全力以赴投入所有资源,所有精力,大力出奇迹。(来源:人物杂志)
张一鸣的天使投资人刘峻说,张一鸣心里想的是100,对投资人只会报个80,但实际上最后做出来的往往是120甚至150。(来源:捕手志)
今日头条早期产品负责人黄河说,张一鸣敢于定很高的目标,头条每年的营收目标都很高,而且在基数已经很大的情况下,还敢去制定几倍的高目标。张一鸣的愿景和目标非常大,所以也推着每个人都极致地努力工作。(来源:左林右狸)
一旦认准“高目标”,字节往往会全力进攻,字节内部人士对虎嗅表示,“我们不是说()不够就不做,我们一定要尽力满足,招人进来做,这个阶段不干别的,直到招满合适的人。”
【参照字节跳动成长轨迹,都有哪些业务适合在开创初期运用OKR进行推动?张一鸣还有哪些关键特质值得注意?加入虎嗅pro查看会员专享的1.1万字原文】
张一鸣在过往绝大多数采访中都表现出一种价值倾向,类似于“我做好事与我是好人之间没有必然联系”。
他不认为字节是一家擅于给用户带去鲜明主张的公司。相较于明确字节价值观这件事,张一鸣更愿意说,字节的远景是“信息更多更快地抵达用户”(2014年,来源:腾讯科技),或者真有价值观的话,是“提高分发效率、满足用户的信息需求”(2016年,来源:财经杂志)。
如果你观察上一段时间,就会发现在字节官方对外的传播口径中,也基本不提“价值观”这三个字。他们在微信上的字节跳动文化官方账号“字节范儿”上比较常用的是“工作方式”、“工作文化”——甚至不是我们在前文里频繁提起的“企业文化”。
这种“重个体,轻集体”的表述,**让字节和大部分规模到了这个量级的中国公司都不太一样,后者一般都相当强调集体性和执行力,带给人无形压力。但字节的员工看上去很轻松,也很个人。**
价值观和企业管理有什么关系?如果按照彼得·德鲁克的定义,管理就是“界定组织使命,然后激励和组织人力资源来实现使命” 的过程。
德鲁克还在《经济人的末日》一书中引用纳粹政府作为管理的负面教材,以此说明管理向善的必要性。他认为,“管理只能行善,不能作恶”。也就是说,管理需要价值观。
价值观是企业面临抉择时的指南针。
虎嗅Pro认为,字节创办至今在价值观上的微妙状态,是这家公司能够持续高速增长,却多少在产品上受到舆论困扰的根本原因。
“让信息流动更高效”具有相当深的延展性,其肉眼可见的正面意义正如今日头条天使投资人刘峻接受捕手志采访时所说,把印刷机和电视机创造出来,让信息得到自由的流通,本身就是一种价值观。
可再往下深入,或者再往上拔高呢?张一鸣却没有明示字节这么做的意义(使命、why),而是让这句话始终停留在愿景(),以及更低维的战略()上,最终演变成一种工作方式——还记得我们在上文介绍与张一鸣乃至字节上下的工作方式相契合的OKR理念吗?那并不是偶然。
“让信息高效流动”,以此原则来指导一切企业行为,则会带来隐患。
当年字节拿了新浪微博的投资,然后抓取微博的公共内容作为今日头条的算法饲料,以实现让信息更高效流动的愿景。从法律上讲好像没啥大问题,可是道德层面呢?
过去八年间,字节固然在推动信息高效流动上取得了瞩目成就,却也因此给自己制造了一道道枷锁,比如媒体状告今日头条侵权、内容低俗……这些看起来都像是外界主动施加给字节的价值判断、道德审判,仔细想想也不尽然。一切问题的根源其实在字节手里,如果张一鸣不行使界定价值观的权力,那么就会有人帮他行使。
张一鸣最终会行使权力吗?或许比这个问题更重要的是,怎样行使权力才不会影响字节的高速增长。
作者:unsakei
链接:https://www.jianshu.com/p/3395815ad66b
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

算法描述:
缺点:
GitHub:https://github.com/twitter-archive/snowflake
官方文档:https://twitter.github.io/twitter-server/
Mybatis采用默认的twitter-snowflake,没有解决时钟回拨问题;
GitHub:https://github.com/baidu/uid-generator

Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。默认采用上图字节分配方式:
RingBuffer环形数组,数组每个元素成为一个slot。RingBuffer容量,默认为Snowflake算法中sequence最大值,且为2^N。可通过boostPower配置进行扩容,以提高RingBuffer 读写吞吐量。
Tail指针、Cursor指针用于环形数组上读写slot:
rejectedPutBufferHandler指定PutRejectPolicyrejectedTakeBufferHandler指定TakeRejectPolicy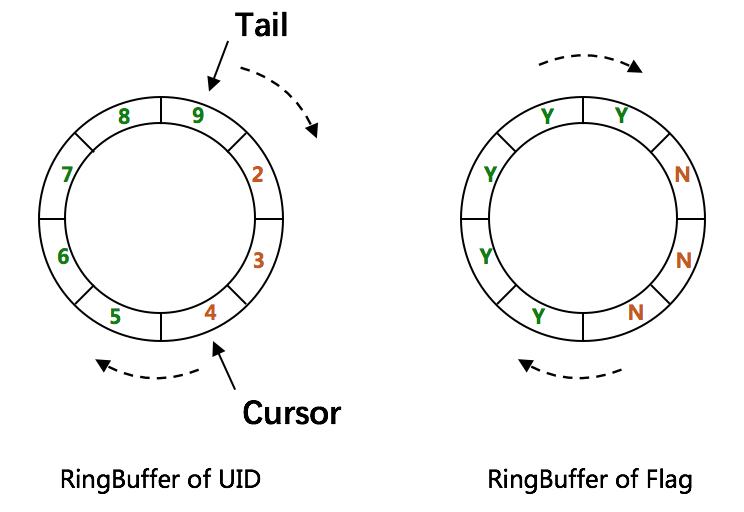
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine 补齐方式。
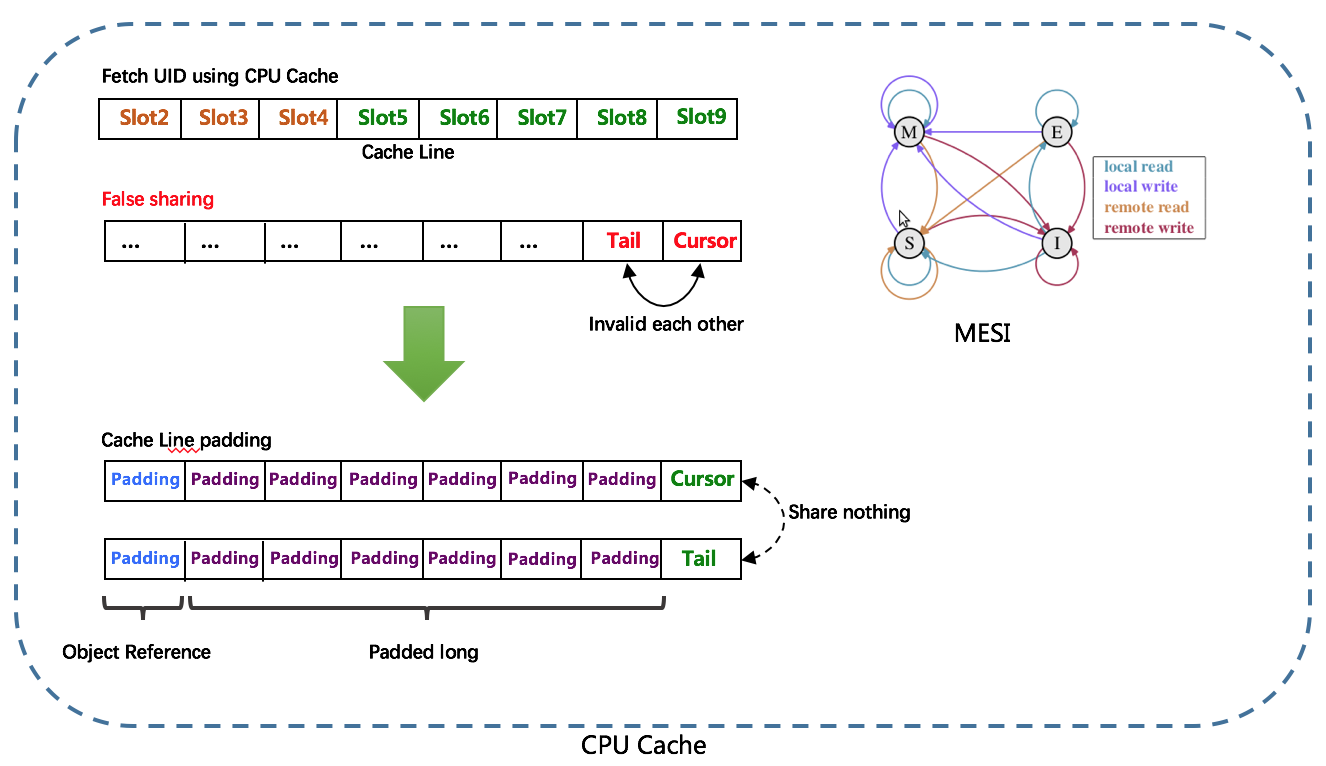
tail - cursor),如小于设定阈值,则补全空闲slots。阈值可通过paddingFactor来进行配置,请参考Quick Start中CachedUidGenerator配置scheduleInterval配置,以应用定时填充功能,并指定Schedule时间间隔CachedUidGenerator在初始化时除了给workerId赋值,还会初始化RingBuffer。这个过程主要工作有:
第二步的异步线程实现非常重要,也是UidGenerator解决时钟回拨的关键:在满足填充新的唯一ID条件时,通过时间值递增得到新的时间值(lastSecond.incrementAndGet()),而不是System.currentTimeMillis()这种方式,而lastSecond是AtomicLong类型,所以能保证线程安全问题。
传统的雪花算法实现都是通过System.currentTimeMillis()来获取时间并与上一次时间进行比较,这样的实现严重依赖服务器的时间。而UidGenerator的时间类型是AtomicLong,且通过incrementAndGet()方法获取下一次的时间,从而脱离了对服务器时间的依赖,也就不会有时钟回拨的问题(这种做法也有一个小问题,即分布式ID中的时间信息可能并不是这个ID真正产生的时间点,例如:获取的某分布式ID的值为3200169789968523265,它的反解析结果为{“timestamp”:”2019-05-02 23:26:39”,”workerId”:”21”,”sequence”:”1”},但是这个ID可能并不是在”2019-05-02 23:26:39”这个时间产生的)。
导读
把绩效管理和价值观贯彻进行有效和深度结合,形成了阿里巴巴独具特色的绩效考核体系,是阿里巴巴持续取得高绩效的关键因素。其中的评定、考核和流程是怎样的呢,推荐阅读这篇干货文章。
绩效特点
阿里巴巴的绩效管理体系基本上借鉴自通用电气,建立之初就有比较健康的基础。在此基础上,阿里巴巴绩效管理形成了自己的特点:
一是制定高目标,
二是把价值观纳入考核,
三是建立了政委体系,做“人”的工作。
绩效基本体系
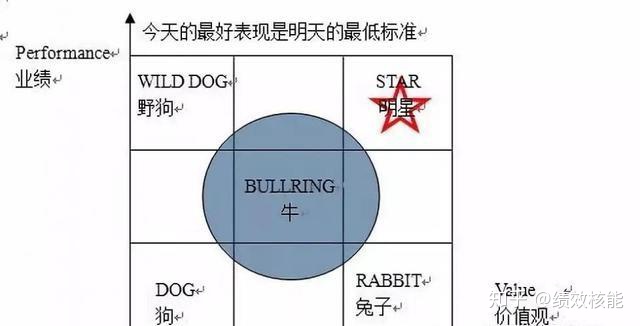
阿里巴巴绩效管理体系的基本理念和框架借鉴自通用。2001年,为通用服务25年的关明生加盟阿里巴巴,帮助阿里巴巴打造了一套与国际接轨的绩效管理体系,奠定了阿里巴巴绩效管理的基础。比如,借鉴和进一步强化了通用对价值观的推崇,阿里巴巴也用了“活力曲线”法则,以及基于这个方法的淘汰和激励制度。
“活力曲线”在阿里巴巴指用“271排名”的方式来考察员工的相对业绩。不过阿里巴巴对后10%的淘汰没有像通用那么严厉。在阿里巴巴,员工通过考核被分成三种:一是有业绩,但价值观不符合的,被称为“野狗“;二是事事老好人,但没有业绩的,被称为“小白兔”;三是有业绩,也有团队精神的,被称为“明星”;业绩和价值观均处于中间位置,被称为“牛”。对价值观表现好,但业务弱的“小白兔型”,阿里巴巴会给予考察、培训、转岗的机会,除了作假行贿等触犯道德底线的“野狗型”员工,阿里巴巴也很少因为价值观考核而直接开除员工。

直观理解为:大家是相互信任的,只要我尽了最大的力量,在公司的基本层面,比如:价值观上没有违背,就不会因为我在前线打了败仗,就“杀”了我。
制定高目标
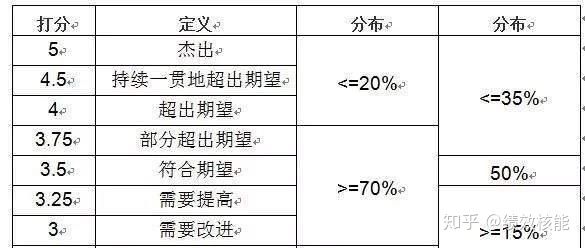
在个人绩效考核方面,阿里巴巴采用5分制的打分方式,每个季度,每年对个人进行绩效评估。在年末制定新一年业绩目标的时候,会详细标明不同的业绩对应不同的分值。阿里巴巴,大概只有10%的员工能在绩效考核中拿到4分。拿到4分不仅意味着12分的努力,还要发挥创造性。按照常规的方式方法工作,基本上达不到4分。拿到4分需要突破常规进行创新。
在阿里巴巴,基本上没有人能够拿到5分。这样的业绩指标设计和打分标准,体现了阿里巴巴的指导思想:如果目标定低了,你就会降低对自己的要求;你可以拿不到5分或4分,但是我要确定你已经尽了12分的努力去实现4分、5分的目标。
把价值观纳入考核
阿里巴巴别出心裁地把价值观纳入绩效考核体系。价值观考核与业务考核各占到50%的比重。而价值观考核指标囊括了追求高绩效的价值观导向和具体的方式方法——如果价值观考核优异,业务绩效不好是不可能的。

一、客户第一——客户是衣食父母
1分:尊重他人,随时随地维护阿里巴巴形象 。
2分:微笑面对投诉和受到的委屈,积极主动地在工作中为客户解决问题 。
3分:与客户交流过程中,即使不是自己的责任,也不推诿 。
4分:站在客户的立场思考问题,在坚持原则的基础上,最终达到客户和公司都满意 。
5分:具有超前服务意识,防患于未然 。
二、 团队合作——共享共担,平凡人做非凡事
1分:积极融入团队,乐于接受同事的帮助,配合团队完成工作 。
2分:决策前积极发表建设性意见,充分参与团队讨论;决策后,无论个人是否有异议,必须从言行上完全予以支持 。
3分:积极主动分享业务知识和经验;主动给予同事必要的帮助;善于利用团队的力量解决问题和困难 。
4分:善于和不同类型的同事合作,不将个人喜好带入工作,充分体现“对事不对人”的原则。
5分:有主人翁意识,积极正面地影响团队,改善团队士气和氛围。
三、 拥抱变化——迎接变化,勇于创新
1分:适应公司的日常变化,不抱怨 。
2分:面对变化,理性对待,充分沟通,诚意配合 。
3分:对变化产生的困难和挫折,能自我调整,并影响和带动同事 。
4分:在工作中有前瞻意识,建立新方法、新思路。
5分:创造变化,并带来绩效突破性地提高。
四、 诚信——诚实正直,言行坦荡
1分:诚实正直,表里如一 。
2分:通过正确的渠道和流程,表达自己的观点;表达批评意见的同时能提出相应建议,直言不讳。
3分:不传播未经证实的消息,不背后不负责任地议论事和人,并能正面引导,对于任何意见和反馈“有则改之,无则加勉”。
4分:勇于承认错误,敢于承担责任,并及时改正。
5分:对损害公司利益的不诚信行为有效地制止。
五、 激情——乐观向上,永不放弃
1分:喜欢自己的工作,认同阿里巴巴企业文化 。
2分:热爱阿里巴巴,顾全大局,不计较个人得失 。
3分:以积极乐观的心态面对日常工作,碰到困难和挫折的时候不放弃 ,不断自我激励,努力提升业绩。
4分:始终以乐观主义的精神和必胜的信念,影响并带动同事和团队。
5分:不断设定更高的目标,今天的最好表现是明天的最低要求
六、 敬业——专业执着,精益求精
1分:今天的事不推到明天,上班时间只做与工作有关的事情。
2分:遵循必要的工作流程,没有因工作失职而造成的重复错误。
3分:持续学习,自我完善,做事情充分体现以结果为导向。
4分:能根据轻重缓急来正确安排工作优先级,做正确的事。
5分:不拘泥于工作流程,化繁为简,用较小的投入获得较大的工作成果。
30条指标把抽象的价值观分解为具体的行为和精神层面的要求。大部分是对行为的要求,也有精神层面的要求。在细分的30条考核指标中,也突出了业绩导向的取向。
硬考核的软力量。阿里巴巴的价值观考核最重要的功能其实不在于考核本身,而在于价值观的传递和强化。尽管价值观考核占绩效考核的50%,但在实际执行中,阿里巴巴几乎不会因为价值观考核分数低而直接开除员工,除非是越过了道德底线。
沟通和宣讲在价值观考核环节中尤为重要。阿里巴巴的价值观考核先由员工自评,然后由上级进行评估,之后是与人力资源部门一起对分歧进行沟通、对没有做好的地方进行分析。
当时有两个原因促使阿里巴巴直接把价值观和绩效考核挂勾。
第一,公司年轻人很多,年轻人需要补课。在中国,年轻人从小接受应试教育,在学校其实他们基本上没有机会学习怎么样跟同事交流、沟通,怎么融入团队。
第二,阿里巴巴的发展太快了,快到如果不用一些矫枉过正的方式去推价值观的话,公司的价值观就会像手里抓沙子一样,一点点流失光。有人说这个考核太严厉了,只要考核结果就好,为什么要考核过程?经验证明,如果没有相应的过程,即使得到那个结果,那也是昙花一现,不能持久。所以一定要用矫枉过正的方式来推价值观。
第三,阿里巴巴对推广价值观有信心。因为你要是用符合这个价值观的方式去思考和行为的话,你自己会非常受益。
1、季度考核
2、价值观考核实行通关制,即:大家应该首先做到较低分数的条款,然后进阶至较高级的条款,依此原则,若较低分数未能做到,则没有机会进阶;体现了更高的一个要求和优先级
3、打分规则:
每一条若只做到部分,可以评0.5分
如要扣分,需对员工有事例当面说明
0.5分(含)以下,或是3分(含)以上,需要上级主管书面说明事例
目标管理(定性、定量,全面、客观)
强调长期而非短期;
强调员工首创和互动,而不仅从上至下;
强调培训督导而非只看结果,过程和结果一样重要;
强调个体绩效趋势;
倡导绩效管理即企业绩效管理而非割裂开的个人绩效管理;
考核的最终结果是一支备受鼓舞和激励的员工队伍,一支生产力水平不断提高的员工队伍;而不只是奖金,加薪和开除。

从上个季度的面谈行动计划开始,对本季度的工作进行自我总结,主管对员工的行为点评,就行为的评价达成共识,明确新目标的行动计划。
立场要坚定, 今天的最好表现是明天的最低要求;你是绩效管理的owner;公正、真诚、善意;丑话当先;不要轻易被不重要的事情所左右。
(1)正面反馈
让下属知道他的表现达到或超过对他的期望。
下属知道他的表现和贡献得到了认可。
强化这种行为,增大这种行为重复的可能性。
要求:真诚,具体
(2)建设性反馈
建设性反馈应集中于潜力点。
建设性反馈是提请人们注意问题或潜在问题的信息。
建设性反馈本身并不解决问题,但它为解决问题或进行其他进一步行动开启了大门。
给予或接受建设性反馈的关键是保持相互尊重和相互学习的态度。
建设性反馈的关键行动:
表达你积极的意图。
具体描述你所观察到的情况。
说明那种行为或行动的影响。
征求对方的答复。
集中讨论解决方法。
总结及表示支持。
(3)负面反馈
负面的反馈的步骤:
1.具体地描述下属的行为,耐心,具体,描述相关的行为(所说,所做),对事不对人,描述而不是判断
2.描述这种行为所带来的后果,客观,准确,不指责
3.探讨下一步的做法,提出建议及这种建议的好处。
负面反馈一定要真诚,富有善意。(来源:老板管理内参中心)
今天给大家推荐一套老板和员工都想要的绩效方案:KSF、PPV、积分式,将给大家一一讲解,请认真往下看。
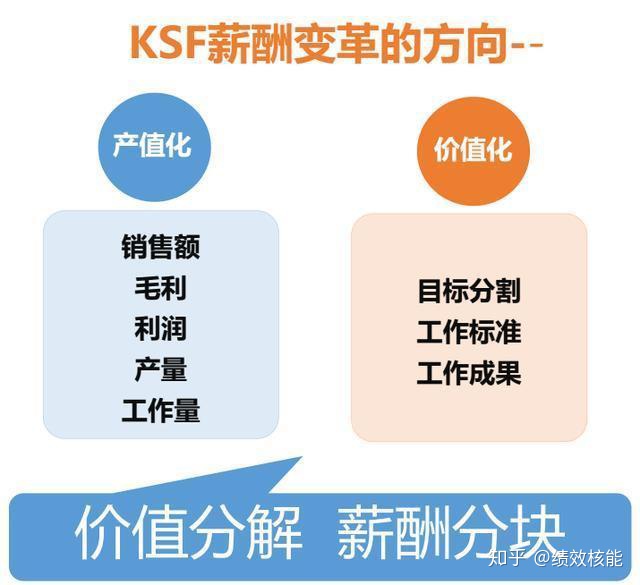
KSF是一种能体现管理者和企业共赢的模式,它一般会给管理者开拓6-8个绩效激励渠道,并在每一个渠道上找到平衡点,超出平衡点即做出分配细节,这个模式分配的不是企业既有的利润,而是一种超价值的分配,要求管理者拿出好的结果、效果与企业进行价值交易,企业赢得的是高绩效、管理者员工赢得的是高收入。
KSF设计的六个步骤:
分析这个岗位核心工作,直接为企业带来效益的价值点
比如销售额、毛利率、毛利润、员工流失率、主推产品销量、员工培训等可量化的急需改善的指标
每一个指标,都配置对应的绩效工资。需要注意,不高把所有的指标平均分配工资,要挑重点。

过去一年里,营业额、利润额、毛利率、成本费用率等
企业和员工最能接受的平衡点,要以历史数据作为参考
依据历史数据,选取好平衡点,讲选取好的指标,各分配不同比例的工资额。
举个案例,某生产经理薪酬模式:
在KSF模式下,他的薪酬分配:固定薪酬(20%)+宽带薪酬(80%),宽带薪酬的部分薪酬,被分配到6-8个指标当中,每一个指标设定一个平衡点(平衡点选在过去一年的数据平均值,或者是老板和员工达成的共识点),只要达到了平衡点,员工就可以拿到这部分薪酬。
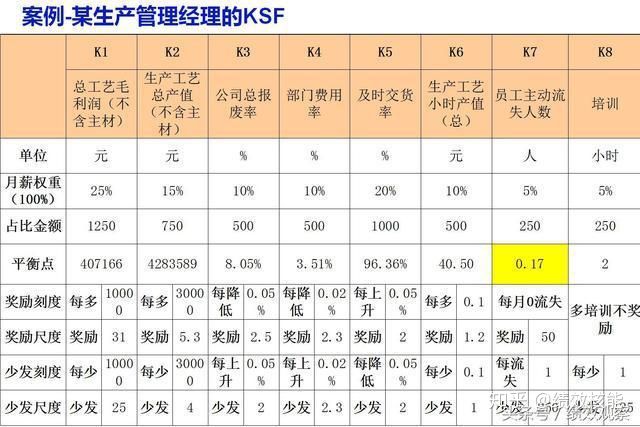
生产经理KSF薪酬模式
如果采用KSF薪酬模式,他会有6-8个加工资的渠道,在原有平衡点上:
KSF全绩效模式,给员工提供了没有上限的加薪模式,员工可以凭借自己的努力,创造更好的结果,为自己加薪。
所谓PPV产值量化薪酬模式:是指将员工的工作职责、工作内容、工作项目、工作结果等以标准化、规则化、价值化的方式进行量化计算,并直接与员工的收入挂钩,形成多劳多得的利益分配机制,相比传统的计件工资、绩效工资等更具激励活力。

以前台文员为例:

用这套PPV薪酬设计模式后,这位前台文员开始每天都忙起来了,下班时间也在工作。每月收入由过去固定的2000元涨到平均5000多元。6个月后,她被公司调到网络部担任业务小主管,现在月薪已经过万了。公司不仅保住了一名前台文员,更将她培养成骨干人才。
三、积分式激励模式
所谓积分式是对人的“综合表现、核心价值、团队贡献”用奖分、扣分进行量化管理的模式,并通过即时激励、综合评价,旨在全方位调动人的主动性,创造力,建立积极正面快乐的绩效文化。
员工要的不是管理,员工要的是激励,激励就是让员工自愿、主动来做,管理就是要求员工去做。
面对员工在工作中存在的问题,我们采用的方式应该是“七分激三分管”,也主就是说我们想要员工做的工作,我们想要员工解决的问题,我们都匹配好激励——给积分、给奖券,让员工每天都能赚到积分、奖券。积分做排名,根据排名做奖励;奖券抽奖品,张张奖券有机会中大奖。
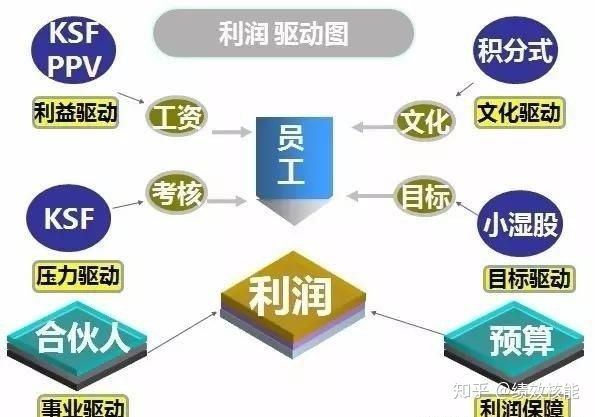
积分式激励4大设计
想要做积分式激励模式,需要做好4件事情:
1.制定积分标准:这是企业想要的,我们希望员工做好的工作、我们想要员工解决的问题,都可以设定为积分标准,激励员工主动做好积分标准的工作;
2.设定奖励计划:当员工赚到积分、奖券时让员工清晰地知道自己能获得什么好处,越努力越幸运;

3.积分软件:让员工在积分软件自主申请,管理者审核,并永久记录,当员工累积到一定积分,可以获得一定奖励。积分数据可以作为晋升的依据。
4.举办快乐大会:快乐大会每个季度举行1次,当天有抽奖、有游戏、有节目……这是员工自己的活动,也是积分奖励计划实现的平台,快乐大会可以和员工生日会、聚餐、户外活动一起举办。

积分式操作要点:
积分式激励模式除了要做好积分标准、奖励计划,同时要特别注重引发积极、主动、快乐的工作氛围,通过每天点点滴滴地引导,最后通积分积累和沉淀下来,让员工能快乐地工作、员工只有快乐地工作,才能对企业有好的归属感,才能沉淀为真正的企业文化。
总结:
当员工和企业的利益趋同时,思维和行动也就自动实现统一。制度也不怕没人执行,管理干部会为了自己的利益,主动寻找企业的问题,并建立制度进行有效管控!因为企业效益越好,员工的收入就越高,只有这样,员工才能可能自动自发!

InnoDB实现了两种 行级锁:共享锁(S) 和 独占锁(X)
共享锁:允许 事务 持有 read 一行 的锁;
独占锁:允许 事务 持有 update 或 delete 一行的锁;
InnoDB 支持 多颗粒度加锁,允许 行锁 和 表锁 共存。例如, LOCK TABLES ... WRITE 就是在指定表上加独占锁。为了支持多颗粒度加锁,InnoDB设计了 意向锁。意向锁 是 一种 表级锁,用来 指示 一个事务对表中的一行数据需要加 哪种类型(shared 或 exclusive)的锁。
意向锁有两种:
intention shared lock (IS)意向共享锁:表示 一个事务 倾向于 对一行数据 使用共享锁;在 transaction 获取一个 共享锁(S) 之前 必须先获得一个 IS 锁;
intention exclusive lock (IX)意向独占锁:表示 一个事务 倾向于 对一行数据 使用独占锁;在 transaction 获取一个 独占锁(X) 之前 必须先获得一个 IX 锁;
例如:SELECT ... LOCK IN SHARE MODE 使用的就是 IS 锁, SELECT ... FOR UPDATE 使用的是 IX 锁;
表级锁的兼容性:
X |
IX |
S |
IS |
|
|---|---|---|---|---|
X |
Conflict | Conflict | Conflict | Conflict |
IX |
Conflict | Compatible | Conflict | Compatible |
S |
Conflict | Conflict | Compatible | Compatible |
IS |
Conflict | Compatible | Compatible | Compatible |
如果请求事务与现有锁兼容,则授予它锁,但如果与现有锁冲突,则不授予它锁。事务将一直等待,直到释放冲突的现有锁。如果锁请求与现有锁发生冲突,并且由于会导致死锁而无法被授予,则会发生错误。
record lock 是 对 index record 加锁的一种锁。例如 SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE; 阻止其他事务 插入、更新、删除 t.c1=10 的行;
record lock 总是对 index record 加锁,即使没有对表定义任何索引。在这种情况下 InnoDB 会添加一个隐藏主键;
一个 gap lock 是 加在 索引记录之间的 锁。例如 SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE可以防止其他事务把 t.c1=15的记录插入表中;
一个 gap 可能是 一行记录,多行记录,或者 为空;
gap lock 是 性能 和 并发 之间的一种折中方案,只在某些隔离级别下生效;
SELECT * FROM child WHERE id = 100;
child[100][x] ~ child[100][y] 之间的记录; 简单来说就是 gap lock 锁定的是一个范围(0~N条记录),而不是单条记录;
InnoDB中的Gap锁是“纯粹的抑制性锁”,这意味着它们的唯一目的是防止其他事务插入到Gap中。间隙锁可以共存。一个事务所采取的间隙锁并不会阻止另一个事务对同一间隙采取间隙锁。共享锁和独占锁之间没有区别。它们彼此不冲突,并且执行相同的功能。
禁用gap lock:
READ COMMITTED ;next-key lock 是 record lock 和 gap lock 的组合
当 InnoDB 搜索索引时,它会在 index 上加一个行级锁;因此 行级锁 实际上 是 index-record lock。
假设 一个 index 包含 10,11,13,20。那么可能的 next-key lock 如下:
1 | (negative infinity, 10] |
在 REPEATABLE READ 隔离级别下,并且禁用了 innodb_locks_unsafe_for_binlog, InnoDB 使用 next-key lock 扫描索引的时候 可以防止幻读;
child表包含90,102两条数据,事务A获取一个 gap lock (100, max_value)
1 | CREATE TABLE child (id int(11) NOT NULL, PRIMARY KEY(id)) ENGINE=InnoDB; |
如果事务B 想插入 101,则需要等待事务A提交
1 | START TRANSACTION; |
auto-inc lock 是一种特殊的表级锁。如果一个事务正在向表中插入值,那么任何其他事务都必须等待,以便由第一个事务插入的行接收连续的主键值。
innodb_autoinc_lock_mode 用于
死锁是指由于每个事务都持有对方需要的锁而无法进行其他事务的情况。因为这两个事务都在等待资源变得可用,所以都不会释放它持有的锁。
该示例涉及两个客户端A和B。
首先,客户端A创建一个包含一行的表,然后开始事务。在事务中,A通过S在共享模式下选择该行来获得对该行的 锁定:
1 | CREATE TABLE t (i INT) ENGINE = InnoDB; |
接下来,客户端B开始事务并尝试从表中删除该行:
1 | START TRANSACTION; |
删除操作需要一个X锁。无法授予该S锁,因为它与客户端A持有的锁不兼容 ,因此该请求进入针对行和客户端B块的锁请求队列中。
最后,客户端A还尝试从表中删除该行:
1 | DELETE FROM t WHERE i = 1; |
此处发生死锁是因为客户端A需要 X锁才能删除该行。但是,不能授予该锁定请求,因为客户端B已经有一个X锁定请求,并且正在等待客户端A释放其S锁定。由于B事先要求锁,所以SA持有的锁也不能 升级 X为X锁。结果, InnoDB为其中一个客户端生成错误并释放其锁。客户端返回此错误:
1 | ERROR 1213 (40001): Deadlock found when trying to get lock; |
届时,可以授予对另一个客户端的锁定请求,并从表中删除该行。
InnoDB自动检测事务 死锁并回滚一个或多个事务以打破死锁。 InnoDB尝试选择要回滚的小事务,其中事务的大小由插入,更新或删除的行数确定。
如果死锁无法检测,通过设置 innodb_lock_wait_timeout 来解决;
如果 一个事务被完整的会滚,那么它所持有的所有锁都会被释放;但如果由于出错仅仅一条sql被会滚,那么某些锁可能不会被释放;这是因为 InnoDB存储行锁的格式 无法确定后续的锁会被哪些sql持有;
要查看InnoDB用户事务中的最后一个死锁,请使用SHOW ENGINE INNODB STATUS命令。
如果频繁出现死锁,则说明事务结构或应用程序错误处理存在问题,请在innodb_print_all_deadlocks 启用该设置的情况下运行,以 将有关所有死锁的信息打印到 mysqld错误日志中
InnoDB使用自动行级锁定。即使在仅插入或 删除 单行的事务中,也可能会遇到死锁。这是因为这些操作并不是真正的“ 原子 ”操作。它们会自动对插入或删除的行的(可能是多个)索引记录设置锁定。
您可以使用以下技术来处理死锁并减少发生死锁的可能性:
在任何时候,发出 SHOW ENGINE INNODB STATUS命令以确定最近死锁的原因。这可以帮助您调整应用程序以避免死锁。
如果频繁出现死锁警告引起关注,请通过启用innodb_print_all_deadlocks 配置选项来收集更广泛的调试信息 。有关每个死锁的信息,而不仅仅是最新的死锁,都记录在MySQL 错误日志中。完成调试后,请禁用此选项。
如果由于死锁而失败,请始终准备重新发出事务。死锁并不危险。请再试一次。
保持交易小巧且持续时间短,以使交易不易发生冲突。
进行一系列相关更改后立即提交事务,以减少冲突的发生。特别是,不要长时间未提交事务而使交互式 mysql会话保持打开状态。
如果您使用锁定读取(SELECT ... FOR UPDATE或 SELECT ... LOCK IN SHARE MODE),请尝试使用较低的隔离级别,例如 READ COMMITTED。
修改事务中的多个表或同一表中的不同行集时,每次都要以一致的顺序执行这些操作。然后,事务形成定义明确的队列,并且不会死锁。例如,组织数据库操作到功能在应用程序中,或调用存储程序,而不是编码的多个相似序列 INSERT,UPDATE以及 DELETE在不同的地方语句。
将选择好的索引添加到表中。然后,您的查询需要扫描更少的索引记录,并因此设置更少的锁。使用EXPLAIN SELECT以确定哪些索引MySQL认为最适合您的查询。
使用较少的锁定。如果你能负担得起,以允许 SELECT从一个旧的快照返回数据,不要添加条款FOR UPDATE或LOCK IN SHARE MODE给它。在READ COMMITTED这里使用隔离级别是件好事,因为同一事务中的每个一致性读取均从其自己的新快照读取。
如果没有其他帮助,请使用表级锁序列化事务。LOCK TABLES与事务表(例如InnoDB 表)一起使用的正确方法 是,以SET autocommit = 0(not START TRANSACTION)后跟来开始事务,直到明确提交事务后才LOCK TABLES调用 UNLOCK TABLES。例如,如果您需要写表 t1和从表中读取数据 t2,则可以执行以下操作:
1 | SET autocommit=0; |
表级锁可防止对表的并发更新,从而避免死锁,但代价是对繁忙系统的响应速度较慢。
序列化事务的另一种方法是创建一个仅包含一行的辅助“ 信号量 ”表。在访问其他表之前,让每个事务更新该行。这样,所有事务都以串行方式发生。请注意,InnoDB 在这种情况下,即时死锁检测算法也适用,因为序列化锁是行级锁。对于MySQL表级锁,必须使用超时方法来解决死锁。
InnoDB 的事务模型 的目标是 将 multi-versioning 和two-phase locking 的最佳属性结合起来。默认情况下 InnoDB 的查询以 “非锁定一致性读” 和 行级锁 的方式运行。
在 InnoDB 中 所有的 用户操作都包裹在事务中;如果 启用了 autocommit,那么每条语句都是一个事务;默认情况下,每创建一个session,autocommit 都是启用的;如果SQL语句正确执行,那么就会自动条,否则会滚之前的操作,然后报错;
在 autocommit 情况下 如果 想把多条语句包裹在一个事务里,则需要如下格式:
1 | START TRANSACTION; |
禁用 autocommit:
1 | SET autocommit=0; |
平常开发过程中免不了对数据库的操作,并且还会有多个线程同时开启事务后对数据库进行访问,那此时不可避免就会出现多个线程之间交叉访问而导致数据的不一致,通过对数据库的隔离级别进行设置可以保证各线程数据获取的准确性。
在介绍隔离级别之前先要弄清楚数据库在并发事务下会出现的一些状态:
脏读就是一个事务读取了另外一个事务未提交的数据。
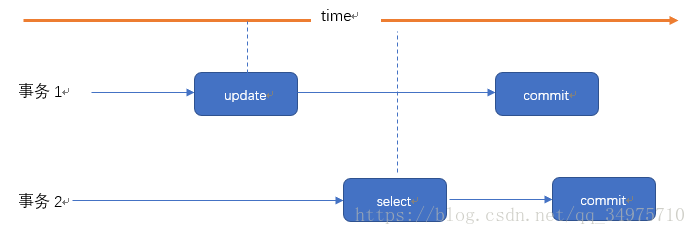
事务2读取了事务1未提交的数据。
在同一事务中,两次读取同一数据,得到内容不同
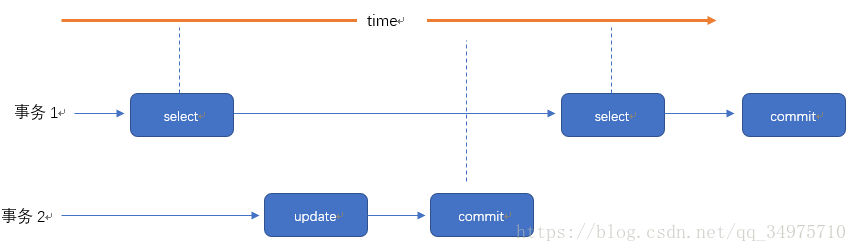
例如事务1读取了某个数据,然后事务2更新了这个数据并提交,然后事务1又来读取了一次,那这两次读取的结果就会不一样。
在一个事务的两次查询中数据记录数不一致,例如有一个事务1查询了几列数据,而事务2在此时插入了新的几列数据,事务1在接下来的查询中,就会发现有几列数据是它先前所没有的。
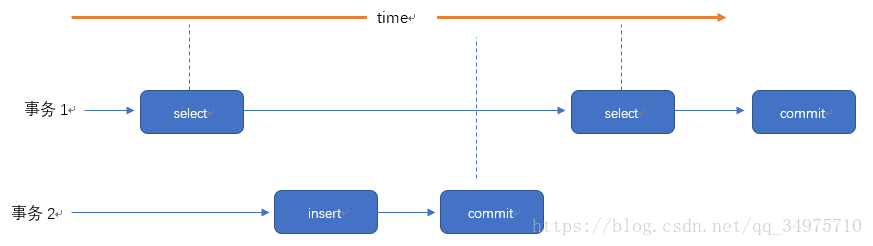
不可重复读是针对于多次读取同一条数据出现不同结果,幻读是多次读取而产生的记录数不一样
Isolation 是 ACID 中的 I;Isolation 是在多个事务同时进行更改和执行查询时,对性能与可靠性、一致性和结果再现性之间的平衡进行微调的设定。
InnoDB 提供了 4 种隔离级别:READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, 和 SERIALIZABLE。默认的 隔离级别是 REPEATABLE READ。
InnoDB 使用不同的锁策略 来实现隔离级别。REPEATABLE READ 用来操作重要的数据,保证 ACID;如果使用 READ UNCOMMITTED 或READ COMMITTED 可以降低锁的开销;SERIALIZABLE是一种比 SERIALIZABLE更严格的规则,一般用在专门的场景,比如 XA事务 或者 解决并发问题和死锁。
可以看到未提交的数据(脏读),举个例子:别人说的话你都相信了,但是可能他只是说说,并不实际做。
读取提交的数据。但是,可能多次读取的数据结果不一致(不可重复读,幻读)。用读写的观点就是:读取的行数据,可以写。
可以重复读取,但有幻读。读写观点:读取的数据行不可写,但是可以往表中新增数据。在MySQL中,其他事务新增的数据,看不到,不会产生幻读。采用多版本并发控制(MVCC)机制解决幻读问题。
可读,不可写。像java中的锁,写数据必须等待另一个事务结束。
1 | -- 1.查看当前会话隔离级别 |
设置隔离级别
1 | -- 设置当前会话隔离级别 |
参考: https://www.cnblogs.com/cjsblog/p/8365921.html
MVCC的全称是“多版本并发控制”。这项技术使得InnoDB的事务隔离级别下执行一致性读操作有了保证,换言之,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值。这是一个可以用来增强并发性的强大的技术,因为这样的一来的话查询就不用等待另一个事务释放锁。这项技术在数据库领域并不是普遍使用的。一些其它的数据库产品,以及mysql其它的存储引擎并不支持它。
网上看到大量的文章讲到MVCC都是说给每一行增加两个隐藏的字段分别表示行的创建时间以及过期时间,它们存储的并不是时间,而是事务版本号。
事实上,这种说法并不准确,严格的来讲,InnoDB会给数据库中的每一行增加三个字段,它们分别是DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID。
但是,为了理解的方便,我们可以这样去理解,索引接下来的讲解中也还是用这两个字段的方式去理解。
在InnoDB中,给每行增加两个隐藏字段来实现MVCC,一个用来记录数据行的创建时间,另一个用来记录行的过期时间(删除时间)。在实际操作中,存储的并不是时间,而是事务的版本号,每开启一个新事务,事务的版本号就会递增。
于是乎,默认的隔离级别(REPEATABLE READ)下,增删查改变成了这样:
快照读:读取的是快照版本,也就是历史版本
当前读:读取的是最新版本
普通的SELECT就是快照读,而UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATE是当前读。
在一个事务中,标准的SELECT语句是不会加锁,但是有两种情况例外。SELECT … LOCK IN SHARE MODE 和 SELECT … FOR UPDATE。
SELECT … LOCK IN SHARE MODE:给记录假设共享锁,这样一来的话,其它事务只能读不能修改,直到当前事务提交;
SELECT … FOR UPDATE:给索引记录加锁,这种情况下跟UPDATE的加锁情况是一样的;
一致性读(consistent read)意味着 InnoDB 对一个 query 展示的数据是 多版本中一个时间点的 snapshot。
如果隔离级别是REPEATABLE READ,那么在同一个事务中的所有一致性读都读的是事务中第一个这样的读读到的快照;
如果是READ COMMITTED,那么一个事务中的每一个一致性读都会读到它自己刷新的快照版本。
Consistent read(一致性读)是READ COMMITTED和REPEATABLE READ隔离级别下普通SELECT语句默认的模式。一致性读不会给它所访问的表加任何形式的锁,因此其它事务可以同时并发的修改它们。
悲观锁,正如它的名字那样,数据库总是认为别人会去修改它所要操作的数据,因此在数据库处理过程中将数据加锁。其实现依靠数据库底层。
乐观锁,如它的名字那样,总是认为别人不会去修改,只有在提交更新的时候去检查数据的状态。通常是给数据增加一个字段来标识数据的版本。
有这样三种锁我们需要了解
假设一个索引包含以下几个值:10,11,13,20。那么这个索引的next-key锁将会覆盖以下区间:
(negative infinity, 10]
(10, 11]
(11, 13]
(13, 20]
(20, positive infinity)
了解了以上概念之后,接下来具体就简单分析下REPEATABLE READ隔离级别是如何实现的
之所以说是理论分析,是因为要是实际操作证明的话我也不知道怎么去证明,毕竟作者水平实在有限。但是,这并不意味着我在此胡说八道,有官方文档为证。
这段话的大致意思是,在默认的隔离级别中,普通的SELECT用的是一致性读不加锁。而对于锁定读、UPDATE和DELETE,则需要加锁,至于加什么锁视情况而定。如果你对一个唯一索引使用了唯一的检索条件,那么只需锁定索引记录即可;如果你没有使用唯一索引作为检索条件,或者用到了索引范围扫描,那么将会使用间隙锁或者next-key锁以此来阻塞其它会话向这个范围内的间隙插入数据。
作者曾经有一个误区,认为按照前面说MVCC下的增删查改的行为就不会出现任何问题,也不会出现不可重复读和幻读。但其实是大错特错。
举个很简单的例子,假设事务A更新表中id=1的记录,而事务B也更新这条记录,并且B先提交,如果按照前面MVVC说的,事务A读取id=1的快照版本,那么它看不到B所提交的修改,此时如果直接更新的话就会覆盖B之前的修改,这就不对了,可能B和A修改的不是一个字段,但是这样一来,B的修改就丢失了,这是不允许的。
所以,在修改的时候一定不是快照读,而是当前读。
而且,前面也讲过只有普通的SELECT才是快照读,其它诸如UPDATE、删除都是当前读。修改的时候加锁这是必然的,同时为了防止幻读的出现还需要加间隙锁。
回想一下
1、利用MVCC实现一致性非锁定读,这就有保证在同一个事务中多次读取相同的数据返回的结果是一样的,解决了不可重复读的问题
2、利用Gap Locks和Next-Key可以阻止其它事务在锁定区间内插入数据,因此解决了幻读问题
综上所述,默认隔离级别的实现依赖于MVCC和锁,再具体一点是一致性读和锁。
InnoDB实现了两种标准行级锁,一种是共享锁 (shared locks,S锁),另一种是独占锁,或者叫排它锁 (exclusive locks,X锁)。
共享锁:允许 事务 持有 read 一行 的锁;
独占锁:允许 事务 持有 update 或 delete 一行的锁;
S锁
如果事务T1持有了行r上的S锁,则其他事务可以同时持有行r的S锁,但是不能对行r加X锁。
X锁
如果事务T1持有了行r上的X锁,则其他任何事务不能持有行r的X锁,必须等待T1在行r上的X锁释放。
如果事务T1在行r上保持S锁,则另一个事务T2对行r的锁的请求按如下方式处理:
X锁,必须等待其他事务对该行添加的S锁或X锁的释放。 InnoDB 支持 多颗粒度加锁,允许 行锁 和 表锁 共存。例如, LOCK TABLES ... WRITE 就是在指定表上加独占锁。为了支持多颗粒度加锁,InnoDB设计了 意向锁。意向锁 是 一种 表级锁,用来 指示 一个事务对表中的一行数据需要加 哪种类型(shared 或 exclusive)的锁。
意向锁有两种:
intention shared lock (IS)意向共享锁:表示 一个事务 倾向于 对一行数据 使用共享锁;在 transaction 获取一个 共享锁(S) 之前 必须先获得一个 IS 锁;
intention exclusive lock (IX)意向独占锁:表示 一个事务 倾向于 对一行数据 使用独占锁;在 transaction 获取一个 独占锁(X) 之前 必须先获得一个 IX 锁;
例如:SELECT ... LOCK IN SHARE MODE 使用的就是 IS 锁, SELECT ... FOR UPDATE 使用的是 IX 锁;
锁的兼容矩阵如下:
| — | 排它锁(X) | 意向排它锁(IX) | 共享锁(S) | 意向共享锁(IS) |
|---|---|---|---|---|
| 排它锁(X) | N | N | N | N |
| 意向排它锁(IX) | N | OK | N | OK |
| 共享锁(S) | N | N | OK | OK |
| 意向共享锁(IS) | N | OK | OK | OK |
按照上面的兼容性,如果不同事务之间的锁兼容,则当前加锁事务可以持有锁,如果有冲突则会等待其他事务的锁释放。
如果一个事务请求锁时,请求的锁与已经持有的锁冲突而无法获取时,互相等待就可能会产生死锁。
意向锁不会阻止除了全表锁定请求之外的任何锁请求。
意向锁的主要目的是显示事务正在锁定某行或者正意图锁定某行。
示例的基础是一个只有两列的数据库表。
1 | create database test; |
数据表test只有两列,id是主键索引,code是普通的索引(注意,一定不要是唯一索引),并初始化了两条记录,分别是(1,1),(10,10)。
这样,我们验证唯一键索引就可以使用id列,验证普通索引(非唯一键二级索引)时就使用code列。
要看到锁的情况,必须手动开启多个事务,其中一些锁的状态的查看则必须使锁处于waiting状态,这样才能在mysql的引擎状态日志中看到。
命令:
1 | show engine innodb status; |
这条命令能显示最近几个事务的状态、查询和写入情况等信息。当出现死锁时,命令能给出最近的死锁明细。
record lock 是 对 index record 加锁的一种锁。例如 SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE; 阻止其他事务 插入、更新、删除 t.c1=10 的行;
record lock 总是对 index 加锁,即使表没有定义任何索引。在这种情况下 InnoDB 会添加一个隐藏主键;
查看记录锁
开启第一个事务,不提交,测试完之后回滚。
2
3
4
5
6
7
> Query OK, 0 rows affected (0.00 sec)
>
> mysql> update test set id=2 where id=1;
> Query OK, 1 row affected (0.00 sec)
> Rows matched: 1 Changed: 1 Warnings: 0
>
事务加锁情况
2
3
4
5
6
7
8
9
10
> ...
> ------------
> TRANSACTIONS
> ------------
> ---TRANSACTION 366811, ACTIVE 690 sec
> 2 lock struct(s), heap size 1136, 1 row lock(s), undo log entries 2
> MySQL thread id 785, OS thread handle 123145432457216, query id 729076 localhost 127.0.0.1 root
> ...
>
可以看到有一行被加了锁。由之前对锁的描述可以推测出,update语句给
id=1这一行上加了一个X锁。注意:X锁广义上是一种抽象意义的排它锁,即锁一般分为
X模式和S模式,狭义上指row或者index上的锁,而Record锁是索引上的锁。
为了不修改数据,可以用select ... for update语句,加锁行为和update、delete是一样的,insert加锁机制较为复杂,后面的章节会提到。第一个事务保持原状,不要提交或者回滚,现在开启第二个事务。
2
3
4
5
> Query OK, 0 rows affected (0.00 sec)
>
> mysql> update test set id=3 where id=1;
>
执行
update时,sql语句的执行被阻塞了。查看下事务状态:
2
3
4
5
6
7
8
9
10
11
12
> ...
> ------- TRX HAS BEEN WAITING 4 SEC FOR THIS LOCK TO BE GRANTED:
> RECORD LOCKS space id 62 page no 3 n bits 72 index PRIMARY of table `test`.`test` trx id 366820 lock_mode X locks rec but not gap waiting
> Record lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 32
> 0: len 8; hex 0000000000000001; asc ;;
> 1: len 6; hex 0000000598e3; asc ;;
> 2: len 7; hex 7e000001a80896; asc ~ ;;
>
> ------------------
> ...
>
喜闻乐见,我们看到了这个锁的状态。状态标题是’事务正在等待获取锁’,描述中的
lock_mode X locks rec but not gap就是本章节中的record记录锁,直译一下’X锁模式锁住了记录’。后面还有一句but not gap意思是只对record本身加锁,并不对间隙加锁,间隙锁的叙述见下一个章节。
gap lock 作用在索引记录之间的间隔,又或者作用在第一个索引之前,最后一个索引之后的间隙。不包括索引本身。例如,SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE;这条语句阻止其他事务插入10和20之间的数字,无论这个数字是否存在。gap lock 是性能和并发权衡的产物,只存在于部分事务隔离级别。
SELECT * FROM child WHERE id = 100;
child[100][x] ~ child[100][y] 之间的记录; 简单来说就是 gap lock 锁定的是一个范围(0~N条记录),而不是单条记录;
InnoDB中的Gap锁是“纯粹的抑制性锁”,这意味着它们的唯一目的是防止其他事务插入到Gap中。间隙锁可以共存。一个事务所采取的间隙锁并不会阻止另一个事务对同一间隙采取间隙锁。共享锁和独占锁之间没有区别。它们彼此不冲突,并且执行相同的功能。
禁用gap lock:
READ COMMITTED ;查看间隙锁
按照官方文档,
where子句查询条件是唯一键且指定了值时,只有record锁,没有gap锁。
如果where语句指定了范围,gap锁是存在的。
这里只测试验证一下当指定非唯一键索引的时候,gap锁的位置,按照文档的说法,会锁定当前索引及索引之前的间隙。(指定了非唯一键索引,例如code=10,间隙锁仍然存在\)开启第一个事务,锁定一条非唯一的普通索引记录
2
3
4
5
6
7
8
9
10
11
>Query OK, 0 rows affected (0.00 sec)
>
>mysql> select * from test where code = 10 for update;
>+----+------+
>| id | code |
>+----+------+
>| 10 | 10 |
>+----+------+
>1 row in set (0.00 sec)
>
由于预存了两条数据,row(1,1)和row(10,10),此时这个间隙应该是`1。我们先插入row(2,2)来验证下gap锁的存在,再插入row(0,0)来验证gap的边界。
按照间隙锁的官方文档定义,
select * from test where code = 10 for update;会锁定code=10这个索引,并且会锁定code<10的间隙。开启第二个事务,在
code=10之前的间隙中插入一条数据,看下这条数据是否能够插入。
2
3
4
5
>Query OK, 0 rows affected (0.00 sec)
>
>mysql> insert into test values(2,2);
>
插入的时候,执行被阻塞,查看引擎状态:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
>...
>---TRANSACTION 366864, ACTIVE 5 sec inserting
>mysql tables in use 1, locked 1
>LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s), undo log entries 1
>MySQL thread id 793, OS thread handle 123145434963968, query id 730065 localhost 127.0.0.1 root update
>insert into test values(2,2)
>------- TRX HAS BEEN WAITING 5 SEC FOR THIS LOCK TO BE GRANTED:
>RECORD LOCKS space id 63 page no 4 n bits 72 index code of table `test`.`test` trx id 366864 lock_mode X locks gap before rec insert intention waiting
>Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
> 0: len 8; hex 800000000000000a; asc ;;
> 1: len 8; hex 000000000000000a; asc ;;
>
>------------------
>...
>
插入语句被阻塞了,
lock_mode X locks gap before rec,由于第一个事务锁住了1到10之间的gap,需要等待获取锁之后才能插入。如果再开启一个事务,插入(0,0)
2
3
4
>mysql> insert into test values(0,0);
>Query OK, 1 row affected (0.00 sec)
>
可以看到:指定的非唯一建索引的gap锁的边界是当前索引到上一个索引之间的gap\。
最后给出锁定区间的示例,首先插入一条记录(5,5)
2
3
>Query OK, 1 row affected (0.00 sec)
>
开启第一个事务:
2
3
4
5
6
7
8
9
10
11
12
13
>Query OK, 0 rows affected (0.00 sec)
>
>mysql> select * from test where code between 1 and 10 for update;
>+----+------+
>| id | code |
>+----+------+
>| 1 | 1 |
>| 5 | 5 |
>| 10 | 10 |
>+----+------+
>3 rows in set (0.00 sec)
>
第二个事务,试图去更新code=5的行:
2
3
4
5
>Query OK, 0 rows affected (0.00 sec)
>
>mysql> update test set code=4 where code=5;
>
执行到这里,如果第一个事务不提交或者回滚的话,第二个事务一直等待直至mysql中设定的超时时间。
Next-key 锁实际上是Record锁和gap锁的组合。Next-key锁是在 下一个索引记录本身 和 索引之前的gap 加上S锁或是X锁(如果是读就加上S锁,如果是写就加X锁)。
默认情况下,InnoDB的事务隔离级别为RR,系统参数 innodb_locks_unsafe_for_binlog 的值为false。InnoDB使用next-key锁对索引进行扫描和搜索,这样就读取不到幻象行,避免了幻读的发生。
幻读是指在同一事务下,连续执行两次同样的SQL语句,第二次的SQL语句可能会返回之前不存在的行。
当查询的索引是唯一索引时,Next-key lock会进行优化,降级为Record Lock,此时Next-key lock仅仅作用在索引本身,而不会作用于gap和下一个索引上。
查看Next-key锁
Next-key锁的作用范围
如上述例子,数据表
test初始化了row(1,1),row(10,10),然后插入了row(5,5)。数据表如下:
2
3
4
5
6
7
8
9
10
> +----+------+
> | id | code |
> +----+------+
> | 1 | 1 |
> | 5 | 5 |
> | 10 | 10 |
> +----+------+
> 3 rows in set (0.00 sec)
>
由于
id是主键、唯一索引,mysql会做优化,因此使用code这个非唯一键的二级索引来举例说明。对于
code,可能的next-key锁的范围是:
2
3
4
5
> (1,5]
> (5,10]
> (10,+∞)
>
开启第一个事务,在
code=5的索引上请求更新:
2
3
4
5
6
7
8
9
10
11
> Query OK, 0 rows affected (0.00 sec)
>
> mysql> select * from test where code=5 for update;
> +----+------+
> | id | code |
> +----+------+
> | 5 | 5 |
> +----+------+
> 1 row in set (8.81 sec)
>
之前在gap锁的章节中介绍了,
code=5 for update会在code=5的索引上加一个record锁,还会在1<gap<5的间隙上加gap锁。现在不再验证,直接插入一条(8,8):
2
3
4
> Query OK, 0 rows affected (0.00 sec)
> mysql> insert into test values(8,8);
>
insert处于等待执行的状态,这就是next-key锁生效而导致的结果。第一个事务,锁定了区间(1,5],由于RR的隔离级别下next-key锁处于开启生效状态,又锁定了(5,10]区间。所以插入SQL语句的执行被阻塞。解释:在这种情况下,被锁定的区域是
code=5前一个索引到它的间隙,以及next-key的区域。code=5 for update对索引的锁定用区间表示,gap锁锁定了(1,5),record锁锁定了{5}索引记录,next-key锁锁住了(5,10],也就是说整个(1,10]的区间被锁定了。由于是for update,所以这里的锁都是X锁,因此阻止了其他事务中带有冲突锁定的操作执行。如果我们在第一个事务中,执行了
code > 8 for update,在扫描过程中,找到了code=10,此时就会锁住10之前的间隙(5到10之间的gap),10本身(record),和10之后的间隙(next-key)。此时另一个事务插入(6,6),(9,9)和(11,11)都是不被允许的,只有在前一个索引5及5之前的索引和间隙才能执行插入(更新和删除也会被阻塞)。
插入意向锁在行插入之前由INSERT设置一种间隙锁,是意向排它锁的一种。
在多事务同时写入不同数据至同一索引间隙的时,不会发生锁等待,事务之间互相不影响其他事务的完成,这和间隙锁的定义是一致的。
假设一个记录索引包含4和7,其他不同的事务分别插入5和6,此时只要行不冲突,插入意向锁不会互相等待,可以直接获取。参照锁兼容/冲突矩阵。
插入意向锁的例子不再列举,可以查看gap锁的第一个例子。
auto-inc lock 是一种特殊的表级锁。如果一个事务正在向表中插入值,那么任何其他事务都必须等待,以便由第一个事务插入的行接收连续的主键值。
我们一般把主键设置为AUTO_INCREMENT的列,默认情况下这个字段的值为0,InnoDB会在AUTO_INCREMENT修饰下的数据列所关联的索引末尾设置独占锁。在访问自增计数器时,InnoDB使用自增锁,但是锁定仅仅持续到当前SQL语句的末尾,而不是整个事务的结束,毕竟自增锁是表级别的锁,如果长期锁定会大大降低数据库的性能。由于是表锁,在使用期间,其他会话无法插入表中。
如果一个SQL语句要对二级索引(非主键索引)设置X模式的Record锁,InnoDB还会检索出相应的聚簇索引(主键索引)并对它们设置锁定。
SELECT ... FROM是快照读取,除了SERIALIZABLE的事务隔离级别,该SQL语句执行时不会加任何锁。
SERIALIZABLE级别下,SELECT语句的执行会在遇到的索引记录上设置S模式的next-key锁。但是对于唯一索引,只锁定索引记录,而不会锁定gap。
S锁读取(SELECT ... LOCK IN SHARE MODE),X锁读取(SELECT ... FOR UPDATE)、更新UPDATE和删除DELETE这四类语句,采用的锁取决于搜索条件中使用的索引类型。
UPDATE ... WHERE ...在搜索遇到的每条记录上设置一个独占的next-key锁,如果是唯一索引只锁定记录。
当UPDATE修改聚簇索引时,将对受影响的二级索引采用隐式锁,隐式锁是在索引中对二级索引的记录逻辑加锁,实际上不产生锁对象,不占用内存空间。
例如
update test set code=100 where id=10;执行的时候code=10的索引(code是二级索引,见文中给出的建表语句)会被加隐式锁,只有隐式锁产生冲突时才会变成显式锁(如S锁、X锁)。即此时另一个事务也去更新id=10这条记录,隐式锁就会升级为显示锁。
这样做的好处是降低了锁的开销。
UPDATE可能会导致新的普通索引的插入。当新的索引插入之前,会首先执行一次重复索引检查。在重复检查和插入时,更新操作会对受影响的二级索引记录采用共享锁定(S锁)。
DELETE FROM ... WHERE ...在搜索遇到的每条记录上设置一个独占的next-key锁,如果是唯一索引只锁定记录。
INSERT区别于UPDATE系列单独列出,是因为它的处理方式较为特别。
插入行之前,会设置一种插入意向锁,插入意向锁表示插入的意图。如果其它事务在 要插入的位置 上设置了X锁,则无法获取插入意向锁,插入操作也因此阻塞。
INSERT在插入的行上设置X锁。该锁是一个Record锁,并不是next-key锁,即只锁定记录本身,不锁定间隙,因此不会阻止其他 session 在这行记录前的间隙中插入新的记录。
死锁是指由于每个事务都持有对方需要的锁而无法进行其他事务的情况。因为这两个事务都在等待资源变得可用,所以都不会释放它持有的锁。
该示例涉及两个客户端A和B。
首先,客户端A创建一个包含一行的表,然后开始事务。在事务中,A通过S在共享模式下选择该行来获得对该行的 锁定:
1 | CREATE TABLE t (i INT) ENGINE = InnoDB; |
接下来,客户端B开始事务并尝试从表中删除该行:
1 | START TRANSACTION; |
删除操作需要一个X锁。无法授予该S锁,因为它与客户端A持有的锁不兼容 ,因此该请求进入针对行和客户端B块的锁请求队列中。
最后,客户端A还尝试从表中删除该行:
1 | DELETE FROM t WHERE i = 1; |
此处发生死锁是因为客户端A需要 X锁才能删除该行。但是,不能授予该锁定请求,因为客户端B已经有一个X锁定请求,并且正在等待客户端A释放其S锁定。由于B事先要求锁,所以SA持有的锁也不能 升级 X为X锁。结果, InnoDB为其中一个客户端生成错误并释放其锁。客户端返回此错误:
1 | ERROR 1213 (40001): Deadlock found when trying to get lock; |
届时,可以授予对另一个客户端的锁定请求,并从表中删除该行。
InnoDB自动检测事务 死锁并回滚一个或多个事务以打破死锁。 InnoDB尝试选择要回滚的小事务,其中事务的大小由插入,更新或删除的行数确定。
如果死锁无法检测,通过设置 innodb_lock_wait_timeout 来解决;
如果 一个事务被完整的会滚,那么它所持有的所有锁都会被释放;但如果由于出错仅仅一条sql被会滚,那么某些锁可能不会被释放;这是因为 InnoDB存储行锁的格式 无法确定后续的锁会被哪些sql持有;
要查看InnoDB用户事务中的最后一个死锁,请使用SHOW ENGINE INNODB STATUS命令。
如果频繁出现死锁,则说明事务结构或应用程序错误处理存在问题,请在innodb_print_all_deadlocks 启用该设置的情况下运行,以 将有关所有死锁的信息打印到 mysqld错误日志中
InnoDB使用自动行级锁定。即使在仅插入或 删除 单行的事务中,也可能会遇到死锁。这是因为这些操作并不是真正的“ 原子 ”操作。它们会自动对插入或删除的行的(可能是多个)索引记录设置锁定。
您可以使用以下技术来处理死锁并减少发生死锁的可能性:
在任何时候,发出 SHOW ENGINE INNODB STATUS命令以确定最近死锁的原因。这可以帮助您调整应用程序以避免死锁。
如果频繁出现死锁警告引起关注,请通过启用innodb_print_all_deadlocks 配置选项来收集更广泛的调试信息 。有关每个死锁的信息,而不仅仅是最新的死锁,都记录在MySQL 错误日志中。完成调试后,请禁用此选项。
如果由于死锁而失败,请始终准备重新发出事务。死锁并不危险。请再试一次。
保持交易小巧且持续时间短,以使交易不易发生冲突。
进行一系列相关更改后立即提交事务,以减少冲突的发生。特别是,不要长时间未提交事务而使交互式 mysql会话保持打开状态。
如果您使用锁定读取(SELECT ... FOR UPDATE或 SELECT ... LOCK IN SHARE MODE),请尝试使用较低的隔离级别,例如 READ COMMITTED。
修改事务中的多个表或同一表中的不同行集时,每次都要以一致的顺序执行这些操作。然后,事务形成定义明确的队列,并且不会死锁。例如,组织数据库操作到功能在应用程序中,或调用存储程序,而不是编码的多个相似序列 INSERT,UPDATE以及 DELETE在不同的地方语句。
将选择好的索引添加到表中。然后,您的查询需要扫描更少的索引记录,并因此设置更少的锁。使用EXPLAIN SELECT以确定哪些索引MySQL认为最适合您的查询。
使用较少的锁定。如果你能负担得起,以允许 SELECT从一个旧的快照返回数据,不要添加条款FOR UPDATE或LOCK IN SHARE MODE给它。在READ COMMITTED这里使用隔离级别是件好事,因为同一事务中的每个一致性读取均从其自己的新快照读取。
如果没有其他帮助,请使用表级锁序列化事务。LOCK TABLES与事务表(例如InnoDB 表)一起使用的正确方法 是,以SET autocommit = 0(not START TRANSACTION)后跟来开始事务,直到明确提交事务后才LOCK TABLES调用 UNLOCK TABLES。例如,如果您需要写表 t1和从表中读取数据 t2,则可以执行以下操作:
1 | SET autocommit=0; |
表级锁可防止对表的并发更新,从而避免死锁,但代价是对繁忙系统的响应速度较慢。
序列化事务的另一种方法是创建一个仅包含一行的辅助“ 信号量 ”表。在访问其他表之前,让每个事务更新该行。这样,所有事务都以串行方式发生。请注意,InnoDB 在这种情况下,即时死锁检测算法也适用,因为序列化锁是行级锁。对于MySQL表级锁,必须使用超时方法来解决死锁。
InnoDB 的事务模型 的目标是 将 multi-versioning 和two-phase locking 的最佳属性结合起来。默认情况下 InnoDB 的查询以 “非锁定一致性读” 和 行级锁 的方式运行。
在 InnoDB 中 所有的 用户操作都包裹在事务中;如果 启用了 autocommit,那么每条语句都是一个事务;默认情况下,每创建一个session,autocommit 都是启用的;如果SQL语句正确执行,那么就会自动条,否则会滚之前的操作,然后报错;
在 autocommit 情况下 如果 想把多条语句包裹在一个事务里,则需要如下格式:
1 | START TRANSACTION; |
禁用 autocommit:
1 | SET autocommit=0; |
平常开发过程中免不了对数据库的操作,并且还会有多个线程同时开启事务后对数据库进行访问,那此时不可避免就会出现多个线程之间交叉访问而导致数据的不一致,通过对数据库的隔离级别进行设置可以保证各线程数据获取的准确性。
在介绍隔离级别之前先要弄清楚数据库在并发事务下会出现的一些状态:
脏读就是一个事务读取了另外一个事务未提交的数据。
事务2读取了事务1未提交的数据。
在同一事务中,两次读取同一数据,得到内容不同
例如事务1读取了某个数据,然后事务2更新了这个数据并提交,然后事务1又来读取了一次,那这两次读取的结果就会不一样。
在一个事务的两次查询中数据记录数不一致,例如有一个事务1查询了几列数据,而事务2在此时插入了新的几列数据,事务1在接下来的查询中,就会发现有几列数据是它先前所没有的。
不可重复读是针对于多次读取同一条数据出现不同结果,幻读是多次读取而产生的记录数不一样
Isolation 是 ACID 中的 I;Isolation 是在多个事务同时进行更改和执行查询时,对性能与可靠性、一致性和结果再现性之间的平衡进行微调的设定。
InnoDB 提供了 4 种隔离级别:READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, 和 SERIALIZABLE。默认的 隔离级别是 REPEATABLE READ。
InnoDB 使用不同的锁策略 来实现隔离级别。REPEATABLE READ 用来操作重要的数据,保证 ACID;如果使用 READ UNCOMMITTED 或READ COMMITTED 可以降低锁的开销;SERIALIZABLE是一种比 SERIALIZABLE更严格的规则,一般用在专门的场景,比如 XA事务 或者 解决并发问题和死锁。
可以看到未提交的数据(脏读),举个例子:别人说的话你都相信了,但是可能他只是说说,并不实际做。
读取提交的数据。但是,可能多次读取的数据结果不一致(不可重复读,幻读)。用读写的观点就是:读取的行数据,可以写。
可以重复读取,但有幻读。读写观点:读取的数据行不可写,但是可以往表中新增数据。在MySQL中,其他事务新增的数据,看不到,不会产生幻读。采用多版本并发控制(MVCC)机制解决幻读问题。
可读,不可写。像java中的锁,写数据必须等待另一个事务结束。
1 | -- 1.查看当前会话隔离级别 |
设置隔离级别
1 | -- 设置当前会话隔离级别 |
参考: https://www.cnblogs.com/cjsblog/p/8365921.html
MVCC的全称是“多版本并发控制”。这项技术使得InnoDB的事务隔离级别下执行一致性读操作有了保证,换言之,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值。这是一个可以用来增强并发性的强大的技术,因为这样的一来的话查询就不用等待另一个事务释放锁。这项技术在数据库领域并不是普遍使用的。一些其它的数据库产品,以及mysql其它的存储引擎并不支持它。
网上看到大量的文章讲到MVCC都是说给每一行增加两个隐藏的字段分别表示行的创建时间以及过期时间,它们存储的并不是时间,而是事务版本号。
事实上,这种说法并不准确,严格的来讲,InnoDB会给数据库中的每一行增加三个字段,它们分别是DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID。
但是,为了理解的方便,我们可以这样去理解,索引接下来的讲解中也还是用这两个字段的方式去理解。
在InnoDB中,给每行增加两个隐藏字段来实现MVCC,一个用来记录数据行的创建时间,另一个用来记录行的过期时间(删除时间)。在实际操作中,存储的并不是时间,而是事务的版本号,每开启一个新事务,事务的版本号就会递增。
于是乎,默认的隔离级别(REPEATABLE READ)下,增删查改变成了这样:
快照读:读取的是快照版本,也就是历史版本
当前读:读取的是最新版本
普通的SELECT就是快照读,而UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATE是当前读。
在一个事务中,标准的SELECT语句是不会加锁,但是有两种情况例外。SELECT … LOCK IN SHARE MODE 和 SELECT … FOR UPDATE。
SELECT … LOCK IN SHARE MODE:给记录假设共享锁,这样一来的话,其它事务只能读不能修改,直到当前事务提交;
SELECT … FOR UPDATE:给索引记录加锁,这种情况下跟UPDATE的加锁情况是一样的;
一致性读(consistent read)意味着 InnoDB 对一个 query 展示的数据是 多版本中一个时间点的 snapshot。
如果隔离级别是REPEATABLE READ,那么在同一个事务中的所有一致性读都读的是事务中第一个这样的读读到的快照;
如果是READ COMMITTED,那么一个事务中的每一个一致性读都会读到它自己刷新的快照版本。
Consistent read(一致性读)是READ COMMITTED和REPEATABLE READ隔离级别下普通SELECT语句默认的模式。一致性读不会给它所访问的表加任何形式的锁,因此其它事务可以同时并发的修改它们。
悲观锁,正如它的名字那样,数据库总是认为别人会去修改它所要操作的数据,因此在数据库处理过程中将数据加锁。其实现依靠数据库底层。
乐观锁,如它的名字那样,总是认为别人不会去修改,只有在提交更新的时候去检查数据的状态。通常是给数据增加一个字段来标识数据的版本。
有这样三种锁我们需要了解
假设一个索引包含以下几个值:10,11,13,20。那么这个索引的next-key锁将会覆盖以下区间:
(negative infinity, 10]
(10, 11]
(11, 13]
(13, 20]
(20, positive infinity)
了解了以上概念之后,接下来具体就简单分析下REPEATABLE READ隔离级别是如何实现的
之所以说是理论分析,是因为要是实际操作证明的话我也不知道怎么去证明,毕竟作者水平实在有限。但是,这并不意味着我在此胡说八道,有官方文档为证。
这段话的大致意思是,在默认的隔离级别中,普通的SELECT用的是一致性读不加锁。而对于锁定读、UPDATE和DELETE,则需要加锁,至于加什么锁视情况而定。如果你对一个唯一索引使用了唯一的检索条件,那么只需锁定索引记录即可;如果你没有使用唯一索引作为检索条件,或者用到了索引范围扫描,那么将会使用间隙锁或者next-key锁以此来阻塞其它会话向这个范围内的间隙插入数据。
作者曾经有一个误区,认为按照前面说MVCC下的增删查改的行为就不会出现任何问题,也不会出现不可重复读和幻读。但其实是大错特错。
举个很简单的例子,假设事务A更新表中id=1的记录,而事务B也更新这条记录,并且B先提交,如果按照前面MVVC说的,事务A读取id=1的快照版本,那么它看不到B所提交的修改,此时如果直接更新的话就会覆盖B之前的修改,这就不对了,可能B和A修改的不是一个字段,但是这样一来,B的修改就丢失了,这是不允许的。
所以,在修改的时候一定不是快照读,而是当前读。
而且,前面也讲过只有普通的SELECT才是快照读,其它诸如UPDATE、删除都是当前读。修改的时候加锁这是必然的,同时为了防止幻读的出现还需要加间隙锁。
回想一下
1、利用MVCC实现一致性非锁定读,这就有保证在同一个事务中多次读取相同的数据返回的结果是一样的,解决了不可重复读的问题
2、利用Gap Locks和Next-Key可以阻止其它事务在锁定区间内插入数据,因此解决了幻读问题
综上所述,默认隔离级别的实现依赖于MVCC和锁,再具体一点是一致性读和锁。
Netty 实现了 Reactor 模型,核心是 Selector;
Netty 的 Selector 底层是基于 JDK 的 Selector 实现的,依赖于 操作系统的 NIO实现;
1 | public static SelectorProvider provider() { |
下载 openjdk-8 的源码
搜索 SelectorProvider 即可发现,不同的操作系统 有不同的 DefaultSelectorProvider 实现:
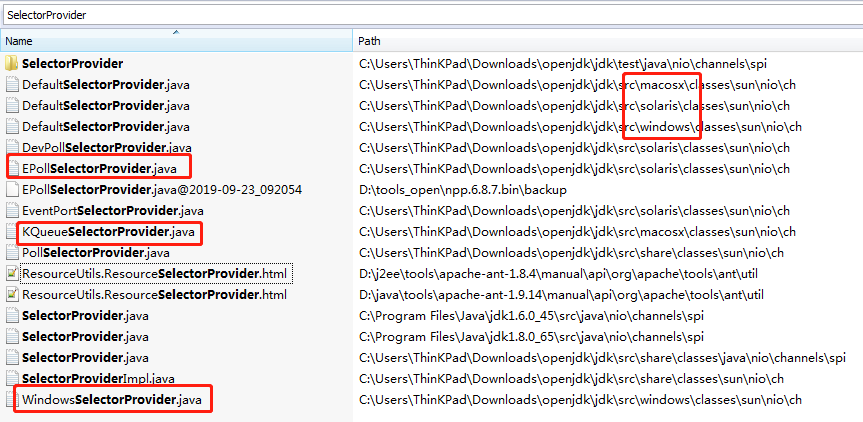
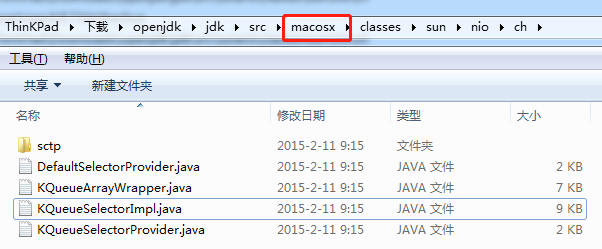
DefaultSelectorProvider 定义 封装:
1 | public class DefaultSelectorProvider { |
KQueueSelectorProvider 定义 kqueue 实现;
KQueueSelectorImpl 定义 kqueue 的实现逻辑;
KQueueArrayWrapper 真正通过 jni 调用 操作系统实现 kqueue;
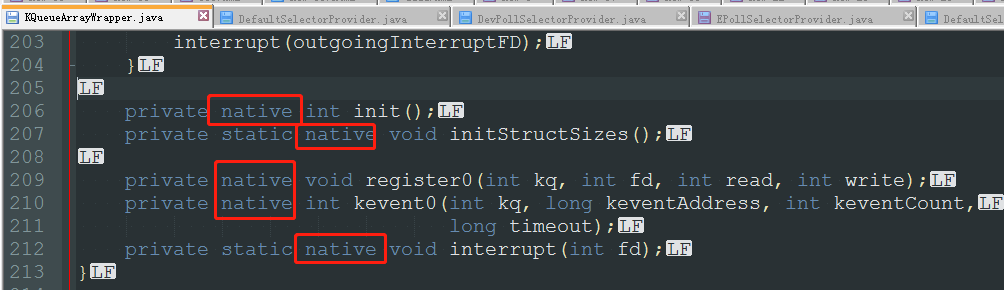
可以看到NIO只有 poll
1 | public class DefaultSelectorProvider { |
可以看到如果 操作系统是 SunOS 下,则调用 DevPollSelectorProvider,否则调用 EPollSelectorProvider, 如果不能确定,默认调用 PollSelectorProvider;
可以看到 EPoll 的实现也是 jni 调用系统实现

关于IO的最小单位:
1、数据库IO的最小单位是16K(MySQL默认,oracle是8K)
2、文件系统IO的最小单位是4K(也有1K的)
3、磁盘IO的最小单位是512字节
因此,存在IO写入导致page损坏的风险(写入了一部分):
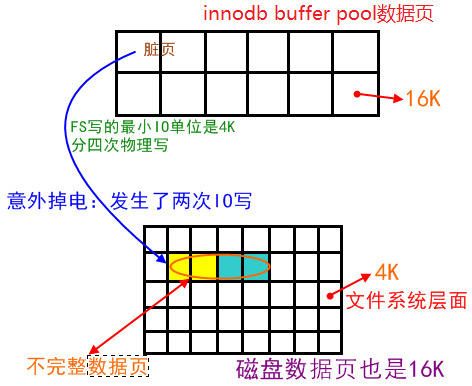
提高innodb的可靠性,用来解决部分写失败(partial page write页断裂)。
一个数据页的大小是16K,假设在把内存中的脏页写到数据库的时候,写了2K突然掉电,也就是说前2K数据是新的,后14K是旧的,那么磁盘数据库这个数据页就是不完整的,是一个坏掉的数据页。redo只能加上旧、校检完整的数据页恢复一个脏块,不能修复坏掉的数据页,所以这个数据就丢失了,可能会造成数据不一致,所以需要double write。
当数据库正在从内存向磁盘写一个数据页是,数据库宕机,从而导致这个页只写了部分数据,这就是部分写失效,它会导致数据丢失。这时是无法通过重做日志恢复的,因为重做日志记录的是对页的物理修改,如果页本身已经损坏,重做日志也无能为力。

doublewrite由两部分组成,一部分为内存中的 doublewrite buffer,其大小为2MB,另一部分是磁盘上共享表空间(ibdata x)中连续的128个页,即2个区(extent),大小也是2M。
1、当一系列机制触发数据缓冲池中的脏页刷新时,并不直接写入磁盘数据文件中,而是先拷贝至内存中的doublewrite buffer中;
2、接着从两次写缓冲区分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1MB;
3、待第二步完成后,再将doublewrite buffer中的脏页数据写入实际的各个表空间文件(离散写);(脏页数据固化后,即进行标记对应doublewrite数据可覆盖)
如果操作系统在将页写入磁盘的过程中发生崩溃,在恢复过程中,innodb存储引擎可以从共享表空间的doublewrite中找到该页的一个最近的副本,将其复制到表空间文件,再应用redo log,就完成了恢复过程。
因为有副本所以也不担心表空间中数据页是否损坏。
Q:为什么log write不需要doublewrite的支持?
A:因为 redo log 写入的单位就是512字节,也就是磁盘IO的最小单位,所以无所谓数据损坏。
1、double write是一个buffer, 但其实它是开在物理文件上的一个buffer, 其实也就是file, 所以它会导致系统有更多的fsync操作, 而硬盘的fsync性能是很慢的, 所以它会降低mysql的整体性能。
2、但是,doublewrite buffer写入磁盘共享表空间这个过程是连续存储,是顺序写,性能非常高,(约占写的%10),牺牲一点写性能来保证数据页的完整还是很有必要的。
1 | show global status like '%dblwr%'; |
关注点:Innodb_dblwr_pages_written / Innodb_dblwr_writes
开启doublewrite后,每次脏页刷新必须要先写doublewrite,而doublewrite存在于磁盘上的是两个连续的区,每个区由连续的页组成,一般情况下一个区最多有64个页,所以一次IO写入应该可以最多写64个页。
而根据以上系统Innodb_dblwr_pages_written与Innodb_dblwr_writes的比例来看,大概在3左右,远远还没到64(如果约等于64,那么说明系统的写压力非常大,有大量的脏页要往磁盘上写),所以从这个角度也可以看出,系统写入压力并不高。
1、海量DML
2、不惧怕数据损坏和丢失
3、系统写负载成为主要负载
1 | show variables like '%double%'; |
作为InnoDB的一个关键特性,doublewrite功能默认是开启的,但是在上述特殊的一些场景也可以视情况关闭,来提高数据库写性能。静态参数,配置文件修改,重启数据库。
4、为什么没有把double write里面的数据写到data page里面呢?
1、double write里面的数据是连续的,如果直接写到data page里面,而data page的页又是离散的,写入会很慢。
2、double write里面的数据没有办法被及时的覆盖掉,导致double write的压力很大;短时间内可能会出现double write溢出的情况。
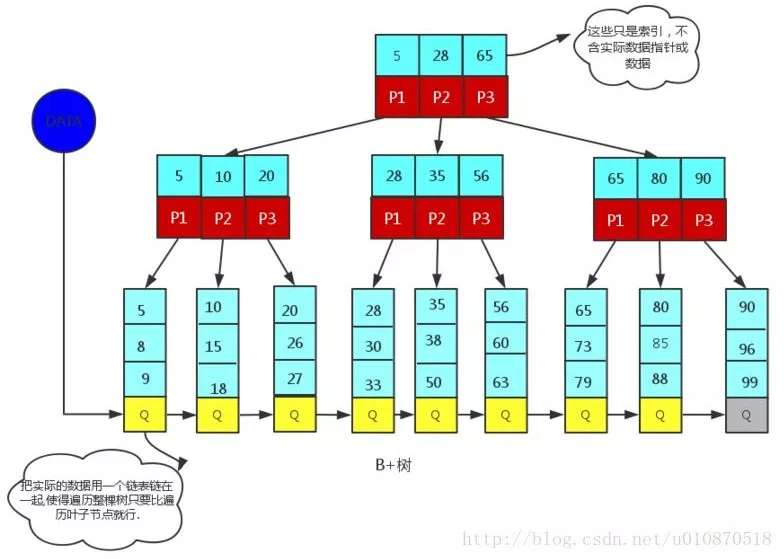
B+树是应文件系统所需而产生的一种B树的变形树(文件的目录一级一级索引,只有最底层的叶子节点(文件)保存数据)非叶子节点只保存索引,不保存实际的数据,数据都保存在叶子节点中,这不就是文件系统文件的查找吗?
我们就举个文件查找的例子:有3个文件夹a、b、c, a包含b,b包含c,一个文件yang.c,a、b、c就是索引(存储在非叶子节点), a、b、c只是要找到的yang.c的key,而实际的数据yang.c存储在叶子节点上。
所有的非叶子节点都可以看成索引部分!
(下面提到的都是和B树不相同的性质)
1、非叶子节点的子树指针与关键字个数相同;
2、非叶子节点的子树指针p[i],指向关键字值属于[k[i],k[i+1]]的子树.(B树是开区间,也就是说B树不允许关键字重复, B+树允许重复);
3、为所有叶子节点增加一个链指针;
4、所有关键字都在叶子节点出现(稠密索引). (且链表中的关键字恰好是有序的);
5、非叶子节点相当于是叶子节点的索引(稀疏索引),叶子节点相当于是存储(关键字)数据的数据层;
6、更适合于文件系统;
索引组织表 (index organized table, IOT) 就是 数据存储在一个索引结构中的表。存储在堆中的表是无组织的 (也就是说,只要有可用的空间,数据可以放在任何地方),IOT中的数据则按主键存储和排序。对你的应用来说,IOT表和一个“常规”表并无二致。
索引组织表的数据按主键排序手段被存储在B-树索引中,除了存储主键列值外还存储非键列的值。普通索引只存储索引列,而索引组织表则存储表的所有列的值。
` IOT`有什么意义呢?使用堆组织表时,我们必须为表和表主键上的索引分别留出空间。而IOT不存在主键的空间开销,因为索引就是数据,数据就是索引,二者已经合二为一。但是,IOT带来的好处并不止于节约了磁盘空间的占用,更重要的是大幅度降低了I/O,减少了访问缓冲区缓存(尽管从缓冲区缓存获取数据比从硬盘读要快得多,但缓冲区缓存并不免费,而且也绝对不是廉价的。每个缓冲区缓存获取都需要缓冲区缓存的多个闩,而闩是串行化设备,会限制应用的扩展能力) 1、完全由主键组成的表。这样的表如果采用堆组织表,则表本身完全是多余的开销,因为所有的数据全部同样也保存在索引里,此时,堆表是没用的。
2、代码查找表。如果你只会通过一个主键来访问一个表,这个表就非常适合实现为IOT.
3、如果你想保证数据存储在某个位置上,或者希望数据以某种特定的顺序物理存储,IOT就是一种合适的结构。
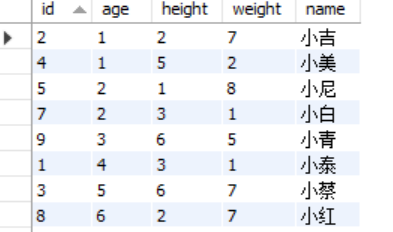
1 | create table user( |
相信只要入门数据库的同学都可以理解这个语句,我们也将从这个最简单的表开始,一步步地理解MySQL的索引结构。
首先,我们往这个表中插入一些数据。
1 | INSERT INTO user(id,age,height,weight,name)VALUES(2,1,2,7,'小吉'); |
我们来查一下,看看这些数据是否已经放入表中。
1 | mysql> select * from user; |
可以看到,数据已经完整地放到了我们创建的user表中。
但是不知道大家发现了什么没有,好像发生了一件非常诡异的事情,我们插入的数据好像乱序了…
MySQL好像悄悄的给我们按照id排了个序。
为什么会出现MySQL在我们没有显式排序的情况下,默默帮我们排了序呢?它是在什么时候进行排序的?
不知道大家毕业多长时间了,作为一个刚学完操作系统不久的学渣,页的概念依旧在脑中还没有变凉。其实MySQL中也有类似页的逻辑存储单位,听我慢慢道来。
在操作系统的概念中,当我们往磁盘中取数据,假设要取出的数据的大小是1KB,但是操作系统并不会只取出这1kb的数据,而是会取出4KB的数据,因为操作系统的一个页表项的大小是4KB。那为什么我们只需要1KB的数据,但是操作系统要取出4KB的数据呢?
这就涉及到一个程序局部性的概念,大概就是“一个程序在访问了一条数据之后,在之后会有极大的可能再次访问这条数据和访问这条数据的相邻数据”,所以索性直接加载4KB的数据到内存中,下次要访问这一页的数据时,直接从内存中找,可以减少磁盘IO次数,我们知道,磁盘IO是影响程序性能主要的因素,因为磁盘IO和内存IO的速度是不可同日而语的。
或许看完上面那一大段描述,还是有些抽象,所以我们索性回到数据库层面中,重新理解页的概念。
抛开所有东西不谈,假设还是我们刚才插入的那些数据,我们现在要找id = 5的数据,依照最原始的方式,我们一定会想到的就是——遍历,没错,这也是我们刚开始学计算机的时候最常用的寻找数据的方式。那么我们就来看看,以遍历的方式,我们找到id=5的数据,需要经历几次磁盘IO。
首先,我们得先从id=1的数据开始读起,然后判断是否是我们需要的数据,如果不是,就再取id=2的数据,再进行判断,循环往复。毋庸置疑,在MySQL帮我们排好序之后,我们需要经历五次磁盘IO,才能将5号数据找到并读出来。
那么我们再来看看引入页的概念之后,我们是如何读数据的。
在引入页的概念之后,MySQL会将多条数据存在一个叫“页”的数据结构中,当MySQL读取id=1的数据时,会将id=1数据所在的页整页读到内存中,然后在内存中进行遍历判断,由于内存的IO速度比磁盘高很多,所以相对于磁盘IO,几乎可以忽略不计,那么我们来看看这样读取数据我们需要经历几次磁盘IO(假设每一页可以存4条数据)。
那么我们第一次会读取id=1的数据,并且将id=1到id=4的数据全部读到内存中,这是第一次磁盘IO,第二次将读取id=5的数据到内存中,这是第二次磁盘IO。所以我们只需要经历2次磁盘IO就可以找到id=5的这条数据。
但其实,在MySQL的InnoDb引擎中,页的大小是16KB,是操作系统的4倍,而int类型的数据是4个字节,其它类型的数据的字节数通常也在4000字节以内,所以一页是可以存放很多很多条数据的,而MySQL的数据正是以页为基本单位组合而成的。
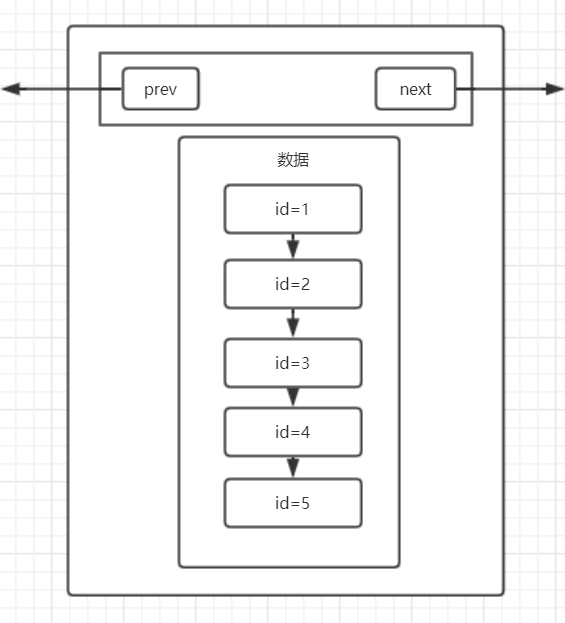
上图就是我们目前为止所理解的页的结构,他包含我们的多条数据,另外,MySQL的数据以页组成,那么它有指向下一页的指针和指向上一页的指针。
那么说到这里,其实可以回答第一个问题了,MySQL实际上就是在我们插入数据的时候,就帮我们在页中排好了序,至于为什么要排序,这里先卖个关子,接着往下看。
上文中我们提了一个问题,为什么数据库在插入数据时要对其进行排序呢?我们按正常顺序插入数据不是也挺好的吗?
这就要涉及到一个数据库查询流程的问题了,无论如何,我们是绝对不会去平白无故地在插入数据时增加一个操作来让流程复杂化的,所以插入数据时排序一定有其目的,就是优化查询的效率。
而我们不难看出,页内部存放数据的模块,实质上就是一个链表的结构,链表的特点也就是增删快,查询慢,所以优化查询的效率是必须的。
还是基于我们第一节中的那张页图来谈,我们插入了五条数据,id分别是从1-5,那么假设我要找一个表中不存在的id,假设id=-1,那么现在的查询流程就是:
将id=1的这一整页数据取出,进行逐个比对,那么当我们找到id=1的这条数据时,发现这个id大于我们所需要找的哪个id,由于数据库在插入数据时,已经进行过排序了,那么在id=1的数据后面,都是id>1的数据,所以我们就不需要再继续往下寻找了。
如果在插入时没有进行排序,那毋庸置疑,我们需要再继续往下进行寻找,逐条查找直到到结尾也没有找到这条数据,才能返回不存在这条数据。
当然,这只是排序优化的冰山一角,接着往下看。
说完了排序,下面就来分析一下我们在第一节中的那幅图,对于大数据量下有什么弊端,或者换一个说法,我们可以怎么对这个模式进行优化。
我们不难看出,在现阶段我们了解的页模式中,只有一个功能,就是在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。但是,我们也可以看到,现在的页模式内部,实际上是采用了链表的结构,前一条数据指向后一条数据,本质上还是通过数据的逐条比较来取出特定的数据。
那么假设,我们这一页中有一百万条数据,我们要查的数据正好在最后一个,那么我们是不是一定要从前往后找到这一条数据呢?如果是这样,我们需要查找的次数就达到了一百万次,即使是在内存中查找,这个效率也是不高的。那么有什么办法来优化这种情况下的查找效率呢?
我们可以打个比方,我们在看书的时候,如果要找到某一节,而这一节我们并不知道在哪一页,我们是不是就要从前往后,一节一节地去寻找我们需要的内容的页码呢?答案是否定的,因为在书的前面,存在目录,它会告诉你这一节在哪一页,例如,第一节在第1页、第二节在第13页。在数据库的页中,实际上也使用了这种目录的结构,这就是页目录。
那么引入页目录之后,我们所理解的页结构,就变成了这样:
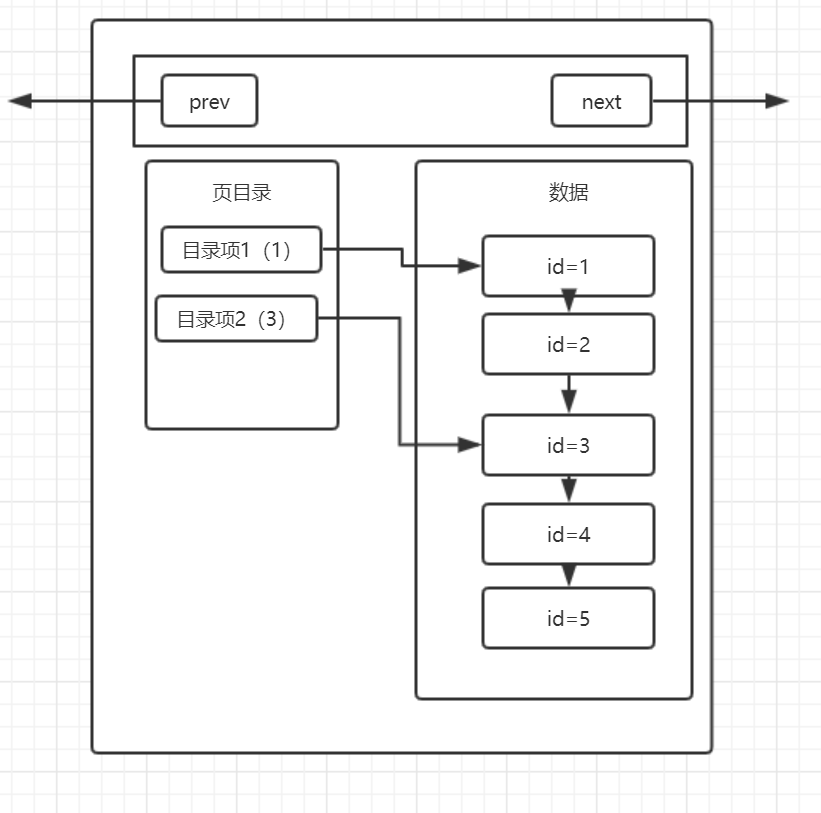
分析一下这张图,实际上页目录就像是我们在看书的时候书本的目录一样,目录项1就相当于第一节,目录项2就相当于第二节,而每一条数据就相当于书本的每一页,这张图就可以解释成,第一节从第一页开始,第二节从第三页开始,而实际上,每个目录项会存放自己这个目录项当中最小的id,也就是说,目录项1中会存放1,而目录项2会存放3。
那么对比一下数据库在没有页目录时候的查找流程,假设要查找id=3的数据,在没有页目录的情况下,需要查找id=1、id=2、id=3,三次才能找到该数据,而如果有页目录之后,只需要先查看一下id=3存在于哪个目录项下,然后直接通过目录项进行数据的查找即可,如果在该目录项下没有找到这条数据,那么就可以直接确定这条数据不存在,这样就大大提升了数据库的查找效率,但是这种页目录的实现,首先就需要基于数据是在已经进行过排序的的场景下,才可以发挥其作用,所以看到这里,大家应该明白第二个问题了,为什么数据库在插入时会进行排序,这才是真正发挥排序的作用的地方。
在上文中,我们基本上说明白了MySQL数据库中页的概念,以及它是如何基于页来减少磁盘IO次数的,以及排序是如何优化查询的效率的。
那么我们现在再来思考第三个问题:在开头说页的概念的时候,我们有说过,MySQL中每一页的大小只有16KB,不会随着数据的插入而自动扩容,所以这16KB不可能存下我们所有的数据,那么必定会有多个页来存储数据,那么在多页的情况下,MySQL中又是怎么组织这些页的呢?
针对这个问题,我们继续来画出我们现在所了解的多页的结构图:
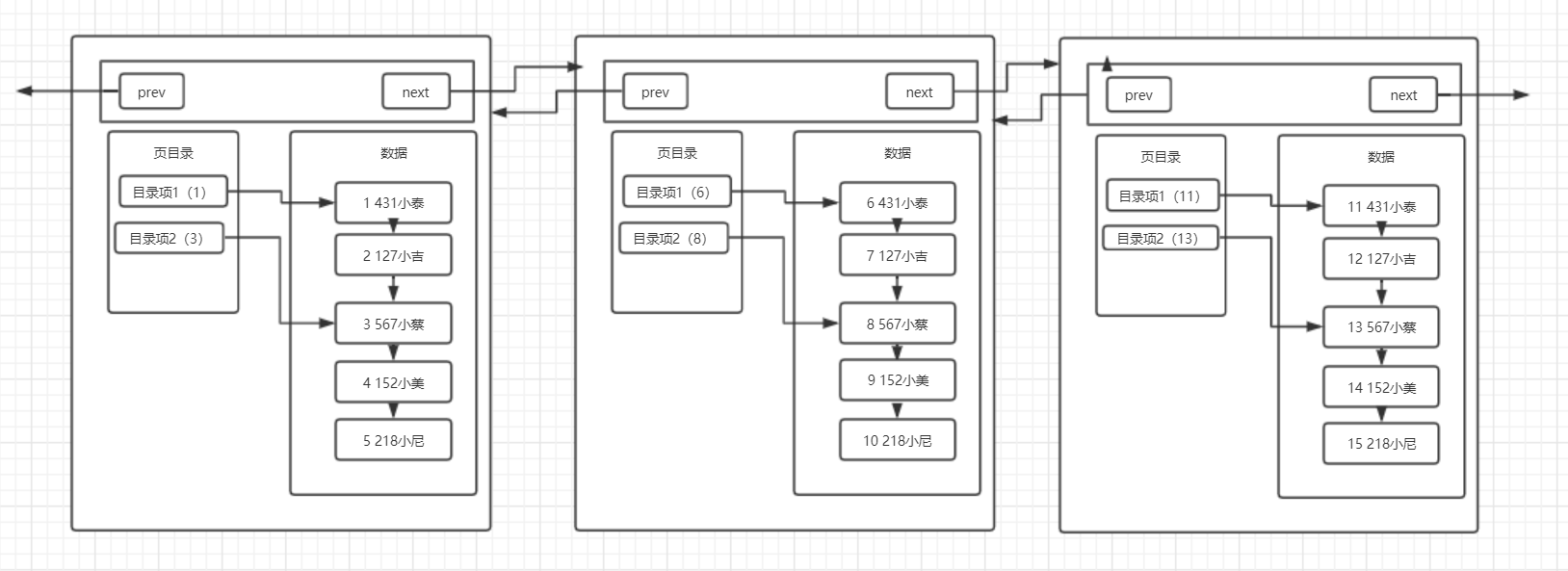
可以看到,在数据不断变多的情况下,MySQL会再去开辟新的页来存放新的数据,而每个页都有指向下一页的指针和指向上一页的指针,将所有页组织起来(这里修改了一下数据,将每一列的数据都放到了数据区中,其中第一个空格之前的代表id),第一页中存放id为1-5的数据,第二页存放id为6-10的数据,第三页存放id为11-15的数据,需要注意的是在开辟新页的时候,我们插入的数据不一定是放在新开辟的页上,而是要进行所有页的数据比较,来决定这条插入的数据放在哪一页上,而完成数据插入之后,最终的多页结构就会像上图中画的那样。
在多页模式下,MySQL终于可以完成多数据的存储了,就是采用开辟新页的方式,将多条数据放在不同的页中,然后同样采用链表的数据结构,将每一页连接起来。那么可以思考第四个问题:多页情况下是否对查询效率有影响呢?
针对这个问题,既然问出来了,那么答案是肯定的,多页会对查询效率产生一定的影响,影响主要就体现在,多页其本质也是一个链表结构,只要是链表结构,查询效率一定不会高。
假设数据又非常多条,数据库就会开辟非常多的新页,而这些新页就会像链表一样连接在一起,当我们要在这么多页中查询某条数据时,它还是会从头节点遍历到存在我们要查找的那条数据所存在的页上,我们好不容易通过页目录优化了页中数据的查询效率,现在又出现了以页为单位的链表,这不是前功尽弃了吗?
由于多页模式会影响查询的效率,那么肯定需要有一种方式来优化多页模式下的查询。相信有同学已经猜出来了,既然我们可以用页目录来优化页内的数据区,那么我们也可以采取类似的方式来优化这种多页的情况。
是的,页内数据区和多页模式本质上都是链表,那么的确可以采用相同的方式来对其进行优化,它就是目录页。
所以我们对比页内数据区,来分析如何优化多页结构。在单页时,我们采用了页目录的目录项来指向一行数据,这条数据就是存在于这个目录项中的最小数据,那么就可以通过页目录来查找所需数据。
所以对于多页结构也可以采用这种方式,使用一个目录项来指向某一页,而这个目录项存放的就是这一页中存放的最小数据的索引值。和页目录不同的地方在于,这种目录管理的级别是页,而页目录管理的级别是行。
那么分析到这里,我们多页模式的结构就会是下图所示的这样:
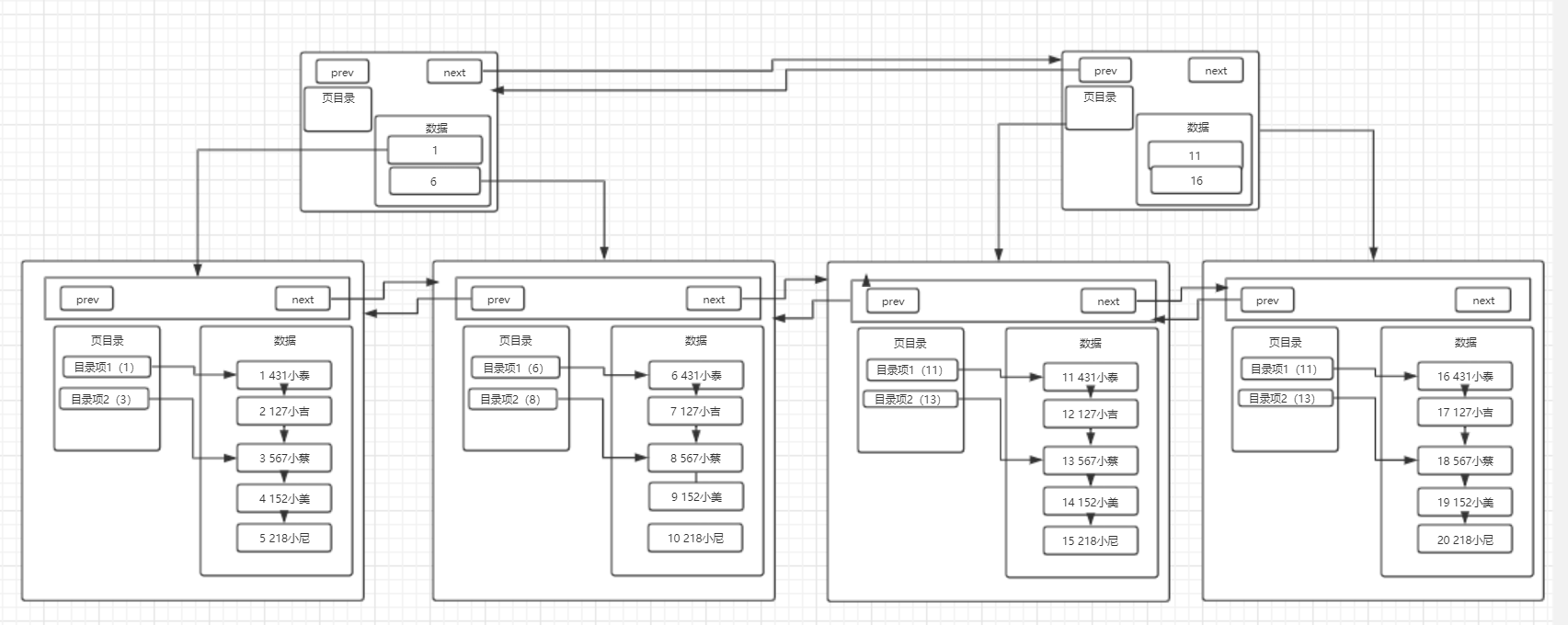
存在一个目录页来管理页目录,目录页中的数据存放的就是指向的那一页中最小的数据。
这里要注意的一点是:其实目录页的本质也是页,普通页中存的数据是项目数据,而目录页中存的数据是普通页的地址。
假设我们要查找id=19的数据,那么按照以前的查找方式,我们需要从第一页开始查找,发现不存在那么再到第二页查找,一直找到第四页才能找到id=19的数据,但是如果有了目录页,就可以使用id=19与目录页中存放的数据进行比较,发现19大于任何一条数据,于是进入id=16指向的页进行查找,直接然后再通过页内的页目录行级别的数据的查找,很快就可以找到id为19的数据了。随着数据越来越多,这种结构的效率相对于普通的多页模式,优势也就越来越明显。
回归正题,相信有对MySQL比较了解的同学已经发现了,我们画的最终的这幅图,就是MySQL中的一种索引结构——B+树。
B+树的特点我在《[从入门到入土]令人脱发的数据库底层设计》已经有详细叙述过了,在这里就不重复叙述了,如果有不了解的同学可以去看这篇博客。
我们接着往下聊,我们将我们画的存在目录页的多页模式图宏观化,可以形成下面的这张图:
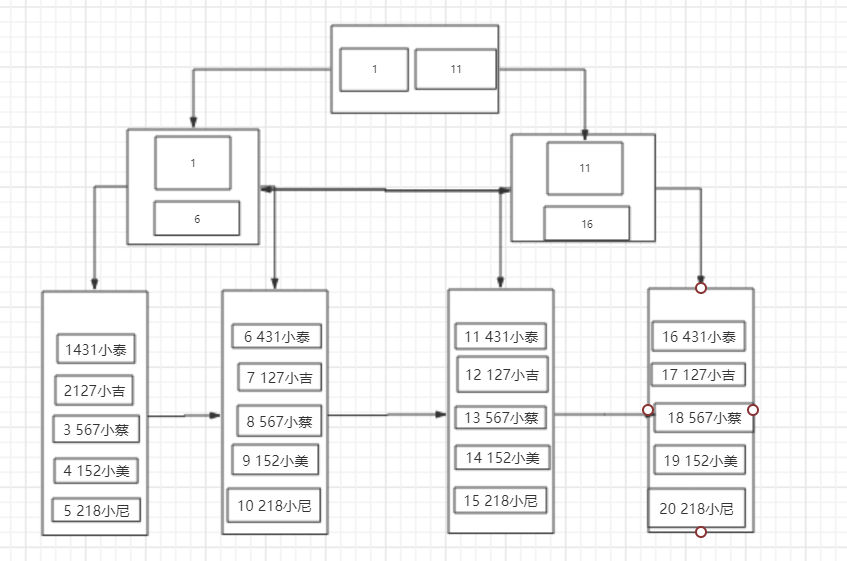
这就是我们兜兜转转由简到繁形成的一颗B+树。和常规B+树有些许不同,这是一棵MySQL意义上的B+树,MySQL的一种索引结构,其中的每个节点就可以理解为是一个页,而叶子节点也就是数据页,除了叶子节点以外的节点就是目录页。
这一点在图中也可以看出来,非叶子节点只存放了索引,而只有叶子节点中存放了真实的数据,这也是符合B+树的特点的。
- 由于叶子节点上存放了所有的数据,并且有指针相连,每个叶子节点在逻辑上是相连的,所以对于范围查找比较友好。
- B+树的所有数据都在叶子节点上,所以B+树的查询效率稳定,一般都是查询3次。
- B+树有利于数据库的扫描。
- B+树有利于磁盘的IO,因为他的层高基本不会因为数据扩大而增高(三层树结构大概可以存放两千万数据量。
说完了页的概念和页是如何一步一步地组合称为B+树的结构之后,相信大家对于页都有了一个比较清楚的认知,所以这里就要开始说说官方概念了,基于我们上文所说的,给出一个完整的页结构,也算是对上文中自己理解页结构的一种补充。

上图为 Page 数据结构,File Header 字段用于记录 Page 的头信息,其中比较重要的是 FIL_PAGE_PREV 和 FIL_PAGE_NEXT 字段,通过这两个字段,我们可以找到该页的上一页和下一页,实际上所有页通过两个字段可以形成一条双向链表。
Page Header 字段用于记录 Page 的状态信息。接下来的 Infimum 和 Supremum 是两个伪行记录,Infimum(下确界)记录比该页中任何主键值都要小的值,Supremum (上确界)记录比该页中任何主键值都要大的值,这个伪记录分别构成了页中记录的边界。
User Records 中存放的是实际的数据行记录,具体的行记录结构将在本文的第二节中详细介绍。Free Space 中存放的是空闲空间,被删除的行记录会被记录成空闲空间。Page Directory 记录着与二叉查找相关的信息。File Trailer 存储用于检测数据完整性的校验和等数据。

看到这里,我们已经了解了MySQL从单条数据开始,到通过页来减少磁盘IO次数,并且在页中实现了页目录来优化页中的查询效率,然后使用多页模式来存储大量的数据,最终使用目录页来实现多页模式的查询效率并形成我们口中的索引结构——B+树。既然说到这里了,那我们就来聊聊MySQL的其他知识点。
关于聚簇索引和非聚簇索引在[从入门到入土]令人脱发的数据库底层设计这篇文章中已经有了详细的介绍,这里简单地说说,所谓聚簇索引,就是将索引和数据放到一起,找到索引也就找到了数据,我们刚才看到的B+树索引就是一种聚簇索引,而非聚簇索引就是将数据和索引分开,查找时需要先查找到索引,然后通过索引回表找到相应的数据。InnoDB有且只有一个聚簇索引,而MyISAM中都是非聚簇索引。
在MySQL数据库中不仅可以对某一列建立索引,还可以对多列建立一个联合索引,而联合索引存在一个最左前缀匹配原则的概念,如果基于B+树来理解这个最左前缀匹配原则,相对来说就会容易很很多了。
首先我们基于文首的这张表建立一个联合索引:
1 | create index idx_obj on user(age asc,height asc,weight asc) |
我们已经了解了索引的数据结构是一颗B+树,也了解了B+树优化查询效率的其中一个因素就是对数据进行了排序,那么我们在创建idx_obj这个索引的时候,也就相当于创建了一颗B+树索引,而这个索引就是依据联合索引的成员来进行排序,这里是age,height,weight。
看过我之前那篇博客的同学知道,InnoDB中只要有主键被定义,那么主键列被作为一个聚簇索引,而其它索引都将被作为非聚簇索引,所以自然而然的,这个索引就会是一个非聚簇索引。
所以根据这些我们可以得出结论:
根据这两个结论,首先需要了解的就是,如何排序?
单列排序很简单,比大小嘛,谁都会,但是多列排序是基于什么原则的呢(重点)?
实际上在MySQL中,联合索引的排序有这么一个原则,从左往右依次比较大小,就拿刚才建立的索引举例子,他会先去比较age的大小,如果age的大小相同,那么比较height的大小,如果height也无法比较大小, 那么就比较weight的大小,最终对这个索引进行排序。
那么根据这个排序我们也可以画出一个B+树,这里就不像上文画的那么详细了,简化一下:
数据:
B+树:
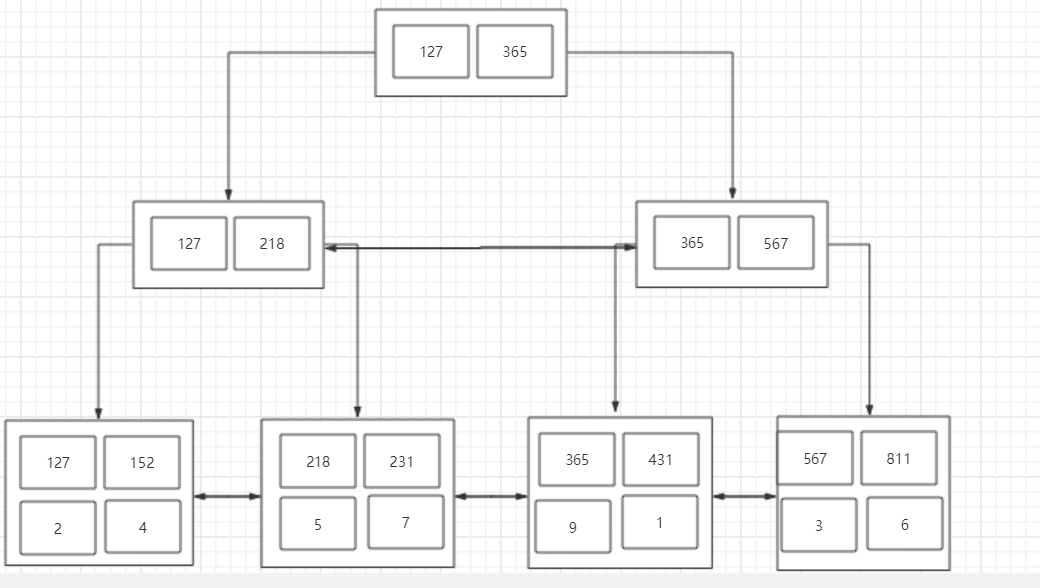
注意:此时由于是非聚簇索引,所以叶子节点不在有数据,而是存了一个主键索引,最终会通过主键索引来回表查询数据。
B+树的结构有了,就可以通过这个来理解最左前缀匹配原则了。
我们先写一个查询语句
1 | SELECT * FROM user WHERE age=1 and height = 2 and weight = 7 |
毋庸置疑,这条语句一定会走idx_obj这个索引。
那么我们再看一个语句:
1 | SELECT * FROM user WHERE height=2 and weight = 7 |
思考一下,这条SQL会走索引吗?
答案是否定的,那么我们分析的方向就是,为什么这条语句不会走索引。
上文中我们提到了一个多列的排序原则,是从左到右进行比较然后排序的,而我们的idx_obj这个索引从左到右依次是age,height,weight,所以当我们使用height和weight来作为查询条件时,由于age的缺失,那么就无法从age来进行比较了。
看到这里可能有小伙伴会有疑问,那如果直接用height和weight来进行比较不可以吗?显然是不可以的,可以举个例子,我们把缺失的这一列写作一个问号,那么这条语句的查询条件就变成了?27,那么我们从这课B+树的根节点开始,根节点上有127和365,那么以height和weight来进行比较的话,走的一定是127这一边,但是如果缺失的列数字是大于3的呢?比如427,527,627,那么如果走索引来查询数据,将会丢失数据,错误查询。所以这种情况下是绝对不会走索引进行查询的。这就是最左前缀匹配原则的成因。
根据我们了解的可以得出结论:
只要无法进行排序比较大小的,就无法走联合索引。
可以再看几个语句:
1 | SELECT * FROM user WHERE age=1 and height = 2 |
这条语句是可以走idx_obj索引的,因为它可以通过比较 (12?<365)。
1 | SELECT * FROM user WHERE age=1 and weight=7 |
这条语句也是可以走ind_obj索引的,因为它也可以通过比较(1?7<365),走左子树,但是实际上weight并没有用到索引,因为根据最左匹配原则,如果有两页的age都等于1,那么会去比较height,但是height在这里并不作为查询条件,所以MySQL会将这两页全都加载到内存中进行最后的weight字段的比较,进行扫描查询。
1 | SELECT * FROM user where age>1 |
这条语句不会走索引,但是可以走索引。这句话是什么意思呢?这条SQL很特殊,由于其存在可以比较的索引,所以它走索引也可以查询出结果,但是由于这种情况是范围查询并且是全字段查询,如果走索引,还需要进行回表,MySQL查询优化器就会认为走索引的效率比全表扫描还要低,所以MySQL会去优化它,让他直接进行全表扫描。
1 | SELECT * FROM user WEHRE age=1 and height>2 and weight=7 |
这条语句是可以走索引的,因为它可以通过age进行比较,但是weight不会用到索引,因为height是范围查找,与第二条语句类似,如果有两页的height都大于2,那么MySQL会将两页的数据都加载进内存,然后再来通过weight匹配正确的数据。
因为聚簇索引是将索引和数据都存放在叶子节点中,如果所有的索引都用聚簇索引,则每一个索引都将保存一份数据,会造成数据的冗余,在数据量很大的情况下,这种数据冗余是很消耗资源的。
这两个点也是上次写关于索引的博客时漏下的,这里补上。
1.什么情况下会发生明明创建了索引,但是执行的时候并没有通过索引呢?
科普时间:查询优化器 一条SQL语句的查询,可以有不同的执行方案,至于最终选择哪种方案,需要通过优化器进行选择,选择执行成本最低的方案。
在一条单表查询语句真正执行之前,MySQL的查询优化器会找出执行该语句所有可能使用的方案,对比之后找出成本最低的方案。这个成本最低的方案就是所谓的执行计划。
优化过程大致如下:
1、根据搜索条件,找出所有可能使用的索引
2、计算全表扫描的代价
3、计算使用不同索引执行查询的代价
4、对比各种执行方案的代价,找出成本最低的那一个 。
根据我们刚才的那张表的非聚簇索引,这条语句就是由于查询优化器的作用,造成没有走索引:
1 | SELECT * FROM user where age>1 |
2.在稀疏索引情况下通常需要通过叶子节点的指针回表查询数据,什么情况下不需要回表?
科普时间:覆盖索引 覆盖索引(covering index)指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。也可以称之为实现了索引覆盖。
当一条查询语句符合覆盖索引条件时,MySQL只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后再返回表操作,减少I/O提高效率。
如,表covering_index_sample中有一个普通索引 idx_key1_key2(key1,key2)。当我们通过SQL语句:select key2 from covering_index_sample where key1 = 'keytest';的时候,就可以通过覆盖索引查询,无需回表。
例如:
1 | SELECT age FROM user where age = 1 |
这句话就不需要进行回表查询。
本篇文章着重聊了一下关于MySQL的索引结构,从零开始慢慢构建了一个B+树索引,并且根据这个过程谈了B+树是如何一步一步去优化查询效率的。
简单地归纳一下就是:
排序:优化查询的根本,插入时进行排序实际上就是为了优化查询的效率。
页:用于减少IO次数,还可以利用程序局部性原理,来稍微提高查询效率。
页目录:用于规避链表的软肋,避免在查询时进行链表的扫描。
多页:数据量增加的情况下开辟新页来保存数据。
目录页:“特殊的页目录”,其中保存的数据是页的地址。查询时可以通过目录页快速定位到页,避免多页的扫描。