vi删除空行或注释行
删除空行
1 | :g/^$/d |
删除空行以及只有空格的行
1 | :g/^\s*$/d |
删除以 # 开头或 空格# 或 tab#开头的行
1 | :g/^\s*#/d |
对于 php.ini 配置文件,注释为 ; 开头
1 | :g/^\s*;/d |
使用正则表达式删除行
如果当前行包含 bbs ,则删除当前行
1 | :/bbs/d |
删除从第二行到包含 bbs 的区间行
1 | :2,/bbs/d |
删除从包含 bbs 的行到最后一行区间的行
1 | :/bbs/,$d |
删除所有包含 bbs 的行
1 | :g/bbs/d |
删除匹配 bbs 且前面只有一个字符的行
1 | :g/.bbs/d |
删除匹配 bbs 且以它开头的行
1 | :g/^bbs/d |
删除匹配 bbs 且以它结尾的行
1 | :g/bbs$/d |
.ini 的注释是以 ; 开始的,如果注释不在行开头,那么删除 ; 及以后的字符
1 | :%s/\;.\+//g |
删除 # 之后所有字符
1 | s/\#.*//g |
最大子序和
算法:动态规划
题目
url:https://leetcode-cn.com/problems/maximum-subarray/
1 | 给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 |
分析: 根据 最大和求最长子序列
长度为1的最大和子序列 => 长度为2的最大和子序列 => 长度为3的最大和子序列
Java解法
1、动态规划
求出每个位置(及其之前累计)的最大和:
max(i-1) >0 : max(i) = max(i-1) + nums[i]
max(i-1) <=0 : max(i) = nums[i]
1 | class MaxKV { |
2、分治法
GitLab+Jenkins+Harbor+Kubernetes集成应用
docker安装jenkins
jenkins官网:http://mirrors.jenkins.io/war-stable/
docker仓库:https://hub.docker.com/_/jenkins
docker pull jenkins:2.7.4-alpine
docker run -d -p 8180:8080 -p 50100:50000 –name jenkins-dev jenkins:2.7.4-alpine
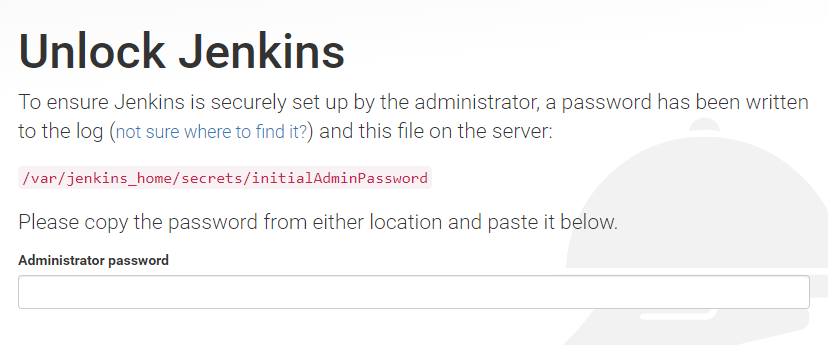
docker exec -it jenkins-dev /bin/bash
cd /var/jenkins_home/
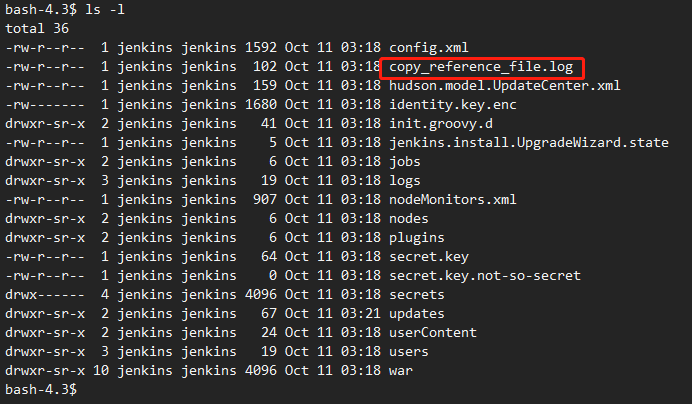
cat /var/jenkins_home/secrets/initialAdminPassword
e8ad89a38a244e80a174b9be916e0f12
选择推荐安装,安装插件 -> 设置管理员账号admin/admin -> 开始使用
centos7部署jenkins.war
1 | echo $JAVA_HOME |
jenkins 插件安装
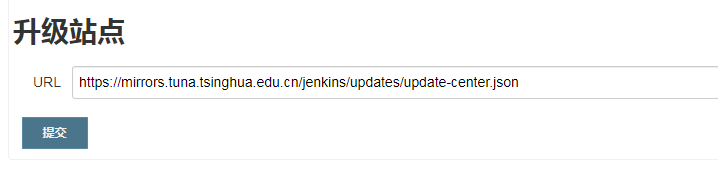
使用国内插件镜像
路径: jenkins -> 插件管理 -> 高级 -> 升级站点,修改地址:
https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
安装Gitlab插件



安装Docker插件

安装k8s插件

打通jenkins与k8s-master两台机器ssh免密登陆
Jenkins Kubernetes配置
使用cronlog 对 tomcat 的 catalina.out 日志自动切割
一、cronlog
采用cronlolog工具对日志拆分的方式处理该问题
1、下载cronolog工具,我下载的版本是cronolog-1.6.2
(yum安装:yum install cronolog)
2、将下载好的文件解压,tar xvzf cronolog-1.6.2.tar.gz
3、切换到解压后的文件目录下:cd cronolog-1.6.2
4、初始化和编译安装
1 | ./configure --prefix=/usr/local/cronolog |
5、查看安装版本
1 | #cronolog --version |
6、修改tomcat的启动文件(tomcat目录/bin/catalina.sh)
1 | vi catalina.sh |
(1)修改输出日志路径
修改:
1 | if [ -z "$CATALINA_OUT" ] ; then |
为:
1 | if [ -z "$CATALINA_OUT" ] ; then |
(2)删除生成日志文件
注释:
1 | touch "$CATALINA_OUT" |
(3)修改启动脚本参数(两项)
修改:
org.apache.catalina.startup.Bootstrap "$@" start \
>> "$CATALINA_OUT" 2>&1 "&"
为:
org.apache.catalina.startup.Bootstrap "$@" start 2>&1 \
| /usr/local/sbin/cronolog "$CATALINA_OUT" >> /dev/null &
7、重启tomcat
tomcat输出日志文件分割成功,输出log文件格式为:catalina.2015-06-30.out
二、logrotate
利用Linux自带的logrotate程序来解决catalina.out的日志轮转问题
1.首先编辑logrotate.conf文件,打开compress选项(去掉注释)
1 | [root@localhost ~] |
2.添加指定文件,在/etc/logrotate.d/目录下新建一个名为tomcat的文件
1 | [] |
参数说明:
copytruncate #备份日志并截断源文件
nocopytruncate # 备份日志文件不截断
dateext #使用当期日期作为命名格式
notifempty #当日志文件为空时,不进行轮转
daily # 每天进行文件的轮转
size 16M # 当文件大于16MB时,就会轮转
rotate 30 #指定日志文件删除之前转储的次数
3.执行方式
①自动执行原理
1 | 1.每天晚上crond守护进程会运行在/etc/cron.daily目录中的任务列表; |
②手动执行:logrotate /etc/logrotate.conf
③只轮转刚刚的tomcat配置文件:logrotate –force /etc/logrotate.d/tomcat
三、log4j
Tomcat7.0.55下使用Log4j 接管 catalina.out 日志文件生成方式,按天存放,解决catalina.out日志文件过大问题
- 准备jar包:
log4j-1.2.17.jar (从 http://www.apache.org/dist/logging/log4j/1.2.17/ 下载)
tomcat-juli.jar, tomcat-juli-adapters.jar (从http://www.apache.org/dist/tomcat/tomcat-7/v7.0.55/bin/extras/下载,根据你的Tomcat版本选择对应的分支) - 将上面的三个jar包拷贝到 Tomcat 的 lib 目录下;
- 将 tomcat-juli.jar 拷贝到 Tomcat 的 bin 目录下,替换原有的jar包;
- 修改 Tomcat 的 conf/context.xml 文件,将
为
(增加 swallowOutput=”true” 的属性配置,只有这样才能完全的把tomcat的stdout给接管过来。这一步很关键 在官网及网上找了许多资料都没有提及。); - 删除 Tomcat 的 conf/logging.properties 文件(或者重命名-建议);
- 在 Tomcat 的 lib 目录下创建 log4j.properties 文件,然后重启服务器:
1 | log4j.rootLogger=INFO, CATALINA |
四、shell脚本切割
通过shell脚本的方式切割每天的日志
windows
部署在windows服务器下的tomcat,将tomcat控制台日志记录到日志文件中
https://www.cnblogs.com/linaGh/p/7777915.html
对于抛出的异常错误,不会被存到文件中的,可以修改代码或者修改cmd属性-布局中的高度,默认是300
高度即行数,设置大点就可以看到没有存到文件中的日志信息
作者:Rooot
链接:https://www.jianshu.com/p/396675386a43
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
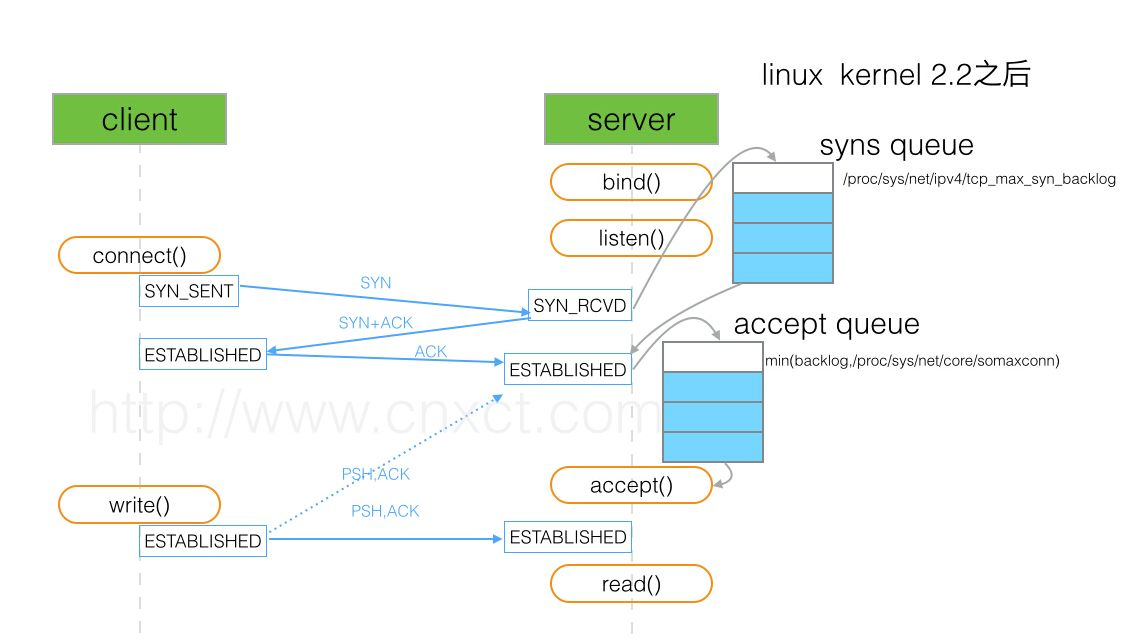
TCP/IP协议中backlog参数
TCP建立连接是要进行三次握手,但是否完成三次握手后,服务器就处理(accept)呢?
backlog其实是一个连接队列,在Linux内核2.2之前,backlog大小包括半连接状态和全连接状态两种队列大小。
半连接状态为:服务器处于Listen状态时收到客户端SYN报文时放入半连接队列中,即SYN queue(服务器端口状态为:SYN_RCVD)。
全连接状态为:TCP的连接状态从服务器(SYN+ACK)响应客户端后,到客户端的ACK报文到达服务器之前,则一直保留在半连接状态中;当服务器接收到客户端的ACK报文后,该条目将从半连接队列搬到全连接队列尾部,即 accept queue (服务器端口状态为:ESTABLISHED)。
在Linux内核2.2之后,分离为两个backlog来分别限制半连接(SYN_RCVD状态)队列大小和全连接(ESTABLISHED状态)队列大小。
SYN queue 队列长度由 /proc/sys/net/ipv4/tcp_max_syn_backlog 指定,默认为2048。
Accept queue 队列长度由 /proc/sys/net/core/somaxconn 和使用listen函数时传入的参数,二者取最小值。默认为128。在Linux内核2.4.25之前,是写死在代码常量 SOMAXCONN ,在Linux内核2.4.25之后,在配置文件 /proc/sys/net/core/somaxconn 中直接修改,或者在 /etc/sysctl.conf 中配置 net.core.somaxconn = 128 。
可以通过ss命令来显示
1 | [root@localhost ~]# ss -l |
在LISTEN状态,其中 Send-Q 即为Accept queue的最大值,Recv-Q 则表示Accept queue中等待被服务器accept()。
另外客户端connect()返回不代表TCP连接建立成功,有可能此时accept queue 已满,系统会直接丢弃后续ACK请求;客户端误以为连接已建立,开始调用等待至超时;服务器则等待ACK超时,会重传SYN+ACK 给客户端,重传次数受限 net.ipv4.tcp_synack_retries ,默认为5,表示重发5次,每次等待30~40秒,即半连接默认时间大约为180秒,该参数可以在tcp被洪水攻击是临时启用这个参数。
查看SYN queue 溢出
1 | [root@localhost ~]# netstat -s | grep LISTEN |
查看Accept queue 溢出
1 | [root@localhost ~]# netstat -s | grep TCPBacklogDrop |
1 | [root@nauru-084 ~]# netstat -s |
参考资料:
那些让你起飞的计算机基础知识
1、信息的表示和处理
计算机如何表示整数:有符号数和无符号数,尤其是如何用补码表示负数,数字的取值范围。
计算机如何表示浮点数,为什么小数的二进制表示法只能近似表示十进制小数。
数值的转换、移位
这几点非常重要,因为几乎所有的编程语言都有数据类型,而最基本数据类型必然包括整数和浮点数。
搞不清这些表示和运算,在编程中就会遇到一些稀奇古怪的问题。
2、从汇编层面理解程序的执行
顺序、分支、循环、函数调用、数组、结构体等在汇编层面是怎么实现的,寄存器和内存是怎么使用的。
理解了这些其实也就理解了冯诺依曼计算机体系结构,这是计算机学科一个基础性的东西。
知道程序在底层是怎么运转的, 对于学习各种虚拟机有很大的帮助,比如 JVM,它要解析执行的是字节码,字节码本质上要表达的就是这些东西,只不过有所扩展。
理解了栈帧,就能理解函数调用的本质,递归,以及尾递归的实现。还有安全相关的概念,如缓冲区溢出这个臭名卓著的漏洞及其防范办法。
3、进程和线程
程序员必备的知识,不了解这个,简直是无法编程。
需要掌握进程的地址空间,代码在哪里,堆在哪里,栈在哪里。
要准确理解进程和线程之间的关系,为什么说进程是拥有资源的基本单位, 线程是CPU调度的基本单位?
进程切换和线程切换之间的区别和联系。
他们是如何创建,执行,有哪些状态,状态之间的转换。 由此会涉及到 并发和并行,线程之间的竞争和合作。
锁 的本质(硬件层面),乐观锁,悲观锁,死锁等问题。
线程的实现方式,用户级线程和内核级线程的对应方式。
在编程的过程中,有些知识点会直接使用,如多线程编程,锁。 还有一些概念能用到很多地方,例如CAS,不仅仅是编程语言的概念,还能在更新数据库时使用。再比如你理解了线程的实现方式,迅速就能掌握go语言中并发的手段:goroutine。
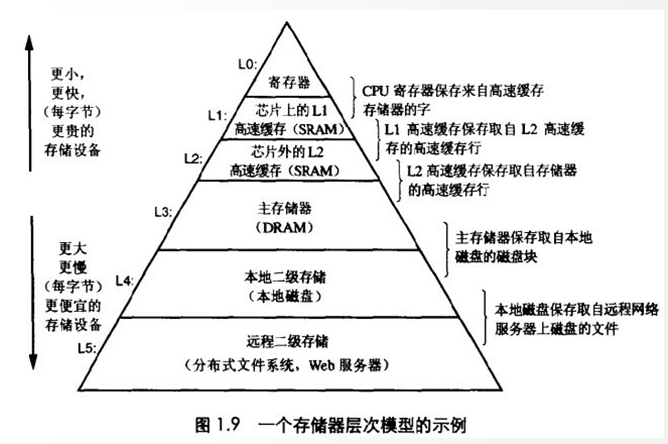
4、存储器的层次结构
Tomcat用了多线程执行请求,Redis用了单线程来处理请求,Node.js也用了单线程来,这是为什么? 秘密都在存储器的层次结构。
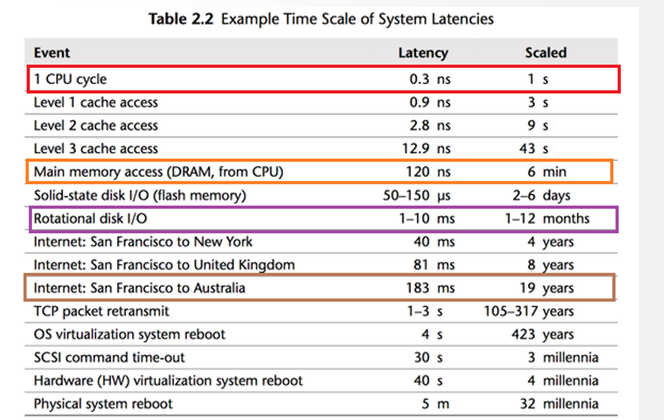
人类制造的计算机设备之间有着巨大的速度差异:
总之,CPU超级快,内存比较快,硬盘非常慢,网络更慢, 这个速度差异是IT行业的一个核心问题,人类想了很多办法试图去弥补这个差异:多线程,缓存(局部性原理),异步,多路复用,硬件层面的DMA。
记着下面这张图,每当你遇到某个软件的特性的时候,想一想和它有什么关系:
5、数据结构和算法
它的重要性我罗嗦过很多次了,不用再重复了, 我就举个最简单的例子: 理解了B+ Tree才能理解MySQL的InnoDB的索引,理解了索引才能更好地优化查询,对吧?
6、计算机网络
现在的程序基本上都是网络程序, 所以这也是一个必备的基础知识,学习计算机网络的一大好处就是和工作直接相关,能直接使用,比较有动力。
HTTP协议肯定跑不掉,TCP, UDP也得会,尤其是TCP可靠传输的原理:如何在一个不可靠的网络中进行可靠的传输, 这是无数前辈总结的经验,一定得掌握。
要理解什么是通信协议,也许某一天你自己就需要定制一个协议来传输数据。
分组交换是什么意思? 协议分层的本质是什么? 什么叫无状态的协议?
Socket相关的编程更是重点,尤其是涉及到服务器端高并发的时候,如何维持和处理这些海量的socket, epoll等技术就得上场了。
还有非常重要的https的基本原理,也是网络安全的精华所在:对称加密,非对称加密,消息摘要,数字证书,中间人攻击。
7、数据库
不多说,关系模型、范式、SQL、索引、事务等知识都得掌握,尤其是要了解他们的实现方式。
8、分布式的基础知识
这些已经偏向应用层面了,但是现在很多系统都是分布式的了,分布式就变成了一种基础知识。
系统通信:RPC, 消息队列等
负载均衡的原理
CAP原理,BASE原理,幂等性,一致性模型(强一致性,最终一致性…)和相关协议(两阶段提交,Raft,Paxos…)
数据分片:取模算法,一致性Hash,虚拟桶
9、基本的设计思想
下面这几种设计思想对我影响很大,需要大家特别注意。但是掌握起来却很不容易,需要在实践中不断地体会:
正交:各个概念之间可以独立变化
抽象:抛弃细节,找到本质和共性
《深入理解计算机系统》一书中提到:“指令集是对CPU的抽象, 文件是对输入/输出设备的抽象, 虚拟存储器是对程序存储的抽象, 进程是对一个正在运行的程序的抽象, 而虚拟机是对整个计算机(包括操作系统、处理器和程序)的抽象。 如果你对这句话透彻理解了,说明对计算机系统的认识已经很深刻了。
分层:我只想和我的邻居打交道, 如网络协议,Web应用开发。
分而治之:大事化小,小事化了,架构设计必备。
10、关键点来了,怎么学习呢?
我原来的方式是先看书,看了很多书,数据结构,操作系统,汇编,网络… 这种办法的最大问题就是枯燥(嗯,那时候还没有码农翻身这样用故事讲解技术的文章)。
理论多,实践少,很多知识点体会不深, 等到参与的项目多了,Coding多了,这些知识点才慢慢地鲜活起来。
一种更加有效的办法是从工作中用到的知识点出发,从这个知识点向外扩展,由点到线,由线到面,然后让各个层次都连接起来,形成一个立体的网络。
切记,学习是一个螺旋上升的过程,想要上升就得深度思考,多问几个为什么。
比如工作中用到了Redis,你在学习过程中发现这个Redis用了单线程来处理读写请求,为什么要这么做? 对于成千上万的请求它是如何处理的? 然后再联想一下别的软件:Tomcat为什么不这么干? 想回答这些问题,需要发掘很多基础知识。
这样做的次数多了,积累到一定程度,量变就会引起质变,整个系统就被你看透了,你的知识又扩大了一圈,更多的疑问出现了…
DNS分别在什么情况下使用UDP和TCP
DNS同时占用UDP和TCP端口53是公认的,这种单个应用协议同时使用两种传输协议的情况在TCP/IP栈也算是个另类。但很少有人知道DNS分别在什么情况下使用这两种协议。
如果用wireshark、sniffer或古老些的tcpdump抓包分析,会发现几乎所有的情况都是在使用UDP,使用TCP的情况非常罕见,神秘兮兮。其实当解析器发出一个request后,返回的response中的tc删节标志比特位被置1时,说明反馈报文因为超长而有删节。这是因为UDP的报文最大长度为512字节。解析器发现后,将使用TCP重发request,TCP允许报文长度超过512字节。既然TCP能将data stream分成多个segment,它就能用更多的segment来传送任意长度的数据。
另外一种情况是,当一个域的辅助域名服务器启动时,将从该域的主域名服务器primary DNS server执行区域传送。除此之外,辅域名服务器也会定时(一般时3小时)向PDS进行查询以便了解SOA的数据是否有变动。如有变动,也会执行一次区域传送。区域传送将使用TCP而不是UDP,因为传送的数据量比一个request或response多得多。
DNS主要还是使用UDP,解析器还是服务端都必须自己处理重传和超时。DNS往往需要跨越广域网或互联网,分组丢失率和往返时间的不确定性要更大些,这对于DNS客户端来说是个考验,好的重传和超时检测就显得更重要了。
DNS为什么用TCP和UDP
DNS同时占用UDP和TCP端口53是公认的,这种单个应用协议同时使用两种传输协议的情况在TCP/IP栈也算是个另类。但很少有人知道DNS分别在什么情况下使用这两种协议。
先简单介绍下TCP与UDP
TCP是一种面向连接的协议,提供可靠的数据传输,一般服务质量要求比较高的情况,使用这个协议。
UDP—用户数据报协议,是一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务。
TCP与UDP的区别
UDP和TCP协议的主要区别是两者在如何实现信息的可靠传递方面不同。TCP协议中包含了专门的传递保证机制,当数据接收方收到发送方传来的信息时,会自动向发送方发出确认消息;发送方只有在接收到该确认消息之后才继续传送其它信息,否则将一直等待直到收到确认信息为止。 与TCP不同,UDP协议并不提供数据传送的保证机制。如果在从发送方到接收方的传递过程中出现数据报的丢失,协议本身并不能做出任何检测或提示。因此,通常人们把UDP协议称为不可靠的传输协议。相对于TCP协议,UDP协议的另外一个不同之处在于如何接收突发性的多个数据报。不同于TCP,UDP并不能确保数据的发送和接收顺序。事实上,UDP协议的这种乱序性基本上很少出现,通常只会在网络非常拥挤的情况下才有可能发生。
既然UDP是一种不可靠的网络协议,那么还有什么使用价值或必要呢?其实不然,在有些情况下UDP协议可能会变得非常有用。因为UDP具有TCP所望尘莫及的速度优势。虽然TCP协议中植入了各种安全保障功能,但是在实际执行的过程中会占用大量的系统开销,无疑使速度受到严重的影响。反观UDP由于排除了信息可靠传递机制,将安全和排序等功能移交给上层应用来完成,极大降低了执行时间,使速度得到了保证。
DNS在进行区域传输的时候使用TCP协议,其它时候则使用UDP协议;
DNS的规范规定了2种类型的DNS服务器,一个叫主DNS服务器,一个叫辅助DNS服务器。在一个区中主DNS服务器从自己本机的数据文件中读取该区的DNS数据信息,而辅助DNS服务器则从区的主DNS服务器中读取该区的DNS数据信息。当一个辅助DNS服务器启动时,它需要与主DNS服务器通信,并加载数据信息,这就叫做区传送(zone transfer)。
为什么既使用TCP又使用UDP?
首先了解一下TCP与UDP传送字节的长度限制:
UDP报文的最大长度为512字节,而TCP则允许报文长度超过512字节。当DNS查询超过512字节时,协议的TC标志出现删除标志,这时则使用TCP发送。通常传统的UDP报文一般不会大于512字节。
区域传送时使用TCP
主要有一下两点考虑:
辅域名服务器会定时(一般时3小时)向主域名服务器进行查询以便了解数据是否有变动。如有变动,则会执行一次区域传送,进行数据同步。区域传送将使用TCP而不是UDP,因为
数据同步传送的数据量比一个请求和应答的数据量要多得多。TCP是一种可靠的连接,保证了数据的准确性。
域名解析时使用UDP协议
客户端向DNS服务器查询域名,一般返回的内容都不超过512字节,用UDP传输即可。不用经过TCP三次握手,这样DNS服务器负载更低,响应更快。虽然从理论上说,客户端也可以指定向DNS服务器查询的时候使用TCP,但事实上,很多DNS服务器进行配置的时候,仅支持UDP查询包。
UDP
UDP 与 TCP 的主要区别在于 UDP 不一定提供可靠的数据传输。事实上,该协议不能保证数据准确无误地到达目的地。UDP 在许多方面非常有效。当某个程序的目标是尽快地传输尽可能多的信息时(其中任意给定数据的重要性相对较低),可使用 UDP。ICQ 短消息使用 UDP 协议发送消息。
许多程序将使用单独的TCP连接和单独的UDP连接。重要的状态信息随可靠的TCP连接发送,而主数据流通过UDP发送。
TCP
TCP的目的是提供可靠的数据传输,并在相互进行通信的设备或服务之间保持一个虚拟连接。TCP在数据包接收无序、丢失或在交付期间被破坏时,负责数据恢复。它通过为其发送的每个数据包提供一个序号来完成此恢复。记住,较低的网络层会将每个数据包视为一个独立的单元,因此,数据包可以沿完全不同的路径发送,即使它们都是同一消息的组成部分。这种路由与网络层处理分段和重新组装数据包的方式非常相似,只是级别更高而已。
为确保正确地接收数据,TCP要求在目标计算机成功收到数据时发回一个确认(即 ACK)。如果在某个时限内未收到相应的 ACK,将重新传送数据包。如果网络拥塞,这种重新传送将导致发送的数据包重复。但是,接收计算机可使用数据包的序号来确定它是否为重复数据包,并在必要时丢弃它。
TCP与UDP的选择
如果比较UDP包和TCP包的结构,很明显UDP包不具备TCP包复杂的可靠性与控制机制。与TCP协议相同,UDP的源端口数和目的端口数也都支持一台主机上的多个应用。一个16位的UDP包包含了一个字节长的头部和数据的长度,校验码域使其可以进行整体校验。(许多应用只支持UDP,如:多媒体数据流,不产生任何额外的数据,即使知道有破坏的包也不进行重发。)
很明显,当数据传输的性能必须让位于数据传输的完整性、可控制性和可靠性时,TCP协议是当然的选择。当强调传输性能而不是传输的完整性时,如:音频和多媒体应用,UDP是最好的选择。在数据传输时间很短,以至于此前的连接过程成为整个流量主体的情况下,UDP也是一个好的选择,如:DNS交换。把SNMP建立在UDP上的部分原因是设计者认为当发生网络阻塞时,UDP较低的开销使其有更好的机会去传送管理数据。TCP丰富的功能有时会导致不可预料的性能低下,但是我们相信在不远的将来,TCP可靠的点对点连接将会用于绝大多数的网络应用。
TCP(Transmission Control Protocol,传输控制协议)是基于连接的协议,也就是说,在正式收发数据前,必须和对方建立可靠的连接。一个TCP连接必须要经过三次“对话”才能建立起来。三次对话的简单过程:主机A向主机B发出连接请求数据包:“我想给你发数据,可以吗?”,这是第一次对话;主机B向主机A发送同意连接和要求同步(同步就是两台主机一个在发送,一个在接收,协调工作)的数据包:“可以,你什么时候发?”,这是第二次对话;主机A再发出一个数据包确认主机B的要求同步:“我现在就发,你接着吧!”,这是第三次对话。三次“对话”的目的是使数据包的发送和接收同步,经过三次“对话”之后,主机A才向主机B正式发送数据。
UDP(User Data Protocol,用户数据报协议)是与TCP相对应的协议。它是面向非连接的协议,它不与对方建立连接,而是直接就把数据包发送过去!
UDP适用于一次只传送少量数据、对可靠性要求不高的应用环境。比如,我们经常使用“ping”命令来测试两台主机之间TCP/IP通信是否正常,其实“ping”命令的原理就是向对方主机发送UDP数据包,然后对方主机确认收到数据包,如果数据包是否到达的消息及时反馈回来,那么网络就是通的。例如,在默认状态下,一次“ping”操作发送4个数据包(如图2所示)。大家可以看到,发送的数据包数量是4包,收到的也是4包(因为对方主机收到后会发回一个确认收到的数据包)。这充分说明了UDP协议是面向非连接的协议,没有建立连接的过程。正因为UDP协议没有连接的过程,所以它的通信效果高;但也正因为如此,它的可靠性不如TCP协议高。QQ就使用UDP发消息,因此有时会出现收不到消息的情况。HTTP是用TCP协议传输的。
TCP协议与UDP协议的区别
TCP基于面向连接的协议,数据传输可靠,传输速度慢,适用于传输大量数据,可靠性要求高的场合。
UDP协议面向非连接协议,数据传输不可靠,传输速度快,适用于一次只传送少量数据、对可靠性要求不高的应用环境。
面向连接的TCP
“面向连接”就是在正式通信前必须要与对方建立起连接。比如你给别人打电话,必须等线路接通了、对方拿起话筒才能相互通话。
TCP协议能为应用程序提供可靠的通信连接,使一台计算机发出的字节流无差错地发往网络上的其他计算机,对可靠性要求高的数据通信系统往往使用TCP协议传输数据。
面向非连接的UDP协议
“面向非连接”就是在正式通信前不必与对方先建立连接,不管对方状态就直接发送。这与现在风行的手机短信非常相似:你在发短信的时候,只需要输入对方手机号就OK了。
UDP适用于一次只传送少量数据、对可靠性要求不高的应用环境
UDP协议是面向非连接的协议,没有建立连接的过程。正因为UDP协议没有连接的过程,所以它的通信效果高;但也正因为如此,它的可靠性不如TCP协议高。QQ就使用UDP发消息,因此有时会出现收不到消息的情况。
TCP**协议与UDP协议支持的应用协议**
TCP支持的应用协议主要有:Telnet**、FTP、SMTP**等;
UDP支持的应用层协议主要有:NFS(网络文件系统)、SNMP(简单网络管理协议)、DNS(主域名称系统)、TFTP(通用文件传输协议)等。
TCP和UDP都是位于OSI模型中的传输层中。
TCP优点:面向连接的,具有实时性,就象打电话一样,两者必须建立连接.
它保证你所传输的东西是准确到达的,并且收方要给你一个收到或没有\ 收到的回复,所以它具有安全性的特点..
UDP优点:面向无连接的,就象给某人寄信一样,对方不需要在邮局等着你的信到.
所以说,它没有保障性,不能确保你一定能收到信,不象TCP那样,,但是 它比TCP好的一点,就是速度快,因为他不需要双方交流是否收到,对发的东西有一个确认的过程.