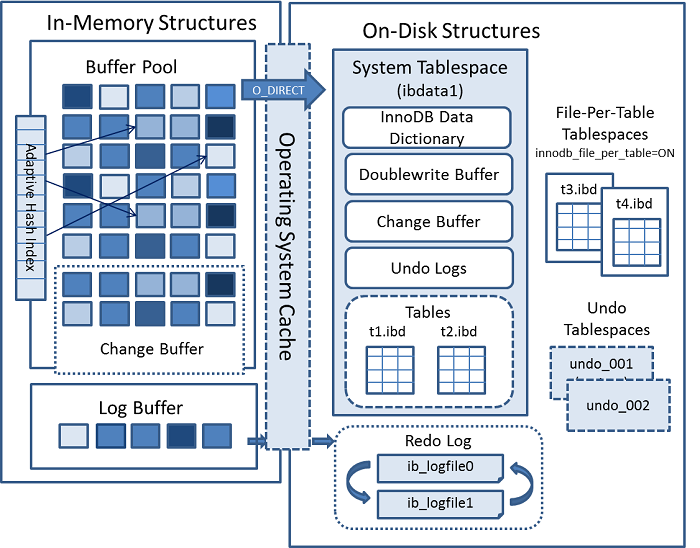
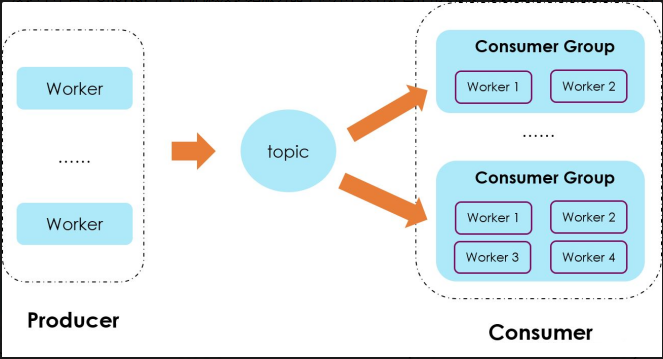
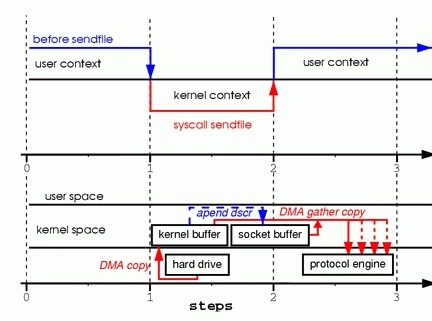
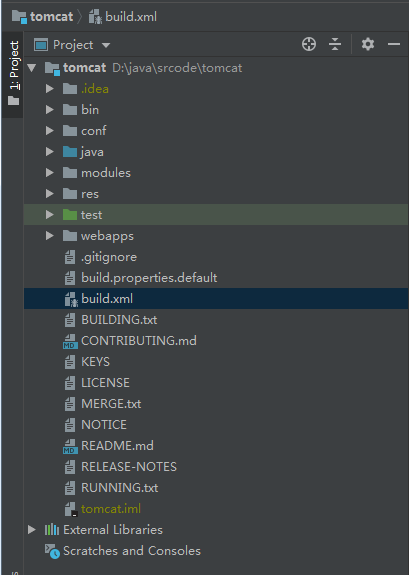
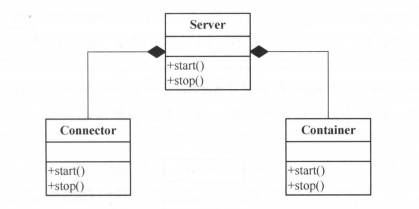
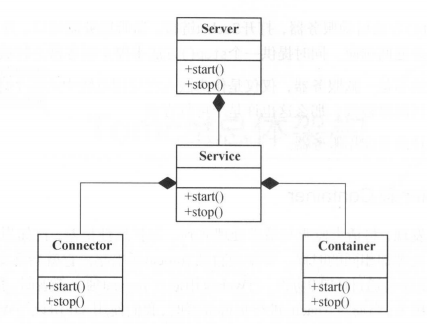
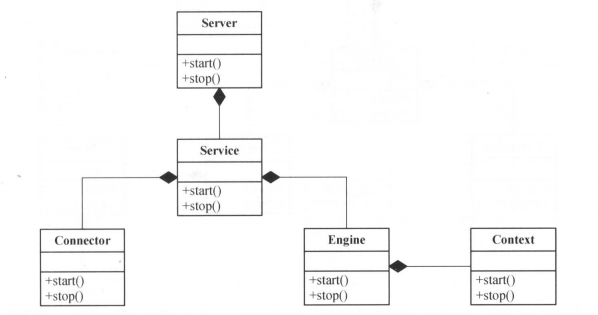
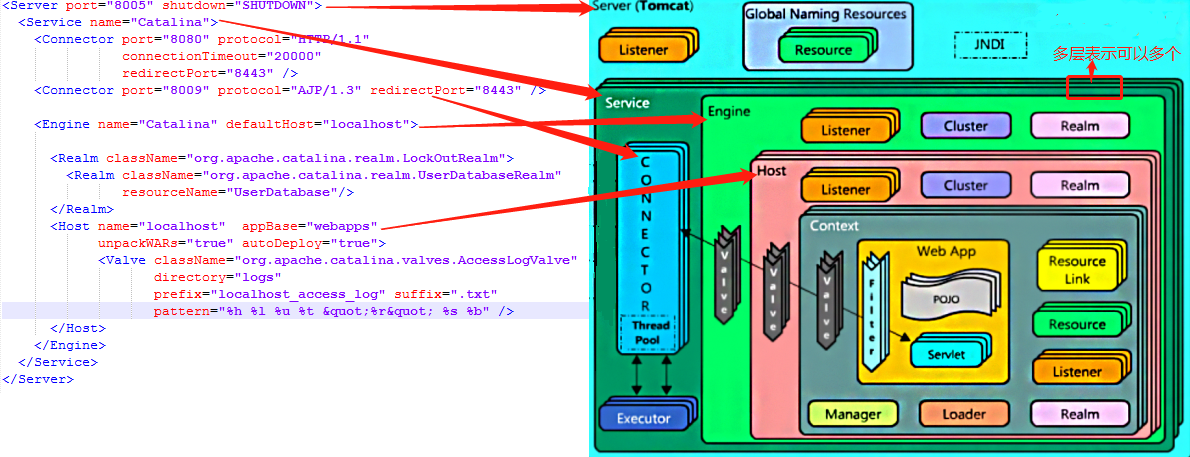
1、broker 端设计架构
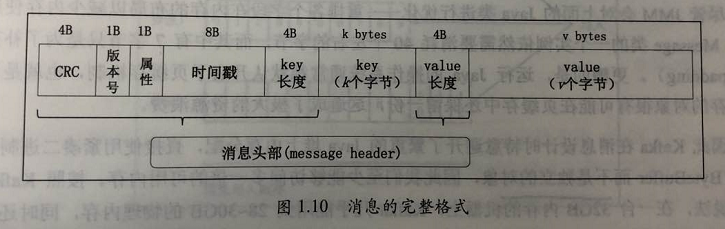
1.1、消息设计
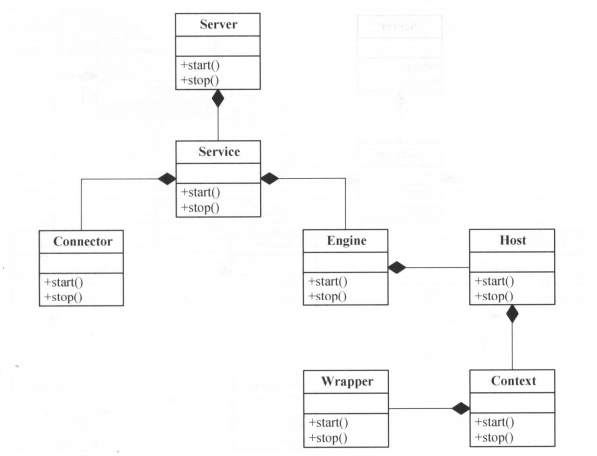
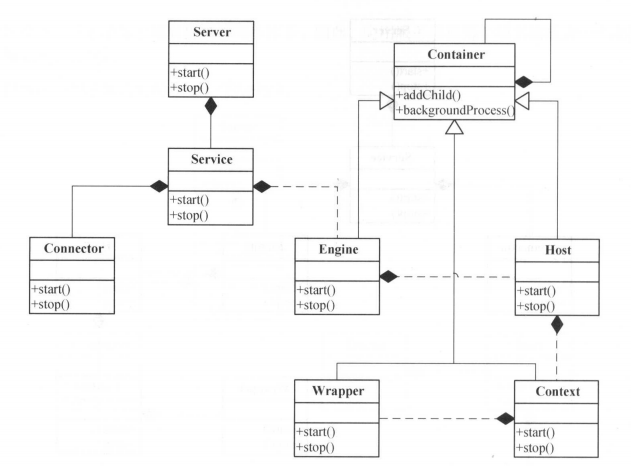
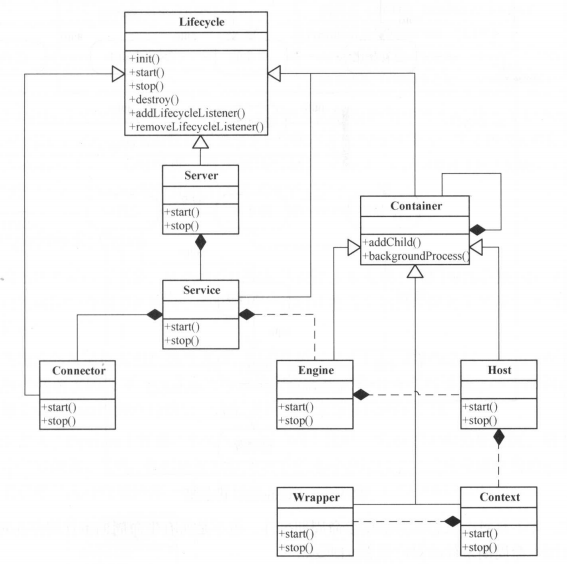
1.2、集群管理
1.2.1、成员管理
kafka 的自动化服务发现 和 成员管理 靠 zookeeper 实现;
每当一个 broker 启动时,它会将 自己 注册到 zookeeper 的一个节点(/brokers/ids/<broker.id>)
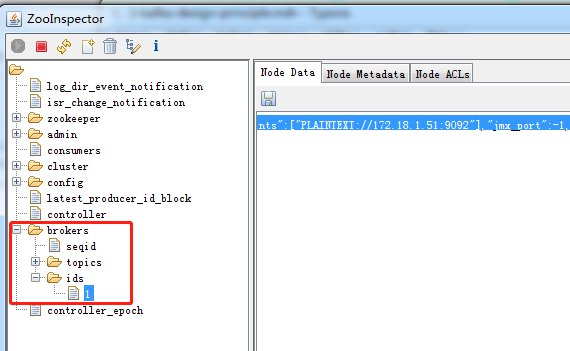
注册信息格式如下:
1 | { |
- listener_security_protocol_map: 该broker与外界通信使用的安全协议类型;
- endpoints:指定 broker 的 endpoint 列表;endpoint可以配置多个,每种协议一个,只是端口号不能冲突;
- rack:指定broker机架信息,若设置了机架信息,kafka 会把副本分配在多个机架上;
- jmx_port: broker 的 JMX 监控端口;
- host:broker 主机名或 IP 地址;
- port:broker 服务端口号;
- timestamp:broker 启动时间;
- version:broker 当前版本号;不是kafka版本号,每个 broker版本,信息格式不一样;

注意 ephemeralOwner值,该值不是0,意味着 这是一个 zookeeper的临时节点;
kafka 管理集群及其成员的主要流程:
1、broker启动时,在 zk 上创建对应的临时节点,同时还会创建一个 监听器(listener)监听该临时节点的状态;
2、一旦 broker 启动后,监听器会自动同步整个集群信息到该 broker 上;
3、一旦 broker 崩溃,broker 与 zk 的会话断开,该临时节点会被自动清楚掉,监听器被触发,然后处理 broker 崩溃的后续事宜。
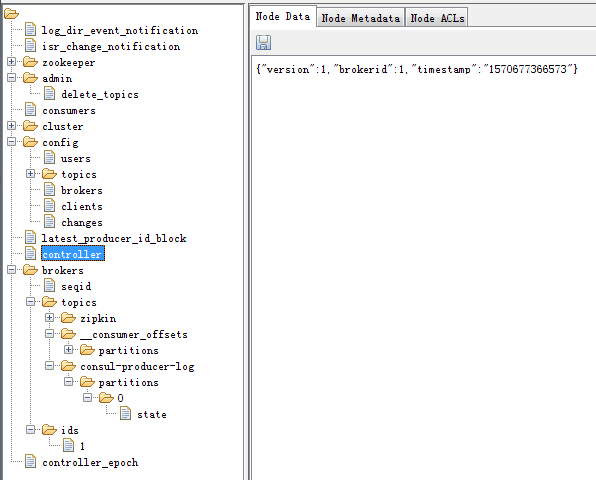
1.2.2、使用到的ZooKeeper 路径
新版本的 producer 和 consumer 已经不再 需要连接 zookeeper
下图涵盖了 Kafka 用到的 ZooKeeper 节点:

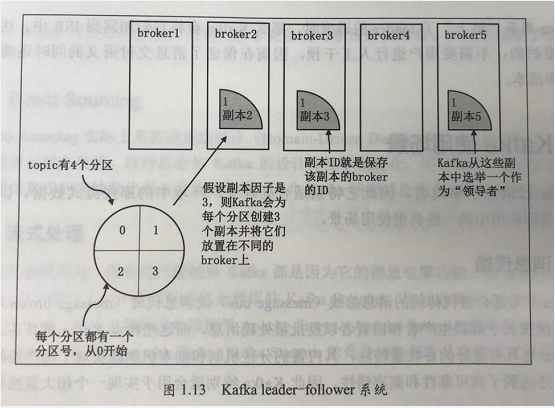
1.3、副本与ISR设计
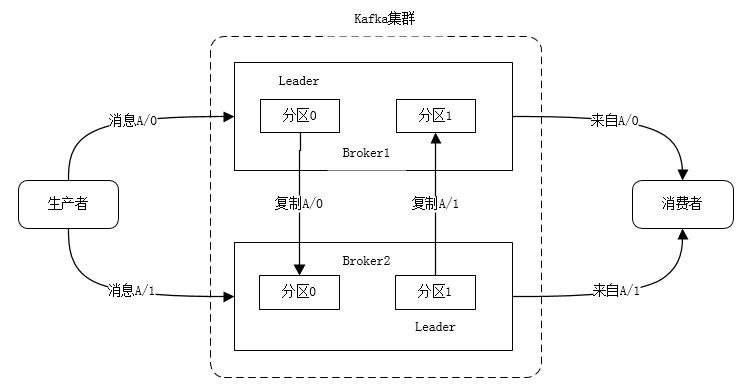
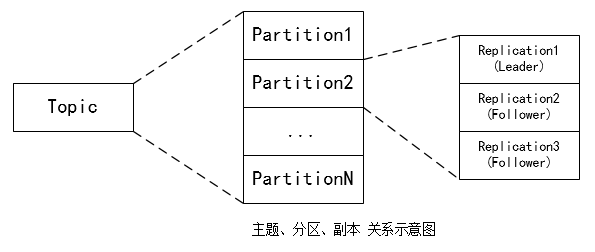
副本:partition 在其他 broker 上的备份;
ISR:与 leader partition 上 保持同步的副本集合;
问题: 如何判断 副本与leader partition是否同步?
1.3.1、follower副本同步
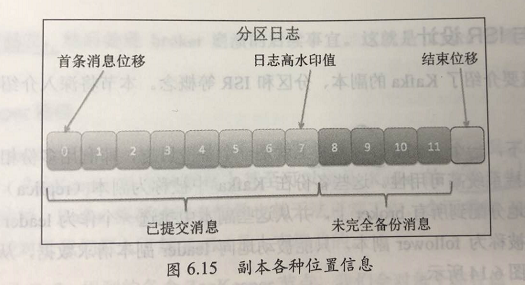
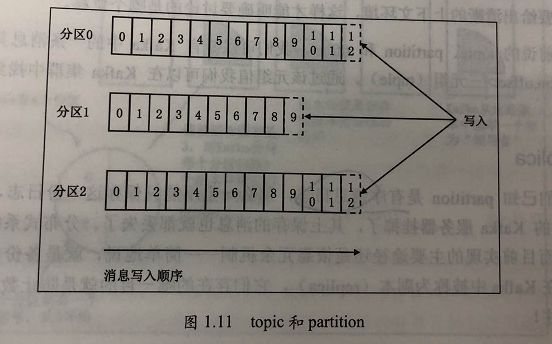
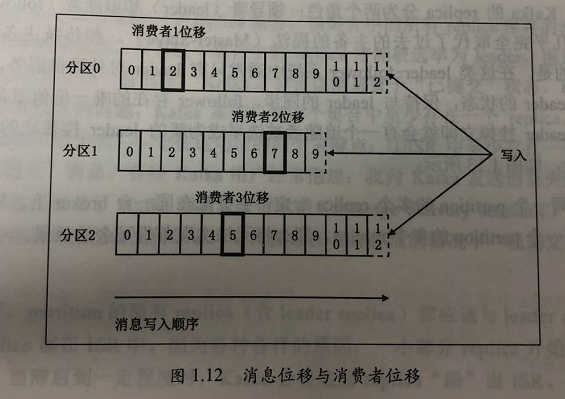
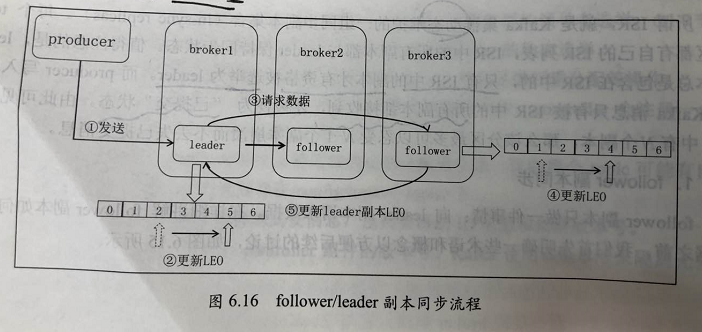
一个partition的格式如上图,其中比较重要的位置信息如下:
- 起始位移(base offset):表示该副本当前所含第一条消息的offset;
- 高水印值(high watermark,HW):副本高水印值。保存了 最新一条”已提交“消息的位移。超过 HW 值的所有消息都被视为 ”未提交成功的“,因此 consumer 是看不到的。注意:不只有 leader partition 有 HW 值,每个 follower 都有 HW 值,只不过只有 leader 的 HW 值 可以决定 consumer 能看到的消息数;
- 日志末端位移(log end offset,LEO):副本日志 下一条待写入消息的 offset,所有的 副本都需要维护自己的 LEO 信息。follower 向 leader 请求到数据后 会增加自己的 LEO。事实上 只有所有ISR副本都更新了对应的 LEO 之后 leader 才会 向右移动对应的 HW 值,来表明 消息写入成功。如下图
1.3.2、ISR 设计
如何判定 ISR?
1、0.9.0.0 版本之前
参数:replica.lag.max.messages=n,follower落后leader的消息数;
参数:replica.lag.time.max.ms=m, follower 在 m 毫秒内 无法 向 leader 请求数据;
follower 落后 leader 的可能原因:
- 请求速度追不上:follower 所在的broker 的 网络 I/O开销过大,导致 获取消息速度过慢;
- 进程卡住:follower 在一段时间内 无法 向 leader 请求数据,比如频繁GC和进程bug等;
- 新创建的副本:如果用户新增了 副本数,新副本追赶 leader 进度期间 通常都是不同步的;
参数:replica.lag.max.messages 的缺陷:无法动态适配场景,容易导致follower 频繁的 踢出加入 ISR;
2、0.9.0.0 版本之后
参数:replica.lag.time.max.ms 默认值10s。用于检测由于慢和进程卡壳的滞后,即 follower 落后 leader 的 时间间隔。
删除了 replica.lag.max.messages 参数,这样,只要 follower 不是持续落后,就不会被反复踢出 ISR;
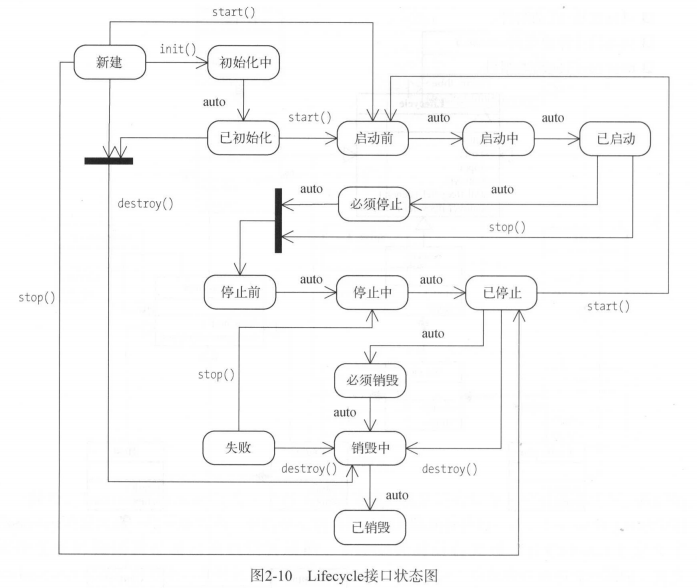
1.4、水印(watermark)和 leader epoch
摘要:
- watermark机制的缺陷;
- leader epoch 解决 watermark 的缺陷;
1.4.1、LEO更新机制
分类:leader 的 LEO 更新机制、follower 的 LEO 更新机制;
follower 的 LEO 保存位置:【follower 所在 broker 的缓存上】,【leader 所在broker 的缓存上】;换句话说 leader 所在broker 上保存了 该 partition 下所有 follower 的 LEO;
follower 的 LEO 更新机制:
- 更新【follower 所在 broker 的缓存】的 LEO,follower 发送 FETCH 请求从leader 拿到数据后,follower 开始向底层log 写数据,从而自动更新 LEO值;
- 更新【leader 所在 broker 的缓存】的 LEO,leader 收到 follower的 FETCH请求后,它首先 从自己的log 读取响应的数据,但在 给 follower 返回数据之前,它会 先去更新自己 broker上的对应follower 的 LEO值;
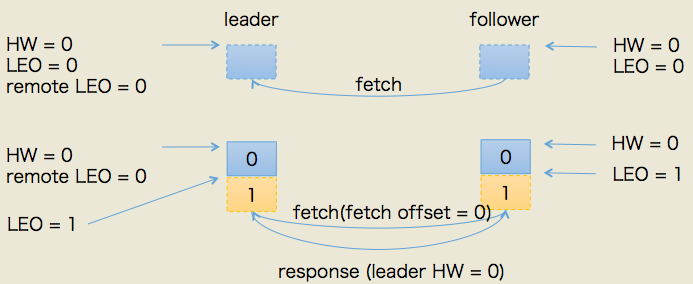
leader 的 LEO 更新机制:和 follower 更新自己 的LEO相同,leader 在写入log 时 会自动更新自己的 LEO值;
1.4.2、HW更新机制
follower 的 HW更新机制: follower.HW = min(follower.LEO,leader.HW); follower 在写完log数据以后,就会尝试更新HW值;
leader 的 HW更新机制:leader的 HW 会影响 consumer的 可见性,所以比较重要;在以下 4种情况下,会做更新HW的尝试:
- 副本称为 leader 时:有必要检查副本的状态;
- 集群中有broker崩溃导致 它的 follower被踢出 ISR时:拖后腿的 ISR没有了,有必要检查一下;
- producer 向 leader 写入消息时:
- leader 处理 follower FETCH 请求时:
leader.HW = min(foreach(ISR.partition.LEO),(落后时间< replica.lag.time.max.ms)partition.LEO);选择【 ISR】 和 【落后于leader的时长不大于 replica.lag.time.max.ms 的所有副本】的最小 LEO值 作为 HW;
1.4.3、watermark备份机制的缺陷
leader 的 HW更新 依赖于 下一轮的 follower FETCH才能完成,这可能引起如下问题:
- 备份数据丢失;
- 备份数据不一致;
问题1:备份数据丢失

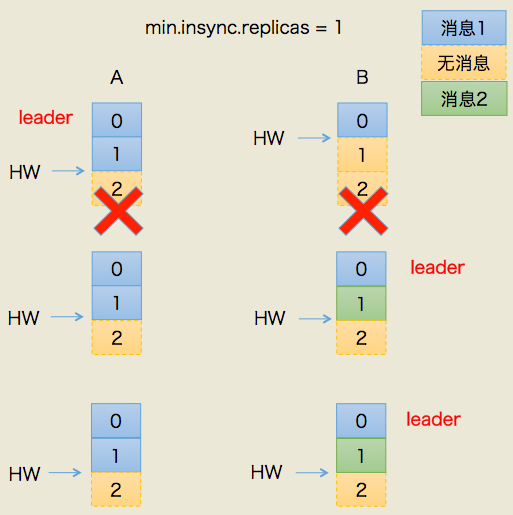
上图中有两个副本:A和B。开始状态是A是leader。我们假设producer端min.insync.replicas设置为1,那么当producer发送两条消息给A后,A写入到底层log,此时Kafka会通知producer说这两条消息写入成功。
但是在broker端,leader和follower底层的log虽都写入了2条消息且分区HW已经被更新到2,但follower HW尚未被更新(也就是上面紫色颜色标记的第二步尚未执行)。倘若此时副本B所在的broker宕机,那么重启回来后B会自动把LEO调整到之前的HW值,故副本B会做日志截断(log truncation),将offset = 1的那条消息从log中删除,并调整LEO = 1,此时follower副本底层log中就只有一条消息,即offset = 0的消息。
B重启之后需要给A发FETCH请求,但若A所在broker机器在此时宕机,那么Kafka会令B成为新的leader,而当A重启回来后也会执行日志截断,将HW调整回1。这样,位移=1的消息就从两个副本的log中被删除,即永远地丢失了。
这个场景丢失数据的前提是在min.insync.replicas=1时,一旦消息被写入leader端log即被认为是“已提交”,而延迟一轮FETCH RPC更新HW值的设计使得follower HW值是异步延迟更新的,倘若在这个过程中leader发生变更,那么成为新leader的follower的HW值就有可能是过期的,使得clients端认为是成功提交的消息被删除
问题2:备份数据不一致
这种情况的初始状态与情况1有一些不同的:A依然是leader,A的log写入了2条消息,但B的log只写入了1条消息。分区HW更新到2,但B的HW还是1,同时producer端的min.insync.replicas = 1。
这次我们让A和B所在机器同时挂掉,然后假设B先重启回来,因此成为leader,分区HW = 1。假设此时producer发送了第3条消息(绿色框表示)给B,于是B的log中offset = 1的消息变成了绿色框表示的消息,同时分区HW更新到2(A还没有回来,就B一个副本,故可以直接更新HW而不用理会A)之后A重启回来,需要执行日志截断,但发现此时分区HW=2而A之前的HW值也是2,故不做任何调整。此后A和B将以这种状态继续正常工作。
显然,这种场景下,A和B底层log中保存在offset = 1的消息是不同的记录,从而引发不一致的情形出现。
1.4.4、leader epoch 如何解决
造成上述两个问题的根本原因在于HW值被用于衡量副本备份的成功与否以及在出现failture时作为日志截断的依据,但HW值的更新是异步延迟的,特别是需要额外的FETCH请求处理流程才能更新,故这中间发生的任何崩溃都可能导致HW值的过期。鉴于这些原因,Kafka 0.11引入了leader epoch来取代HW值。Leader端多开辟一段内存区域专门保存leader的epoch信息,这样即使出现上面的两个场景也能很好地规避这些问题。
所谓leader epoch实际上是一对值:(epoch,offset)。epoch表示leader的版本号,从0开始,当leader变更过1次时epoch就会+1,而offset则对应于该epoch版本的leader写入第一条消息的位移。因此假设有两对值:
(0, 0)
(1, 120)
则表示第一个leader从位移0开始写入消息;共写了120条[0, 119];而第二个leader版本号是1,从位移120处开始写入消息。
leader broker中会保存这样的一个缓存,并定期地写入到一个checkpoint文件中。
当leader写底层log时它会尝试更新整个缓存——如果这个leader首次写消息,则会在缓存中增加一个条目;否则就不做更新。而每次副本重新成为leader时会查询这部分缓存,获取出对应leader版本的位移,这就不会发生数据不一致和丢失的情况。
下面我们依然使用图的方式来说明下利用leader epoch如何规避上述两种情况
一、规避数据丢失
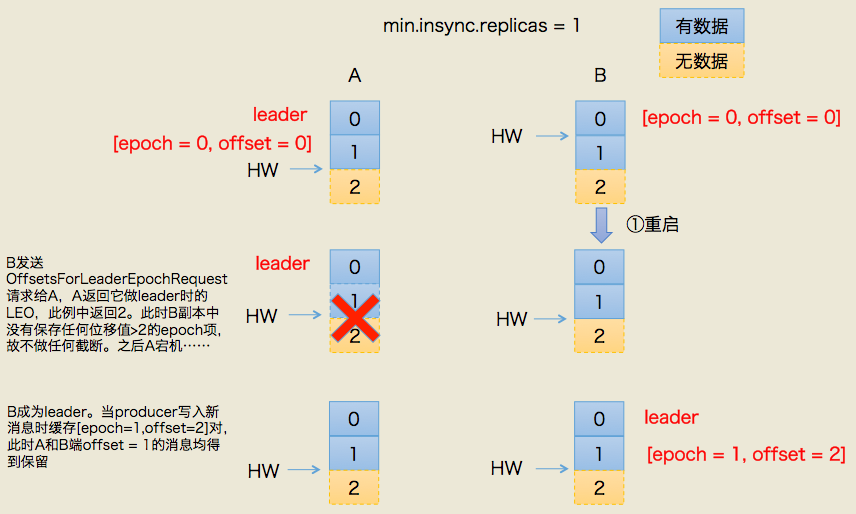
上图左半边已经给出了简要的流程描述,这里不详细展开具体的leader epoch实现细节(比如OffsetsForLeaderEpochRequest的实现),我们只需要知道每个副本都引入了新的状态来保存自己当leader时开始写入的第一条消息的offset以及leader版本。这样在恢复的时候完全使用这些信息而非水位来判断是否需要截断日志。
二、规避数据不一致
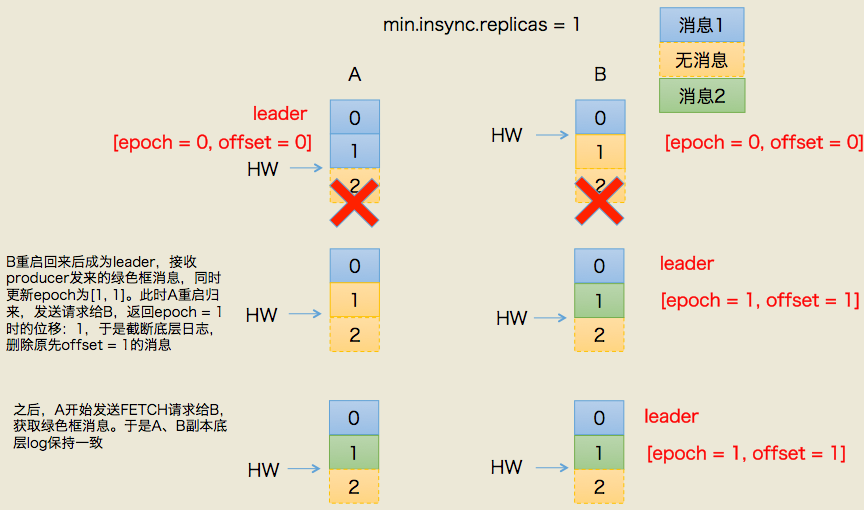
同样的道理,依靠leader epoch的信息可以有效地规避数据不一致的问题。
总结
0.11.0.0版本的Kafka通过引入leader epoch解决了原先依赖水位表示副本进度可能造成的数据丢失/数据不一致问题。有兴趣的读者可以阅读源代码进一步地了解其中的工作原理。
源代码位置:kafka.server.epoch.LeaderEpochCache.scala (leader epoch数据结构)、kafka.server.checkpoints.LeaderEpochCheckpointFile(checkpoint检查点文件操作类)还有分布在Log中的CRUD操作。
1.5、日志存储设计
1、kafka 日志
kafka的日志:不同于 请求日志,kafka日志 是 一种 专门为程序访问的 日志;更像是mysql中的binlog;
kafka 把 消息体 和 元数据信息 打包成 一个record,以追加的方式 写入日志;
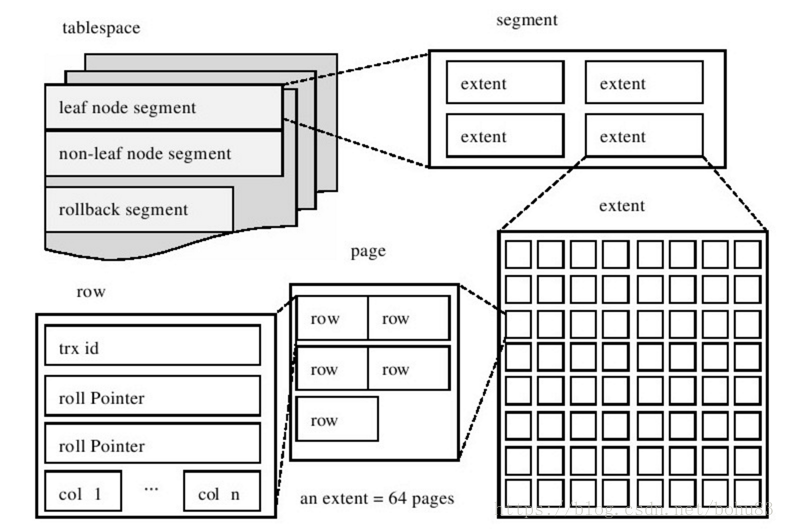
kafka的日志设计:topic -> 多个 partition(分区)-> 每个partition 又可以细分为 段日志(segment log),包含 日志段文件 和 索引文件; 下图中 .log 结尾的 就是 segment log,.index 和 .timeindex 结尾的就是 对应的索引文件;
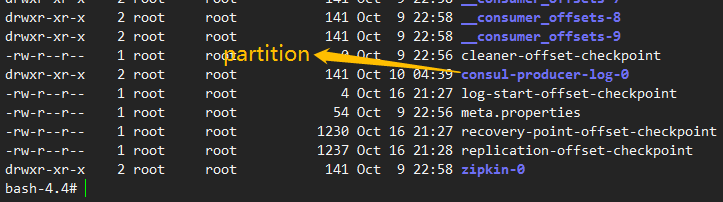
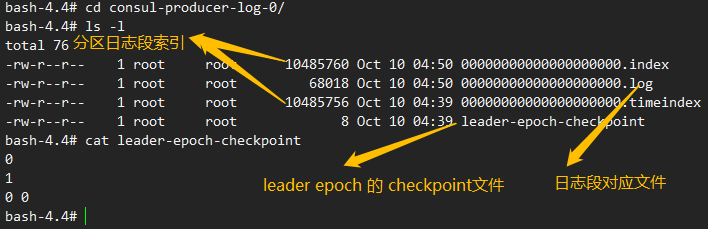
2、日志段文件
parition 分区名字:topic名-分区号;
日志段文件:00000000000000000196.log,每个 日志段文件大小都有上限,默认大小 1GB,通过 broker参数 log.segment.bytes 控制;日志段文件被填满以后,会自动创建一组新的 日志段文件和索引文件;
3、索引文件
除了 .log 文件外,kafka分区日志还包括 两个特殊的文件 .index 和 .timeindex;
.index 是位移索引文件;kafka可以用二分查找 将整体时间复杂度 降到 O(logN);
.timeindex 是 时间戳索引文件;可以根据时间戳找到一定范围的记录;
4、日志留存
kafka 会定期清除日志,而且清除的单位是 日志段文件;即清除 .log 日志 和 对应的 两个索引文件;
留存策略:
- 基于时间的留存策略:kafka会morn清除7天前的日志段数据;可以通过 broker参数 log.retention.{hours|minutes|ms}用于配置清除日志的时间间隔;
- 基于大小的留存策略:kafka 会 保存 log.retention.bytes 参数值大小 字节数 的 日志。默认值 是 -1,表示不限制大小;
注意:日志清除对于当前日志段是不生效的;
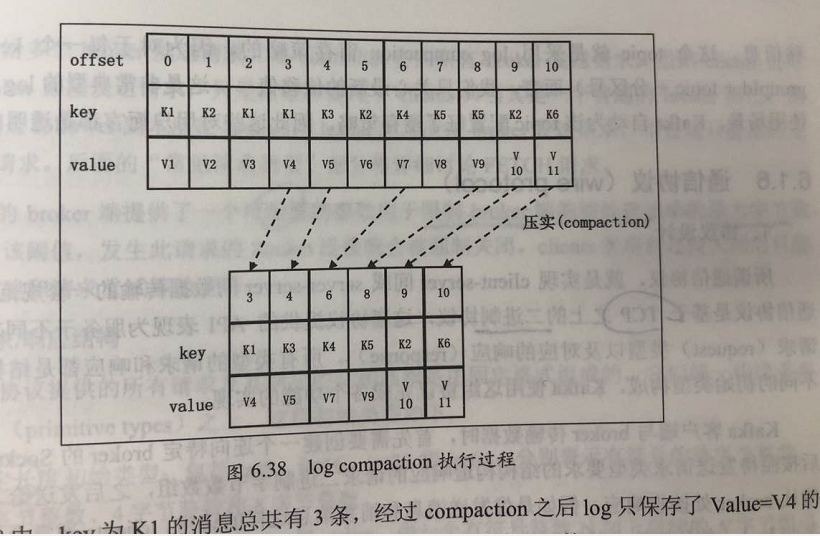
5、日志压实 compaction
kafka可以对key相同的 日志进行和合并,只保留最新的 value;
1.6、通信协议(wire protocol)
1.7、controller设计
1、controller 架构
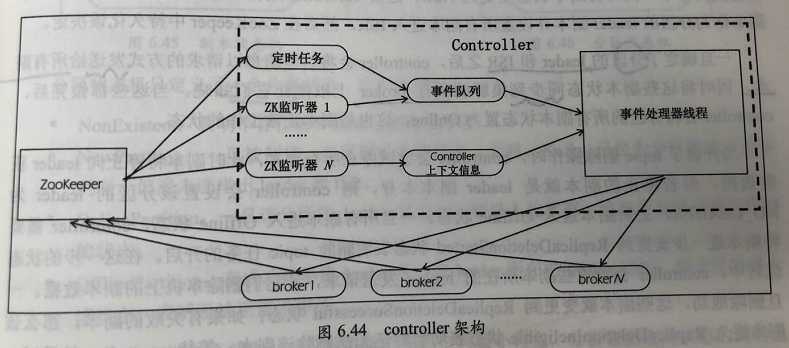
2、controller 管理状态
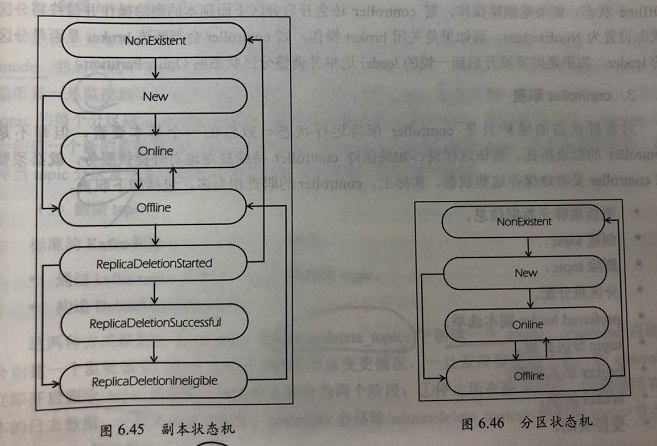
controller维护的状态分类:每台 broker 上的分区副本 和 每个分区的 leader 信息;从维度上看,又分为 副本状态和分区状态;由此 引入 副本状态机 和 分区状态机
3、controller 职责
- 更新集群元数据信息:分区信息变更时,controller封装变更信息 发送给每个 broker;
- 创建topic:监控 zk的/brokers/topics 子节点变更,监听到新节点 触发topic创建逻辑;
- 删除topic:监听到/admin/delete_topics下的节点时,触发删除topic操作;
- 分区重分配:监听 /admin/reassign_partitions 节点下的变更;
- prefered leader 副本选举:分区的第一顺位副本作为 leader;
- topic 分区扩展:用户发起增加分区的操作,会在 /brokers/topics/topic_name 下写入新的分区目录;
- broker 加入集群:新加入的broker会在 /broker/ids 下创建 新的znode并写入 broker信息,对应的监听器会感知到变更;
- broker 崩溃:/broker/ids 下的znode小时,监听器拿到变更,执行broker退出逻辑;
- broker 受控关闭:
- controller leader 选举:/controller 节点 存储了当前 controller所在的brokerid,集群首次启动,都会抢着创建该节点,胜出的那个broker成为 controller,同时更新 /controller_epoch 节点的值;
4、controller 与 broker 通信
5、controller 组件
6、老板本 controller 的缺陷
7、新版本 controller
1.8、broker 请求处理
1、Reactor模型
2、kafka的broker处理模型
1),KafkaServer
该类代表了一个kafka Broker的生命周期,处理kafka启动或者停止所需要的所有功能。
2),SocketServer
一个NIO 服务中心。线程模型是
1个Acceptor线程,用来处理新的链接请求
N个加工Processor线程。每个线程拥有一个他们自己的selector,主要负责IO请求及应答。
3),KafkaRequestHandler
实际会在KafkaRequestHandlerPool中创建多个对象,负责加工处理request线程。
会1创建M个处理Handler线程。负责处理request请求,将responses重新写会加工线程Processor,以便于其写回给客户端。
一个典型的 broker 请求流程如下:
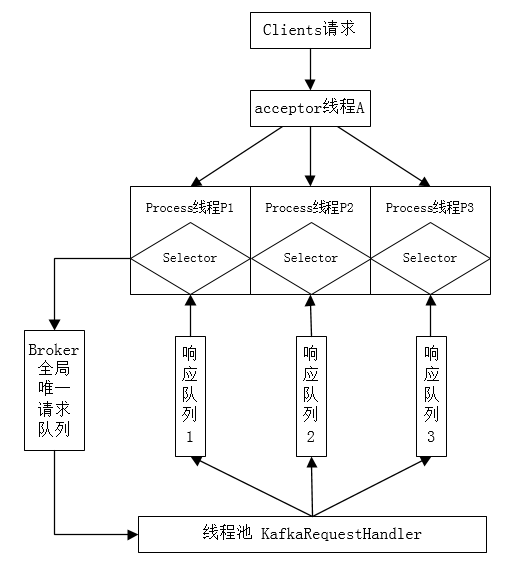
(1)启动 broker
- 启动 acceptor 线程A
- 启动 3个 process 线程 P1, P2, P3
- 创建 KafkaRequestHander 线程池 和 8个请求处理线程 H1 ~ H8
(2)broker 启动后,acceptor 线程 不断轮询是否存在 客户端的 新连接;P1~P3实时轮询 是否有 acceptor新发送的 socket连接通道 以及 请求队列 和 响应队列中是否有请求需要处理;H1 ~ H8 则 实时监控 请求队列中的新请求;
(3)此时 client 向 broker 发送数据,首先 client 会 创建 与 该 broker 的Socket 连接;
(4)acceptor 线程 监听到socket连接,接收,将连接发送给 P1~P3中的一个,假设是 P2;
(5)P2 下一次轮询时 发现 acceptor 传送过来的新连接,将其注册到 Selector上 并开始监听其上的 入站请求;
(6)现在 client 开始给 broker 发送 producer请求;
(7)P2 监听到 有新的请求到来,故获取之,然后发送到请求队列中;
(8)由于 H1~H8 实时监听请求队列,故必有一个线程最早发现 producer请求并开始处理,假设是 H5,H5从请求队列中取出并开始处理;
(9)H5 线程请求处理完成,将响应结果放入 P2 对应的 响应队列;
(10)P2 监听到 它的响应队列 有 响应,将响应取出 发送给 对应的 client;
(11)client 接收响应,标记本次 producer 请求处理过程结束;
2、producer 端设计架构
2.1、producer 端基本数据结构
2.2、工作流程
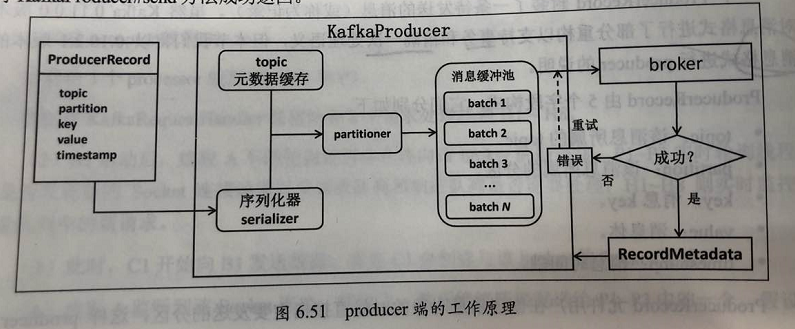
- 用户首先构建发送的消息对象 ProducerRecord,然后调用 KafkaProducer.send 进行发送;
- KafkaProducer 接收到消息后首先 对其进行序列化;
- 然后结合本地缓存的元数据信息一起发送给 pointer 去确定目标分区;最后追加 写入内存中的缓存池(accumulator)。此时 KafkaProducer.send 方法成功返回;
- KafkaProducer 负责 将缓存池 中的消息 分批次 发送给对应的 broker,完成真正的 消息发送逻辑;
3、consumer 端设计架构
3.1、consumer group 状态机
3.2、group 管理协议
3.3、rebalance 场景分析
4、实现精确一次处理语义
4.1、消息交付语义
- 最多一次(at more once):
- 最少一次(at least once):
- 精确一次(exactly once):
KafkaProducer端默认是 at least once,可以通过幂等性 实现 exactly once;
KafkaConsumer 跟 位移提交时机有关系
- 先处理后提交位移,则是 at least once;
- 先提交位移后处理消息,则是 at more once;
4.2、幂等性producer(idempotent producer)
需要 打开 producer 参数 enable.idempotence = true
通过 producer_id,分区号,和消息序列号,实现 单个producer 的 exactly once,多个之间则不能;