1、安装bloomfiler插件
2、用法
1 | [root@dn1 ~]# redis-cli -a 123456 |
布隆过滤器下载安装
首先我们使用布隆过滤器那么我们需要下载布隆过滤器:
下载地址:https://github.com/RedisBloom/RedisBloom
注意:
- 需要选择和你redis版本适配的版本
- 下载之后解压即可
启动redis 时加载该模块:
1 | 启动redisserver 使用配置文件 使用模型 模型文件位置 |
布隆过滤器全自动安装启动
1 | #创建文件并编辑文件 |
什么是布隆过滤器
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率
布隆过滤器的基本使用
布隆过滤器有二个基本指令,bf.add 添加元素,bf.exists 查询元素是否存在,如果想要一次添加多个,就需要用到 bf.madd 指令。同样如果需要一次查询多个元素是否存在,就需要用到 bf.mexists 指令。
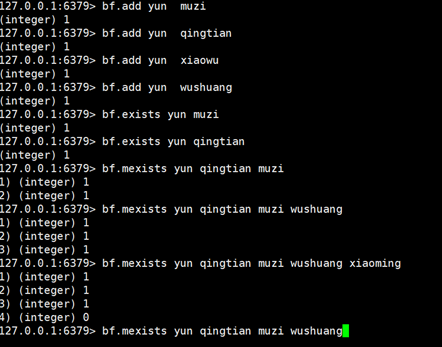
布隆过滤器的进阶
上面的例子中使用的布隆过滤器只是默认参数的布隆过滤器,它在我们第一次使用bf.add 命令时自动创建的。Redis还提供了自定义参数的布隆过滤器,想要尽量减少布隆过滤器的误判,就要设置合理的参数。
在使用bf.add 命令添加元素之前,使用bf.reserve命令创建一个自定义的布隆过滤器。bf.reserve命令有三个参数,分别是:
- key:键
- error_rate:期望错误率,期望错误率越低,需要的空间就越大。
- capacity:初始容量,当实际元素的数量超过这个初始化容量时,误判率上升。
如果对应的key已经存在时,在执行bf.reserve命令就会报错。如果不使用bf.reserve命令创建,而是使用Redis自动创建的布隆过滤器,默认的error_rate是 0.001,capacity是 100。
1 | $ bf.reserve text 0.0001 1000000 #示例 设置 text 精度 0.0001 空间 1000000 |
布隆过滤器的error_rate越小,需要的存储空间就越大,对于不需要过于精确的场景,error_rate设置稍大一点也可以。布隆过滤器的capacity设置的过大,会浪费存储空间,设置的过小,就会影响准确率,所以在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出设置值很多。总之,error_rate和 capacity都需要设置一个合适的数值。

布隆过滤器的原理
Redis中布隆过滤器的数据结构就是一个很大的位数组和几个不一样的无偏哈希函数(能把元素的哈希值算得比较平均,能让元素被哈希到位数组中的位置比较随机)。如下图,A、B、C就是三个这样的哈希函数,分别对“yunxitext”和“云析学院”这两个元素进行哈希,位数组的对应位置则被设置为1:
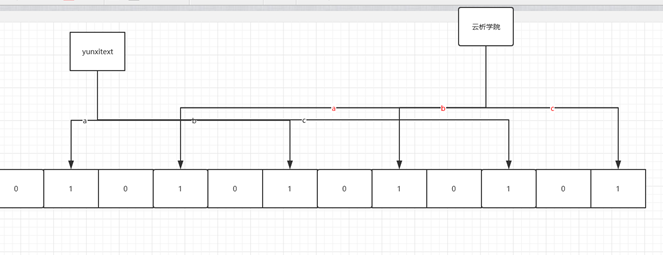
向布隆过滤器中添加元素时,会使用多个无偏哈希函数对元素进行哈希,算出一个整数索引值,然后对位数组长度进行取模运算得到一个位置,每个无偏哈希函数都会得到一个不同的位置。再把位数组的这几个位置都设置为1,这就完成了bf.add命令的操作。
向布隆过滤器查询元素是否存在时,和添加元素一样,也会把哈希的几个位置算出来,然后看看位数组中对应的几个位置是否都为1,只要有一个位为0,那么就说明布隆过滤器里不存在这个元素。如果这几个位置都为1,并不能完全说明这个元素就一定存在其中,有可能这些位置为1是因为其他元素的存在,这就是布隆过滤器会出现误判的原因。
布隆过滤器的应用
- 解决缓存击穿的问题
一般情况下,先查询缓存是否有该条数据,缓存中没有时,再查询数据库。当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存击穿。缓存击穿带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
可以使用布隆过滤器解决缓存击穿的问题,把已存在数据的key存在布隆过滤器中。当有新的请求时,先到布隆过滤器中查询是否存在,如果不存在该条数据直接返回;如果存在该条数据再查询缓存查询数据库。
- 黑名单校验
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。把所有黑名单都放在布隆过滤器中,再收到邮件时,判断邮件地址是否在布隆过滤器中即可。