缓存穿透
定义
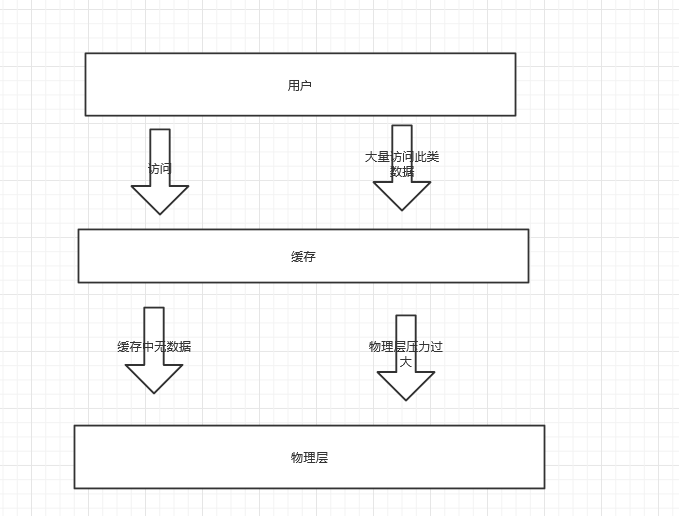
client 从 redis中拿某些key,但key不存在(本就不存在),从而流量到达 DB(DB中也不存在),给 DB 造成压力
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
解决方案
1)布隆过滤器
将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
2)设定空置
如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴
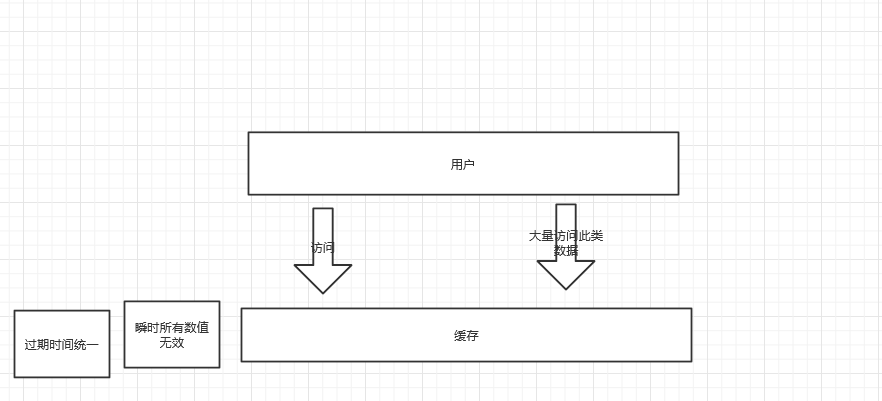
缓存雪崩
定义
由于redis 大量key同时失效,使得客户端的来的请求 直接到达 DB,打爆 DB;
缓存雪崩,是指在某一个时间段,缓存集中过期失效。
比如在商品抢购的时候,缓存里存的商品都是在晚上12点失效,而这时候刚好大量用户来访问这些商品,这时候数据库的压力就会一下上来了
所以在做电商项目的时候,一般是采取不同分类商品,缓存不同周期。在同一分类中的商品,加上一个随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的商品缓存时间短一些,也能节省缓存服务的资源。
场景:
秒杀结束,商品下架
解决方案
1)加锁排队(不推荐)
加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法!
注意:加锁排队的解决方式分布式环境的并发问题,有可能还要解决分布式锁的问题;线程还会被阻塞,用户体验很差!因此,在真正的高并发场景下很少使用!
2)缓存标记(复杂)
给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存,实例伪代码如下:
解释说明:
- 缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际key的缓存;
- 缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。 这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
关于缓存崩溃的解决方法,这里提出了三种方案:使用锁或队列、设置过期标志更新缓存、为key设置不同的缓存失效时间,还有一各被称为“二级缓存”的解决方法,有兴趣的同学可以自行研究。
3)过期时间加随机数(非重复,间隔值较大)
4)延长数据时效
5)降级处理
缓存击穿
定义
热点key 在某一时刻失效 或 不存在(本来应该存在),导致流量打到 DB,打爆 DB
解决方案
互斥锁
永不过期
降级
缓存预热
在刚启动的缓存系统中,如果缓存中没有任何数据,如果依靠用户请求的方式重建缓存数据,那么对数据库的压力非常大,而且系统的性能开销也是巨大的。
此时,最好的策略是启动时就把热点数据加载好。这样,用户请求时,直接读取的就是缓存的数据,而无需去读取 DB 重建缓存数据。

举个例子,热门的或者推荐的商品,需要提前预热到缓存中。
一般来说,有如下几种方式来实现:
- 数据量不大时,项目启动时,自动进行初始化。
- 写个修复数据脚本,手动执行该脚本。
- 写个管理界面,可以手动点击,预热对应的数据到缓存中。
缓存更新
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
- 定时去清理过期的缓存;
- 当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
- 一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
- 警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
- 错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
- 严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
缓存热点key
使用缓存 + 过期时间的策略既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。但是有两个问题如果同时出现,可能就会对应用造成致命的危害:
当前 key 是一个热点 key( 可能对应应用的热卖商品、热点新闻、热点评论等),并发量非常大。
重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的 SQL、多次 IO、多个依赖等。
在缓存失效的瞬间,有大量线程来重建缓存 ( 如下图),造成后端负载加大,甚至可能会让应用崩溃。
热点 key 失效后大量线程重建缓存
要解决这个问题也不是很复杂,但是不能为了解决这个问题给系统带来更多的麻烦,所以需要制定如下目标:
- 减少重建缓存的次数
- 数据尽可能一致
- 较少的潜在危险
互斥锁 (mutex key)
此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可,整个过程如图 ,使用互斥锁重建缓存
下面代码使用 Redis 的 setnx 命令实现上述功能,
1 | //伪代码: |
从 Redis 获取数据,如果值不为空,则直接返回值。
如果 set(nx 和 ex) 结果为 true,说明此时没有其他线程重建缓存,那么当前线程执行缓存构建逻辑。
如果 setnx(nx 和 ex) 结果为 false,说明此时已经有其他线程正在执行构建缓存的工作,那么当前线程将休息指定时间 (例如这里是 50 毫秒,取决于构建缓存的速度 ) 后,重新执行函数,直到获取到数据。
永远不过期
永远不过期”包含两层意思:
从缓存层面来看,确实没有设置过期时间,所以不会出现热点 key 过期后产生的问题,也就是“物理”不过期。
从功能层面来看,为每个 value 设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
” 永远不过期 ” 策略,整个过程如下图所示:
从实战看,此方法有效杜绝了热点 key 产生的问题,但唯一不足的就是重构缓存期间,会出现数据不一致的情况,这取决于应用方是否容忍这种不一致。下面代码使用 Redis 进行模拟:
1 | String get(final String key) { |
作为一个并发量较大的应用,在使用缓存时有三个目标:
第一,加快用户访问速度,提高用户体验。
第二,降低后端负载,减少潜在的风险,保证系统平稳。
第三,保证数据“尽可能”及时更新。下面将按照这三个维度对上述两种解决方案进行分析。
互斥锁 (mutex key):这种方案思路比较简单,但是存在一定的隐患,如果构建缓存过程出现问题或者时间较长,可能会存在死锁和线程池阻塞的风险,但是这种方法能够较好的降低后端存储负载并在一致性上做的比较好。
” 永远不过期 “:这种方案由于没有设置真正的过期时间,实际上已经不存在热点 key 产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大