
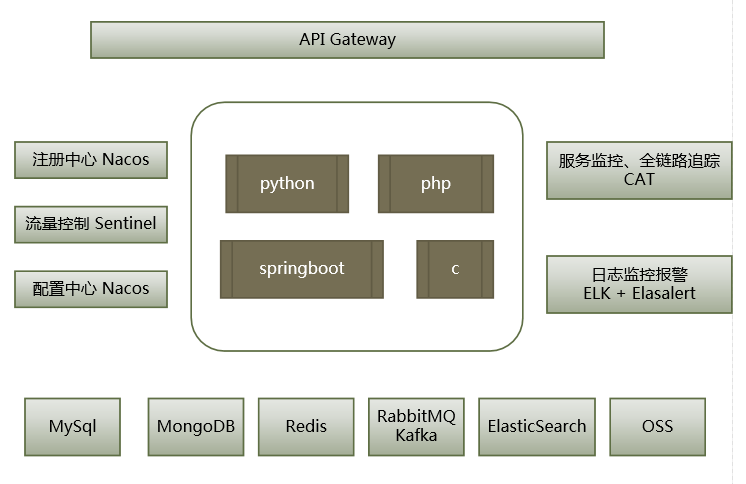
jenkins pipeline自动构建springboot并部署至k8s
1、准备
1.1、安装k8s集群
每个docker机器
1 | vi /etc/docker/daemon.json |
1.2、harbor 启动
1 | docker-compose -f /data/tools/harbor/docker-compose.yml stop |
2. k8s中部署jenkins
2.1、制作jenkins镜像
https://hub.docker.com/r/jenkins/jenkins/tags
1 | docker pull jenkins/jenkins:2.251-alpine |
dockerfile
1 | FROM jenkins/jenkins:2.251-alpine |
编译镜像
1 | docker build -t czharbor.com/devops/cz-jenkins:lts-alpine . |
2.2、共享存储NFS部署
NFS服务部署:https://www.jianshu.com/p/26003390626e
创建NFS 动态供给参考:https://www.jianshu.com/p/092eb3aacefc
centos7-hub(192.168.145.130):磁盘所在机器
k8s-dn1():使用centos7-hub共享的磁盘
k8s-dn2():使用centos7-hub共享的磁盘
k8s-dn1():使用centos7-hub共享的磁盘
2.2.1、在 centos7-hub 上设置
1、关闭防火墙
1 | $ systemctl stop firewalld.service |
2、安装配置 nfs
1 | $ yum -y install nfs-utils rpcbind |
3、共享目录设置权限:
1 | $ mkdir -p /data/nfs/jenkins/ |
4、配置 nfs,nfs 的默认配置文件在 /etc/exports 文件下,在该文件中添加下面的配置信息:
1 | $ vi /etc/exports |
5、配置说明:
/data/nfs/jenkins/:是共享的数据目录
*:表示任何人都有权限连接,当然也可以是一个网段,一个 IP,也可以是域名
rw:读写的权限
sync:表示文件同时写入硬盘和内存
no_root_squash:当登录 NFS 主机使用共享目录的使用者是 root 时,其权限将被转换成为匿名使用者,通常它的 UID 与 GID,都会变成 nobody 身份
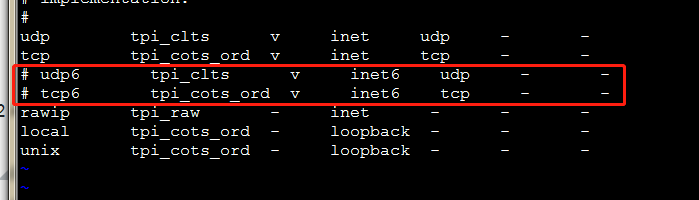
启动服务 nfs 需要向 rpc 注册,rpc 一旦重启了,注册的文件都会丢失,向他注册的服务都需要重启
1 | vi /etc/netconfig |
注意启动顺序,先启动 rpcbind
1 | $ systemctl start rpcbind.service |
看到上面的 Started 证明启动成功了。
然后启动 nfs 服务:
1 | $ systemctl start nfs.service |
同样看到 Started 则证明 NFS Server 启动成功了。
另外还可以通过下面的命令确认下:
1 | $ rpcinfo -p|grep nfs |
查看具体目录挂载权限:
1 | $ cat /var/lib/nfs/etab |
到这里nfs server就安装成功了,接下来在节点 k8s-n1 上来安装 nfs 的客户端来验证下 nfs
2.2.2、在 k8s-n1上设置
安装 nfs 当前也需要先关闭防火墙:
1 | $ systemctl stop firewalld.service |
然后安装 nfs
1 | $ yum -y install nfs-utils rpcbind |
禁用ipv6
1 | vi /etc/netconfig |
安装完成后,和上面的方法一样,先启动 rpc、然后启动 nfs:
1 | systemctl start rpcbind.service |
挂载数据目录 客户端启动完成后,在客户端来挂载下 nfs 测试下:
首先检查下 nfs 是否有共享目录:
1 | $ showmount -e 192.168.145.130 |
然后我们在客户端上新建目录:
1 | $ mkdir /data |
将 nfs 共享目录挂载到上面的目录:
1 | $ mount -t nfs 192.168.145.130:/data/nfs/jenkins /data |
挂载成功后,在客户端上面的目录中新建一个文件,然后观察下 nfs 服务端的共享目录下面是否也会出现该文件:
1 | $ touch /data/test.txt |
然后在 nfs 服务端查看:
1 | $ ls -ls /data/nfs/jenkins |
如果上面出现了 test.txt 的文件,那么证明 nfs 挂载成功了。
2.3、部署jenkins到k8s
jenkins-pv-pvc.yaml
1 | apiVersion: v1 |
jenkins-service-account.yaml
1 | apiVersion: v1 |
jenkins-statefulset.yaml
1 | apiVersion: apps/v1 |
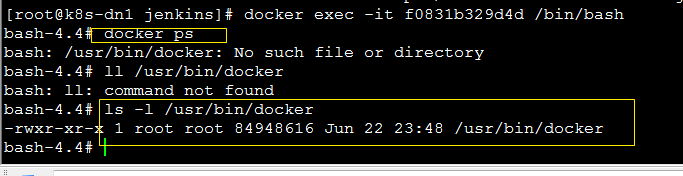
问题1:jenkins镜像里已经安装了docker,千万不能把 主机的 /usr/bin/docker 挂载到 docker 里去,否则会出错:
2
3
bash: /usr/bin/docker: No such file or directory
问题2:Jenkinsfile中运行docker 挂载 父容器的数据卷的时候,会继承父容器的网络,将 jenkins的网络模式指定为
hostNetwork: true表示使用主机的网络和iptables,这样kubectl发布应用才能正常运行
jenkins-service.yaml
1 | apiVersion: v1 |
jenkins-ingress.yaml
1 | apiVersion: extensions/v1beta1 |
执行部署动作
1 | [root@k8s-dn1 ~]# kubectl create ns devops |
访问
在hosts文件中添加
1 | 192.168.145.151 cz-jenkins.dev |
访问jenkins
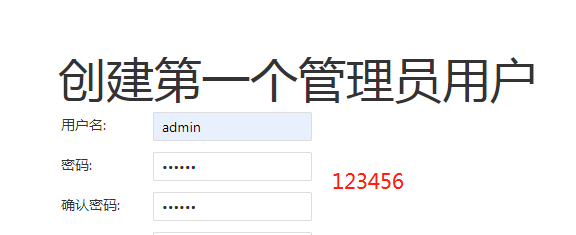
admin/123456
1 | cat /data/nfs/jenkins/secrets/initialAdminPassword |
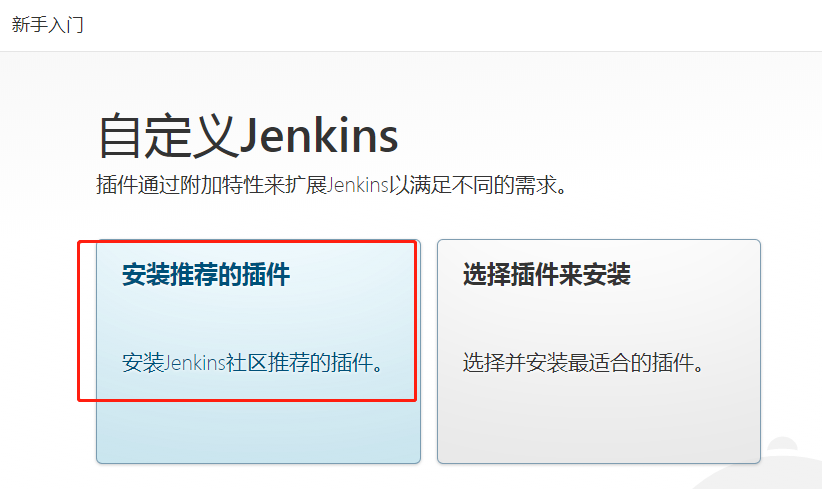
2.4、Jenkins初始化

2.5、Jenkins配置
系统管理 –> 插件管理 –> available,安装需要的插件,有的插件下载不下来可以去官网下载之后上传安装。
系统管理——》插件管理——》可选插件——》安装
Git
Git Parameter
Pipeline
Kubernetes
Kubernetes Continuous Deploy
Gitee
3、构建Jenkins Slave镜像
参考:https://github.com/jenkinsci/docker-jnlp-slave

1. 构建Jenkins Slave镜像环境准备
构建Jenkins Slave镜像环境准备:
代码拉取:git,安装git命令
单元测试:忽略,这不是我们擅长的,如果公司有可以写进来
代码编译:maven,安装maven包
构建镜像:Dockerfile文件、docker命令(通过挂载宿主机docker)
推送镜像:docker命令(通过挂载宿主机docker)
镜像启动后支持slave: 下载官方slave.jar包(获取:http://10.40.6.213:30006/jnlpJars/slave.jar)
启动 slave.ja包:jenkins-slave启动脚步(通过参考文档URL)
maven配置文件:settings.xml (这里配置阿里云的仓库源)
获取相关文件:
Dockerfile
jenkins-slave 启动脚步
settings.xml
slave.jar
创建目录并进入:
mkdir jenkins-slave && cd jenkins-slave
1 | [root@centos7cz jenkin]# pwd |
2. jenkins-slave启动脚本
1 | [root@centos7cz jenkins-slave]# vi jenkins-slave |
1 | cat jenkins-slave |
3、maven源配置文件settings.xml
maven源配置文件settings.xml,这里配置阿里云的源。
1 | [root@centos7cz jenkins-slave]# vi settings.xml |
1 | cat settings.xml |
4. Dockerfile配置文件
1 | [root@centos7cz jenkins-slave]# vi Dockerfile |
1 | FROM alpine:latest |
5. 构建镜像, 并推送至私有镜像仓库
1 | [root@centos7cz jenkins-slave]# docker build -t czharbor.com/devops/jenkins-slave:2.249 . |
4、构建maven镜像
4.1、Dockerfile
1 | FROM alpine:latest |
为了调用protoc,一定要安装glibc
https://github.com/sgerrand/alpine-pkg-glibc
否则会碰到如下问题:
用Alpine跑了JDK8的镜像结果发现,JDK还是无法执行.后来翻阅文档才发现
Java是基于GUN Standard C library(glibc)
Alpine是基于MUSL libc(mini libc)所以Alpine需要安装glibc的库,以下是官方给出wiki
https://wiki.alpinelinux.org/wiki/Running_glibc_programs
2
>
4.2、构建运行
1 | docker build -t czharbor.com/devops/cz-maven:3.6.3-alpine . |
5、构建kubectl镜像
dockerfile
1 | FROM alpine:latest |
1 | docker build -t czharbor.com/devops/kubectl:1.18.6-alpine . |
6、SpringBoot项目准备
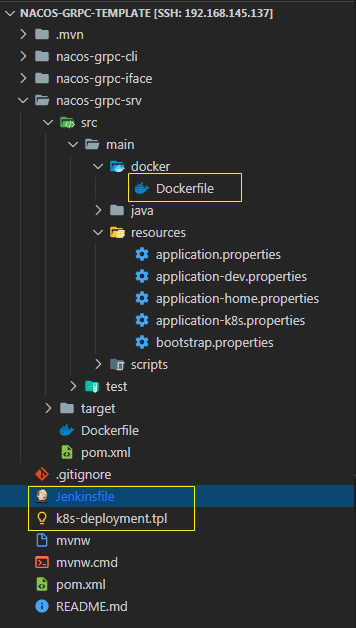
关键文件:
nacos-grpc-srv 本身的 Dockerfile
deployment.yaml的模板文件 k8s-deployment.tpl
jenkins Pipeline 文件 Jenkinsfile
deployment.yaml
1 | apiVersion: apps/v1 |
Jenkinsfile
1 | // 需要在jenkins的Credentials设置中配置jenkins-harbor-creds、jenkins-k8s-config参数 |
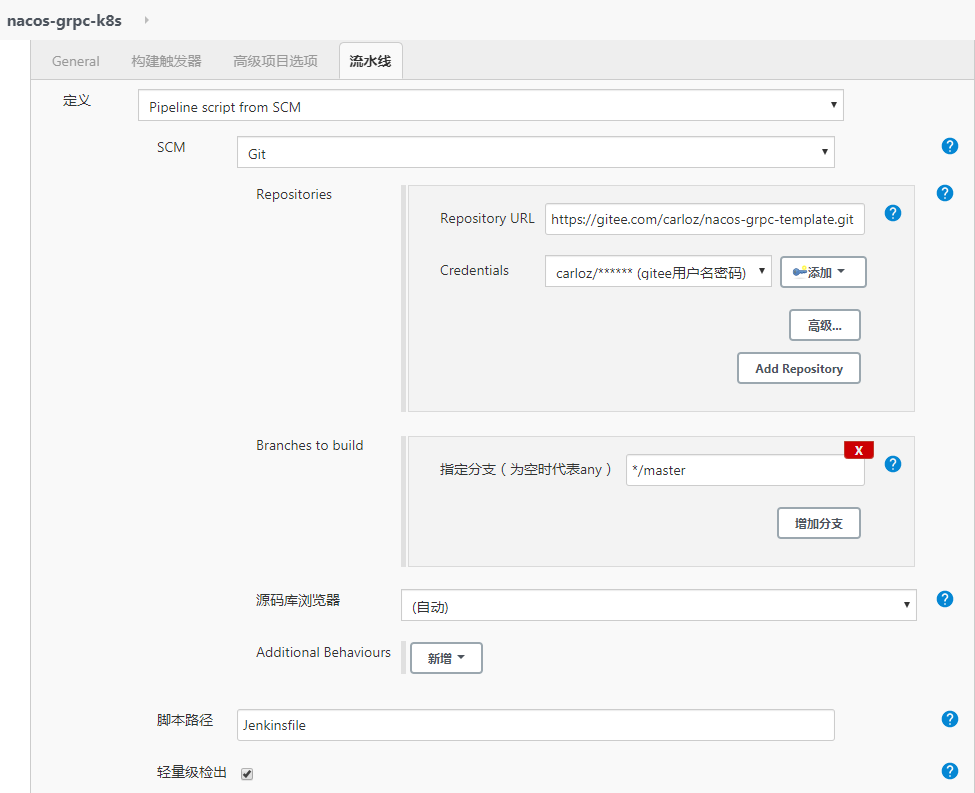
7、使用jenkins部署项目到k8s
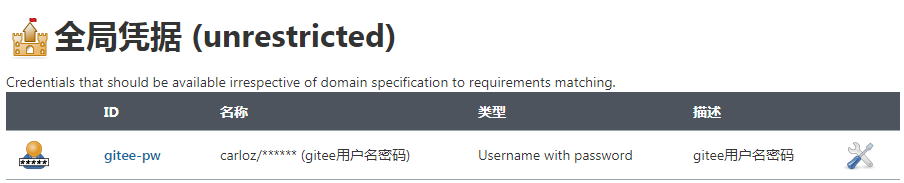
gitee秘钥
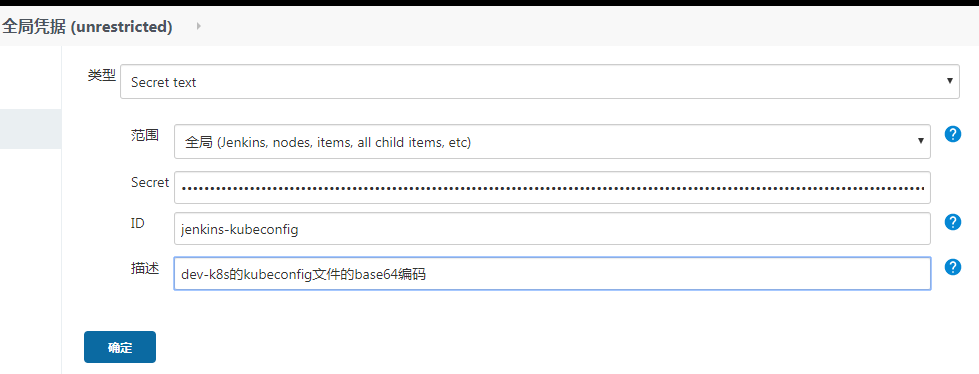
kubeconfig配置
1 | [root@k8s-dn1 ~]# base64 ~/.kube/config > kube-config.txt |
然后类似上一步,在jenkins凭据中增加配置文件内容。在凭据设置界面,类型选择为“Secret text”,ID设置为“jenkins-kubeconfig”(此处的ID必须与Jenkinsfile中的保持一致),Secret设置为上面经过base64编码后的配置文件内容。

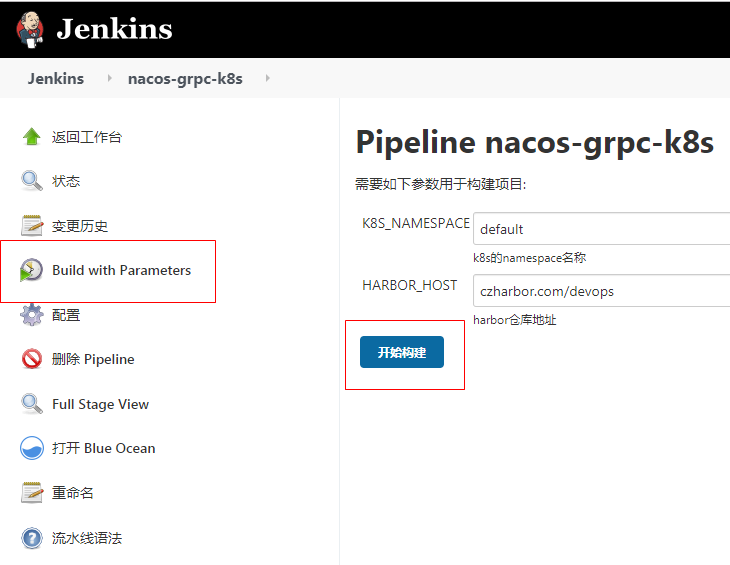
开始构建
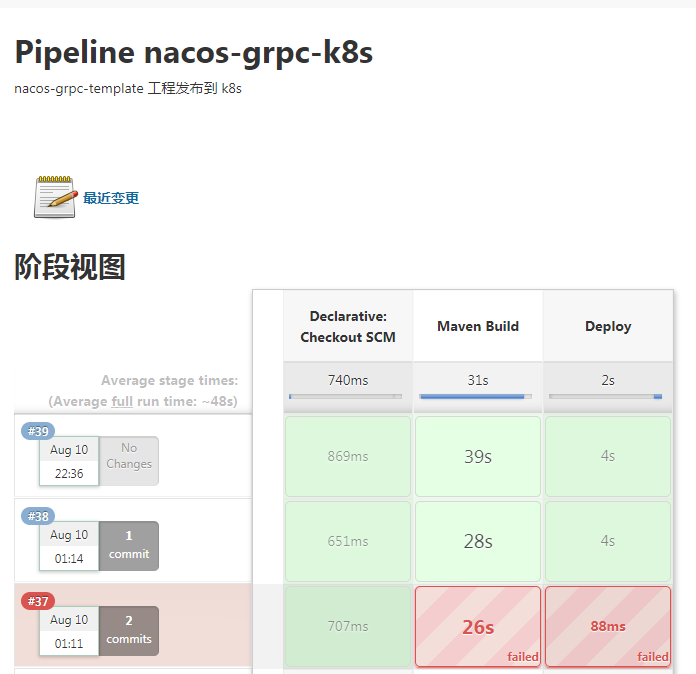
在k8s中查看
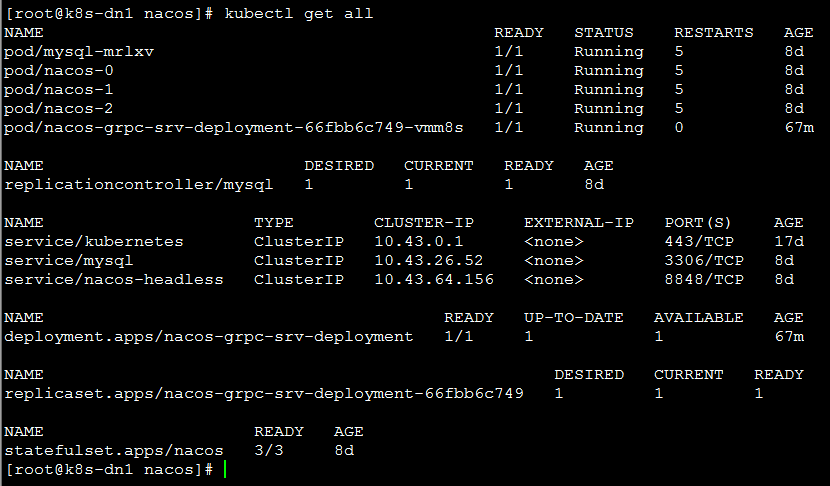
1 | kubectl logs -f pod/nacos-grpc-srv-deployment-66fbb6c749-vmm8s |
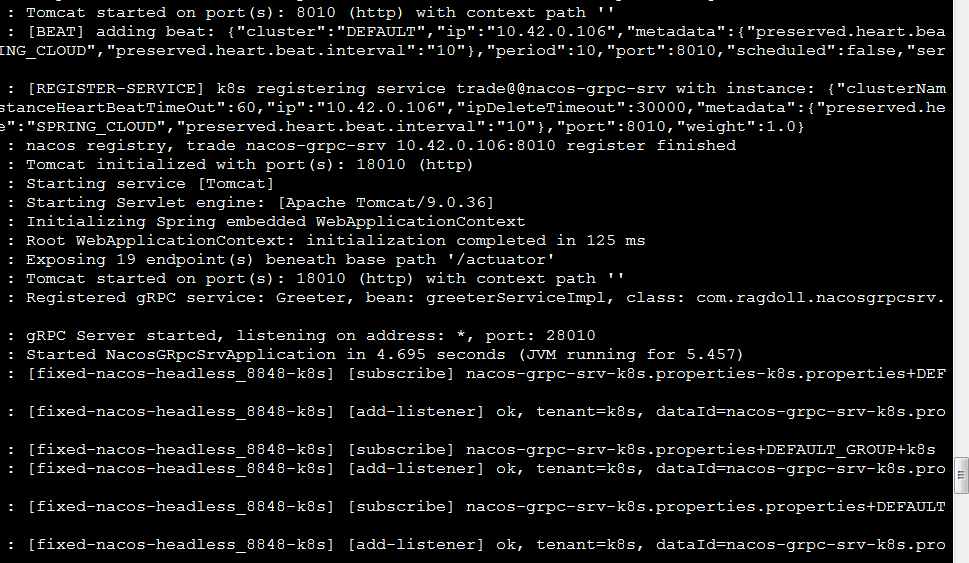
8、暴露nacos
1 | [root@k8s-dn1 nacos]# vi nacos-ingress.yaml |
1 | kubectl apply -f /data/nacos-grpc/nacos-ingress.yaml |
9、问题总结
1 | Unable to connect to the server: x509: certificate signed by unknown authority |
4、lucene源码阅读
Lucene写文档
主类:IndexWriter
org.apache.lucene.index.IndexWriter
API 调用过程:
1 | IndexWriter.addDocument(): |
1 | SimpleTextStoredFieldsWriter.writeField(); |
1 | public long addDocument(Iterable<? extends IndexableField> doc) { |
1 | private long updateDocument(final DocumentsWriterDeleteQueue.Node<?> delNode, |
org.apache.lucene.index.DocumentsWriter
1 | long updateDocument(final Iterable<? extends IndexableField> doc, |
1 | startStoredFields(docState.docID); // 开始存储Fields数据 |
Lucene删除文档
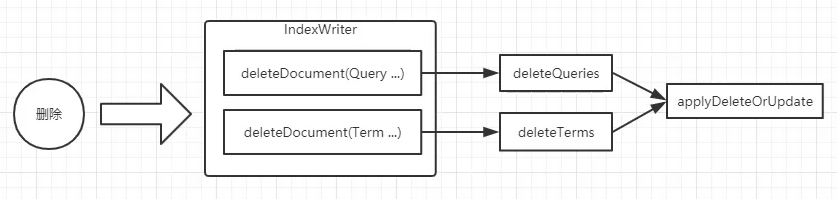
1 | IndexWriter.deleteDocuments(Term... terms); |
1 | package org.apache.lucene.index; |
1 | class DocumentsWriterDeleteQueue { |
1 | // 便于内存控制 |
1 | final class DocumentsWriterFlushQueue { |
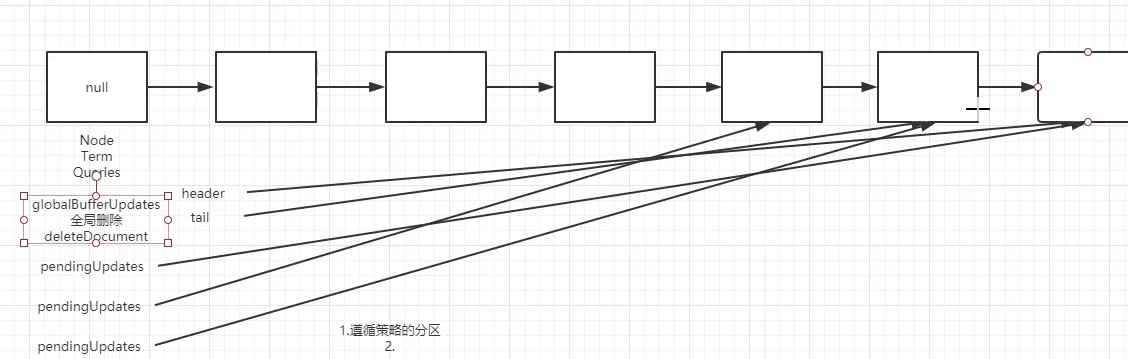
globalBufferUpdates 是全局删除,删除Document
pendingUpdates 是局部删除, 添加或更新Document
局部指向最自己最后的节点, 全局永远指向 整个链表 的 最后一个节点;
Lucene检索过程
查询代码:
1 | public class QueryParseTest { |
查询关键代码:
1 | package org.apache.lucene.search; |
Analysyer 包含两个组件
Tokenizer 分词器(分词 token)
TokenFilter 分词过滤器(大小写转换,词根cats)
Lucene70Codec => 实际去写Term
1 | public class Lucene70Codec extends Codec { |
lucene索引查询
一、Lucene 索引知识扩展
二、索引查询
Lucene 构建查询套路
常用 Query 查询类
TermQuery
BooleanQuery
分页查询
高亮显示
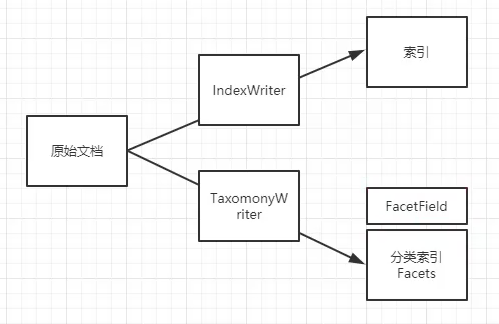
Facets 分类索引

多级分类(类似:省->市->县)
1 | <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-facet --> |

下钻查询
1 | DrillDownQuery drillDownQuery = new DrillDownQuery(config, query); |
查询平行维度
1 | DrillSideways ds = new DrillSideways(searcher, config, query); |
珍藏多年的git问题和操作清单
来源:微信公众号-猿天地
引言
本文整理自工作多年以来遇到的所有 Git 问题汇总,之前都是遗忘的时候去看一遍操作,这次重新整理了一下,发出来方便大家收藏以及需要的时候查找答案。
一、必备知识点

仓库
- Remote: 远程主仓库;
- Repository/History: 本地仓库;
- Stage/Index: Git追踪树,暂存区;
- workspace: 本地工作区(即你编辑器的代码)
二、git add 提交到暂存区,出错怎么办
一般代码提交流程为:工作区 -> git status 查看状态 -> git add . 将所有修改加入暂存区-> git commit -m "提交描述" 将代码提交到 本地仓库 -> git push 将本地仓库代码更新到 远程仓库
场景1:
当你改乱了工作区某个文件的内容,想直接丢弃工作区的修改时,用命令git checkout -- file。
git checkout
1 | // 丢弃工作区的修改 |
场景2:
当你不但改乱了工作区某个文件的内容,还添加到了暂存时,想丢弃修改,分两步,第一步用命令 git reset HEAD file,就回到了场景1,第二步按场景1操作。
三、git commit 提交到本地仓库,出错怎么办?
1. 提交信息出错
更改 commit 信息
1 | git commit --amend -m“新提交消息” |
2. 漏提交
commit 时,遗漏提交部分更新,有两种解决方案:
方案一:再次 commit
1
git commit -m“提交消息”
此时,git 上会出现两次 commit
方案二:遗漏文件提交到之前 commit 上
1
2git add missed-file // missed-file 为遗漏提交文件
git commit --amend --no-edit--no-edit表示提交消息不会更改,在 git 上仅为一次提交
3. 提交错误文件,回退到上一个 commit 版本,再 commit
git reset
删除指定的 commit
1 | // 修改版本库,修改暂存区,修改工作区 |
git revert
撤销 某次操作,此次操作之前和之后的commit和history都会保留,并且把这次撤销
作为一次最新的提交
1 | // 撤销前一次 commit |
git revert是提交一个新的版本,将需要revert的版本的内容再反向修改回去,
版本会递增,不影响之前提交的内容
git revert 和 git reset 的区别
git revert是用一次新的commit来回滚之前的commit,git reset是直接删除指定的commit。- 在回滚这一操作上看,效果差不多。但是在日后继续merge以前的老版本时有区别。因为
git revert是用一次逆向的commit“中和”之前的提交,因此日后合并老的branch时,导致这部分改变不会再次出现,但是git reset是之间把某些commit在某个branch上删除,因而和老的branch再次merge时,这些被回滚的commit应该还会被引入。 git reset是把HEAD向后移动了一下,而git revert是HEAD继续前进,只是新的commit的内容和要revert的内容正好相反,能够抵消要被revert的内容。
四、常用命令
1. 初始开发 git 操作流程
- 克隆最新主分支项目代码
git clone 地址 - 创建本地分支
git branch 分支名 - 查看本地分支
git branch - 查看远程分支
git branch -a - 切换分支
git checkout 分支名(一般修改未提交则无法切换,大小写问题经常会有,可强制切换git checkout 分支名 -f非必须慎用) - 将本地分支推送到远程分支
git push <远程仓库> <本地分支>:<远程分支>
2. git fetch
将某个远程主机的更新,全部/分支 取回本地(此时之更新了Repository)它取回的代码对你本地的开发代码没有影响,如需彻底更新需合并或使用git pull
3. git pull
拉取远程主机某分支的更新,再与本地的指定分支合并(相当与fetch加上了合并分支功能的操作)
4. git push
将本地分支的更新,推送到远程主机,其命令格式与git pull相似
5. 分支操作
- 使用 Git 下载指定分支命令为:
git clone -b 分支名仓库地址 - 拉取远程新分支
git checkout -b serverfix origin/serverfix - 合并本地分支
git merge hotfix:(将 hotfix 分支合并到当前分支) - 合并远程分支
git merge origin/serverfix - 删除本地分支
git branch -d hotfix:(删除本地 hotfix 分支) - 删除远程分支
git push origin --delete serverfix - 上传新命名的本地分支:
git push origin newName; - 创建新分支:
git branch branchName:(创建名为 branchName 的本地分支) - 切换到新分支:
git checkout branchName:(切换到 branchName 分支) - 创建并切换分支:
git checkout -b branchName:(相当于以上两条命令的合并) - 查看本地分支:
git branch - 查看远程仓库所有分支:
git branch -a - 本地分支重命名:
git branch -m oldName newName - 重命名远程分支对应的本地分支:
git branch -m oldName newName - 把修改后的本地分支与远程分支关联:
git branch --set-upstream-to origin/newName
五、优化操作
1. 拉取代码 pull –rebase
在团队协作过程中,假设你和你的同伴在本地中分别有各自的新提交,而你的同伴先于你 push了代码到远程分支上,所以你必须先执行 git pull 来获取同伴的提交,然后才能push 自己的提交到远程分支。
而按照 Git 的默认策略,如果远程分支和本地分支之间的提交线图有分叉的话(即不是 fast-forwarded),Git 会执行一次 merge 操作,因此产生一次没意义的提交记录,从而造成了像上图那样的混乱。
其实在 pull 操作的时候,,使用 git pull --rebase选项即可很好地解决上述问题。加上 --rebase 参数的作用是,提交线图有分叉的话,Git 会 rebase 策略来代替默认的 merge 策略。
假设提交线图在执行 pull 前是这样的:
1 | A---B---C remotes/origin/master |
如果是执行 git pull 后,提交线图会变成这样:
1 | A---B---C remotes/origin/master |
结果多出了 H 这个没必要的提交记录。如果是执行 git pull --rebase 的话,提交线图就会变成这样:
1 | remotes/origin/master |
F G 两个提交通过 rebase 方式重新拼接在 C 之后,多余的分叉去掉了,目的达到。
小结
大多数时候,使用 git pull --rebase是为了使提交线图更好看,从而方便 code review。
不过,如果你对使用 git 还不是十分熟练的话,我的建议是 git pull --rebase多练习几次之后再使用,因为 rebase 在 git 中,算得上是『危险行为』。
另外,还需注意的是,使用 git pull --rebase比直接 pull 容易导致冲突的产生,如果预期冲突比较多的话,建议还是直接 pull。
注意:
git pull = git fetch + git merge
git pull –rebase = git fetch + git rebase
2. 合代码 merge –no-ff
上述的 git pull --rebase 策略目的是修整提交线图,使其形成一条直线,而即将要用到的git merge --no-ff <branch-name> 策略偏偏是反行其道,刻意地弄出提交线图分叉出来。
假设你在本地准备合并两个分支,而刚好这两个分支是 fast-forwarded 的,那么直接合并后你得到一个直线的提交线图,当然这样没什么坏处,但如果你想更清晰地告诉你同伴:这一系列的提交都是为了实现同一个目的,那么你可以刻意地将这次提交内容弄成一次提交线图分叉。
执行 git merge --no-ff <branch-name> 的结果大概会是这样的:

中间的分叉线路图很清晰的显示这些提交都是为了实现 complete adjusting user domains and tags
更进一步
往往我的习惯是,在合并分支之前(假设要在本地将 feature 分支合并到 dev 分支),会先检查 feature 分支是否『部分落后』于远程 dev 分支:
1 | git checkout dev |
如果没有输出任何提交信息的话,即表示 feature 对于 dev 分支是 up-to-date 的。如果有输出的话而马上执行了 git merge --no-ff 的话,提交线图会变成这样:
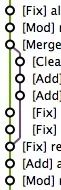
所以这时在合并前,通常我会先执行:
1 | git checkout feature |
这样就可以将 feature 重新拼接到更新了的 dev 之后,然后就可以合并了,最终得到一个干净舒服的提交线图。
再次提醒:像之前提到的,rebase 是『危险行为』,建议你足够熟悉 git 时才这么做,否则的话是得不偿失啊。
总结
使用 git pull --rebase 和 git merge --no-ff 其实和直接使用 git pull git merge 得到的代码应该是一样。
使用 git pull --rebase 主要是为是将提交约线图平坦化,而 git merge --no-ff 则是刻意制造分叉。
六、SSH
1. 查看是否生成了 SSH 公钥
1 | cd ~/.ssh |
其中 id_rsa 是私钥,id_rsa.pub 是公钥。
2. 如果没有那就开始生成,设置全局的user.name与user.email
1 | git config --list // 查看是否设置了user.name与user.email,没有的话,去设置 |
3. 输入 ssh-keygen 即可(或ssh-keygen -t rsa -C "email")
1 | ssh-keygen |
4. 生成之后获取公钥内容,输入 cat ~/.ssh/id_rsa.pub 即可, 复制 ssh-rsa 一直到 .local这一整段内容
1 | cat ~/.ssh/id_rsa.pub |
5. 打开 GitLab 或者 GitHub,点击头像,找到设置页
6. 左侧找到 SSH keys 按钮并点击,输入刚刚复制的公钥即可
七、暂存
git stash 可用来暂存当前正在进行的工作,比如想 pull 最新代码又不想 commit , 或者另为了修改一个紧急的 bug ,先 stash,使返回到自己上一个 commit,,改完 bug 之后再 stash pop , 继续原来的工作;
- 添加缓存栈:
git stash; - 查看缓存栈:
git stash list; - 推出缓存栈:
git stash pop; - 取出特定缓存内容:
git stash apply stash@{1};
八、文件名过长错误
Filename too long warning: Clone succeeded, but checkout failed.
1 | git config --system core.longpaths true |
九、邮箱和用户名
查看
1 | git config user.name |
修改
1 | git config --global user.name "username" |
十、.gitignore 更新后生效:
1 | git rm -r --cached . |
十一、同步Github fork 出来的分支
1、配置remote,指向原始仓库
1 | git remote add upstream https://github.com/InterviewMap/InterviewMap.git |
2、上游仓库获取到分支,及相关的提交信息,它们将被保存在本地的 upstream/master 分支
1 | git fetch upstream |
3、切换到本地的 master 分支
1 | git checkout master |
4、把 upstream/master 分支合并到本地的 master 分支,本地的 master 分支便跟上游仓库保持同步了,并且没有丢失本地的修改。
1 | git merge upstream/master |
5、上传到自己的远程仓库中
1 | git push |
高并发 —— 限流算法
一、限流的作用
由于API接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机。
限流(Rate limiting)指对应用服务的请求进行限制,例如某一接口的请求限制为100个每秒,对超过限制的请求则进行快速失败或丢弃。
限流可以应对:
- 热点业务带来的突发请求;
- 调用方bug导致的突发请求;
- 恶意攻击请求。
因此,对于公开的接口最好采取限流措施。
二、限流算法
实现限流有很多办法,在程序中时通常是根据每秒处理的事务数(Transaction per second)来衡量接口的流量。
本文介绍几种最常用的限流算法:
- 固定窗口计数器;
- 滑动窗口计数器;
- 漏桶;
- 令牌桶;
1、 固定窗口计数器算法
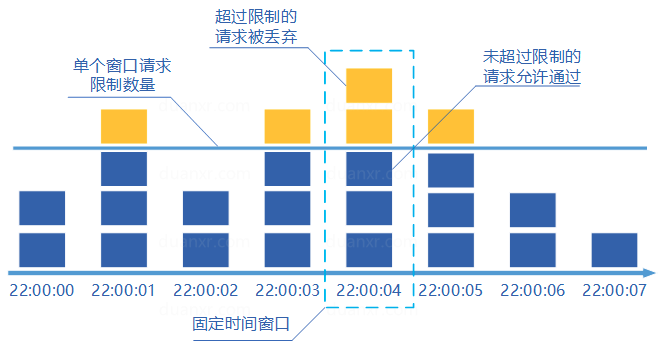
固定窗口计数器算法概念如下:
- 将时间划分为多个窗口;
- 在每个窗口内每有一次请求就将计数器加一;
- 如果计数器超过了限制数量,则本窗口内所有的请求都被丢弃当时间到达下一个窗口时,计数器重置。
固定窗口计数器是最为简单的算法,但这个算法有时会让通过请求量允许为限制的两倍。考虑如下情况:限制1秒内最多通过5个请求,在第一个窗口的最后半秒内通过了5个请求,第二个窗口的前半秒内又通过了5个请求。这样看来就是在1秒内通过了10个请求。
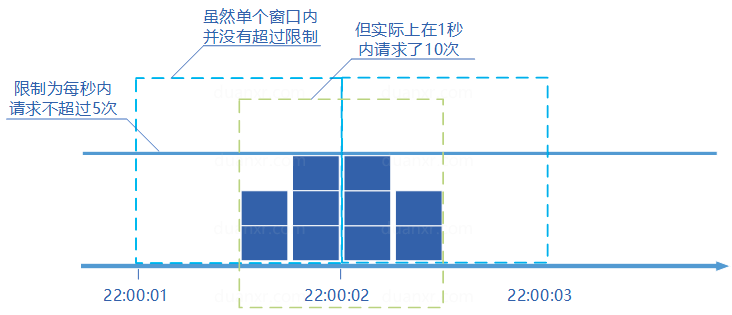
2、滑动窗口计数器算法
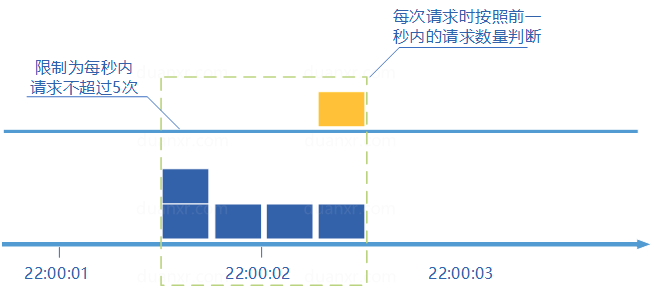
滑动窗口计数器算法概念如下:
- 将时间划分为多个区间;
- 在每个区间内每有一次请求就将计数器加一维持一个时间窗口,占据多个区间;
- 每经过一个区间的时间,则抛弃最老的一个区间,并纳入最新的一个区间;
- 如果当前窗口内区间的请求计数总和超过了限制数量,则本窗口内所有的请求都被丢弃。
滑动窗口计数器是通过将窗口再细分,并且按照时间”滑动”,这种算法避免了固定窗口计数器带来的双倍突发请求,但时间区间的精度越高,算法所需的空间容量就越大。
3、漏桶算法

漏桶算法概念如下:
- 将每个请求视作”水滴”放入”漏桶”进行存储;
- “漏桶”以固定速率向外”漏”出请求来执行如果”漏桶”空了则停止”漏水”;
- 如果”漏桶”满了则多余的”水滴”会被直接丢弃。
漏桶算法多使用队列实现,服务的请求会存到队列中,服务的提供方则按照固定的速率从队列中取出请求并执行,过多的请求则放在队列中排队或直接拒绝。
漏桶算法的缺陷也很明显,当短时间内有大量的突发请求时,即便此时服务器没有任何负载,每个请求也都得在队列中等待一段时间才能被响应。
4、令牌桶算法
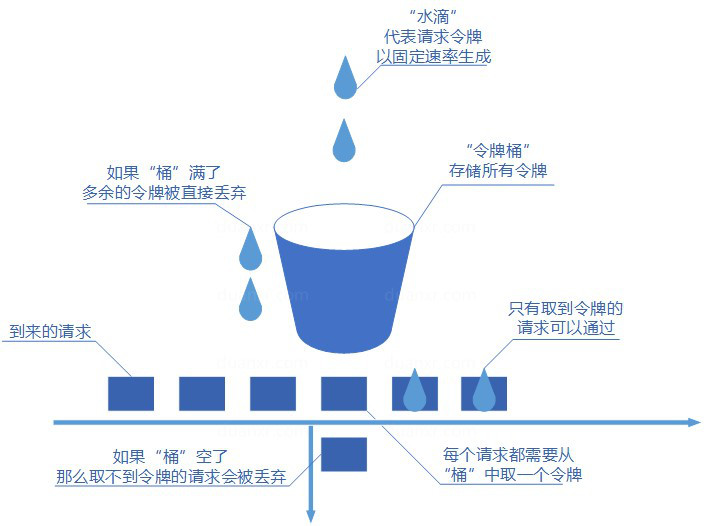
令牌桶算法概念如下:
- 令牌以固定速率生成;
- 生成的令牌放入令牌桶中存放,如果令牌桶满了则多余的令牌会直接丢弃,当请求到达时,会尝试从令牌桶中取令牌,取到了令牌的请求可以执行;
- 如果桶空了,那么尝试取令牌的请求会被直接丢弃。
令牌桶算法既能够将所有的请求平均分布到时间区间内,又能接受服务器能够承受范围内的突发请求,因此是目前使用较为广泛的一种限流算法。
三、单体应用限流
1、信号量Semaphore限流
private final Semaphore permit = new Semaphore(10, true);
2、Guava的RateLimiter实现限流
RateLimiter limiter = RateLimiter.create(1.0); // 这里的1表示每秒允许处理的量为1个
3、利用Atomic类自己实现限流算法
四、接入层限流
1、nginx限流
1、自带模块 limit_req_zone and limit_req
https://www.nginx.com/blog/rate-limiting-nginx/
2、nginx+lua+redis 实现复杂的限流算法
openresty了解一下
五、分布式限流
1、为什么要分布式限流
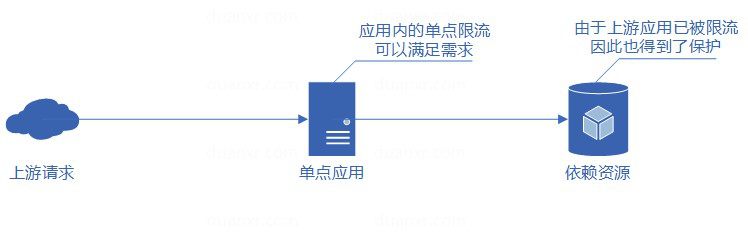
当应用为单点应用时,只要应用进行了限流,那么应用所依赖的各种服务也都得到了保护。
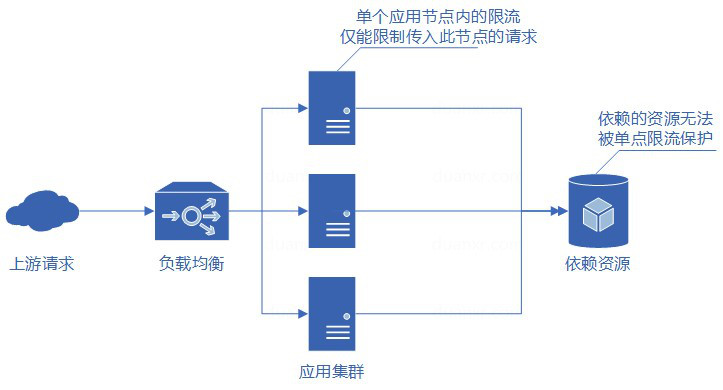
但线上业务出于各种原因考虑,多是分布式系统,单节点的限流仅能保护自身节点,但无法保护应用依赖的各种服务,并且在进行节点扩容、缩容时也无法准确控制整个服务的请求限制。
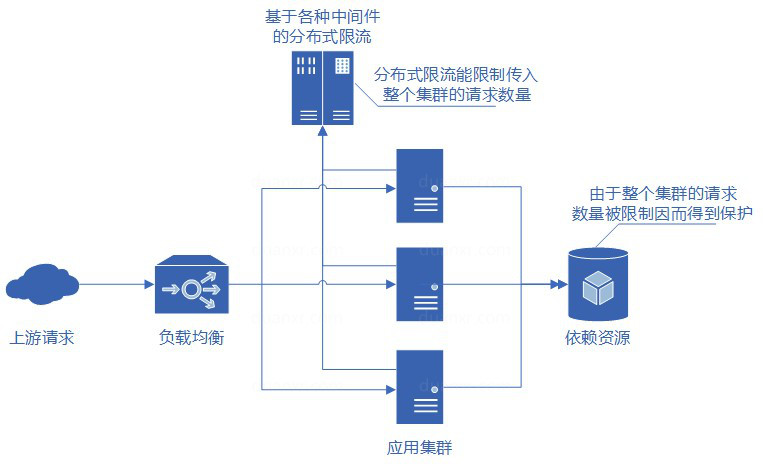
而如果实现了分布式限流,那么就可以方便地控制整个服务集群的请求限制,且由于整个集群的请求数量得到了限制,因此服务依赖的各种资源也得到了限流的保护。
2、现有方案
而分布式限流常用的则有Hystrix、resilience4j、Sentinel等框架,但这些框架都需引入第三方的类库,对于国企等一些保守的企业,引入外部类库都需要经过层层审批,较为麻烦。
3、代码+redis+lua实现
分布式限流本质上是一个集群并发问题,而Redis作为一个应用广泛的中间件,又拥有单进程单线程的特性,天然可以解决分布式集群的并发问题。本文简单介绍一个通过Redis实现单次请求判断限流的功能。
1、脚本编写
经过上面的对比,最适合的限流算法就是令牌桶算法。而为实现限流算法,需要反复调用Redis查询与计算,一次限流判断需要多次请求较为耗时。因此我们采用编写Lua脚本运行的方式,将运算过程放在Redis端,使得对Redis进行一次请求就能完成限流的判断。
令牌桶算法需要在Redis中存储桶的大小、当前令牌数量,并且实现每隔一段时间添加新的令牌。最简单的办法当然是每隔一段时间请求一次Redis,将存储的令牌数量递增。
但实际上我们可以通过对限流两次请求之间的时间和令牌添加速度来计算得出上次请求之后到本次请求时,令牌桶应添加的令牌数量。因此我们在Redis中只需要存储上次请求的时间和令牌桶中的令牌数量,而桶的大小和令牌的添加速度可以通过参数传入实现动态修改。
由于第一次运行脚本时默认令牌桶是满的,因此可以将数据的过期时间设置为令牌桶恢复到满所需的时间,及时释放资源。
编写完成的Lua脚本如下:
1 | local ratelimit_info = redis.pcall('HMGET',KEYS[1],'last_time','current_token') |
2、执行限流
这里使用Spring Data Redis来进行Redis脚本的调用。
编写Redis脚本类:
1 | public class RedisReteLimitScript implements RedisScript<String> { |
通过RedisTemplate对象执行脚本:
1 | public boolean rateLimit(String key, int max, int rate) { |
rateLimit方法传入的key为限流接口的ID,max为令牌桶的最大大小,rate为每秒钟恢复的令牌数量,返回的boolean即为此次请求是否通过了限流。为了测试Redis脚本限流是否可以正常工作,我们编写一个单元测试进行测试看看。
1 |
|
设置令牌桶大小为10,令牌桶每秒恢复10个,启动10个线程在短时间内进行30次请求,并输出每次限流查询的结果。日志输出:
1 | [19:12:50,283]true |
可以看到,在0.1秒内请求的30次请求中,除了初始的10个令牌以及随时间恢复的1个令牌外,剩下19个没有取得令牌的请求均返回了false,限流脚本正确的将超过限制的请求给判断出来了,业务中此时就可以直接返回系统繁忙或接口请求太过频繁等提示。
3、开发中遇到的问题
1)Lua变量格式
Lua中的String和Number需要通过tonumber()和tostring()进行转换。
2)Redis入参
Redis的pexpire等命令不支持小数,但Lua的Number类型可以存放小数,因此Number类型传递给 Redis时最好通过math.ceil()等方式转换以避免存在小数导致命令失败。
3)Time命令
由于Redis在集群下是通过复制脚本及参数到所有节点上,因此无法在具有不确定性的命令后面执行写入命令,因此只能请求时传入时间而无法使用Redis的Time命令获取时间。
3.2版本之后的Redis脚本支持redis.replicate_commands(),可以改为使用Time命令获取当前时间。
4)潜在的隐患
由于此Lua脚本是通过请求时传入的时间做计算,因此务必保证分布式节点上获取的时间同步,如果时间不同步会导致限流无法正常运作。
各种主流 SQLServer 迁移到 MySQL 工具对比
四种工具分别是:
● SQLyog(https://www.webyog.com/product/sqlyog)
● Navicat Premium(https://www.navicat.com/products/navicat-premium)
● Mss2sql(http://www.convert-in.com/)
● DB2DB(http://www.szmesoft.com/DB2DB)
由于公司需要处理的是业务数据库,因此必须保证数据转换的准确率(不允许丢失数据,数据库字段、索引完整),并且需要保证数据库迁移后能立即使用。因 此在实施数据迁移前,对这几种 SQLServer 到 MySQL 的迁移工具进行一个全面测试。下面我们将基于以下需求为前提进行测试:
● 软件易用性
● 处理速度和内存占用
● 数据完整性
● 试用版限制
● 其它功能
一、测试用的源数据库和系统
用于测试的源数据库名为 MesoftReportCenter。由于其中一个测试工具试用版限制只能处理两张数据表的原因,因此我们只选取了记录数最多的两张数据 表:HISOPChargeIntermediateResult 和 HISOPChargeItemIntermediateResult。两张数据表合计的记录数约为 328万,数据库不算大,但针对本次进行测试也基本上足够了。
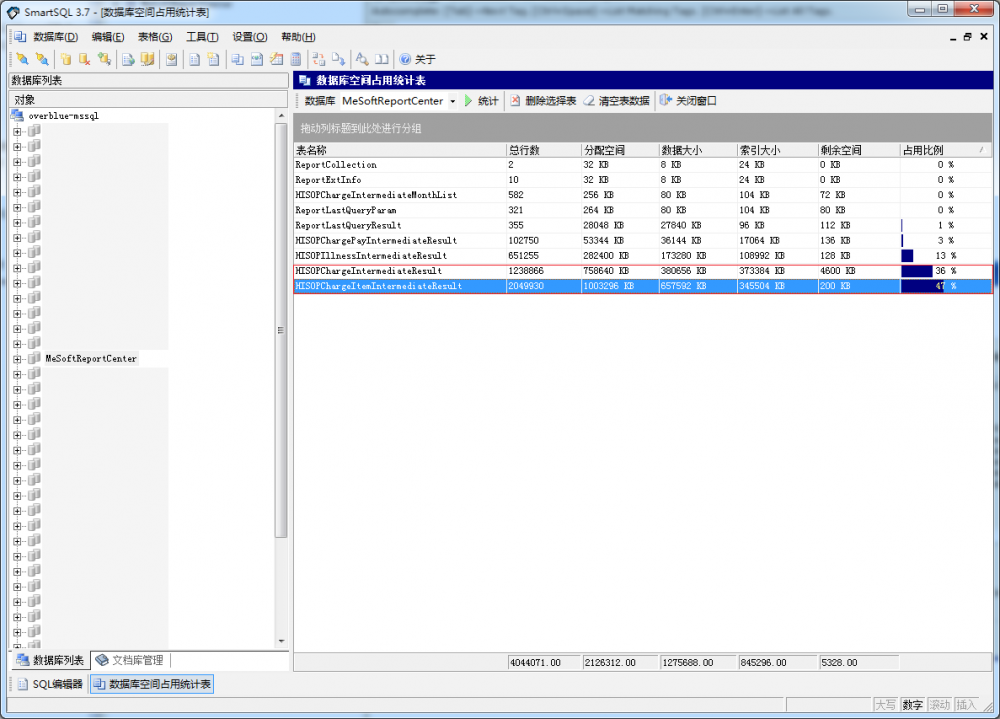 SQLServer 服务器和 MySQL 服务器分别运行在两台独立的虚拟机系统中,而所有的待测试程序都运行在 MySQL 所在的服务器上面。其中:
SQLServer 服务器和 MySQL 服务器分别运行在两台独立的虚拟机系统中,而所有的待测试程序都运行在 MySQL 所在的服务器上面。其中:
SQLServer 服务配置:
● 操作系统:Windows XP
● 内 存:2GB
● 100MB 电信光纤
MySQL 服务配置:
● 操作系统:Windows XP
● 内 存:1GB
● 100MB 电信光纤
同时为了测试的公平性,除 Mss2SQL 外,所有软件都是直接从官网下载最新的版本。 Mss2SQL 由于试用版的限制原因没有参与测试,而使用了网上唯一能找到的 5.3 破解版进行测试。
二、软件易用性评测
软件易用性主要是指软件在导入前的配置是否容易。由于很多软件设计是面向程序员而非一般的数据库管理人员、甚至是普通的应用程序实施人员,而这一类人员很 多时候并没有数据源配置经验。因为一些使用 ODBC 或者 ADO 进行配置的程序往往会让这类用户造成困扰(主要是不知道应该选择什么类型的数据库驱动程序)。下面让我们看看四个工具的设计界面:
1、SQLyog
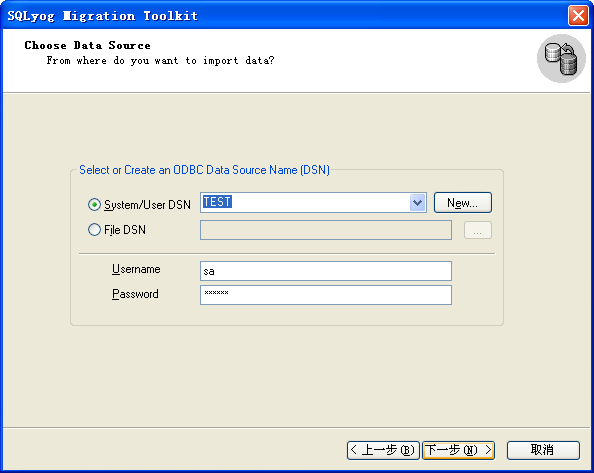
 SQLyog 使用的是古老的 ODBC 连接,但对于新一代的程序来说,这种方式的非常的不熟悉并且不容易使用,并且必须要求本机安装好相应的数据库的 ODBC 驱动程序(SQL Server 一般自带好)。
SQLyog 使用的是古老的 ODBC 连接,但对于新一代的程序来说,这种方式的非常的不熟悉并且不容易使用,并且必须要求本机安装好相应的数据库的 ODBC 驱动程序(SQL Server 一般自带好)。
2、Navicat Premium
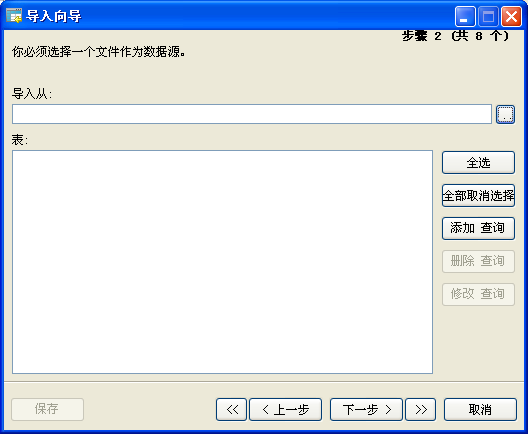
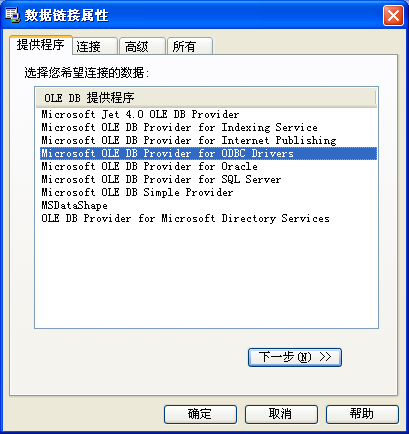
Navicat Premium 是四个应用工具中设计最不人性化的一个:从上图怎么也想像不到要点按那个小按钮来添加一个新的连接,并且这个连接设置不会保存,每次导入时都必须重新设 置。 Navicat Premium 使用的是比 ODBC 稍先进的 ADO 设置方式(199X年代的产物),但使用上依然是针对老一代的程序员。
3、Mss2sql
Mss2sql 是最容易在百度上搜索出来的工具,原因之一是它出现的时间较早。

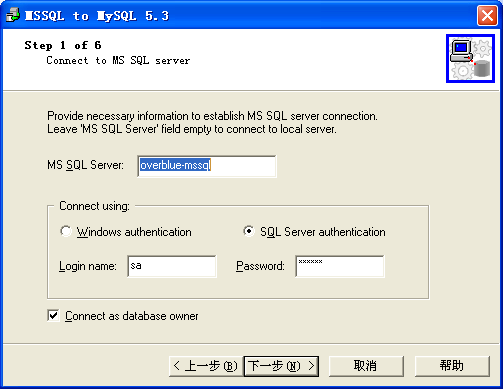
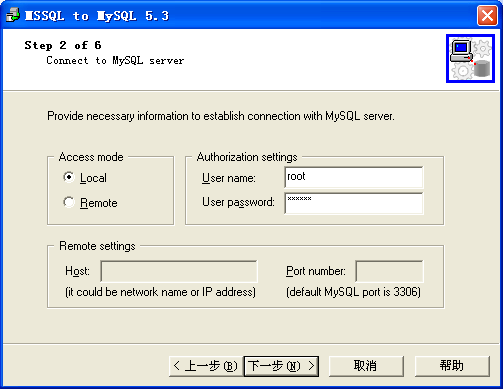
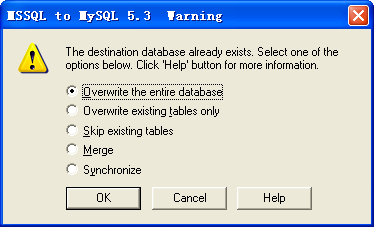
Mss2sql 由于是很有针对性的从 SQLServer 迁移到 MySQL,因为界面使用了操作向导设计,使用非常容易。同时在设置的过程中,有非常多的选项进行细节调整,可以感觉到软件经过了相当长一段时间的使用渐渐完善出来的。
4、DB2DB
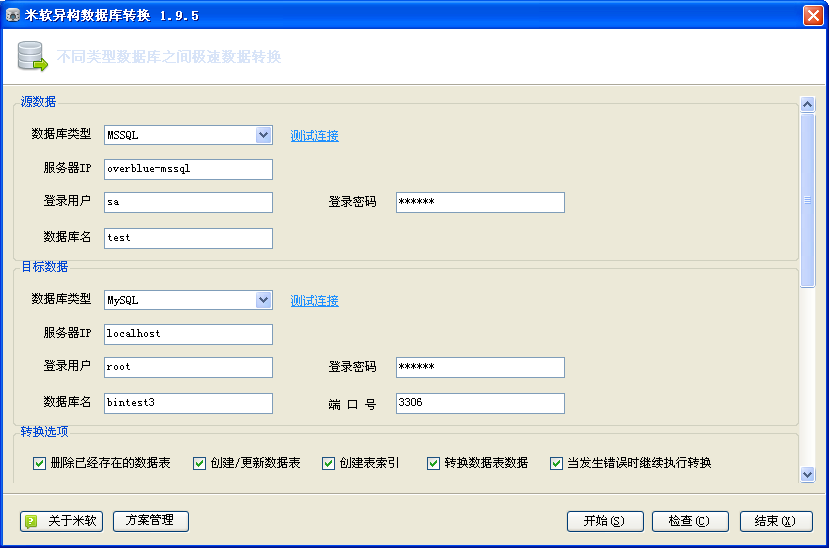
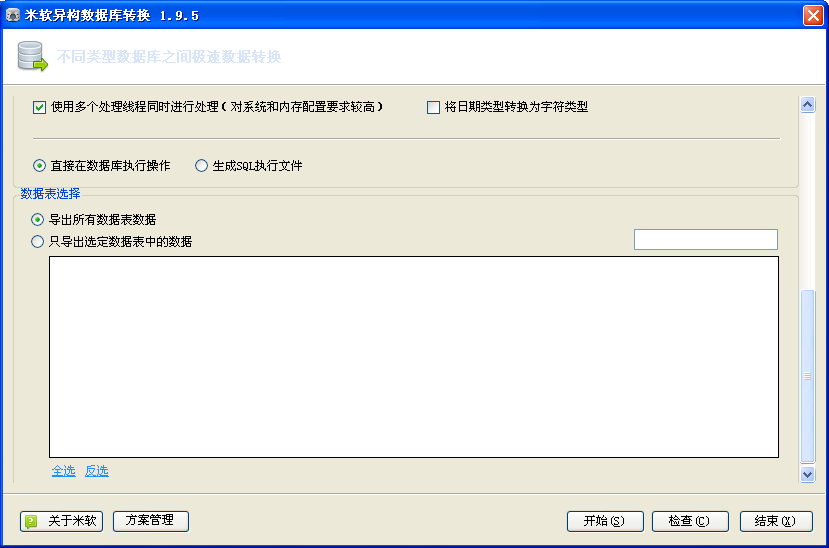
DB2DB 由于是由国人开发,因此无论是界面还是提示信息,都是全程汉字。另外,由于 DB2DB 在功能上很有针对性,因为界面设计一目了然和易使用。和 mss2sql 一样, DB2DB 提供了非常多的选项供用户进行选择和设置。
三、处理速度和内存占用评测
在本评测前,本人的一位资深同事曾经从网上下载了某款迁移软件,把一个大约2500万记录数的数据表转送到阿里云 MySQL,结果经过了三天三夜(好在其中两天是星期六和星期日两个休息日)都未能迁移过来。因此这一次需要对这四个工具的处理速度作一个详细的测试。
考虑到从 SQL Server 迁移到 MySQL 会出现两种不同的场景:
● 从 SQL Server 迁移到本地 MySQL 进行代码测试和修改;
● 从 SQL Server 迁移到云端 MySQL 数据库正式上线使用;
因此我们的测试也会针对这两个场景分别进行评测,测试结果如下(记录数约为 328万):
| 工具名称 | 迁移到本地耗时 | 迁移到云端耗时 | 最高CPU占用 | 内存占用 |
|---|---|---|---|---|
| SQLyog | 2806秒 | 4438秒 | 08% | 20MB |
| Navicat Premium | 598秒 | 3166秒 | 52% | 32MB |
| Mss2sql | 726秒 | 1915秒 | 30% | 12MB |
| DB2DB | 164秒 | 1282秒 | 34% | 40MB |
注:红色字体标识为胜出者。
以下为测试过程中的截图:
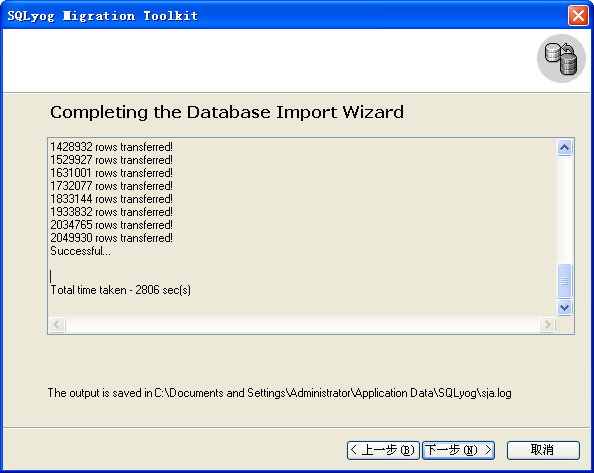
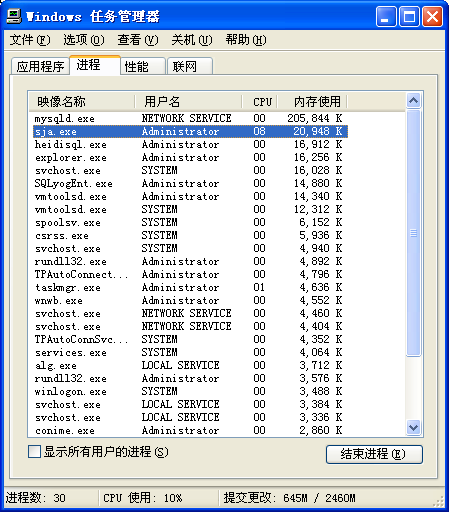
1、SQLyog
2、Navicat Premium
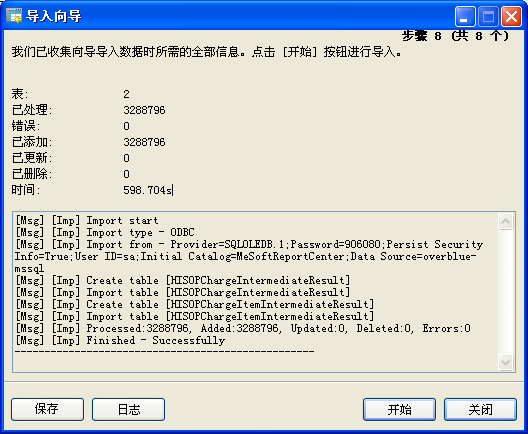
注意:我们在测试 Navicat Premium 迁移到 MySQL 时发现,对于 SQL Server 的 Money 类型支持不好(不排除还有其它的数据类型支持不好)。Money 类型字段默认的小数位长度为 255,使得无法创建数据表导致整个测试无法成功,需要我们逐张表进行表结构修改才能完成测试过程。
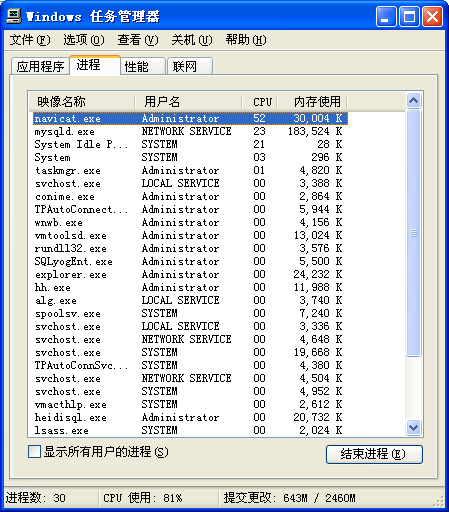
 Navicat Premium 的处理速度属于中等,不算快也不算慢,但 CPU 占用还有内存占用都处于高位水平。不过以现在的电脑硬件水平来说,还是可以接受。但 CPU 占用率太高,将使得数据在导入的过程中,服务器不能用于其它用途。
Navicat Premium 的处理速度属于中等,不算快也不算慢,但 CPU 占用还有内存占用都处于高位水平。不过以现在的电脑硬件水平来说,还是可以接受。但 CPU 占用率太高,将使得数据在导入的过程中,服务器不能用于其它用途。
3、Mss2sql
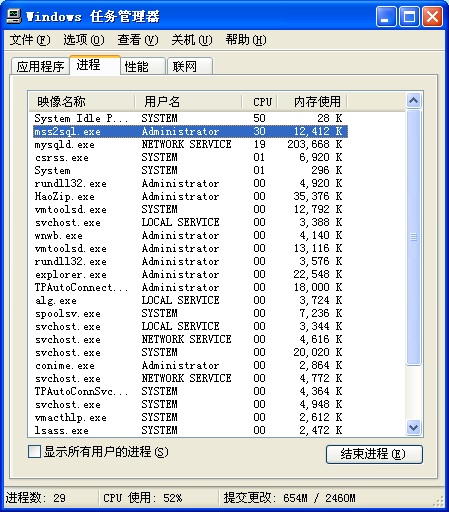 Mss2sql 并没有提供计时器,因此我们使用人工计时的方法,整个过程处理完毕大于是 726 秒。Mss2sql 的 CPU 占用率相对其它工具来说较高,但仍属于可以接受的范围之内。
Mss2sql 并没有提供计时器,因此我们使用人工计时的方法,整个过程处理完毕大于是 726 秒。Mss2sql 的 CPU 占用率相对其它工具来说较高,但仍属于可以接受的范围之内。
4、DB2DB
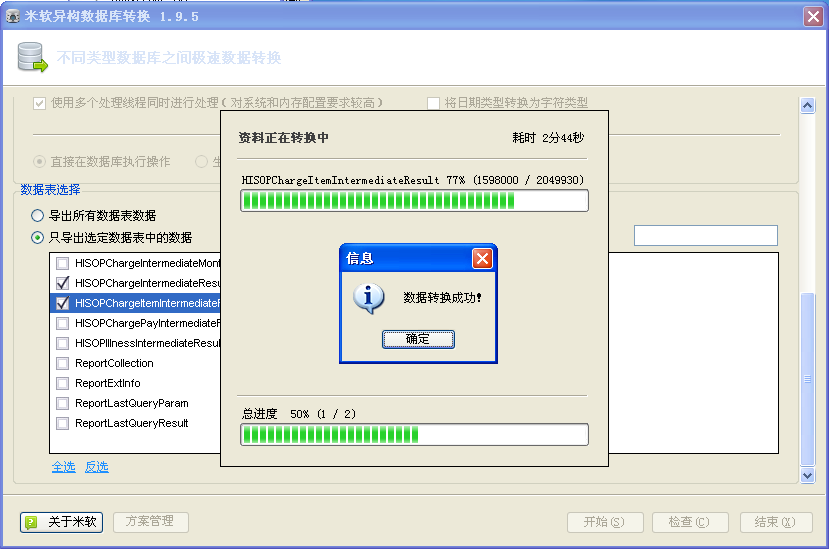
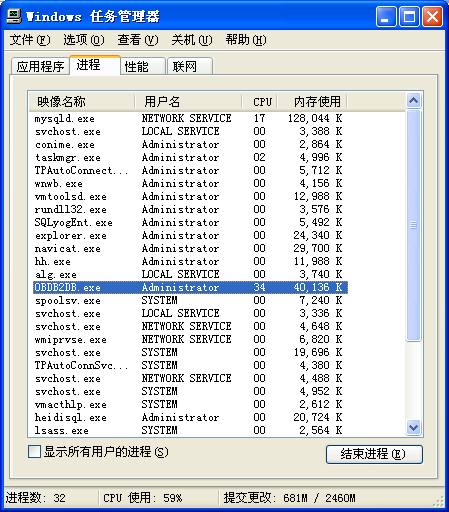
DB2DB 同样迁移 300万数据时,仅仅使用了 2 分 44 秒,这个速度相当惊人。不过最后的结果出现一个 BUG,就是提示了转换成功,但后面的进度条却没有走完(在后面的数据完整性评测中,我们验证了数据其实是已经全部处理完毕了)。
四、数据完整性评测
把数据准确无误地从 SQL Server 迁移到 MySQL 应该作为这些工具的一个基本要求,因此这里我们对四种工具转换之后的结果进行检查。

我们通过后台 SQL 对记录数进行检查,发现所有的工具都能把记录完整地迁移到新的数据库。如果仔细观察,可以发现上图中各个数据库的大小是不一致的,基本的判断是由于各种工 具在映射数据表字段时,字段长度取值可能不能而引起的。而 mesoftreportcenter2 数据库大小比起其它数据库差不多少了一半,这引起了我们的注意。通过分析,我们发现 Navicat Premium 在迁移数据库时,并不会为该数据库所有数据表创建索引和主键,缺少索引和主键的数据库大小显然比其它数据库要少得多。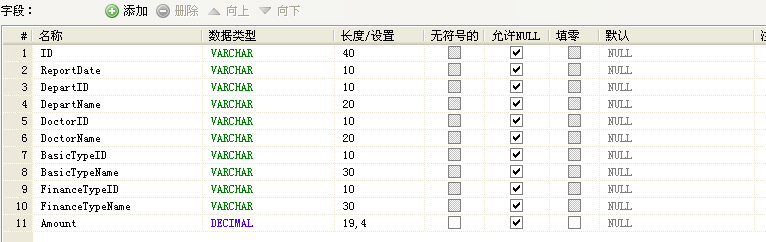
为了解各工具迁移后的数据库能否立即应用于生产环境,我们对创建后的数据表进行了更深入的分析,发现各工具对字段默认值的支持程度也不尽相同。其中:
● SQLyog:完整支持 SQL Server 的默认值;
● Navicat Premium:完全不支持默认值,所有迁移后的数据表都没有默认值;
● Mss2sql:支持默认值但有严重错误;
● DB2DB:完整支持 SQL Server 的默认值。
Mss2sql 的默认值有一个严重的错误,在 SQL Server 中字段默认值为空字符串 ”,但迁移之后变成两个 ” 符号。Mss2sql 这个严重的错误会使得程序在正式环境运行后,数据库会产生错误的数据!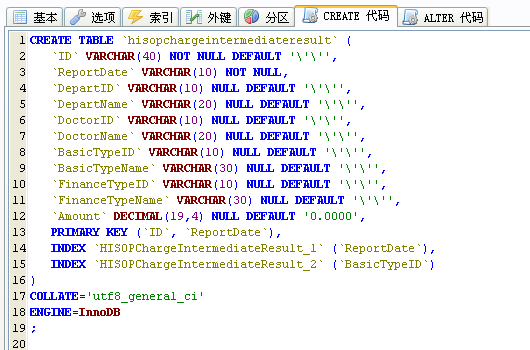
在一些老旧的系统中,数据库还会存在 Text、二进制类型的字段数据,通过测试对比后,四种工具都完美支持 Text 和 二进制(Image)类型字段。
小结:
| 测试项目 | SQLyog | Navicat Premium | Mss2sql | DB2DB |
|---|---|---|---|---|
| 表结构 | 支持 | 支持 | 支持 | 支持 |
| 字段长度 | 支持 | 部分支持(对Money等支持不好) | 支持 | 支持 |
| 数据 | 完整 | 完整 | 完整 | 完整 |
| 索引 | 支持 | 不支持 | 支持 | 支持 |
| 关键字 | 支持 | 不支持 | 支持 | 支持 |
| 默认值 | 支持 | 不支持 | 支持,但有严重错误 | 支持 |
| 二进制数据 | 支持 | 支持 | 支持 | 支持 |
五、各工具其它功能及试用版限制
估计由于数据库同步会存在一些技术难题的原因,4 款工具目前都是只是提供试用版本,最后我们来看看四个工具的试用版本各自的限制是什么:
| 工具名 | 价格 | 试用限制 | 其它功能 | 备注 |
|---|---|---|---|---|
| SQyog | $199 | 30天试用,并且只允许转换两张数据表 | 无 | |
| Navicat Premium | $799 | 无 | ||
| Mss2sql | $49 | 每张数据表只允许有50秒处理时间 | 支持导出为 SQL | |
| DB2DB | ¥199 | 10万记录限制 | 支持导出为 SQL |
四种工具中,由于 SQLyog 和 Navicat Premium 提供了额外的管理功能,所以价格相比其它两款工具的要高得多。特别是 Navicat,必须是 Premium 版本才提供数据转换的功能。而 Mss2sql 最新版本的试用版只提供了 50 秒处理时间,因为实用价值不大。而笔者与 DB2DB 作者联系时得知,DB2DB 设置 10万记录限制,主要是考虑国内很多小型软件记录数都是少于 10 万笔,而这一类人群一般都是小型创业团队。
六、评测总结
最后,对四款软件的测试结果作一个整体的总结:
| 工具名 | 处理速度 | 数据完整性 | 价格 | 推荐度 |
|---|---|---|---|---|
| SQLyog | ★☆☆☆☆ | ★★★★★ | ★★☆☆☆ | ★★☆☆☆ |
| Navicat Premium | ★★★☆☆ | ★☆☆☆☆ | ★☆☆☆☆ | ★☆☆☆☆ |
| Mss2sql | ★★☆☆☆ | ★★★☆☆ | ★★★★☆ | ★★★☆☆ |
| DB2DB | ★★★★★ | ★★★★★ | ★★★★★ | ★★★★★ |
以上四款软件中,最不推荐使用的是 Navicat Premium,主要原因是数据的完整性表现较差,转换后的数据不能立即用于生产环境,需要程序员仔细自行查找原因和分析。而 SQLyog 有较好的数据完整性,但整体处理速度非常的慢,如果数据较大的情况下,需要浪费非常多宝贵的时间。比较推荐的是 DB2DB,软件整体表现较好,对我来说最重要的是在不购买的情况下也够用了,而且全中文的傻瓜式界面操作起来实在方便。
分布式计算文档汇总
分布式计算总站:https://equn.com/wiki/%E9%A6%96%E9%A1%B5
知乎·分布式计算:https://www.zhihu.com/topic/19552071/hot
批计算
MapReduce 是一种 分而治之 的计算模式,在分布式领域中,除了典型的 Hadoop 的 MapReduce(Google MapReduce 的开源实现),还有 Fork-Join,Fork-Join 是 Java 等语言或库提供的原生多线程并行处理框架,采用线程级的分而治之计算模式。它充分利用多核 CPU 的优势,以递归的方式把一个任务拆分成多个“小任务”,把多个“小任务”放到多个处理器上并行执行,即 Fork 操作。当多个“小任务”执行完成之后,再将这些执行结果合并起来即可得到原始任务的结果,即 Join 操作。
虽然 MapReduce 是进程级的分而治之计算模式,但与 Fork-Join 的核心思想是一致的。因此,Fork-Join 又被称为 Java 版的 MapReduce 框架。但,MapReduce 和 Fork-Join 之间有一个本质的区别:Fork-Join 不能大规模扩展,只适用于在单个 Java 虚拟机上运行,多个小任务虽然运行在不同的处理器上,但可以相互通信,甚至一个线程可以“窃取”其他线程上的子任务。
MapReduce 可以大规模扩展,适用于大型计算机集群。通过 MapReduce 拆分后的任务,可以跨多个计算机去执行,且各个小任务之间不会相互通信。
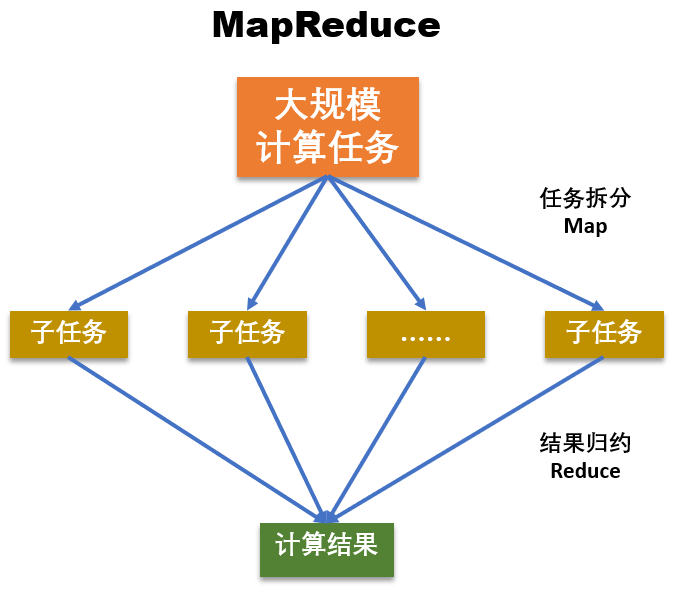

MapReduce 模式的核心思想是,将大任务拆分成多个小任务,针对这些小任务分别计算后,再合并各小任务的结果以得到大任务的计算结果,任务运行完成后整个任务进程就结束了,属于短任务模式。但任务进程的启动和停止是一件很耗时的事儿,因此 MapReduce 对处理实时性的任务就不太合适了
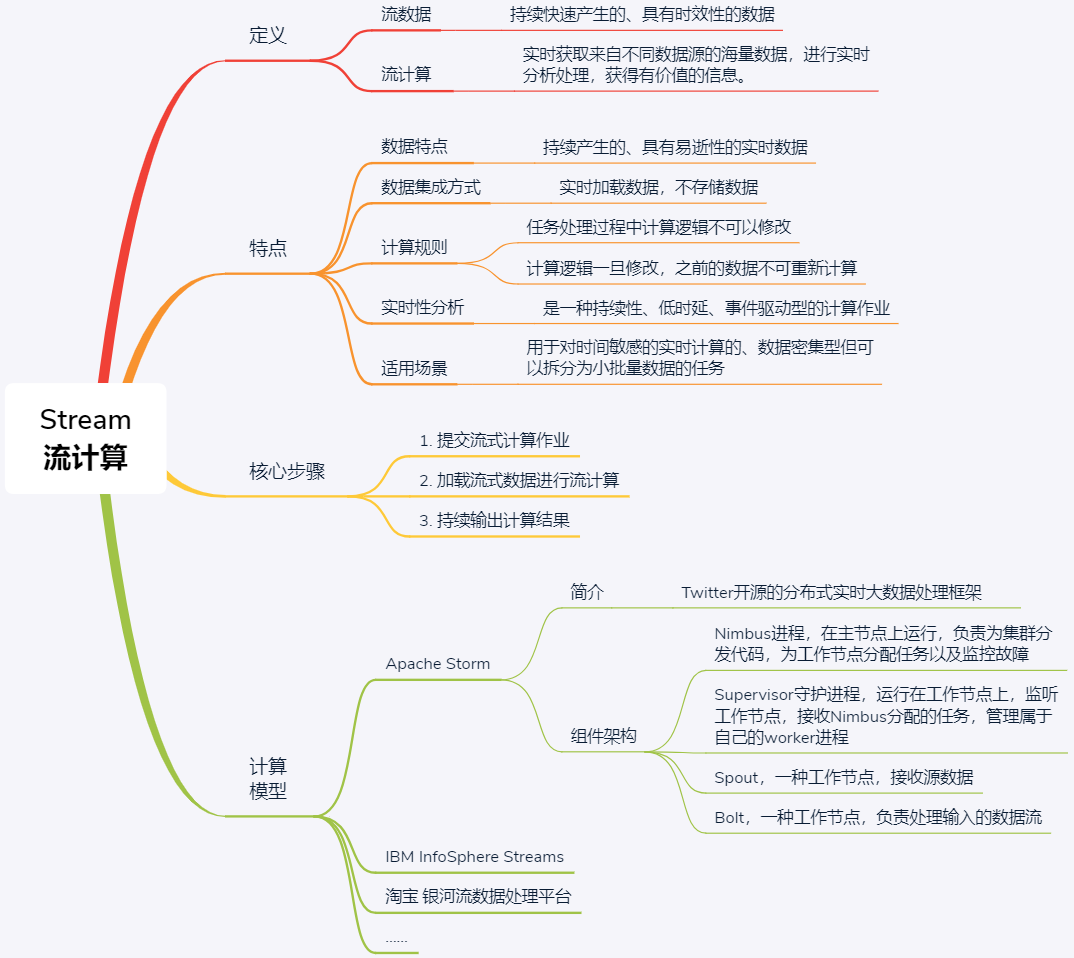
流计算
实时性任务主要是针对流数据的处理,对处理时延要求很高,通常需要有常驻服务进程,等待数据的随时到来随时处理,以保证低时延。处理流数据任务的计算模式,在分布式领域中叫作 Stream。近年来,由于网络监控、传感监测、AR/VR 等实时性应用的兴起,一类需要处理流数据的业务发展了起来。比如各种直播平台中,我们需要处理直播产生的音视频数据流等。这种如流水般持续涌现,且需要实时处理的数据,我们称之为流数据。
总结来讲,流数据的特征主要包括以下 4 点:
- 数据如流水般持续、快速地到达;
- 海量数据规模,数据量可达到 TB 级甚至 PB 级;
- 对实时性要求高,随着时间流逝,数据的价值会大幅降低;
- 数据顺序无法保证,系统无法控制将要处理的数据元素的顺序。
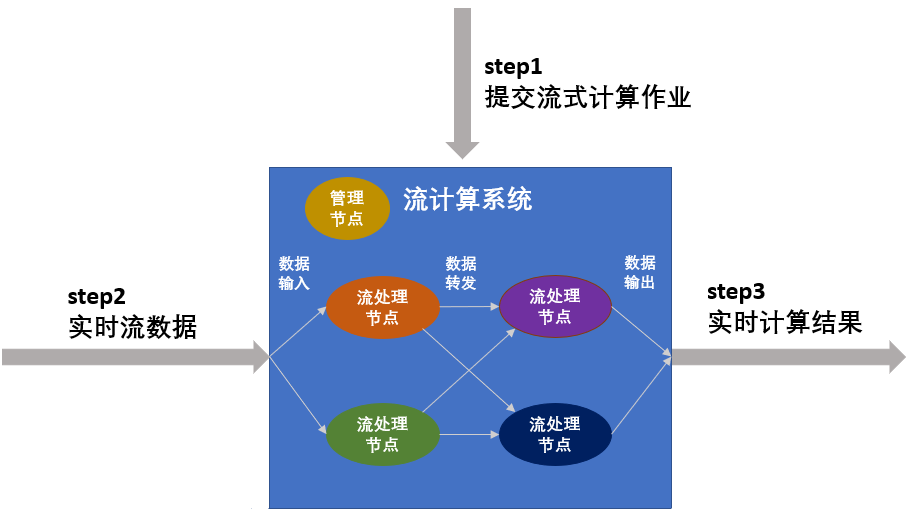
第一步,提交流式计算作业
第二步,加载流式数据进行流计算
第三步,持续输出计算结果。
Flink 各版本 changelog
https://ci.apache.org/projects/flink/flink-docs-release-1.10/release-notes/
Flink 1.10
Clusters & Deployment
FileSystems should be loaded via Plugin Architecture (FLINK-11956)
s3-hadoop and s3-presto filesystems do no longer use class relocations and need to be loaded through plugins but now seamlessly integrate with all credential providers. Other filesystems are strongly recommended to be only used as plugins as we will continue to remove relocations.
Flink Client respects Classloading Policy (FLINK-13749)
The Flink client now also respects the configured classloading policy, i.e., parent-first or child-first classloading. Previously, only cluster components such as the job manager or task manager supported this setting. This does mean that users might get different behaviour in their programs, in which case they should configure the classloading policy explicitly to use parent-first classloading, which was the previous (hard-coded) behaviour.
Enable spreading out Tasks evenly across all TaskManagers (FLINK-12122)
When FLIP-6 was rolled out with Flink 1.5.0, we changed how slots are allocated from TaskManagers (TMs). Instead of evenly allocating the slots from all registered TMs, we had the tendency to exhaust a TM before using another one. To use a scheduling strategy that is more similar to the pre-FLIP-6 behaviour, where Flink tries to spread out the workload across all currently available TMs, one can set cluster.evenly-spread-out-slots: true in the flink-conf.yaml.
Directory Structure Change for highly available Artifacts (FLINK-13633)
All highly available artifacts stored by Flink will now be stored under HA_STORAGE_DIR/HA_CLUSTER_ID with HA_STORAGE_DIR configured by high-availability.storageDir and HA_CLUSTER_ID configured by high-availability.cluster-id.
Resources and JARs shipped via –yarnship will be ordered in the Classpath (FLINK-13127)
When using the --yarnship command line option, resource directories and jar files will be added to the classpath in lexicographical order with resources directories appearing first.
Removal of –yn/–yarncontainer Command Line Options (FLINK-12362)
The Flink CLI no longer supports the deprecated command line options -yn/--yarncontainer, which were used to specify the number of containers to start on YARN. This option has been deprecated since the introduction of FLIP-6. All Flink users are advised to remove this command line option.
Removal of –yst/–yarnstreaming Command Line Options (FLINK-14957)
The Flink CLI no longer supports the deprecated command line options -yst/--yarnstreaming, which were used to disable eager pre-allocation of memory. All Flink users are advised to remove this command line option.
Mesos Integration will reject expired Offers faster (FLINK-14029)
Flink’s Mesos integration now rejects all expired offers instead of only 4. This improves the situation where Fenzo holds on to a lot of expired offers without giving them back to the Mesos resource manager.
Scheduler Rearchitecture (FLINK-14651)
Flink’s scheduler was refactored with the goal of making scheduling strategies customizable in the future. Using the legacy scheduler is discouraged as it will be removed in a future release. However, users that experience issues related to scheduling can fallback to the legacy scheduler by setting jobmanager.scheduler to legacy in their flink-conf.yaml for the time being. Note, however, that using the legacy scheduler with the Pipelined Region Failover Strategy enabled has the following caveats:
- Exceptions that caused a job to restart will not be shown on the job overview page of the Web UI (FLINK-15917). However, exceptions that cause a job to fail (e.g., when all restart attempts exhausted) will still be shown.
- The
uptimemetric will not be reset after restarting a job due to task failure (FLINK-15918).
Note that in the default flink-conf.yaml, the Pipelined Region Failover Strategy is already enabled. That is, users that want to use the legacy scheduler and cannot accept aforementioned caveats should make sure that jobmanager.execution.failover-strategy is set to full or not set at all.
Java 11 Support (FLINK-10725)
Beginning from this release, Flink can be compiled and run with Java 11. All Java 8 artifacts can be also used with Java 11. This means that users that want to run Flink with Java 11 do not have to compile Flink themselves.
When starting Flink with Java 11, the following warnings may be logged:
1 | WARNING: An illegal reflective access operation has occurred |
These warnings are considered harmless and will be addressed in future Flink releases.
Lastly, note that the connectors for Cassandra, Hive, HBase, and Kafka 0.8–0.11 have not been tested with Java 11 because the respective projects did not provide Java 11 support at the time of the Flink 1.10.0 release.
Memory Management
New Task Executor Memory Model (FLINK-13980)
With FLIP-49, a new memory model has been introduced for the task executor. New configuration options have been introduced to control the memory consumption of the task executor process. This affects all types of deployments: standalone, YARN, Mesos, and the new active Kubernetes integration. The memory model of the job manager process has not been changed yet but it is planned to be updated as well.
If you try to reuse your previous Flink configuration without any adjustments, the new memory model can result in differently computed memory parameters for the JVM and, thus, performance changes.
Please, check the user documentation for more details.
Deprecation and breaking changes
The following options have been removed and have no effect anymore:
| Deprecated/removed config option | Note |
|---|---|
| taskmanager.memory.fraction | Check also the description of the new option taskmanager.memory.managed.fraction but it has different semantics and the value of the deprecated option usually has to be adjusted |
| taskmanager.memory.off-heap | Support for on-heap managed memory has been removed, leaving off-heap managed memory as the only possibility |
| taskmanager.memory.preallocate | Pre-allocation is no longer supported, and managed memory is always allocated lazily |
The following options, if used, are interpreted as other new options in order to maintain backwards compatibility where it makes sense:
| Deprecated config option | Interpreted as |
|---|---|
| taskmanager.heap.size | taskmanager.memory.flink.size for standalone deploymenttaskmanager.memory.process.size for containerized deployments |
| taskmanager.memory.size | taskmanager.memory.managed.size |
| taskmanager.network.memory.min | taskmanager.memory.network.min |
| taskmanager.network.memory.max | taskmanager.memory.network.max |
| taskmanager.network.memory.fraction | taskmanager.memory.network.fraction |
The container cut-off configuration options, containerized.heap-cutoff-ratio and containerized.heap-cutoff-min, have no effect for task executor processes anymore but they still have the same semantics for the JobManager process.
RocksDB State Backend Memory Control (FLINK-7289)
Together with the introduction of the new Task Executor Memory Model, the memory consumption of the RocksDB state backend will be limited by the total amount of Flink Managed Memory, which can be configured via taskmanager.memory.managed.size or taskmanager.memory.managed.fraction. Furthermore, users can tune RocksDB’s write/read memory ratio (state.backend.rocksdb.memory.write-buffer-ratio, by default 0.5) and the reserved memory fraction for indices/filters (state.backend.rocksdb.memory.high-prio-pool-ratio, by default 0.1). More details and advanced configuration options can be found in the Flink user documentation.
Fine-grained Operator Resource Management (FLINK-14058)
Config options table.exec.resource.external-buffer-memory, table.exec.resource.hash-agg.memory, table.exec.resource.hash-join.memory, and table.exec.resource.sort.memory have been deprecated. Beginning from Flink 1.10, these config options are interpreted as weight hints instead of absolute memory requirements. Flink choses sensible default weight hints which should not be adjustment by users.
Table API & SQL
Rename of ANY Type to RAW Type (FLINK-14904)
The identifier raw is a reserved keyword now and must be escaped with backticks when used as a SQL field or function name.
Rename of Table Connector Properties (FLINK-14649)
Some indexed properties for table connectors have been flattened and renamed for a better user experience when writing DDL statements. This affects the Kafka Connector properties connector.properties and connector.specific-offsets. Furthermore, the Elasticsearch Connector property connector.hosts is affected. The aforementioned, old properties are deprecated and will be removed in future versions. Please consult the Table Connectors documentation for the new property names.
Methods for interacting with temporary Tables & Views (FLINK-14490)
Methods registerTable()/registerDataStream()/registerDataSet() have been deprecated in favor of createTemporaryView(), which better adheres to the corresponding SQL term.
The scan() method has been deprecated in favor of the from() method.
Methods registerTableSource()/registerTableSink() become deprecated in favor of ConnectTableDescriptor#createTemporaryTable(). The ConnectTableDescriptor approach expects only a set of string properties as a description of a TableSource or TableSink instead of an instance of a class in case of the deprecated methods. This in return makes it possible to reliably store those definitions in catalogs.
Method insertInto(String path, String... pathContinued) has been removed in favor of in insertInto(String path).
All the newly introduced methods accept a String identifier which will be parsed into a 3-part identifier. The parser supports quoting the identifier. It also requires escaping any reserved SQL keywords.
Removal of ExternalCatalog API (FLINK-13697)
The deprecated ExternalCatalog API has been dropped. This includes:
ExternalCatalog(and all dependent classes, e.g.,ExternalTable)SchematicDescriptor,MetadataDescriptor,StatisticsDescriptor
Users are advised to use the new Catalog API.
Configuration
Introduction of Type Information for ConfigOptions (FLINK-14493)
Getters of org.apache.flink.configuration.Configuration throw IllegalArgumentException now if the configured value cannot be parsed into the required type. In previous Flink releases the default value was returned in such cases.
Increase of default Restart Delay (FLINK-13884)
The default restart delay for all shipped restart strategies, i.e., fixed-delay and failure-rate, has been raised to 1 s (from originally 0 s).
Simplification of Cluster-Level Restart Strategy Configuration (FLINK-13921)
Previously, if the user had set restart-strategy.fixed-delay.attempts or restart-strategy.fixed-delay.delay but had not configured the option restart-strategy, the cluster-level restart strategy would have been fixed-delay. Now the cluster-level restart strategy is only determined by the config option restart-strategy and whether checkpointing is enabled. See “Task Failure Recovery” for details.
Disable memory-mapped BoundedBlockingSubpartition by default (FLINK-14952)
The config option taskmanager.network.bounded-blocking-subpartition-type has been renamed to taskmanager.network.blocking-shuffle.type. Moreover, the default value of the aforementioned config option has been changed from auto to file. The reason is that TaskManagers running on YARN with auto, could easily exceed the memory budget of their container, due to incorrectly accounted memory-mapped files memory usage.
Removal of non-credit-based Network Flow Control (FLINK-14516)
The non-credit-based network flow control code was removed alongside of the configuration option taskmanager.network.credit-model. Flink will now always use credit-based flow control.
Removal of HighAvailabilityOptions#HA_JOB_DELAY (FLINK-13885)
The configuration option high-availability.job.delay has been removed since it is no longer used.
State
Enable Background Cleanup of State with TTL by default (FLINK-14898)
Background cleanup of expired state with TTL is activated by default now for all state backends shipped with Flink. Note that the RocksDB state backend implements background cleanup by employing a compaction filter. This has the caveat that even if a Flink job does not store state with TTL, a minor performance penalty during compaction is incurred. Users that experience noticeable performance degradation during RocksDB compaction can disable the TTL compaction filter by setting the config option state.backend.rocksdb.ttl.compaction.filter.enabled to false.
Deprecation of StateTtlConfig#Builder#cleanupInBackground() (FLINK-15606)
StateTtlConfig#Builder#cleanupInBackground() has been deprecated because the background cleanup of state with TTL is already enabled by default.
Timers are stored in RocksDB by default when using RocksDBStateBackend (FLINK-15637)
The default timer store has been changed from Heap to RocksDB for the RocksDB state backend to support asynchronous snapshots for timer state and better scalability, with less than 5% performance cost. Users that find the performance decline critical can set state.backend.rocksdb.timer-service.factory to HEAP in flink-conf.yaml to restore the old behavior.
Removal of StateTtlConfig#TimeCharacteristic (FLINK-15605)
StateTtlConfig#TimeCharacteristic has been removed in favor of StateTtlConfig#TtlTimeCharacteristic.
New efficient Method to check if MapState is empty (FLINK-13034)
We have added a new method MapState#isEmpty() which enables users to check whether a map state is empty. The new method is 40% faster than mapState.keys().iterator().hasNext() when using the RocksDB state backend.
RocksDB Upgrade (FLINK-14483)
We have again released our own RocksDB build (FRocksDB) which is based on RocksDB version 5.17.2 with several feature backports for the Write Buffer Manager to enable limiting RocksDB’s memory usage. The decision to release our own RocksDB build was made because later RocksDB versions suffer from a performance regression under certain workloads.
RocksDB Logging disabled by default (FLINK-15068)
Logging in RocksDB (e.g., logging related to flush, compaction, memtable creation, etc.) has been disabled by default to prevent disk space from being filled up unexpectedly. Users that need to enable logging should implement their own RocksDBOptionsFactory that creates DBOptions instances with InfoLogLevel set to INFO_LEVEL.
Improved RocksDB Savepoint Recovery (FLINK-12785)
In previous Flink releases users may encounter an OutOfMemoryError when restoring from a RocksDB savepoint containing large KV pairs. For that reason we introduced a configurable memory limit in the RocksDBWriteBatchWrapper with a default value of 2 MB. RocksDB’s WriteBatch will flush before the consumed memory limit is reached. If needed, the limit can be tuned via the state.backend.rocksdb.write-batch-size config option in flink-conf.yaml.
PyFlink
Python 2 Support dropped (FLINK-14469)
Beginning from this release, PyFlink does not support Python 2. This is because Python 2 has reached end of life on January 1, 2020, and several third-party projects that PyFlink depends on are also dropping Python 2 support.
Monitoring
InfluxdbReporter skips Inf and NaN (FLINK-12147)
The InfluxdbReporter now silently skips values that are unsupported by InfluxDB, such as Double.POSITIVE_INFINITY, Double.NEGATIVE_INFINITY, Double.NaN, etc.
Connectors
Kinesis Connector License Change (FLINK-12847)
flink-connector-kinesis is now licensed under the Apache License, Version 2.0, and its artifacts will be deployed to Maven central as part of the Flink releases. Users no longer need to build the Kinesis connector from source themselves.
Miscellaneous Interface Changes
ExecutionConfig#getGlobalJobParameters() cannot return null anymore (FLINK-9787)
ExecutionConfig#getGlobalJobParameters has been changed to never return null. Conversely, ExecutionConfig#setGlobalJobParameters(GlobalJobParameters) will not accept null values anymore.
Change of contract in MasterTriggerRestoreHook interface (FLINK-14344)
Implementations of MasterTriggerRestoreHook#triggerCheckpoint(long, long, Executor) must be non-blocking now. Any blocking operation should be executed asynchronously, e.g., using the given executor.
Client-/ and Server-Side Separation of HA Services (FLINK-13750)
The HighAvailabilityServices have been split up into client-side ClientHighAvailabilityServices and cluster-side HighAvailabilityServices. When implementing custom high availability services, users should follow this separation by overriding the factory method HighAvailabilityServicesFactory#createClientHAServices(Configuration). Moreover, HighAvailabilityServices#getWebMonitorLeaderRetriever() should no longer be implemented since it has been deprecated.
Deprecation of HighAvailabilityServices#getWebMonitorLeaderElectionService() (FLINK-13977)
Implementations of HighAvailabilityServices should implement HighAvailabilityServices#getClusterRestEndpointLeaderElectionService() instead of HighAvailabilityServices#getWebMonitorLeaderElectionService().
Interface Change in LeaderElectionService (FLINK-14287)
LeaderElectionService#confirmLeadership(UUID, String) now takes an additional second argument, which is the address under which the leader will be reachable. All custom LeaderElectionService implementations will need to be updated accordingly.
Deprecation of Checkpoint Lock (FLINK-14857)
The method org.apache.flink.streaming.runtime.tasks.StreamTask#getCheckpointLock() is deprecated now. Users should use MailboxExecutor to run actions that require synchronization with the task’s thread (e.g. collecting output produced by an external thread). The methods MailboxExecutor#yield() or MailboxExecutor#tryYield() can be used for actions that need to give up control to other actions temporarily, e.g., if the current operator is blocked. The MailboxExecutor can be accessed by using YieldingOperatorFactory (see AsyncWaitOperator for an example usage).
Deprecation of OptionsFactory and ConfigurableOptionsFactory interfaces (FLINK-14926)
Interfaces OptionsFactory and ConfigurableOptionsFactory have been deprecated in favor of RocksDBOptionsFactory and ConfigurableRocksDBOptionsFactory, respectively.
Flink 1.9
Known shortcomings or limitations for new features
New Table / SQL Blink planner
Flink 1.9.0 provides support for two planners for the Table API, namely Flink’s original planner and the new Blink planner. The original planner maintains same behaviour as previous releases, while the new Blink planner is still considered experimental and has the following limitations:
- The Blink planner can not be used with
BatchTableEnvironment, and therefore Table programs ran with the planner can not be transformed toDataSetprograms. This is by design and will also not be supported in the future. Therefore, if you want to run a batch job with the Blink planner, please use the newTableEnvironment. For streaming jobs, bothStreamTableEnvironmentandTableEnvironmentworks. - Implementations of
StreamTableSinkshould implement theconsumeDataStreammethod instead ofemitDataStreamif it is used with the Blink planner. Both methods work with the original planner. This is by design to make the returnedDataStreamSinkaccessible for the planner. - Due to a bug with how transformations are not being cleared on execution,
TableEnvironmentinstances should not be reused across multiple SQL statements when using the Blink planner. Table.flatAggregateis not supported- Session and count windows are not supported when running batch jobs.
- The Blink planner only supports the new
CatalogAPI, and does not supportExternalCatalogwhich is now deprecated.
Related issues:
- FLINK-13708: Transformations should be cleared because a table environment could execute multiple job
- FLINK-13473: Add GroupWindowed FlatAggregate support to stream Table API (Blink planner), i.e, align with Flink planner
- FLINK-13735: Support session window with Blink planner in batch mode
- FLINK-13736: Support count window with Blink planner in batch mode
SQL DDL
In Flink 1.9.0, the community also added a preview feature about SQL DDL, but only for batch style DDLs. Therefore, all streaming related concepts are not supported yet, for example watermarks.
Related issues:
- FLINK-13661: Add a stream specific CREATE TABLE SQL DDL
- FLINK-13568: DDL create table doesn’t allow STRING data type
Java 9 support
Since Flink 1.9.0, Flink can now be compiled and run on Java 9. Note that certain components interacting with external systems (connectors, filesystems, metric reporters, etc.) may not work since the respective projects may have skipped Java 9 support.
Related issues:
Memory management
In Fink 1.9.0 and prior version, the managed memory fraction of taskmanager is controlled by taskmanager.memory.fraction, and with 0.7 as the default value. However, sometimes this will cause OOMs due to the fact that the default value of JVM parameter NewRatio is 2, which means the old generation occupied only 2/3 (0.66) of the heap memory. So if you run into this case, please manually change this value to a lower value.
Related issues:
Deprecations and breaking changes
Scala expression DSL for Table API moved to flink-table-api-scala
Since 1.9.0, the implicit conversions for the Scala expression DSL for the Table API has been moved to flink-table-api-scala. This requires users to update the imports in their Table programs.
Users of pure Table programs should define their imports like:
1 | import org.apache.flink.table.api._ |
Users of the DataStream API should define their imports like:
1 | import org.apache.flink.table.api._ |
Related issues:
Failover strategies
As a result of completing fine-grained recovery (FLIP-1), Flink will now attempt to only restart tasks that are connected to failed tasks through a pipelined connection. By default, the region failover strategy is used.
Users who were not using a restart strategy or have already configured a failover strategy should not be affected. Moreover, users who already enabled the region failover strategy, along with a restart strategy that enforces a certain number of restarts or introduces a restart delay, will see changes in behavior. The region failover strategy now correctly respects constraints that are defined by the restart strategy.
Streaming users who were not using a failover strategy may be affected if their jobs are embarrassingly parallel or contain multiple independent jobs. In this case, only the failed parallel pipeline or affected jobs will be restarted.
Batch users may be affected if their job contains blocking exchanges (usually happens for shuffles) or the ExecutionMode was set to BATCH or BATCH_FORCED via the ExecutionConfig.
Overall, users should see an improvement in performance.
Related issues:
- FLINK-13223: Set jobmanager.execution.failover-strategy to region in default flink-conf.yaml
- FLINK-13060: FailoverStrategies should respect restart constraints
Job termination via CLI
With the support of graceful job termination with savepoints for semantic correctness (FLIP-34), a few changes related to job termination has been made to the CLI.
From now on, the stop command with no further arguments stops the job with a savepoint targeted at the default savepoint location (as configured via the state.savepoints.dir property in the job configuration), or a location explicitly specified using the -p option. Please make sure to configure the savepoint path using either one of these options.
Since job terminations are now always accompanied with a savepoint, stopping jobs is expected to take longer now.
Related issues:
- FLINK-13123: Align Stop/Cancel Commands in CLI and REST Interface and Improve Documentation
- FLINK-11458: Add TERMINATE/SUSPEND Job with Savepoint
Network stack
A few changes in the network stack related to changes in the threading model of StreamTask to a mailbox-based approach requires close attention to some related configuration:
- Due to changes in the lifecycle management of result partitions, partition requests as well as re-triggers will now happen sooner. Therefore, it is possible that some jobs with long deployment times and large state might start failing more frequently with
PartitionNotFoundexceptions compared to previous versions. If that’s the case, users should increase the value oftaskmanager.network.request-backoff.maxin order to have the same effective partition request timeout as it was prior to 1.9.0. - To avoid a potential deadlock, a timeout has been added for how long a task will wait for assignment of exclusive memory segments. The default timeout is 30 seconds, and is configurable via
taskmanager.network.memory.exclusive-buffers-request-timeout-ms. It is possible that for some previously working deployments this default timeout value is too low and might have to be increased.
Please also notice that several network I/O metrics have had their scope changed. See the 1.9 metrics documentation for which metrics are affected. In 1.9.0, these metrics will still be available under their previous scopes, but this may no longer be the case in future versions.
Related issues:
- FLINK-13013: Make sure that SingleInputGate can always request partitions
- FLINK-12852: Deadlock occurs when requiring exclusive buffer for RemoteInputChannel
- FLINK-12555: Introduce an encapsulated metric group layout for shuffle API and deprecate old one
AsyncIO
Due to a bug in the AsyncWaitOperator, in 1.9.0 the default chaining behaviour of the operator is now changed so that it is never chained after another operator. This should not be problematic for migrating from older version snapshots as long as an uid was assigned to the operator. If an uid was not assigned to the operator, please see the instructions here for a possible workaround.
Related issues:
Connectors and Libraries
Introduced KafkaSerializationSchema to fully replace KeyedSerializationSchema
The universal FlinkKafkaProducer (in flink-connector-kafka) supports a new KafkaSerializationSchema that will fully replace KeyedSerializationSchema in the long run. This new schema allows directly generating Kafka ProducerRecords for sending to Kafka, therefore enabling the user to use all available Kafka features (in the context of Kafka records).
Dropped connectors and libraries
- The Elasticsearch 1 connector has been dropped and will no longer receive patches. Users may continue to use the connector from a previous series (like 1.8) with newer versions of Flink. It is being dropped due to being used significantly less than more recent versions (Elasticsearch versions 2.x and 5.x are downloaded 4 to 5 times more), and hasn’t seen any development for over a year.
- The older Python APIs for batch and streaming have been removed and will no longer receive new patches. A new API is being developed based on the Table API as part of FLINK-12308: Support python language in Flink Table API. Existing users may continue to use these older APIs with future versions of Flink by copying both the
flink-streaming-pythonandflink-pythonjars into the/libdirectory of the distribution and the corresponding start scriptspyflink-stream.shandpyflink.shinto the/bindirectory of the distribution. - The older machine learning libraries have been removed and will no longer receive new patches. This is due to efforts towards a new Table-based machine learning library (FLIP-39). Users can still use the 1.8 version of the legacy library if their projects still rely on it.
Related issues:
- FLINK-11693: Add KafkaSerializationSchema that directly uses ProducerRecord
- FLINK-12151: Drop Elasticsearch 1 connector
- FLINK-12903: Remove legacy flink-python APIs
- FLINK-12308: Support python language in Flink Table API
- FLINK-12597: Remove the legacy flink-libraries/flink-ml
MapR dependency removed
Dependency on MapR vendor-specific artifacts has been removed, by changing the MapR filesystem connector to work purely based on reflection. This does not introduce any regession in the support for the MapR filesystem. The decision to remove hard dependencies on the MapR artifacts was made due to very flaky access to the secure https endpoint of the MapR artifact repository, and affected build stability of Flink.
Related issues:
- FLINK-12578: Use secure URLs for Maven repositories
- FLINK-13499: Remove dependency on MapR artifact repository
StateDescriptor interface change
Access to the state serializer in StateDescriptor is now modified from protected to private access. Subclasses should use the StateDescriptor#getSerializer() method as the only means to obtain the wrapped state serializer.
Related issues:
Web UI dashboard
The web frontend of Flink has been updated to use the latest Angular version (7.x). The old frontend remains available in Flink 1.9.x, but will be removed in a later Flink release once the new frontend is considered stable.
Related issues:
Flink 1.8
State
Continuous incremental cleanup of old Keyed State with TTL
We introduced TTL (time-to-live) for Keyed state in Flink 1.6 (FLINK-9510). This feature allowed to clean up and make inaccessible keyed state entries when accessing them. In addition state would now also being cleaned up when writing a savepoint/checkpoint.
Flink 1.8 introduces continous cleanup of old entries for both the RocksDB state backend (FLINK-10471) and the heap state backend (FLINK-10473). This means that old entries (according to the ttl setting) are continously being cleanup up.
New Support for Schema Migration when restoring Savepoints
With Flink 1.7.0 we added support for changing the schema of state when using the AvroSerializer (FLINK-10605). With Flink 1.8.0 we made great progress migrating all built-in TypeSerializers to a new serializer snapshot abstraction that theoretically allows schema migration. Of the serializers that come with Flink, we now support schema migration for the PojoSerializer (FLINK-11485), and Java EnumSerializer (FLINK-11334), As well as for Kryo in limited cases (FLINK-11323).
Savepoint compatibility
Savepoints from Flink 1.2 that contain a Scala TraversableSerializer are not compatible with Flink 1.8 anymore because of an update in this serializer (FLINK-11539). You can get around this restriction by first upgrading to a version between Flink 1.3 and Flink 1.7 and then updating to Flink 1.8.
RocksDB version bump and switch to FRocksDB (FLINK-10471)
We needed to switch to a custom build of RocksDB called FRocksDB because we need certain changes in RocksDB for supporting continuous state cleanup with TTL. The used build of FRocksDB is based on the upgraded version 5.17.2 of RocksDB. For Mac OS X, RocksDB version 5.17.2 is supported only for OS X version >= 10.13. See also: https://github.com/facebook/rocksdb/issues/4862.
Maven Dependencies
Changes to bundling of Hadoop libraries with Flink (FLINK-11266)
Convenience binaries that include hadoop are no longer released.
If a deployment relies on flink-shaded-hadoop2 being included in flink-dist, then you must manually download a pre-packaged Hadoop jar from the optional components section of the download page and copy it into the /lib directory. Alternatively, a Flink distribution that includes hadoop can be built by packaging flink-dist and activating the include-hadoop maven profile.
As hadoop is no longer included in flink-dist by default, specifying -DwithoutHadoop when packaging flink-dist no longer impacts the build.
Configuration
TaskManager configuration (FLINK-11716)
TaskManagers now bind to the host IP address instead of the hostname by default . This behaviour can be controlled by the configuration option taskmanager.network.bind-policy. If your Flink cluster should experience inexplicable connection problems after upgrading, try to set taskmanager.network.bind-policy: name in your flink-conf.yaml to return to the pre-1.8 behaviour.
Table API
Deprecation of direct Table constructor usage (FLINK-11447)
Flink 1.8 deprecates direct usage of the constructor of the Table class in the Table API. This constructor would previously be used to perform a join with a lateral table. You should now use table.joinLateral() or table.leftOuterJoinLateral() instead.
This change is necessary for converting the Table class into an interface, which will make the API more maintainable and cleaner in the future.
Introduction of new CSV format descriptor (FLINK-9964)
This release introduces a new format descriptor for CSV files that is compliant with RFC 4180. The new descriptor is available as org.apache.flink.table.descriptors.Csv. For now, this can only be used together with the Kafka connector. The old descriptor is available as org.apache.flink.table.descriptors.OldCsv for use with file system connectors.
Deprecation of static builder methods on TableEnvironment (FLINK-11445)
In order to separate API from actual implementation, the static methods TableEnvironment.getTableEnvironment() are deprecated. You should now use Batch/StreamTableEnvironment.create() instead.
Change in the Maven modules of Table API (FLINK-11064)
Users that had a flink-table dependency before, need to update their dependencies to flink-table-planner and the correct dependency of flink-table-api-*, depending on whether Java or Scala is used: one of flink-table-api-java-bridge or flink-table-api-scala-bridge.
Change to External Catalog Table Builders (FLINK-11522)
ExternalCatalogTable.builder() is deprecated in favour of ExternalCatalogTableBuilder().
Change to naming of Table API connector jars (FLINK-11026)
The naming scheme for kafka/elasticsearch6 sql-jars has been changed.
In maven terms, they no longer have the sql-jar qualifier and the artifactId is now prefixed with flink-sql instead of flink, e.g., flink-sql-connector-kafka....
Change to how Null Literals are specified (FLINK-11785)
Null literals in the Table API need to be defined with nullOf(type) instead of Null(type) from now on. The old approach is deprecated.
Connectors
Introduction of a new KafkaDeserializationSchema that give direct access to ConsumerRecord (FLINK-8354)
For the Flink KafkaConsumers, we introduced a new KafkaDeserializationSchema that gives direct access to the Kafka ConsumerRecord. This subsumes the KeyedSerializationSchema functionality, which is deprecated but still available for now.
FlinkKafkaConsumer will now filter restored partitions based on topic specification (FLINK-10342)
Starting from Flink 1.8.0, the FlinkKafkaConsumer now always filters out restored partitions that are no longer associated with a specified topic to subscribe to in the restored execution. This behaviour did not exist in previous versions of the FlinkKafkaConsumer. If you wish to retain the previous behaviour, please use the disableFilterRestoredPartitionsWithSubscribedTopics() configuration method on the FlinkKafkaConsumer.
Consider this example: if you had a Kafka Consumer that was consuming from topic A, you did a savepoint, then changed your Kafka consumer to instead consume from topic B, and then restarted your job from the savepoint. Before this change, your consumer would now consume from both topic A and B because it was stored in state that the consumer was consuming from topic A. With the change, your consumer would only consume from topic B after restore because we filter the topics that are stored in state using the configured topics.
Miscellaneous Interface changes
The canEqual() method was dropped from the TypeSerializer interface (FLINK-9803)
The canEqual() methods are usually used to make proper equality checks across hierarchies of types. The TypeSerializer actually doesn’t require this property, so the method is now removed.
Removal of the CompositeSerializerSnapshot utility class (FLINK-11073)
The CompositeSerializerSnapshot utility class has been removed. You should now use CompositeTypeSerializerSnapshot instead, for snapshots of composite serializers that delegate serialization to multiple nested serializers. Please see here for instructions on using CompositeTypeSerializerSnapshot.
Memory management
In Fink 1.8.0 and prior version, the managed memory fraction of taskmanager is controlled by taskmanager.memory.fraction, and with 0.7 as the default value. However, sometimes this will cause OOMs due to the fact that the default value of JVM parameter NewRatio is 2, which means the old generation occupied only 2/3 (0.66) of the heap memory. So if you run into this case, please manually change this value to a lower value.
Flink 1.7
Scala 2.12 support
When using Scala 2.12 you might have to add explicit type annotations in places where they were not required when using Scala 2.11. This is an excerpt from the TransitiveClosureNaive.scala example in the Flink code base that shows the changes that could be required.
Previous code:
1 | val terminate = prevPaths |
With Scala 2.12 you have to change it to:
1 | val terminate = prevPaths |
The reason for this is that Scala 2.12 changes how lambdas are implemented. They now use the lambda support using SAM interfaces introduced in Java 8. This makes some method calls ambiguous because now both Scala-style lambdas and SAMs are candidates for methods were it was previously clear which method would be invoked.
State evolution
Before Flink 1.7, serializer snapshots were implemented as a TypeSerializerConfigSnapshot (which is now deprecated, and will eventually be removed in the future to be fully replaced by the new TypeSerializerSnapshot interface introduced in 1.7). Moreover, the responsibility of serializer schema compatibility checks lived within the TypeSerializer, implemented in the TypeSerializer#ensureCompatibility(TypeSerializerConfigSnapshot) method.
To be future-proof and to have flexibility to migrate your state serializers and schema, it is highly recommended to migrate from the old abstractions. Details and migration guides can be found here.
Removal of the legacy mode
Flink no longer supports the legacy mode. If you depend on this, then please use Flink 1.6.x.
Savepoints being used for recovery
Savepoints are now used while recovering. Previously when using exactly-once sink one could get into problems with duplicate output data when a failure occurred after a savepoint was taken but before the next checkpoint occurred. This results in the fact that savepoints are no longer exclusively under the control of the user. Savepoint should not be moved nor deleted if there was no newer checkpoint or savepoint taken.
MetricQueryService runs in separate thread pool
The metric query service runs now in its own ActorSystem. It needs consequently to open a new port for the query services to communicate with each other. The query service port can be configured in flink-conf.yaml.
Granularity of latency metrics
The default granularity for latency metrics has been modified. To restore the previous behavior users have to explicitly set the granularity to subtask.
Latency marker activation
Latency metrics are now disabled by default, which will affect all jobs that do not explicitly set the latencyTrackingInterval via ExecutionConfig#setLatencyTrackingInterval. To restore the previous default behavior users have to configure the latency interval in flink-conf.yaml.
Relocation of Hadoop’s Netty dependency
We now also relocate Hadoop’s Netty dependency from io.netty to org.apache.flink.hadoop.shaded.io.netty. You can now bundle your own version of Netty into your job but may no longer assume that io.netty is present in the flink-shaded-hadoop2-uber-*.jar file.
Local recovery fixed
With the improvements to Flink’s scheduling, it can no longer happen that recoveries require more slots than before if local recovery is enabled. Consequently, we encourage our users to enable local recovery in flink-conf.yaml.
Support for multi slot TaskManagers
Flink now properly supports TaskManagers with multiple slots. Consequently, TaskManagers can now be started with an arbitrary number of slots and it is no longer recommended to start them with a single slot.
StandaloneJobClusterEntrypoint generates JobGraph with fixed JobID
The StandaloneJobClusterEntrypoint, which is launched by the script standalone-job.sh and used for the job-mode container images, now starts all jobs with a fixed JobID. Thus, in order to run a cluster in HA mode, one needs to set a different cluster id for each job/cluster.
Scala shell does not work with Scala 2.12
Flink’s Scala shell does not work with Scala 2.12. Therefore, the module flink-scala-shell is not being released for Scala 2.12.
See FLINK-10911 for more details.
Limitations of failover strategies
Flink’s non-default failover strategies are still a very experimental feature which come with a set of limitations. You should only use this feature if you are executing a stateless streaming job. In any other cases, it is highly recommended to remove the config option jobmanager.execution.failover-strategy from your flink-conf.yaml or set it to "full".
In order to avoid future problems, this feature has been removed from the documentation until it will be fixed. See FLINK-10880 for more details.
SQL over window preceding clause
The over window preceding clause is now optional. It defaults to UNBOUNDED if not specified.
OperatorSnapshotUtil writes v2 snapshots
Snapshots created with OperatorSnapshotUtil are now written in the savepoint format v2.
SBT projects and the MiniClusterResource
If you have a sbt project which uses the MiniClusterResource, you now have to add the flink-runtime test-jar dependency explicitly via:
1 | libraryDependencies += "org.apache.flink" %% "flink-runtime" % flinkVersion % Test classifier "tests" |
The reason for this is that the MiniClusterResource has been moved from flink-test-utils to flink-runtime. The module flink-test-utils has correctly a test-jar dependency on flink-runtime. However, sbt does not properly pull in transitive test-jar dependencies as described in this sbt issue. Consequently, it is necessary to specify the test-jar dependency explicitly.
Flink 1.6
Changed Configuration Default Values
The default value of the slot idle timeout slot.idle.timeout is set to the default value of the heartbeat timeout (50 s).
Changed ElasticSearch 5.x Sink API
Previous APIs in the Flink ElasticSearch 5.x Sink’s RequestIndexer interface have been deprecated in favor of new signatures. When adding requests to the RequestIndexer, the requests now must be of type IndexRequest, DeleteRequest, or UpdateRequest, instead of the base ActionRequest.
Limitations of failover strategies
Flink’s non-default failover strategies are still a very experimental feature which come with a set of limitations. You should only use this feature if you are executing a stateless streaming job. In any other cases, it is highly recommended to remove the config option jobmanager.execution.failover-strategy from your flink-conf.yaml or set it to "full".
In order to avoid future problems, this feature has been removed from the documentation until it will be fixed. See FLINK-10880 for more details.
Flink 1.5
These release notes discuss important aspects, such as configuration, behavior, or dependencies, that changed between Flink 1.4 and Flink 1.5. Please read these notes carefully if you are planning to upgrade your Flink version to 1.5.
Update Configuration for Reworked Job Deployment
Flink’s reworked cluster and job deployment component improves the integration with resource managers and enables dynamic resource allocation. One result of these changes is, that you no longer have to specify the number of containers when submitting applications to YARN and Mesos. Flink will automatically determine the number of containers from the parallelism of the application.
Although the deployment logic was completely reworked, we aimed to not unnecessarily change the previous behavior to enable a smooth transition. Nonetheless, there are a few options that you should update in your conf/flink-conf.yaml or know about.
- The allocation of TaskManagers with multiple slots is not fully supported yet. Therefore, we recommend to configure TaskManagers with a single slot, i.e., set
taskmanager.numberOfTaskSlots: 1 - If you observed any problems with the new deployment mode, you can always switch back to the pre-1.5 behavior by configuring
mode: legacy.
Please report any problems or possible improvements that you notice to the Flink community, either by posting to a mailing list or by opening a JIRA issue.
Note: We plan to remove the legacy mode in the next release.
Update Configuration for Reworked Network Stack
The changes on the networking stack for credit-based flow control and improved latency affect the configuration of network buffers. In a nutshell, the networking stack can require more memory to run applications. Hence, you might need to adjust the network configuration of your Flink setup.
There are two ways to address problems of job submissions that fail due to lack of network buffers.
- Reduce the number of buffers per channel, i.e.,
taskmanager.network.memory.buffers-per-channelor - Increase the amount of TaskManager memory that is used by the network stack, i.e., increase
taskmanager.network.memory.fractionand/ortaskmanager.network.memory.max.
Please consult the section about network buffer configuration in the Flink documentation for details. In case you experience issues with the new credit-based flow control mode, you can disable flow control by setting taskmanager.network.credit-model: false.
Note: We plan to remove the old model and this configuration in the next release.
Hadoop Classpath Discovery
We removed the automatic Hadoop classpath discovery via the Hadoop binary. If you want Flink to pick up the Hadoop classpath you have to export HADOOP_CLASSPATH. On cloud environments and most Hadoop distributions you would do
1 | export HADOOP_CLASSPATH=`hadoop classpath`. |
Breaking Changes of the REST API
In an effort to harmonize, extend, and improve the REST API, a few handlers and return values were changed.
- The jobs overview handler is now registered under
/jobs/overview(before/joboverview) and returns a list of job details instead of the pre-grouped view of running, finished, cancelled and failed jobs. - The REST API to cancel a job was changed.
- The REST API to cancel a job with savepoint was changed.
Please check the REST API documentation for details.
Kafka Producer Flushes on Checkpoint by Default
The Flink Kafka Producer now flushes on checkpoints by default. Prior to version 1.5, the behaviour was disabled by default and users had to explicitly call setFlushOnCheckpoints(true) on the producer to enable it.
Updated Kinesis Dependency
The Kinesis dependencies of Flink’s Kinesis connector have been updated to the following versions.
1 | <aws.sdk.version>1.11.319</aws.sdk.version> |
Limitations of failover strategies
Flink’s non-default failover strategies are still a very experimental feature which come with a set of limitations. You should only use this feature if you are executing a stateless streaming job. In any other cases, it is highly recommended to remove the config option jobmanager.execution.failover-strategy from your flink-conf.yaml or set it to "full".
In order to avoid future problems, this feature has been removed from the documentation until it will be fixed. See FLINK-10880 for more details.